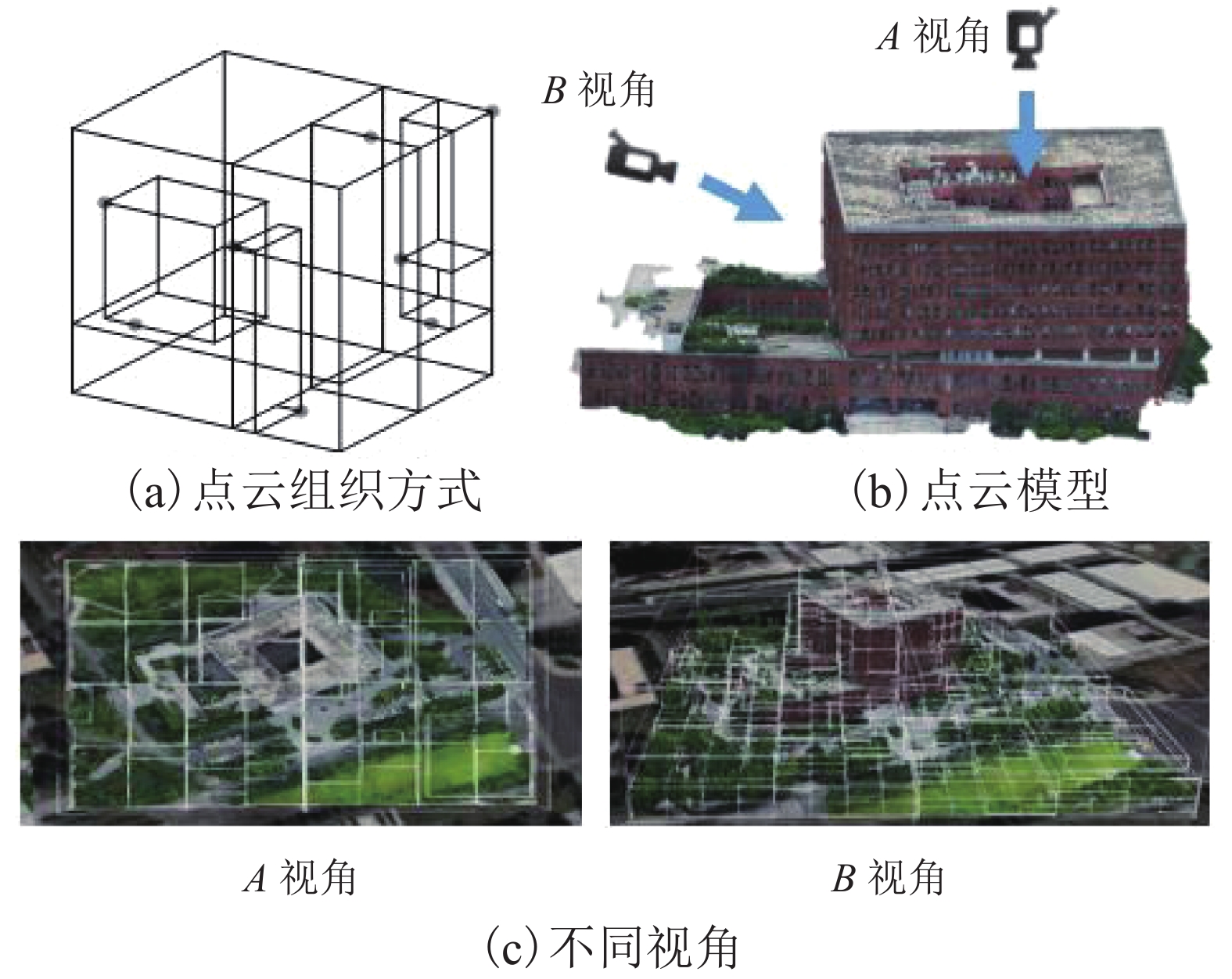
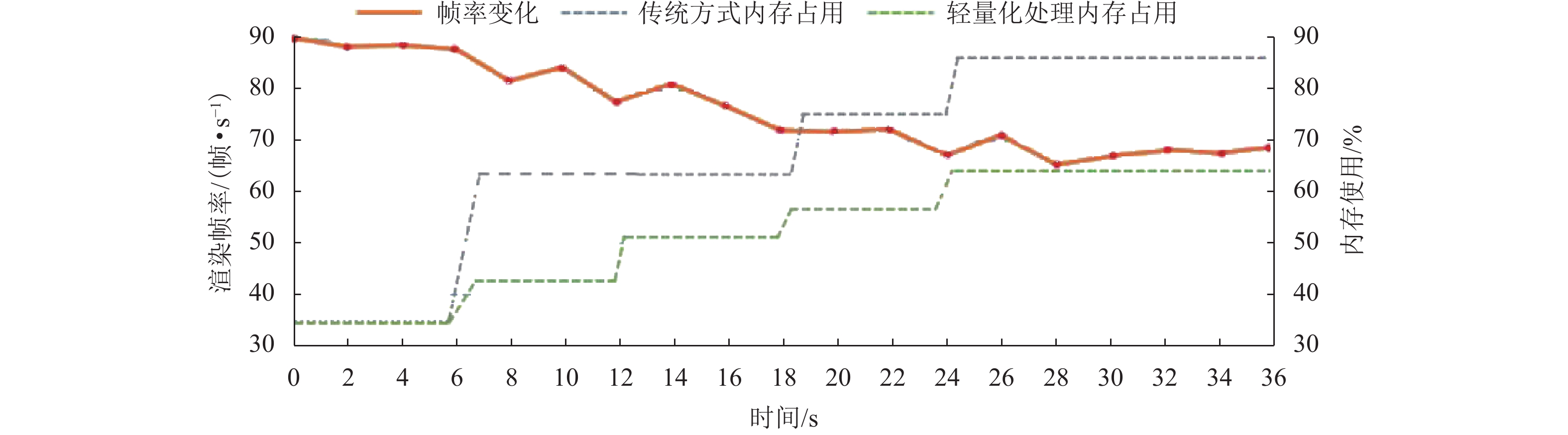
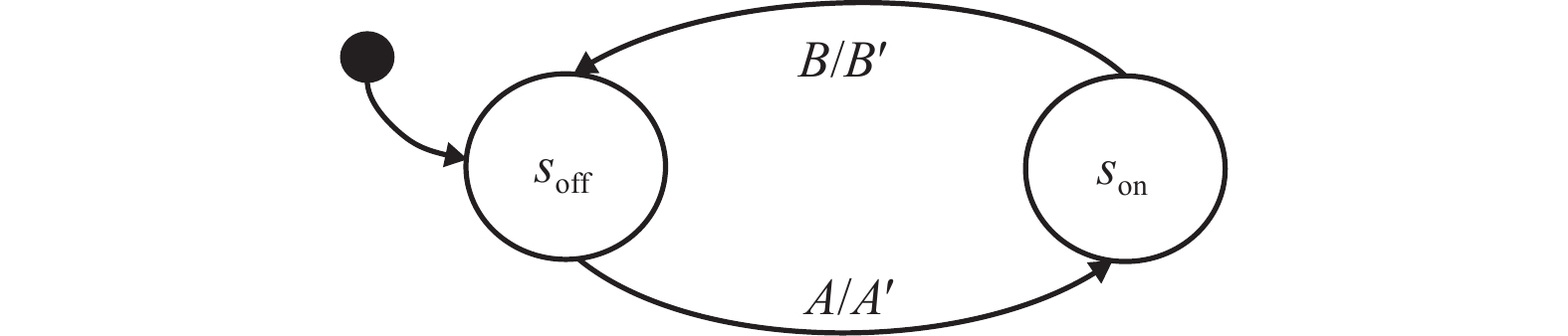
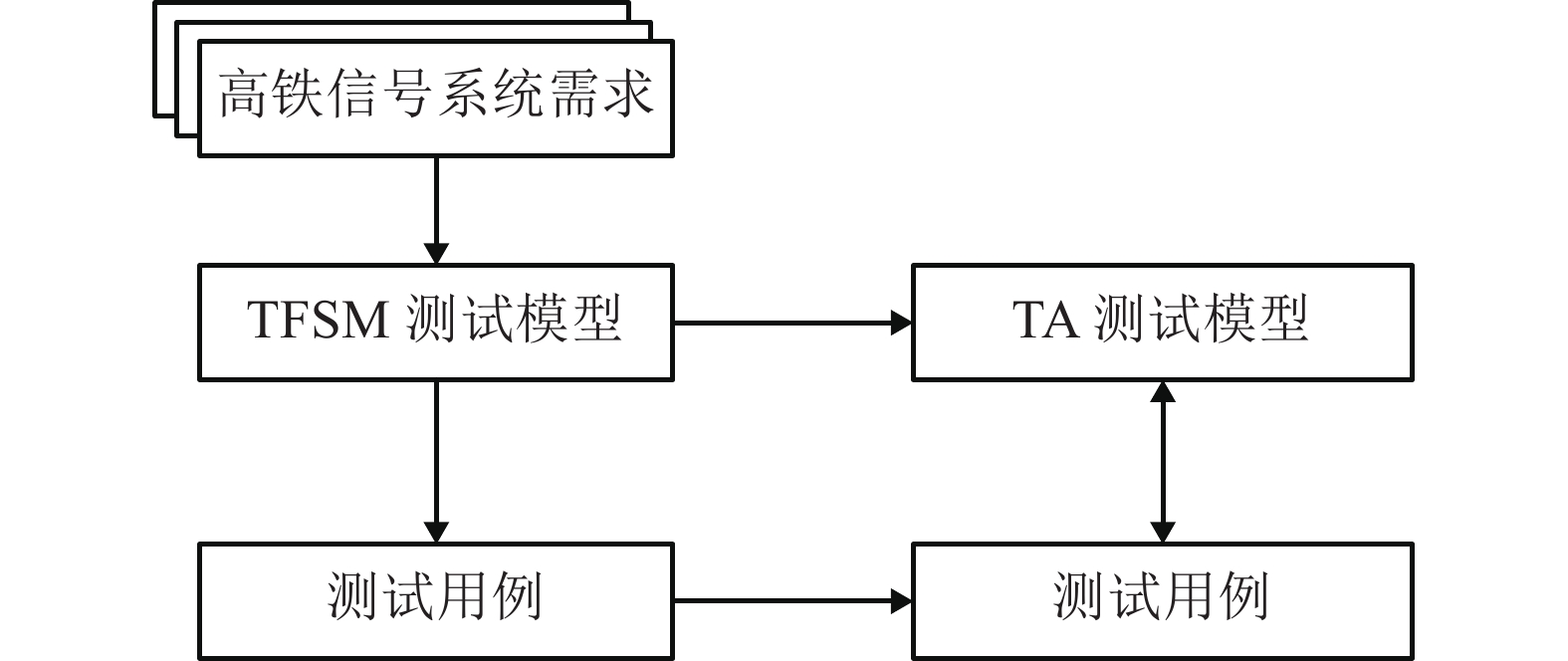
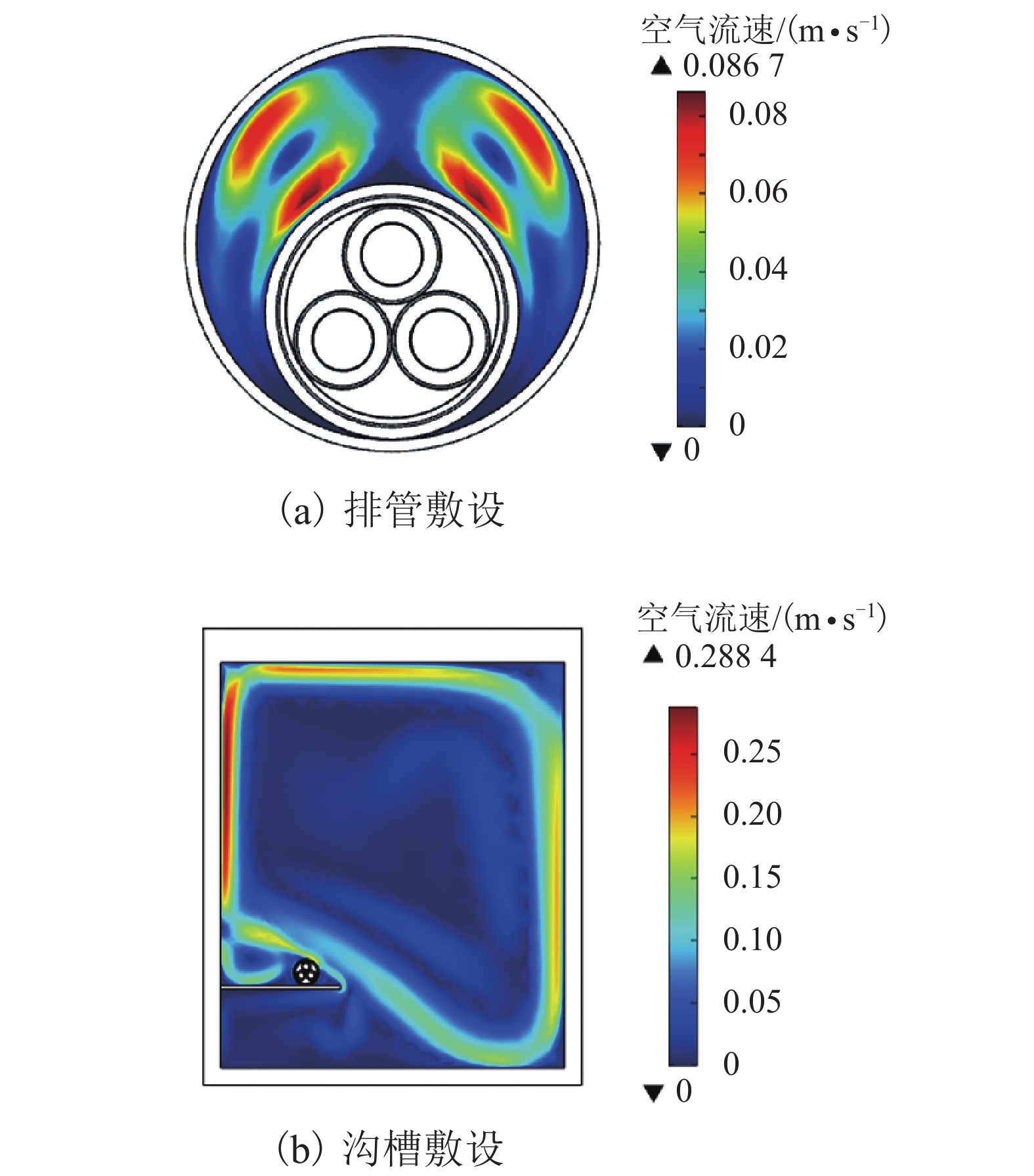
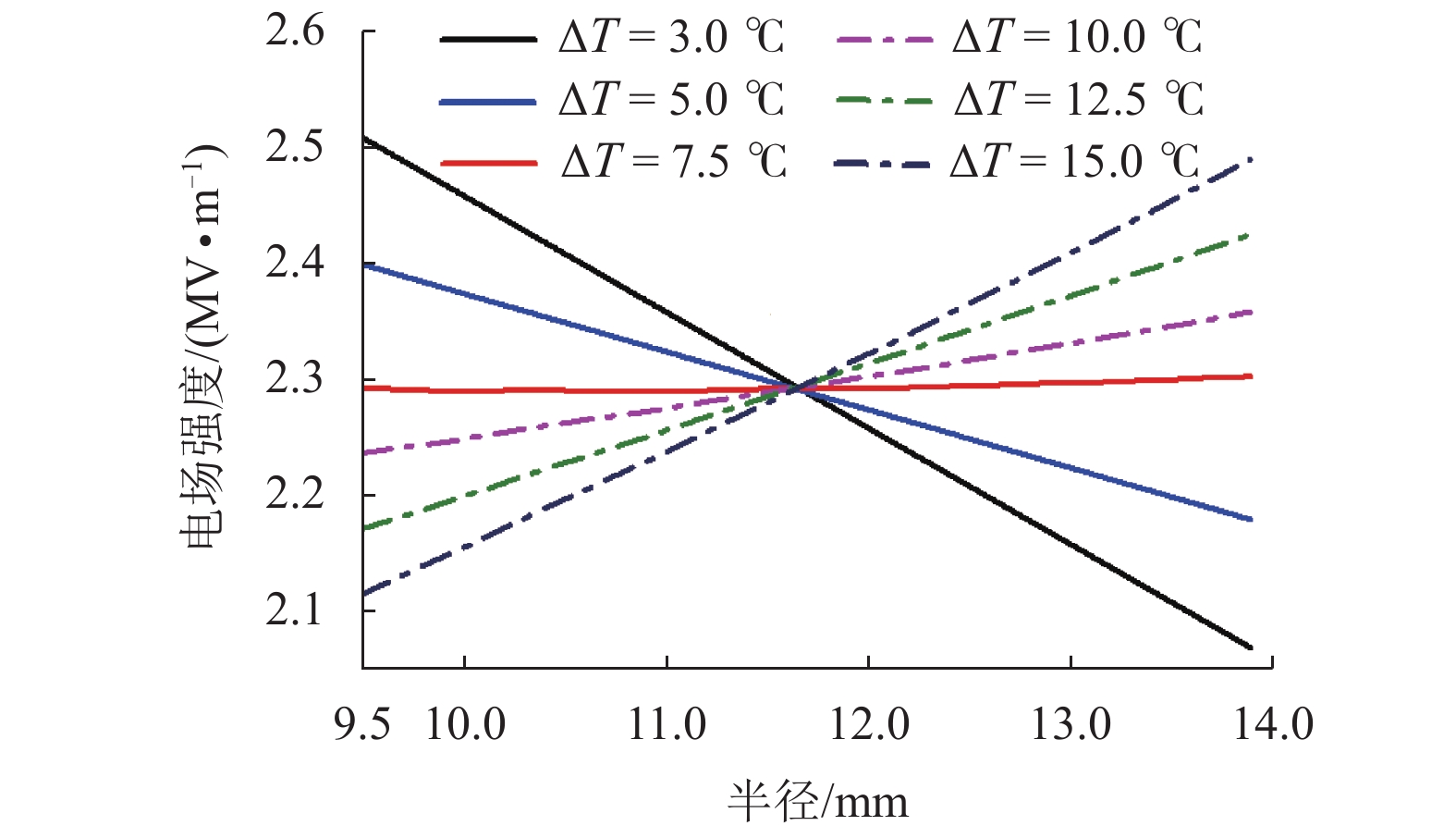
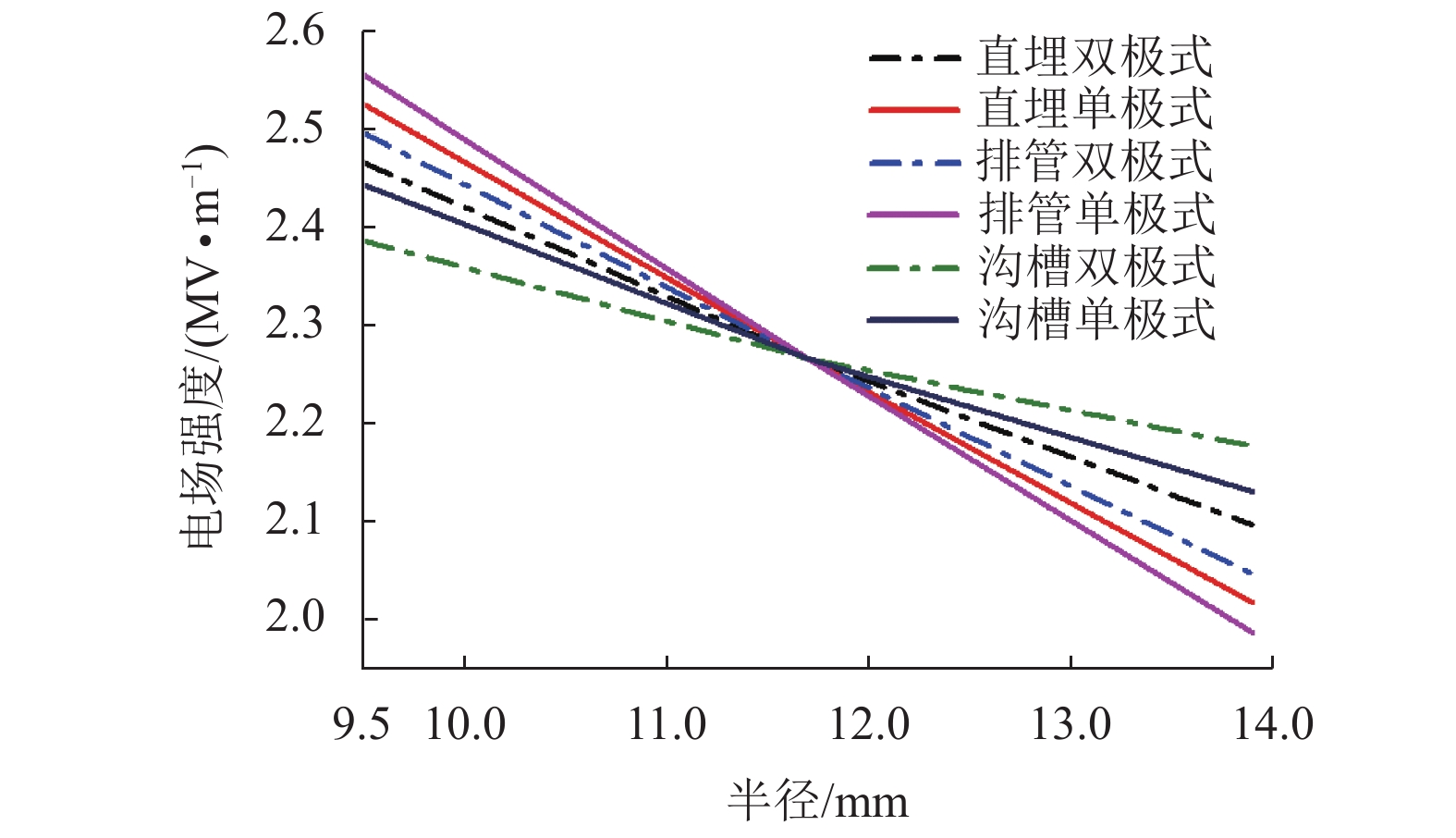
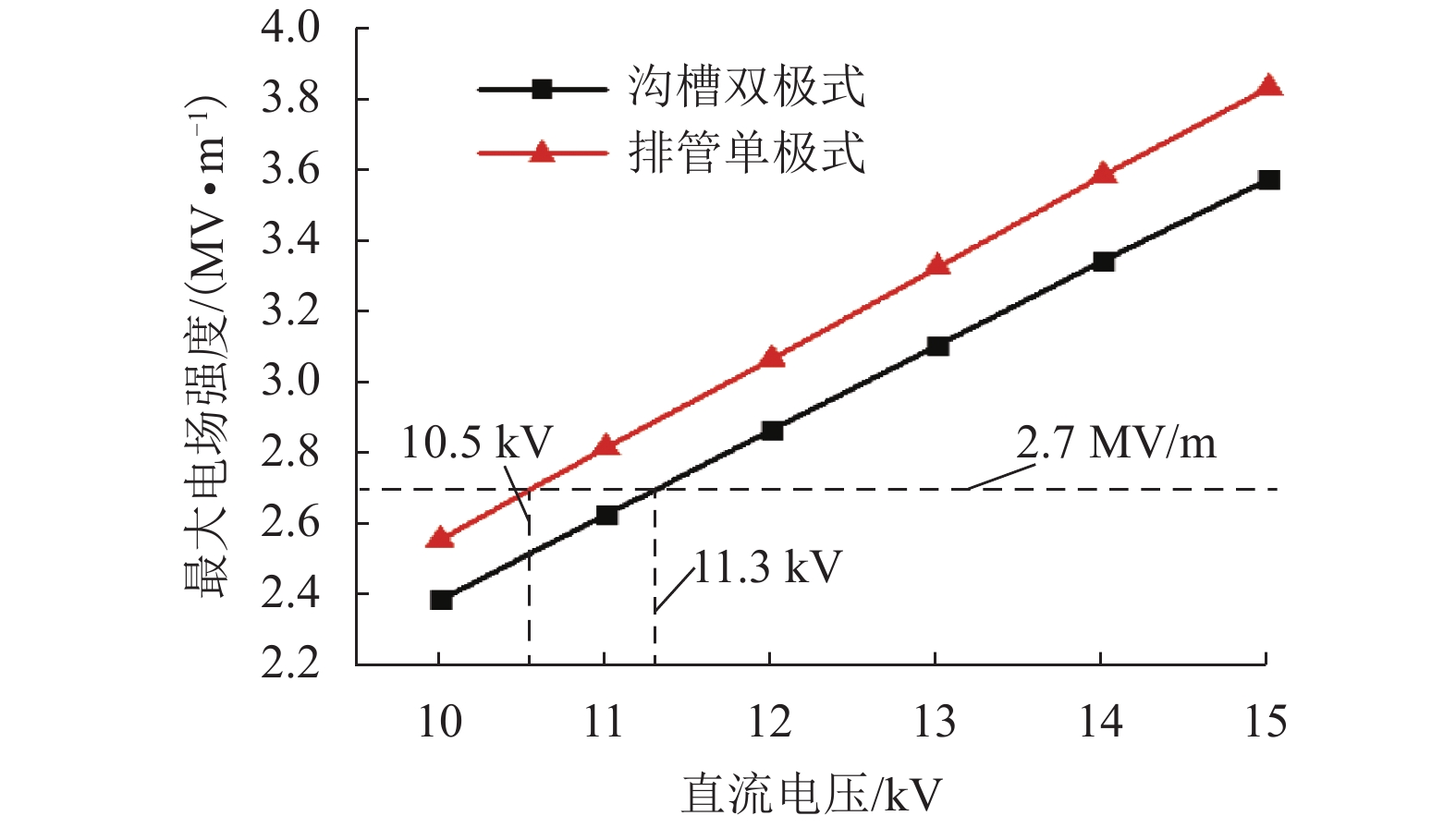
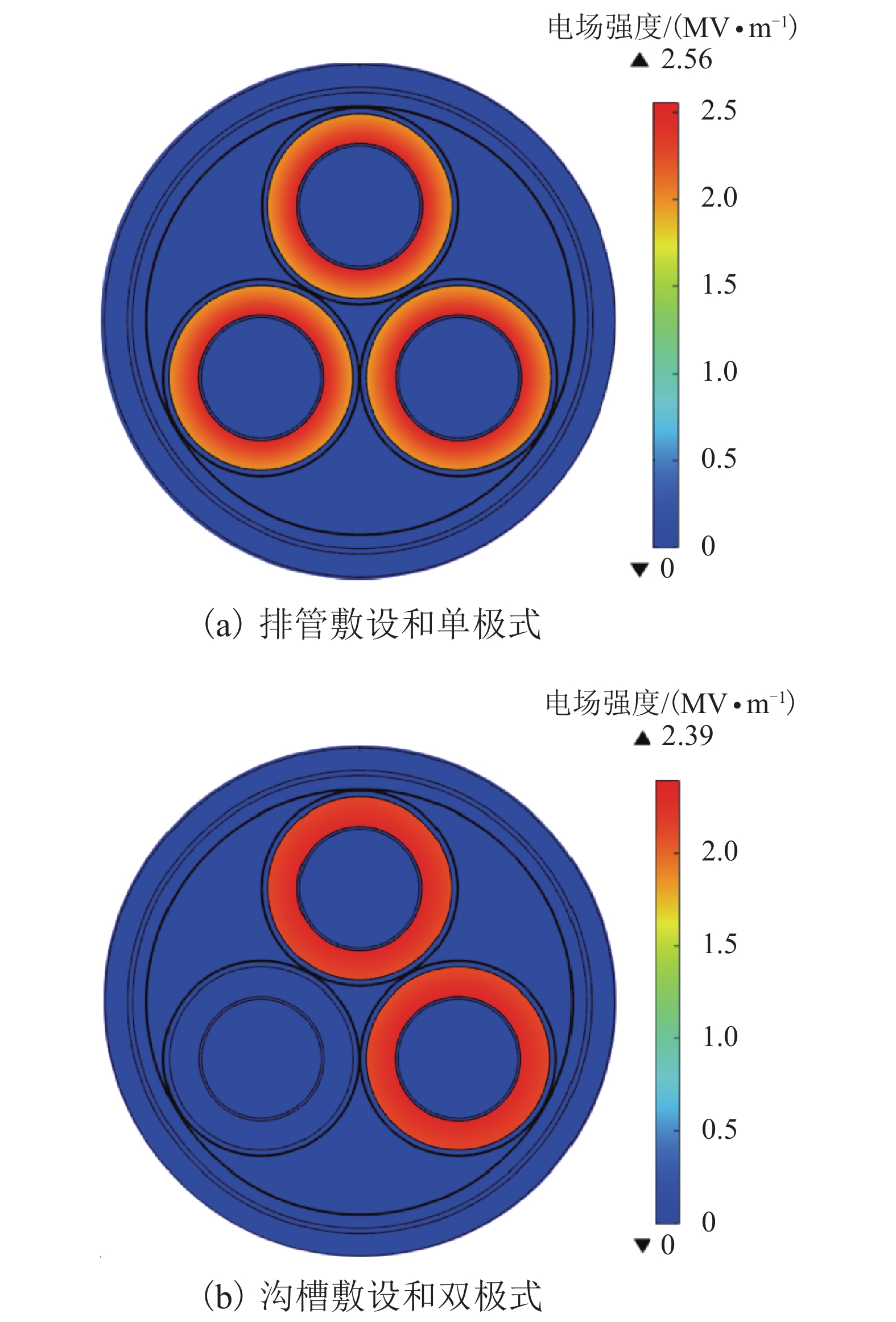
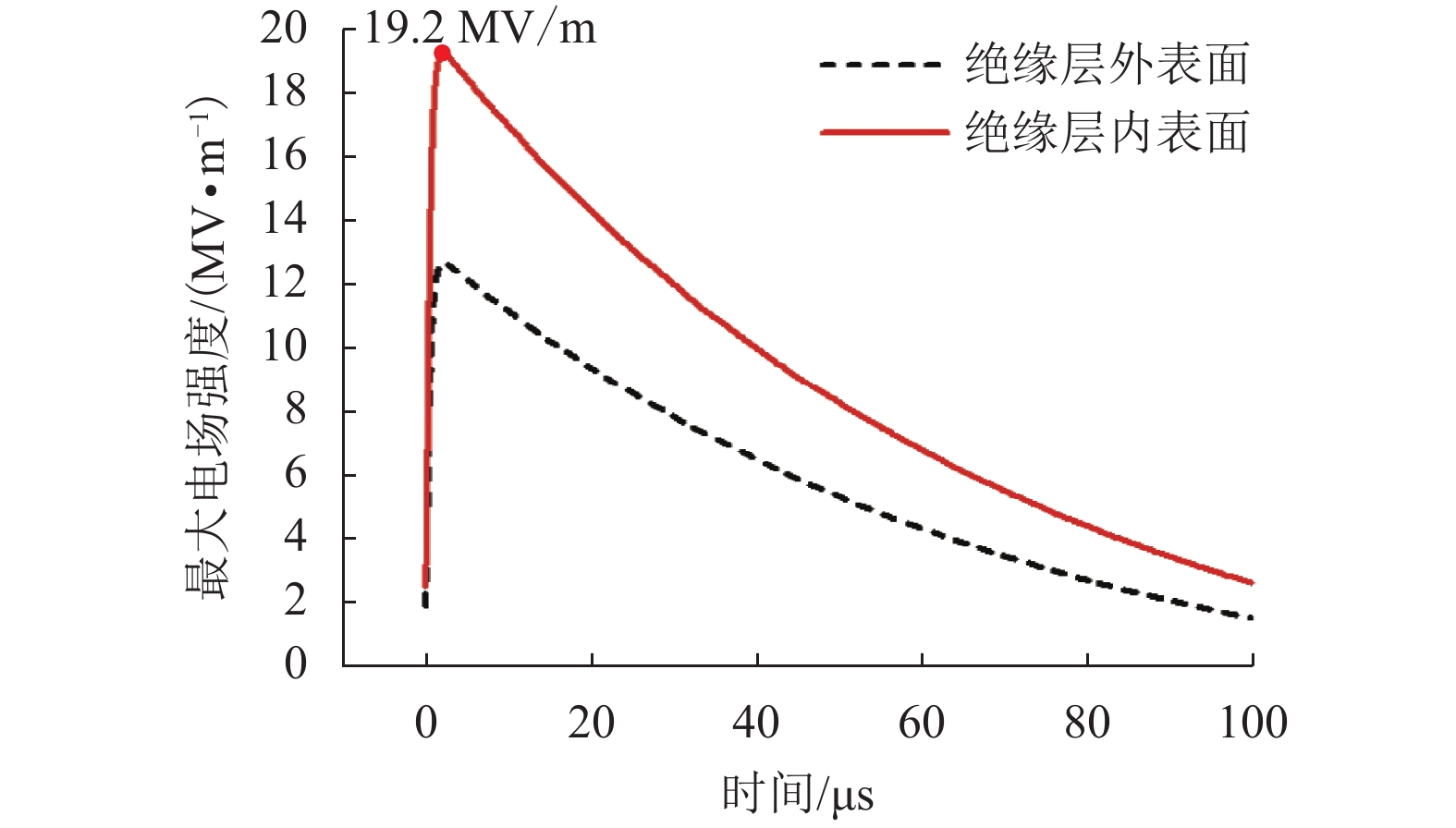
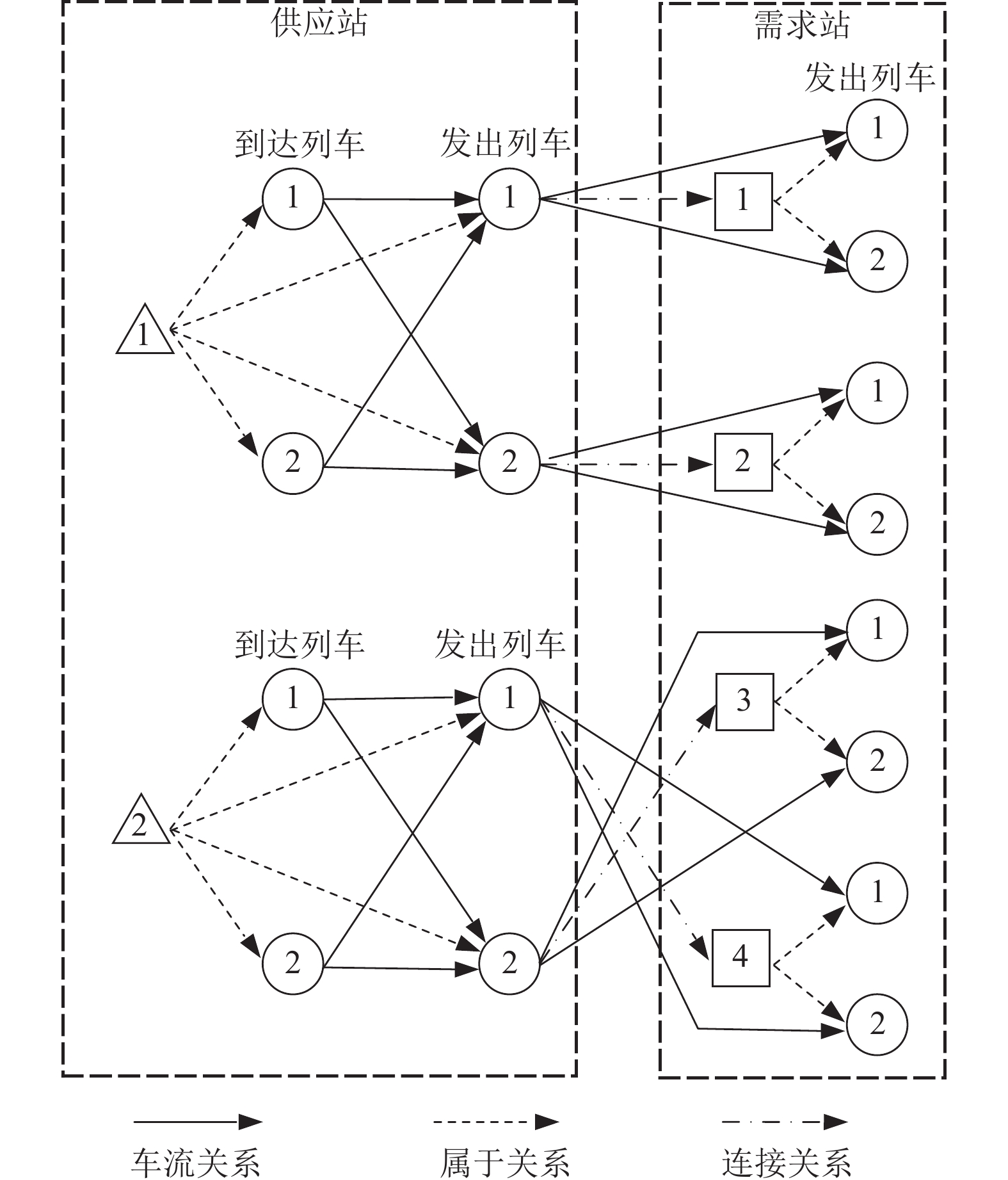
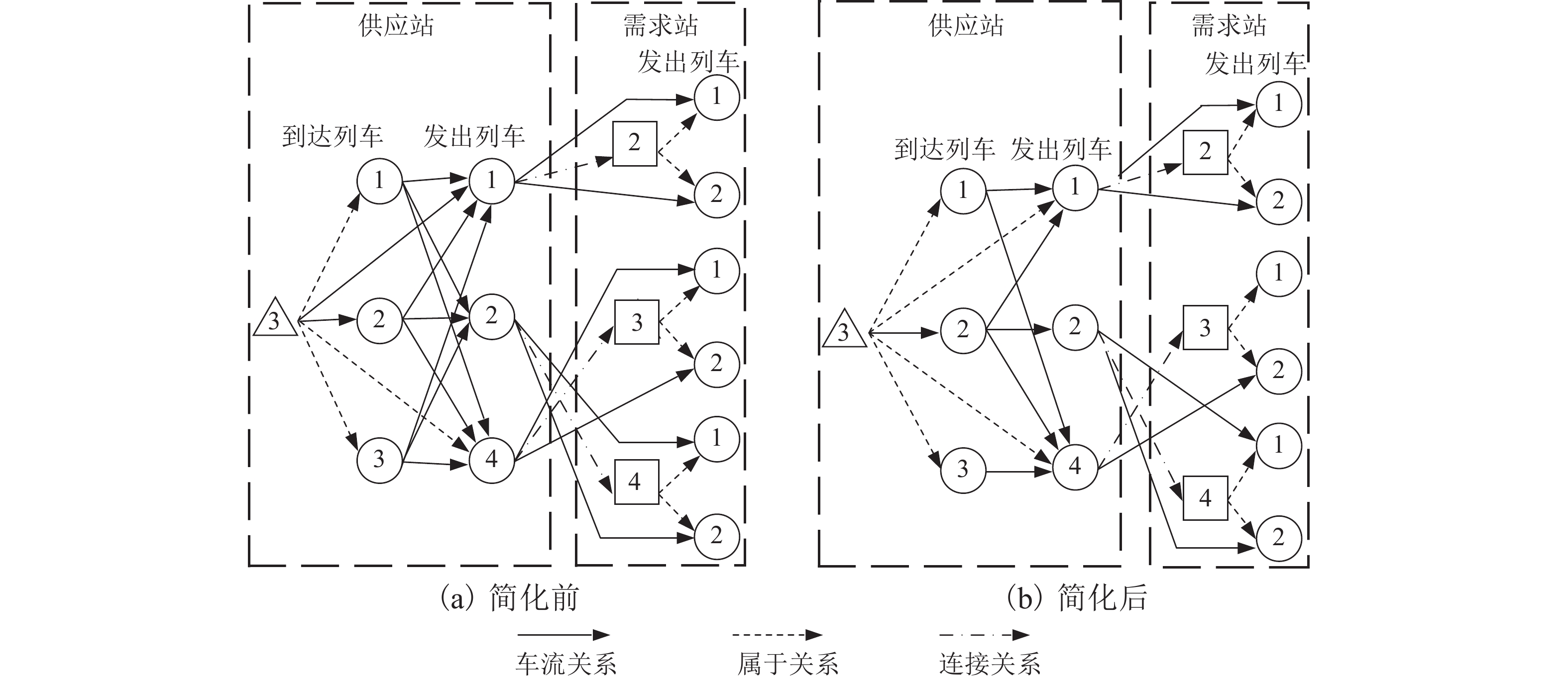
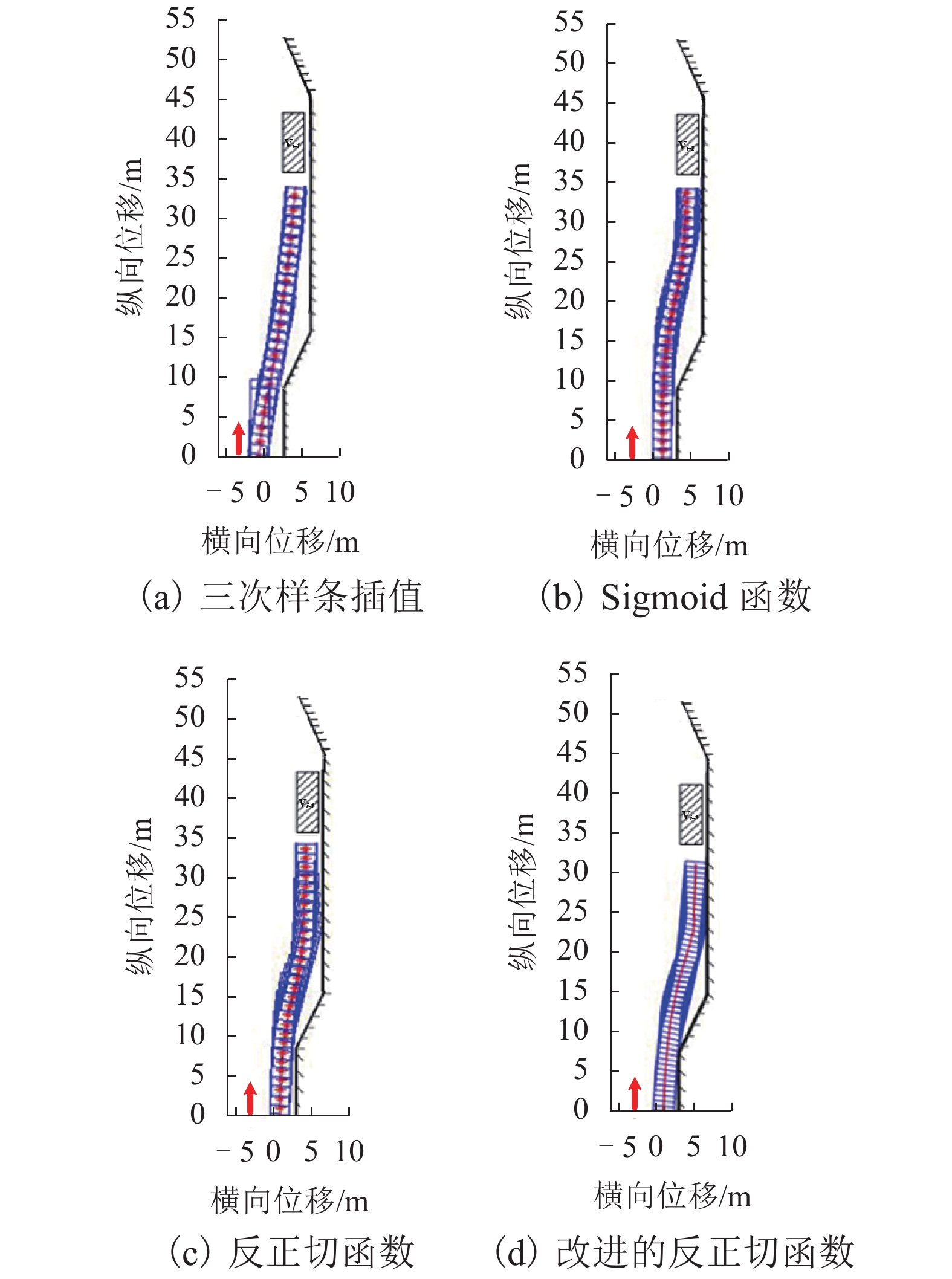
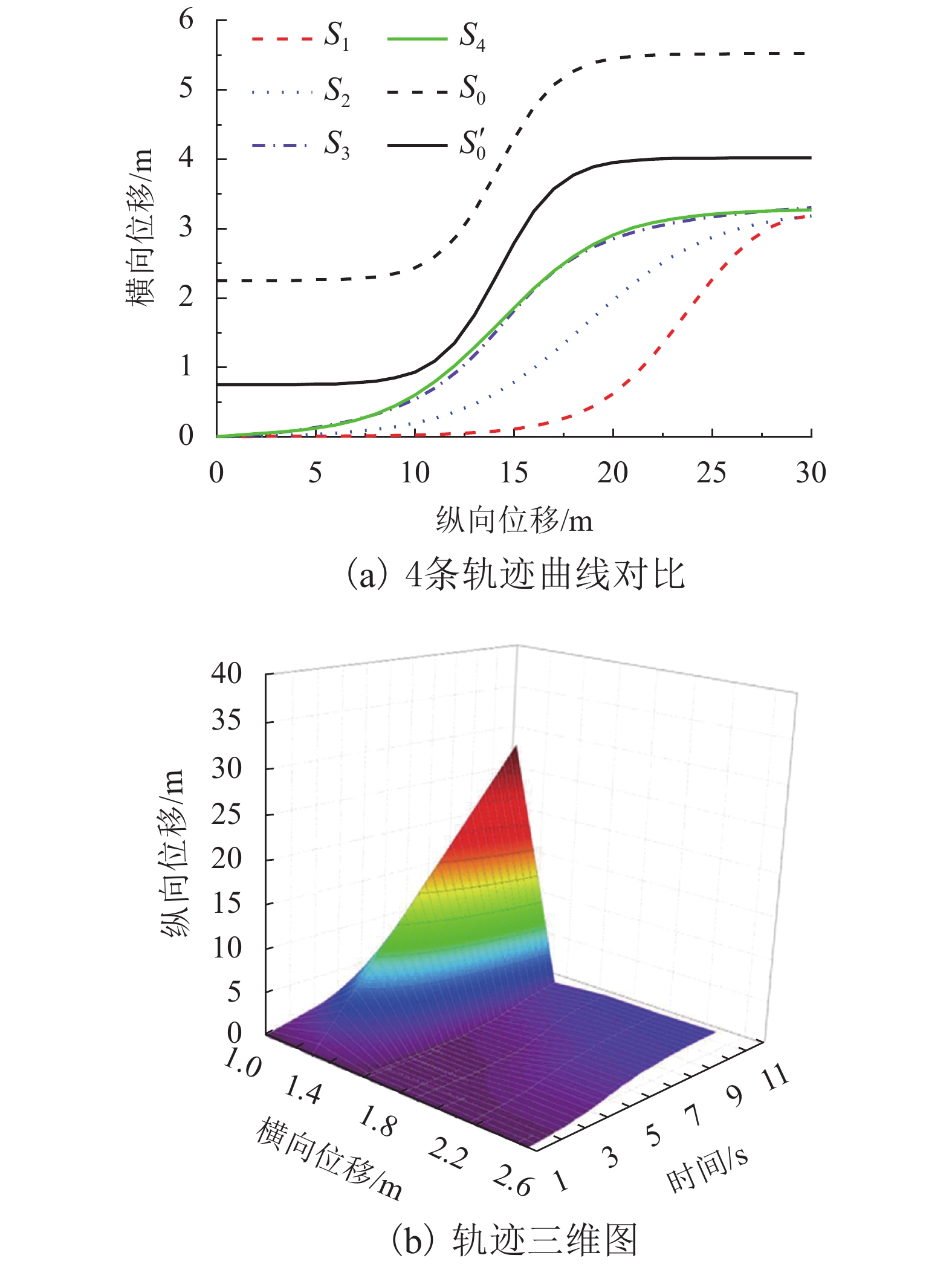
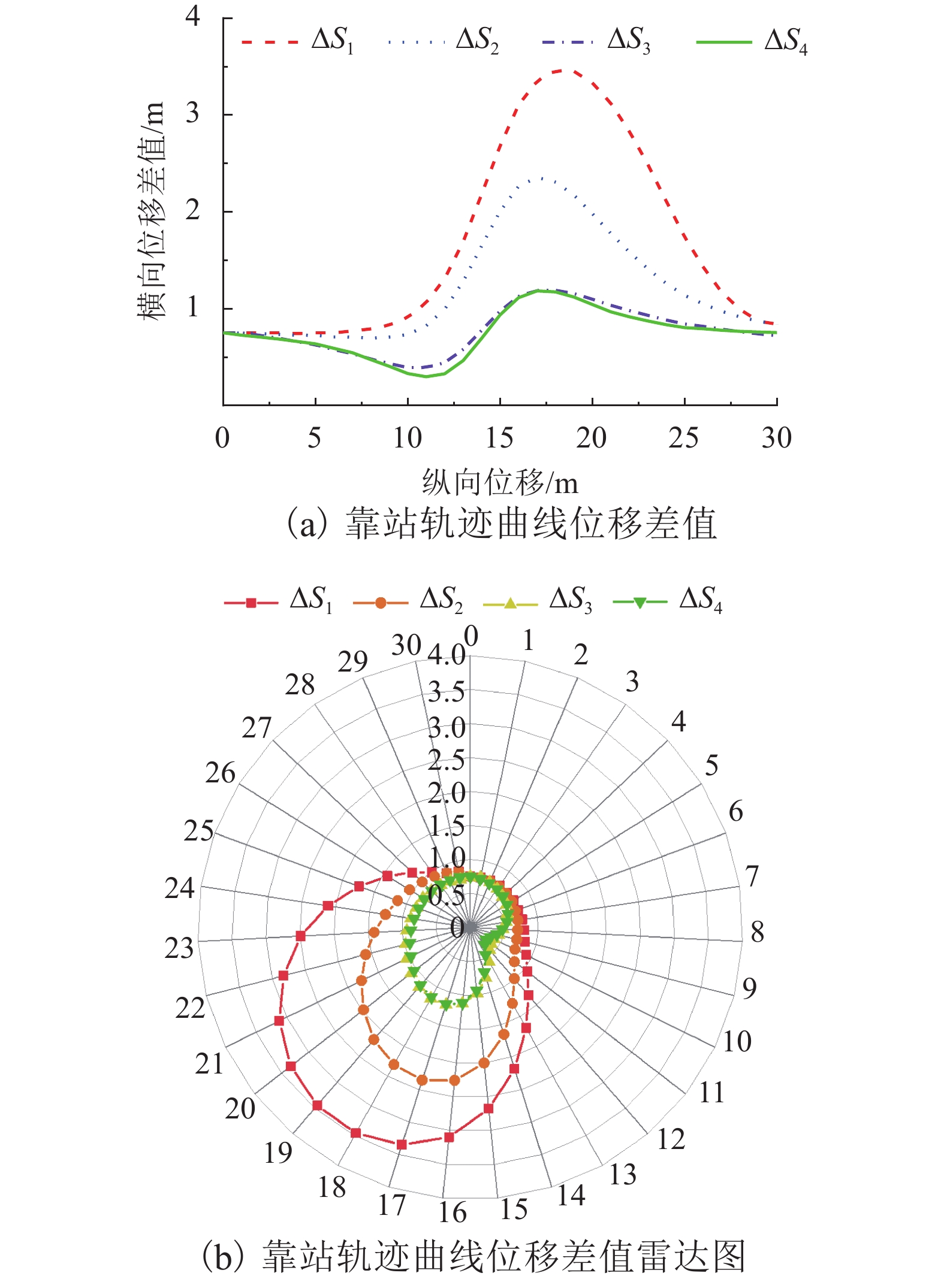
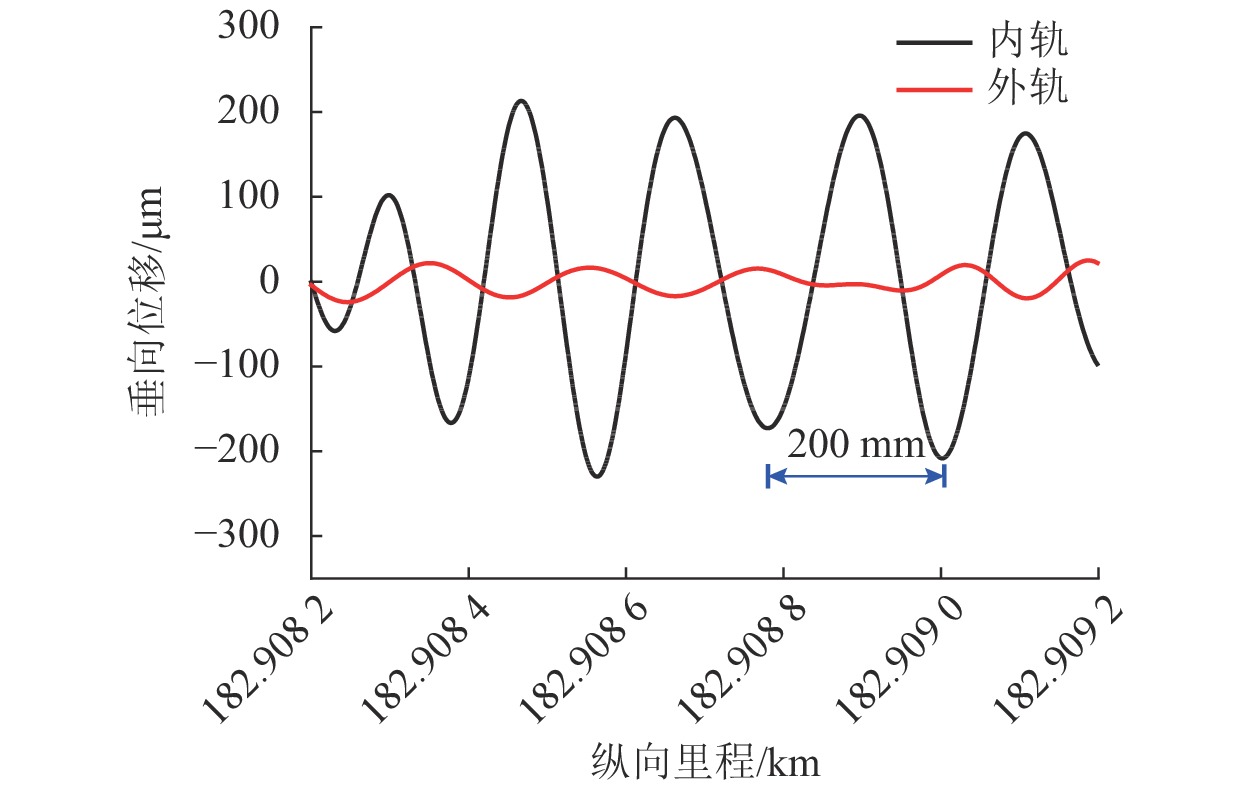
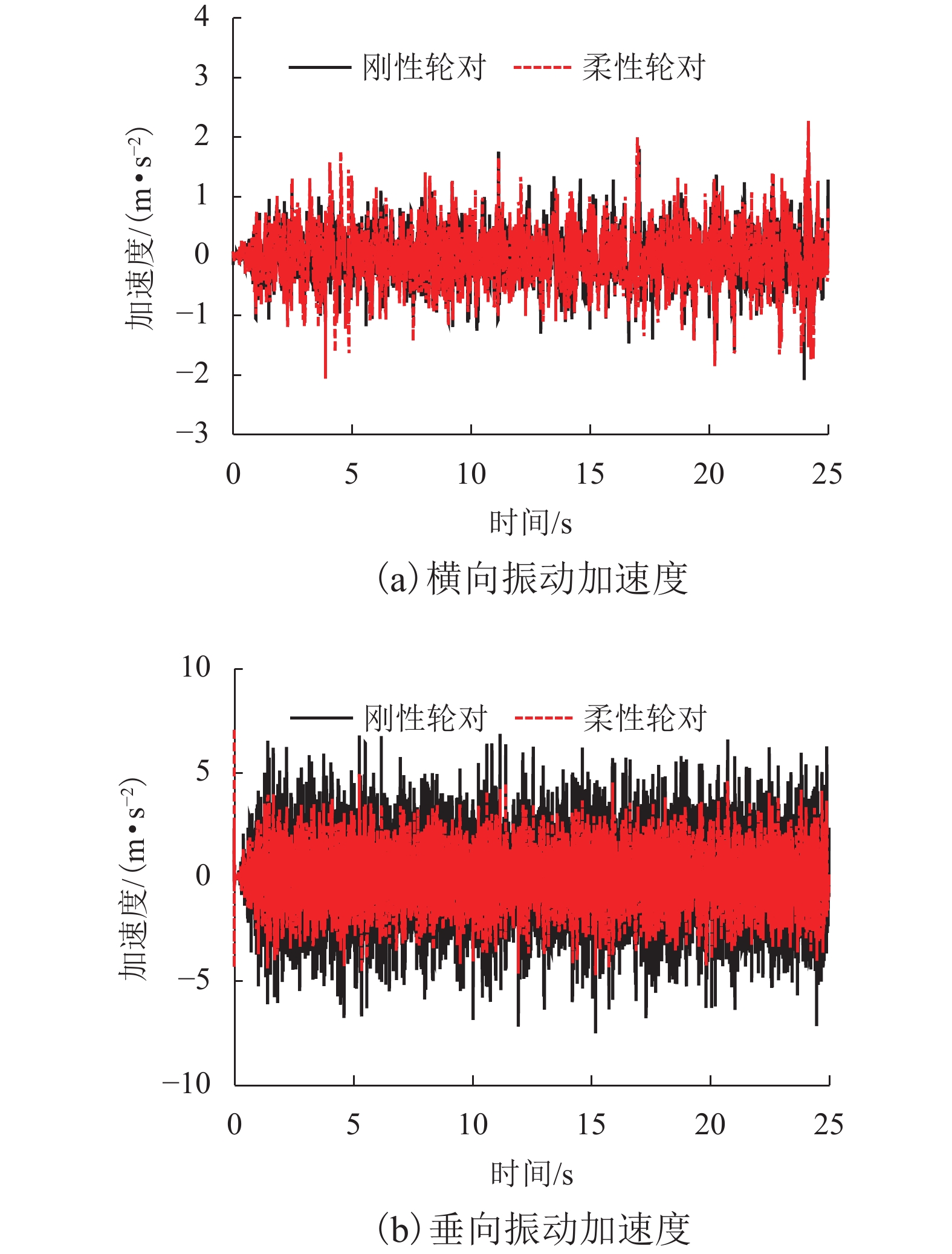
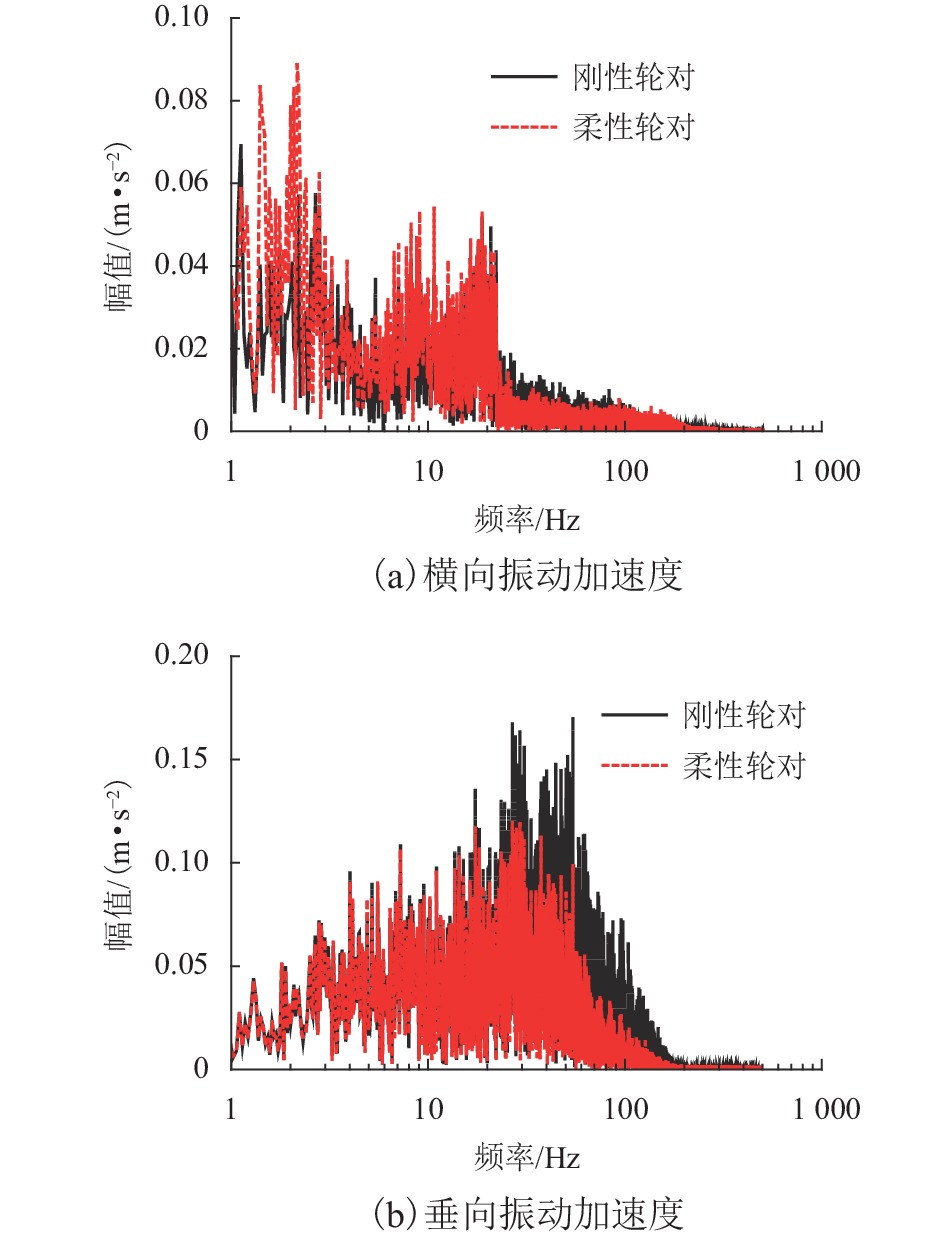
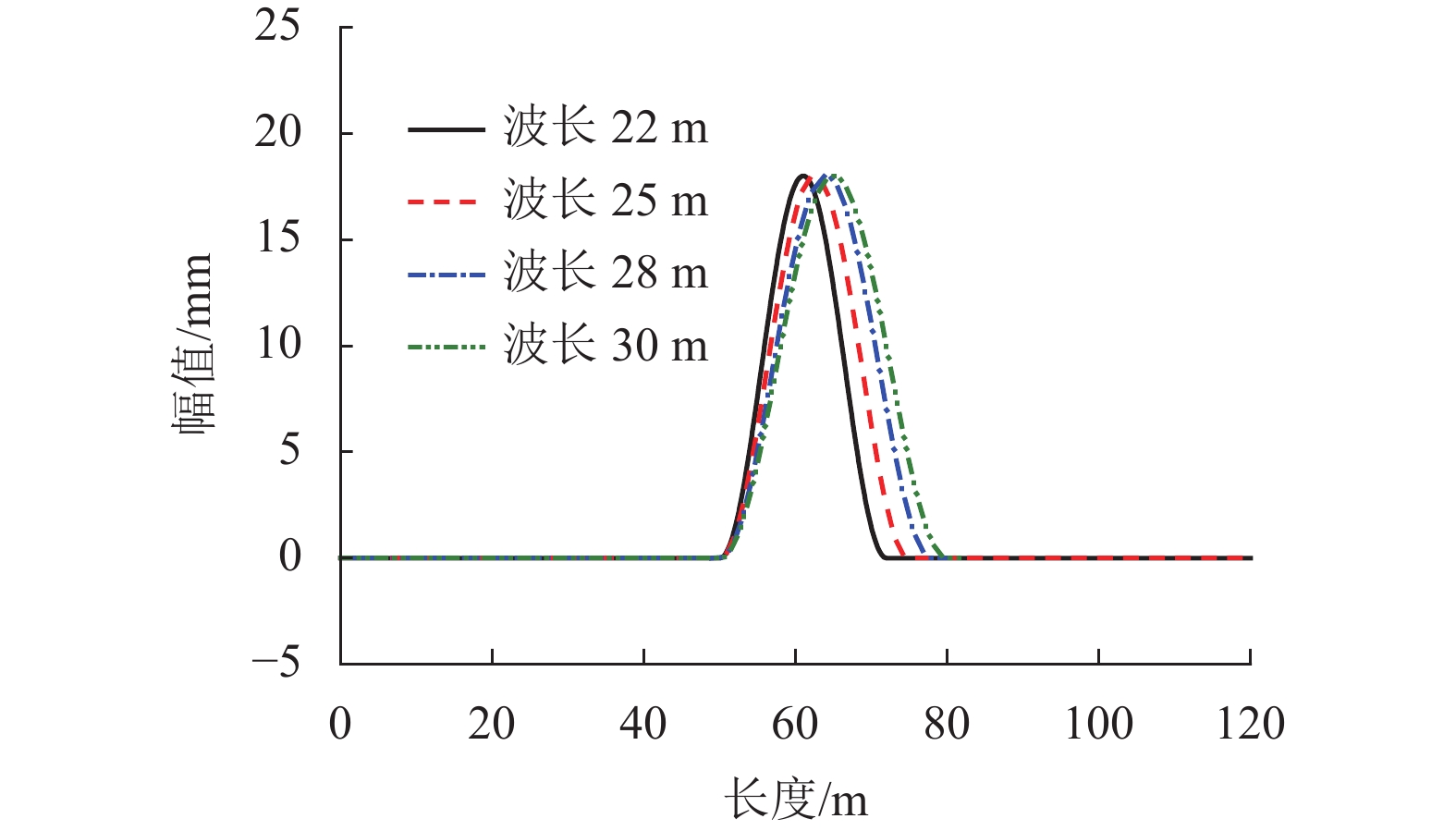
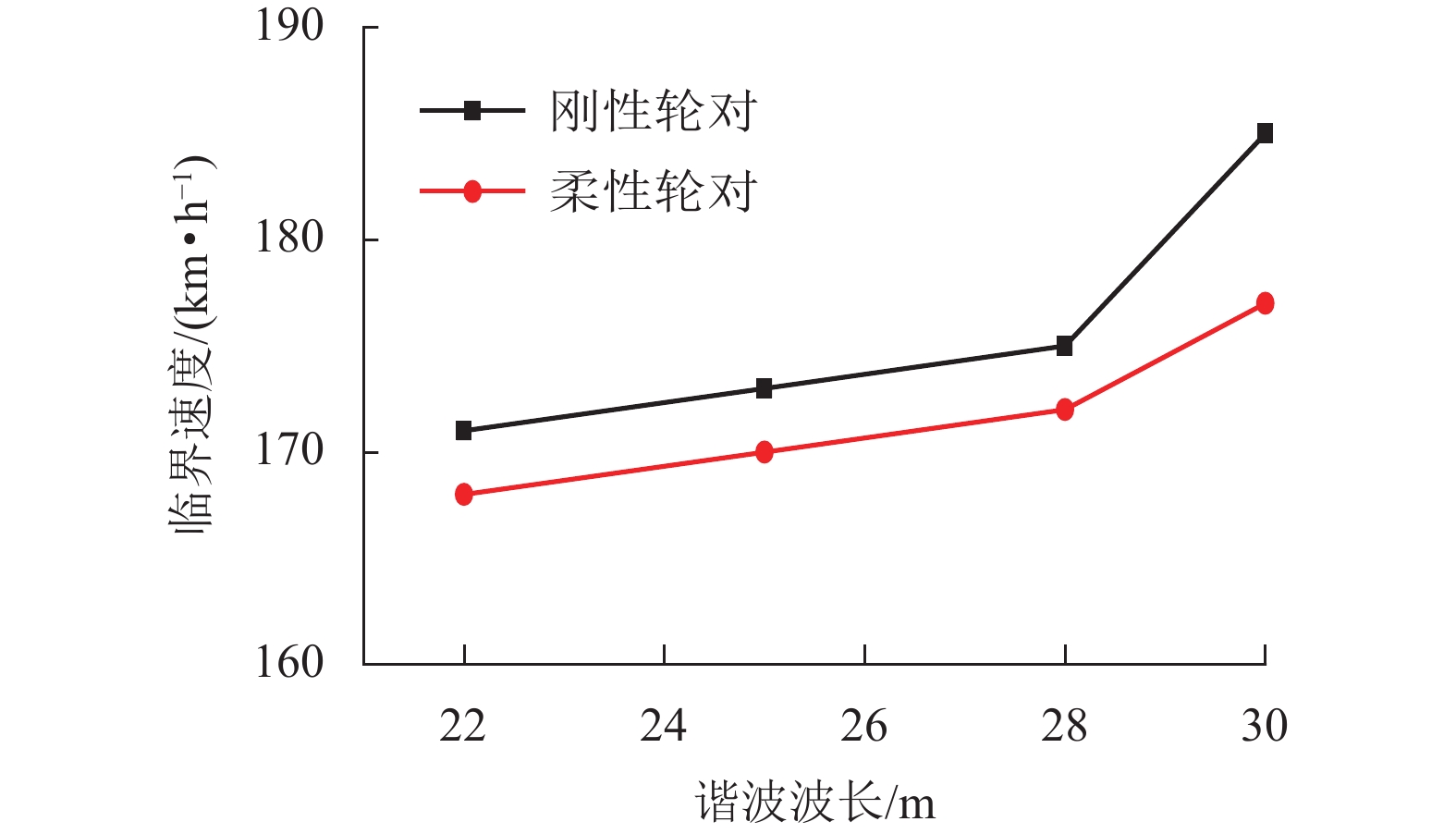
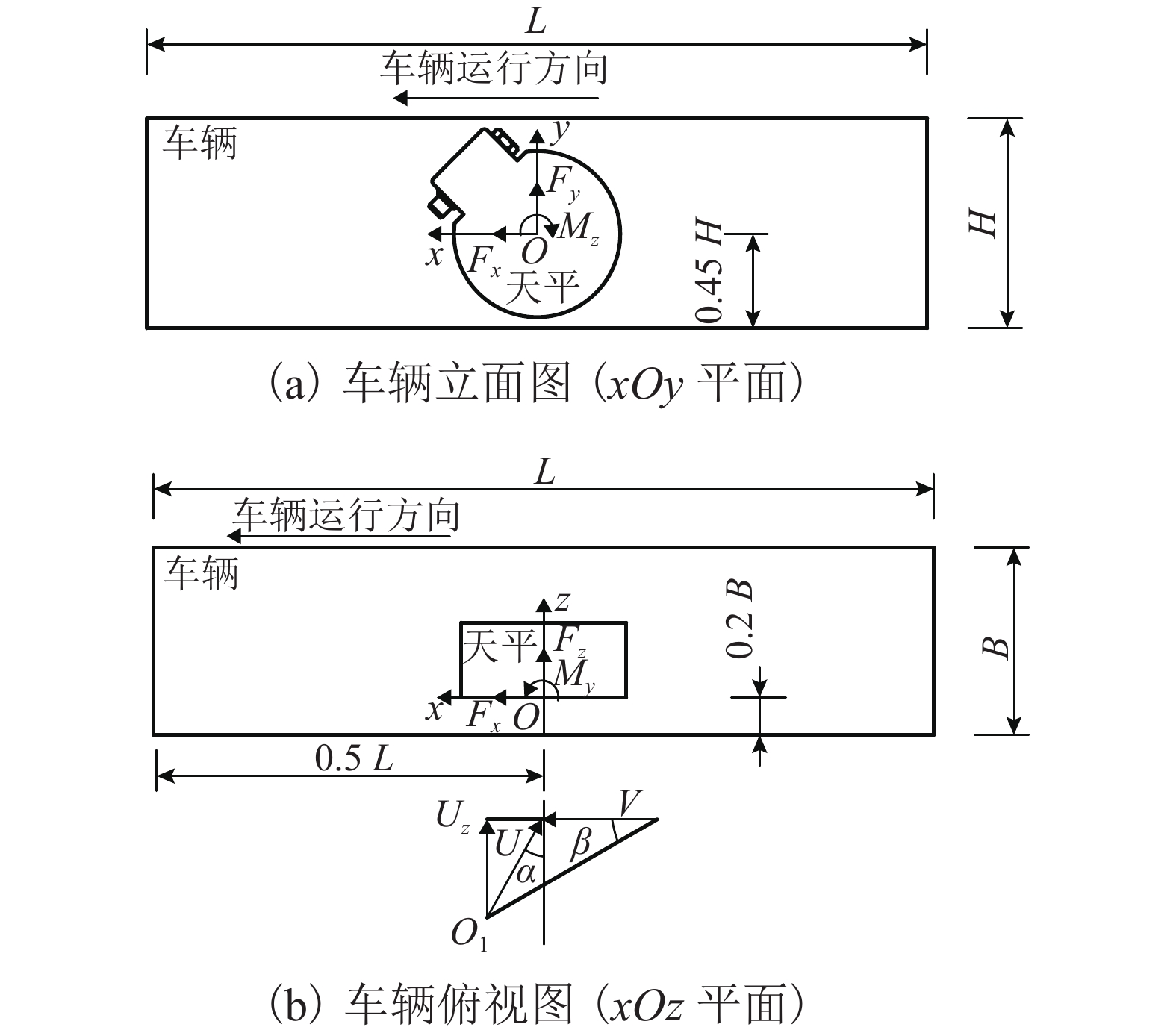
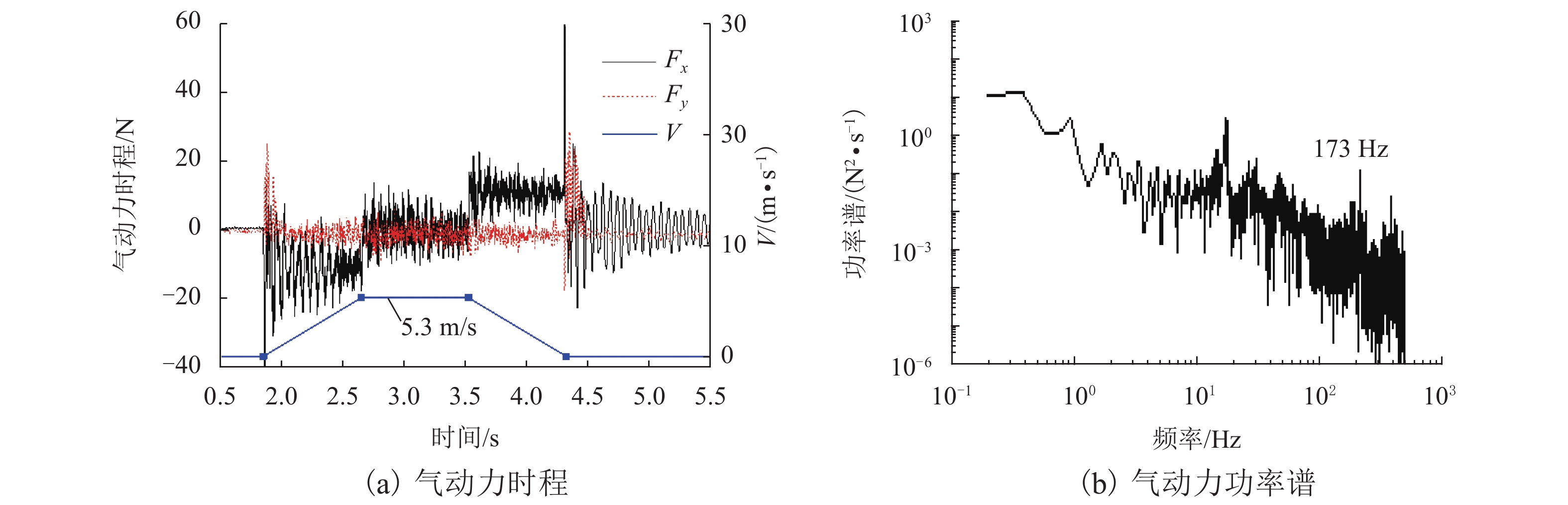
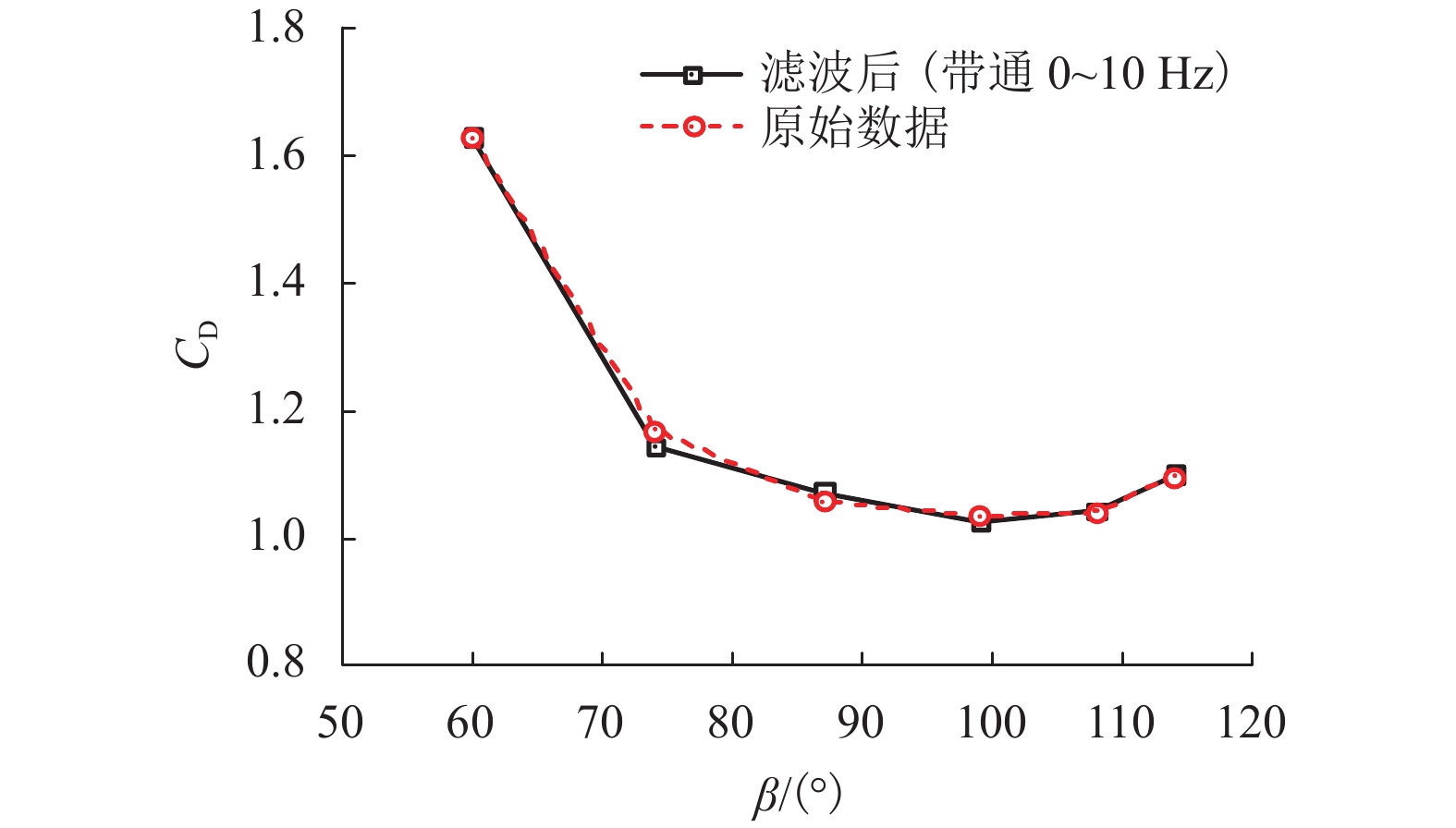
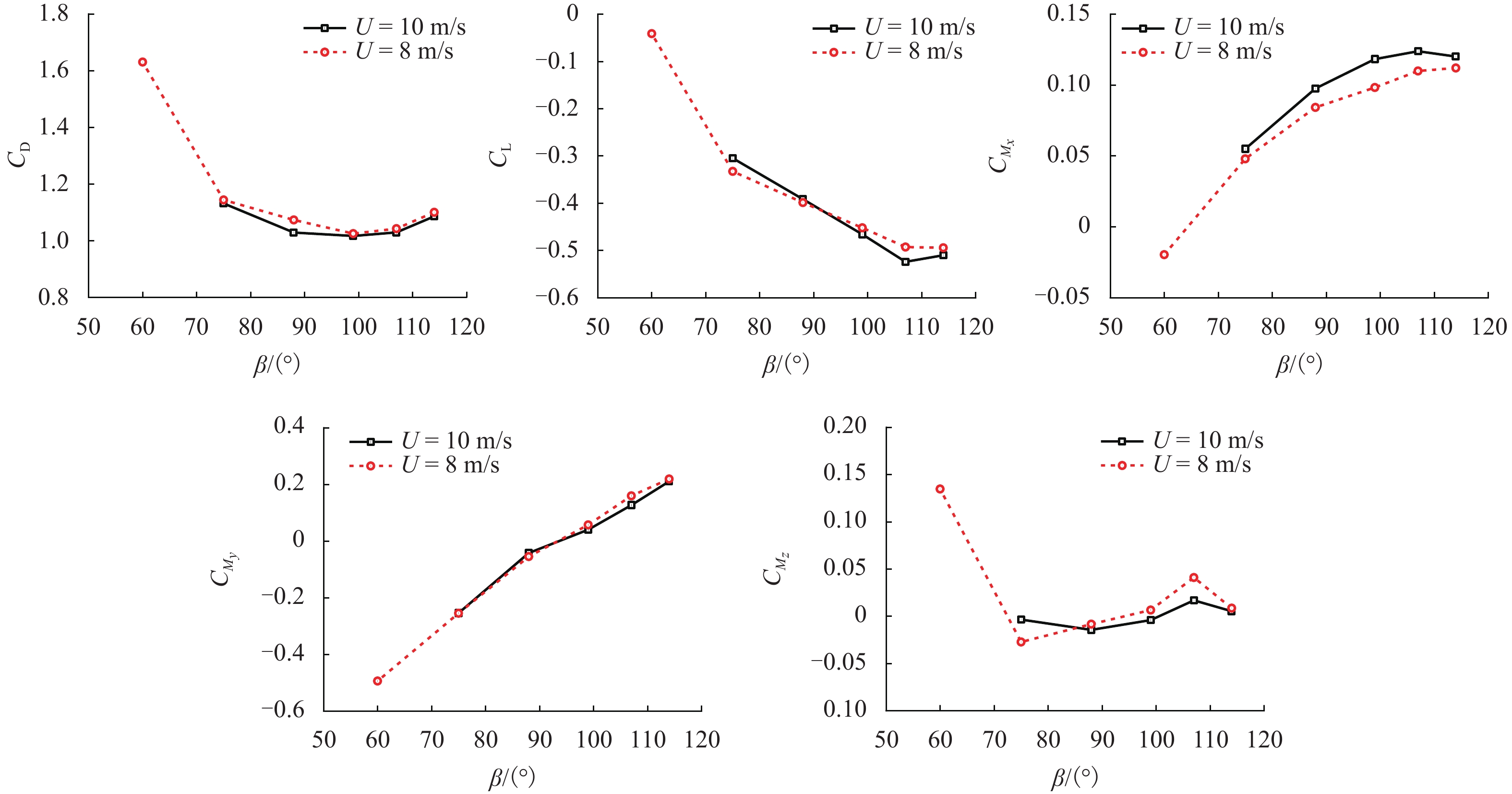
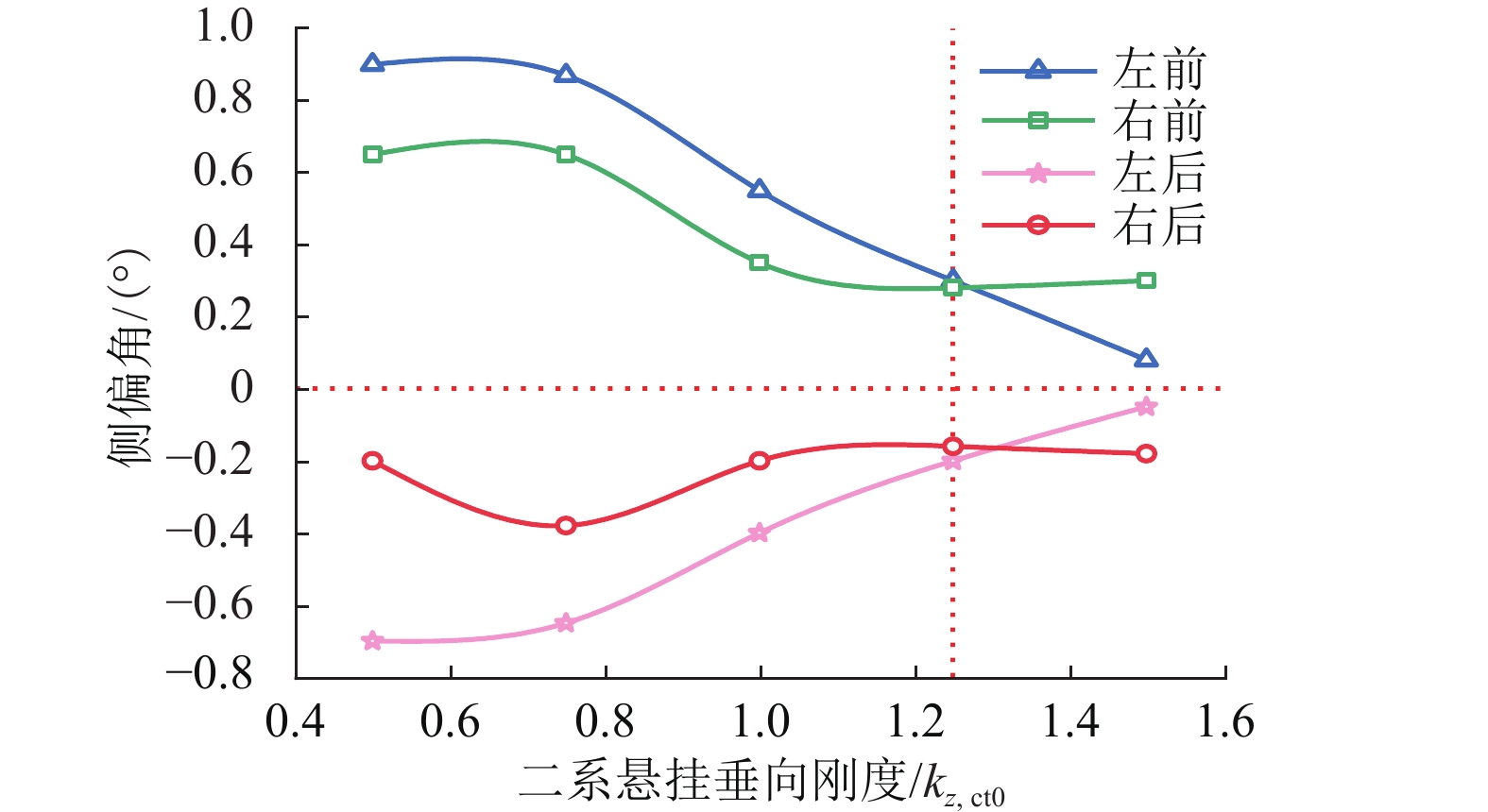
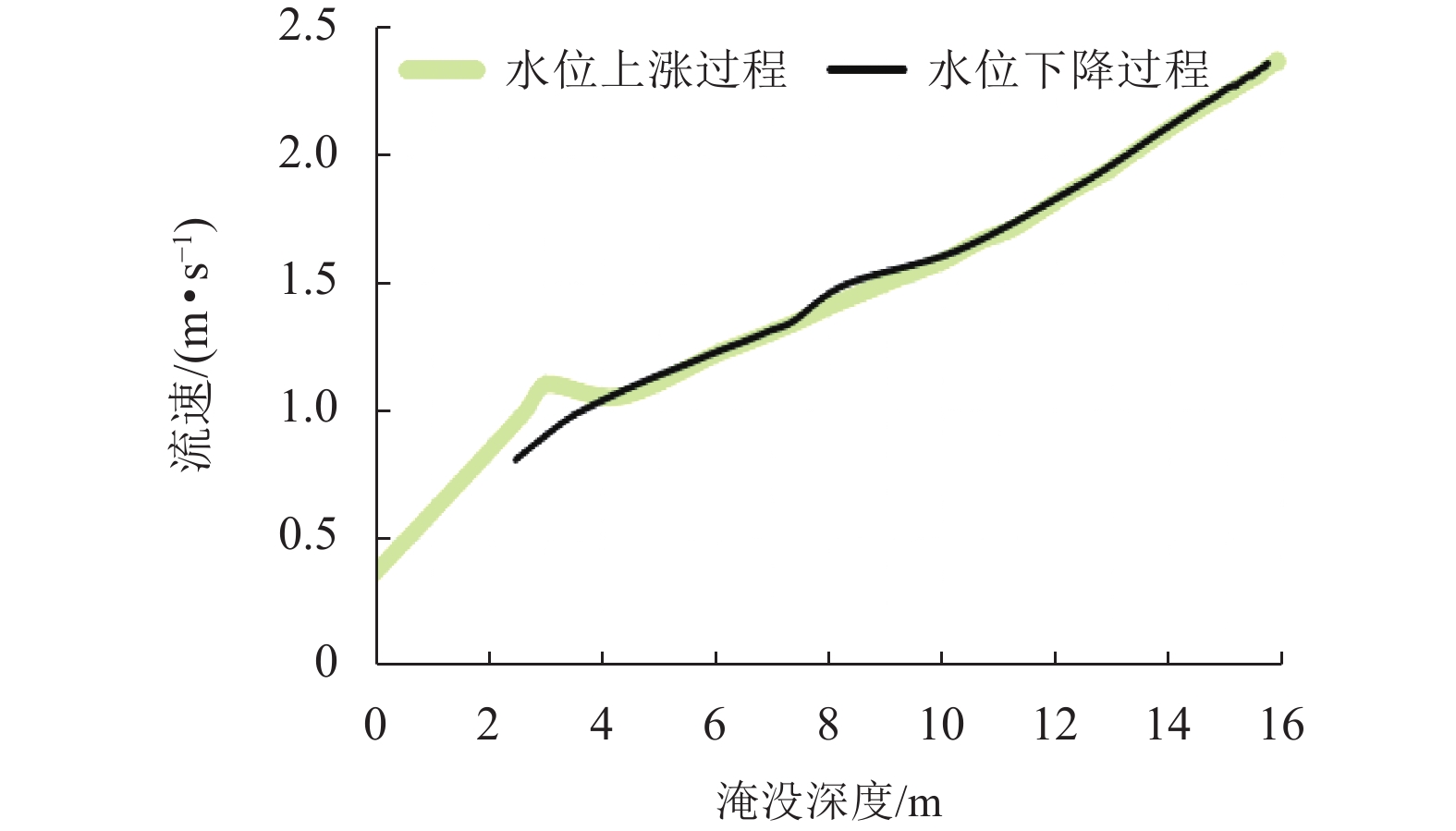
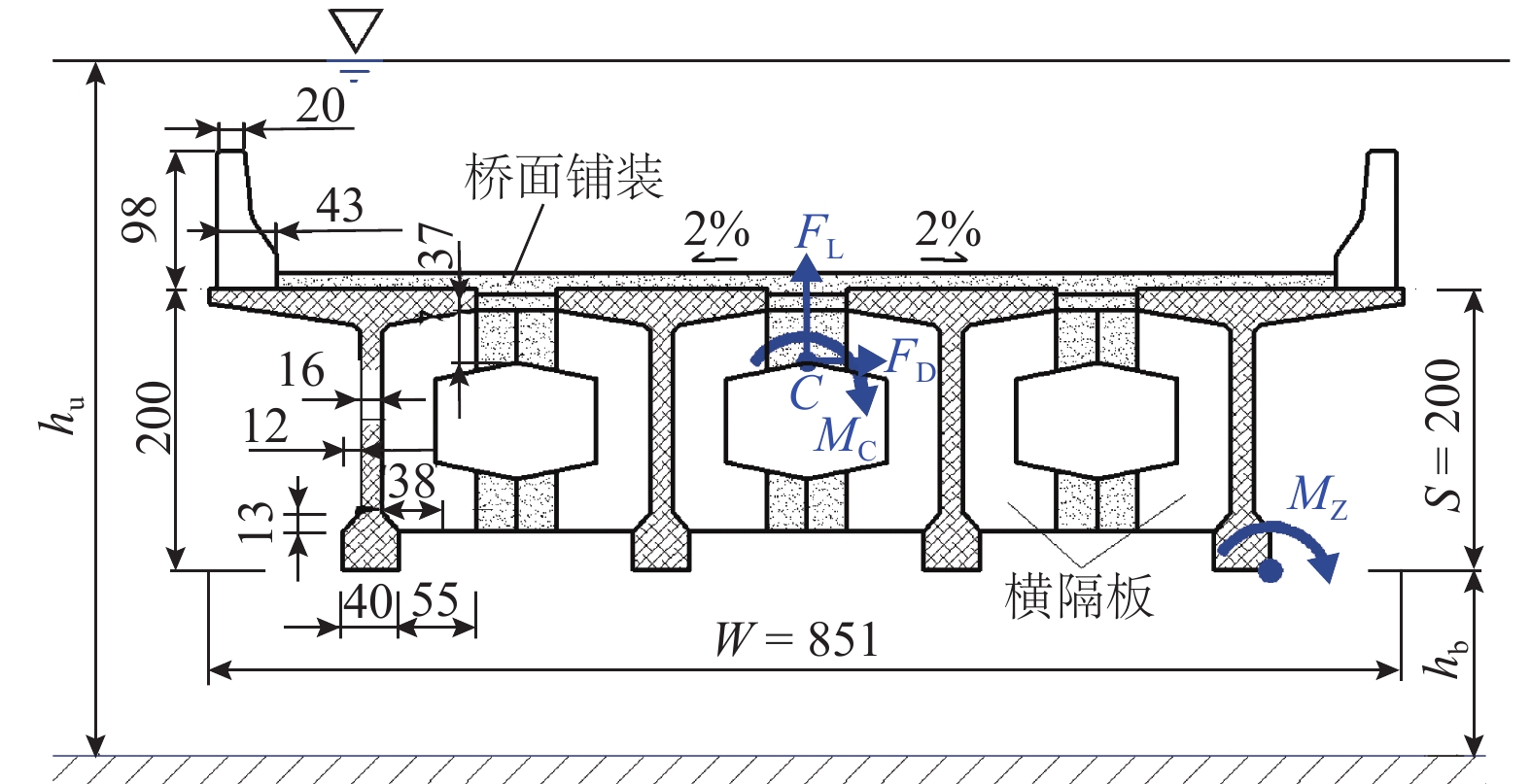
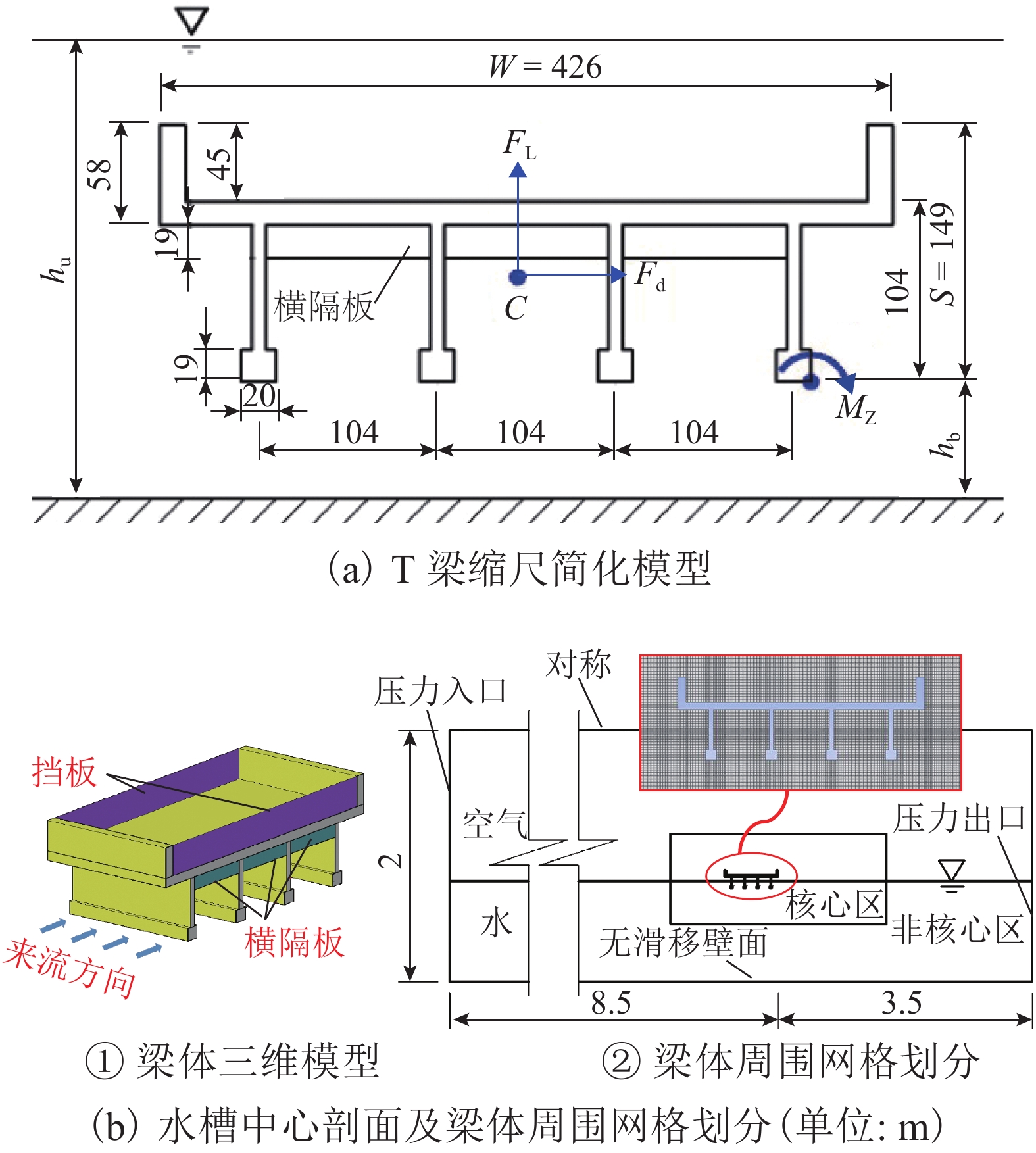
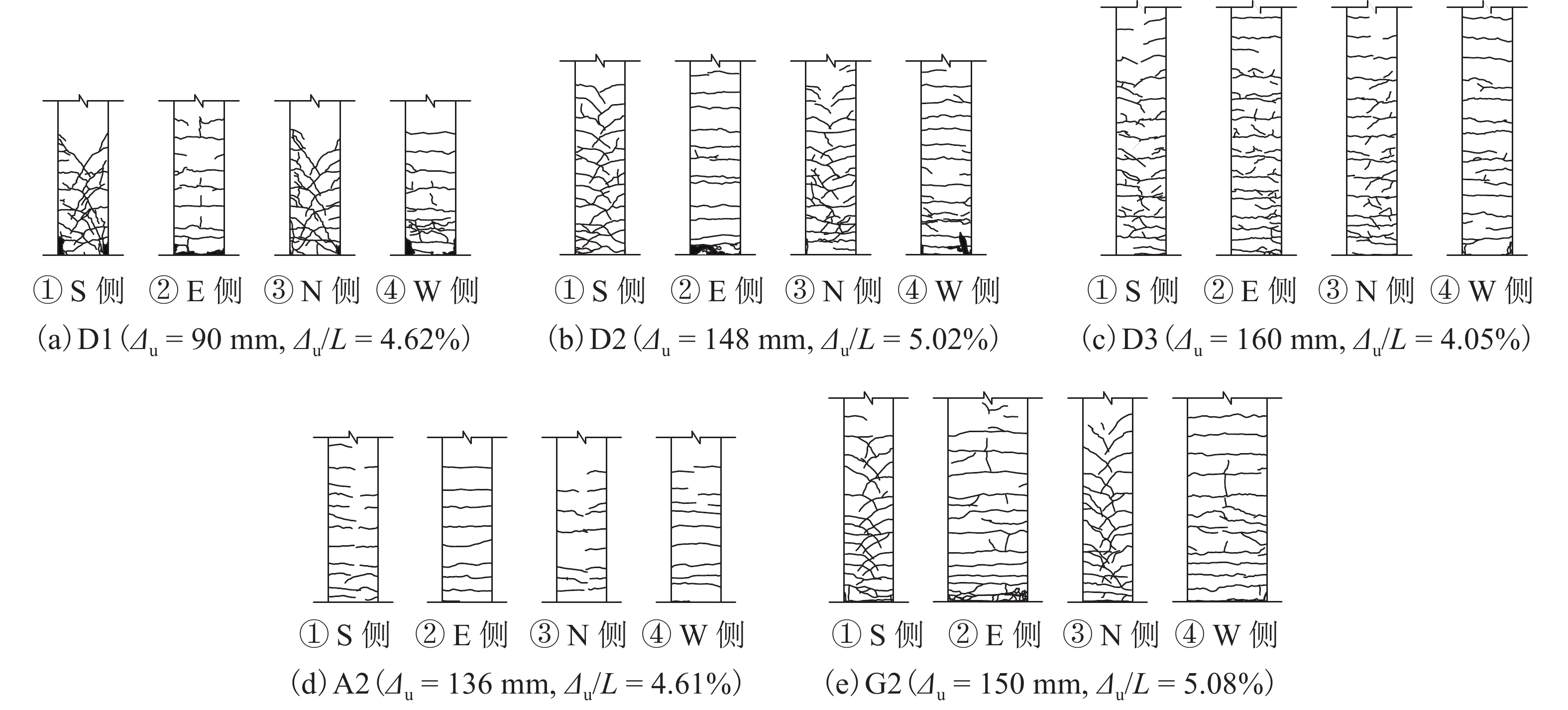
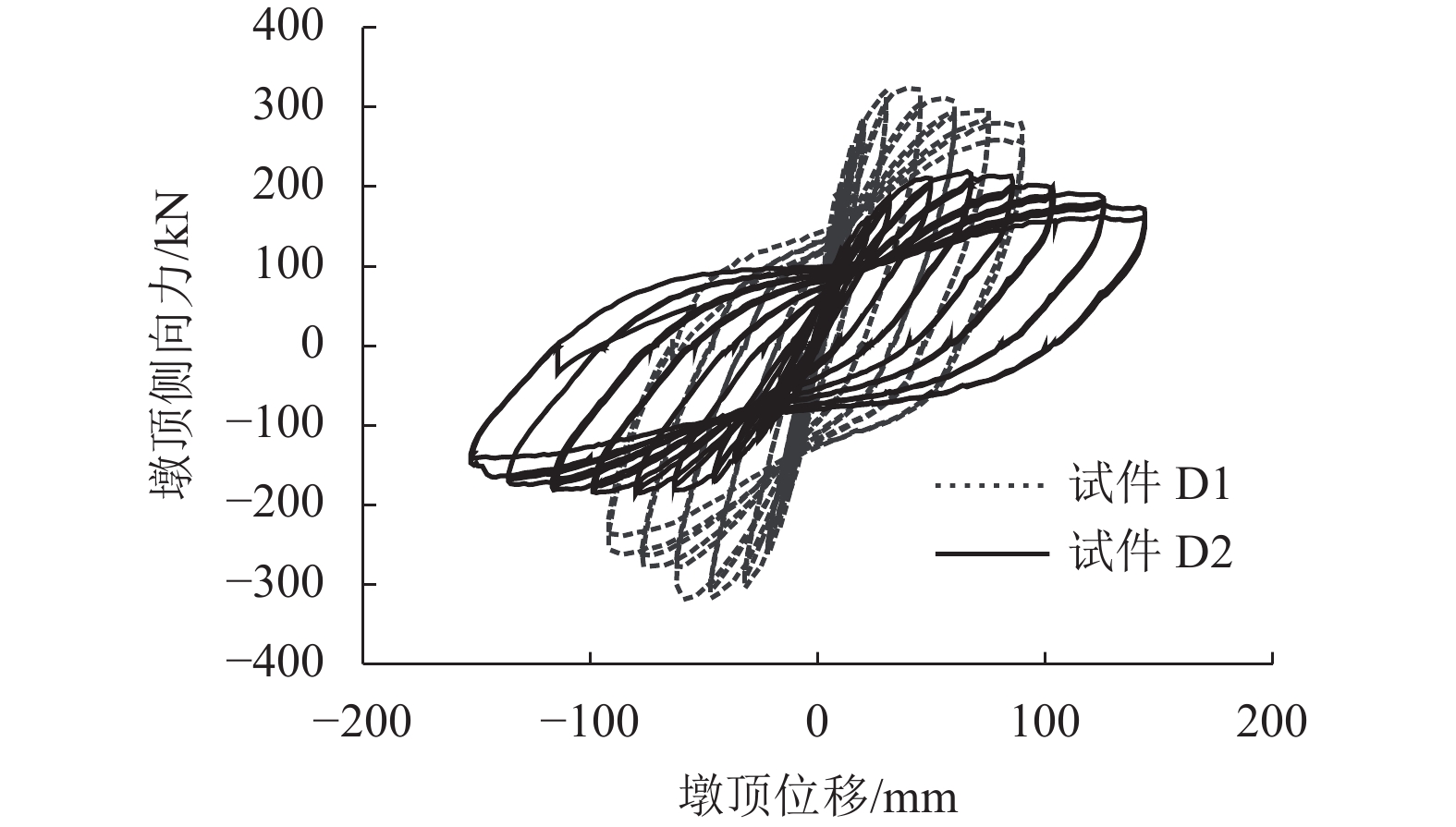
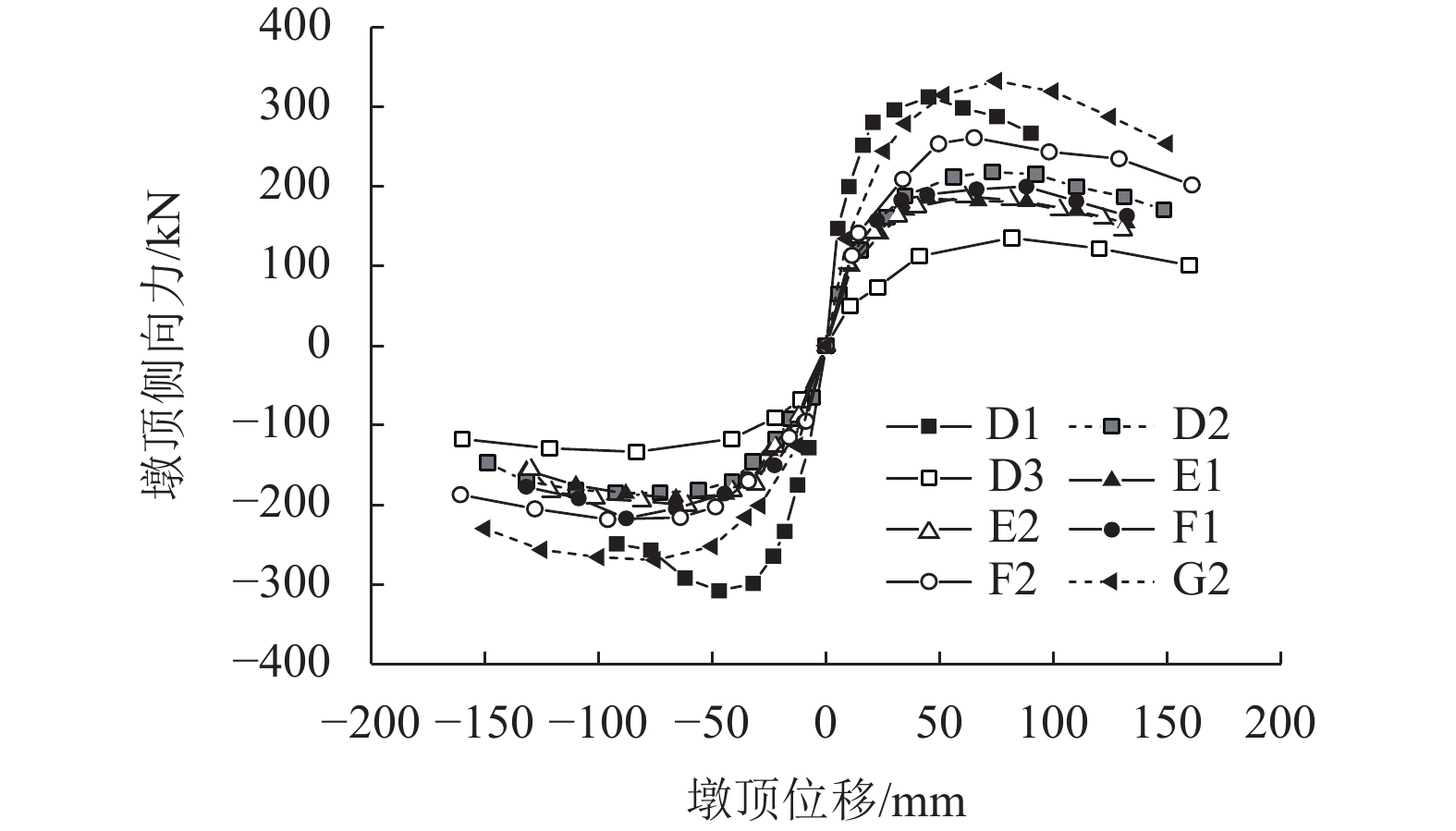
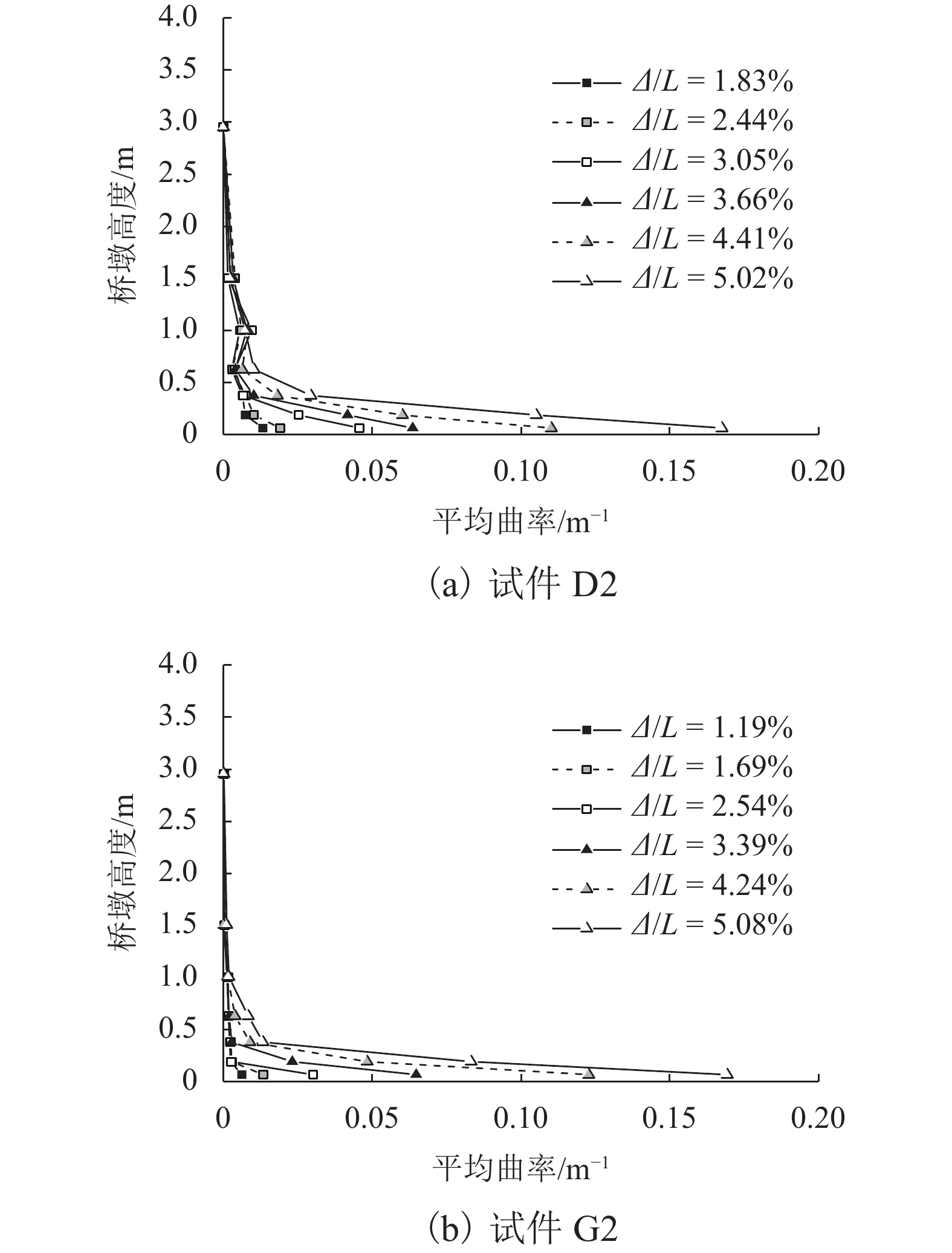
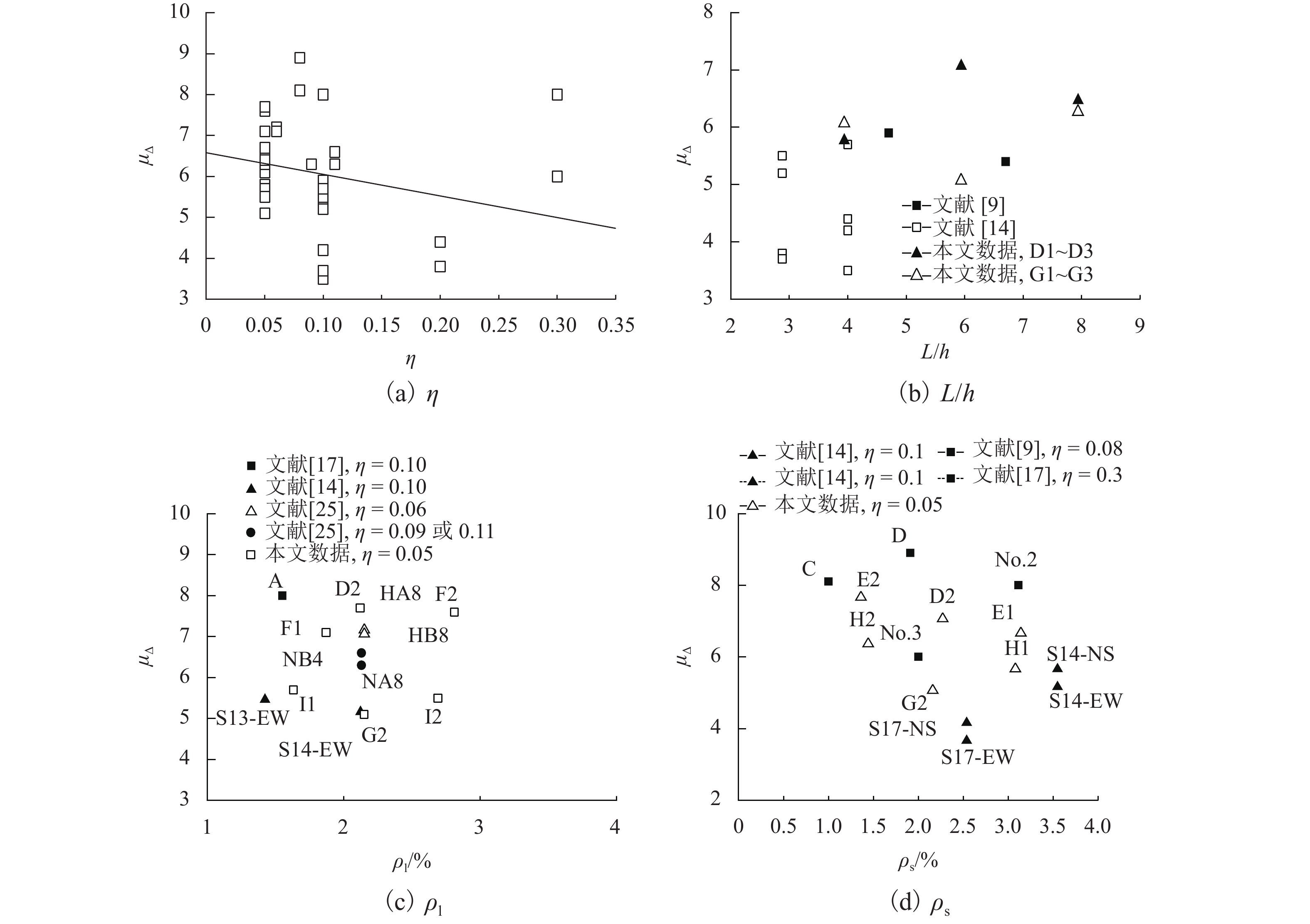
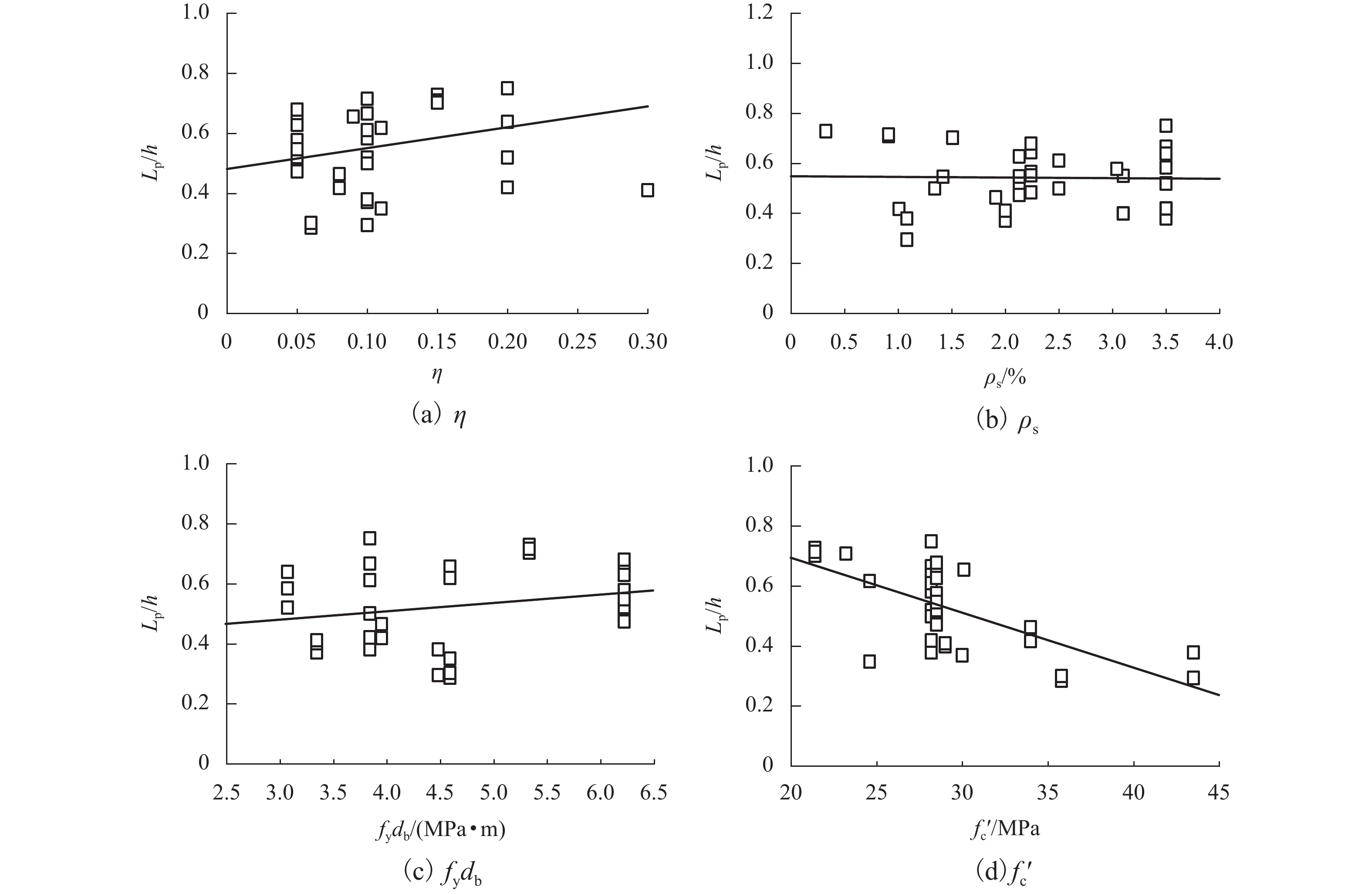
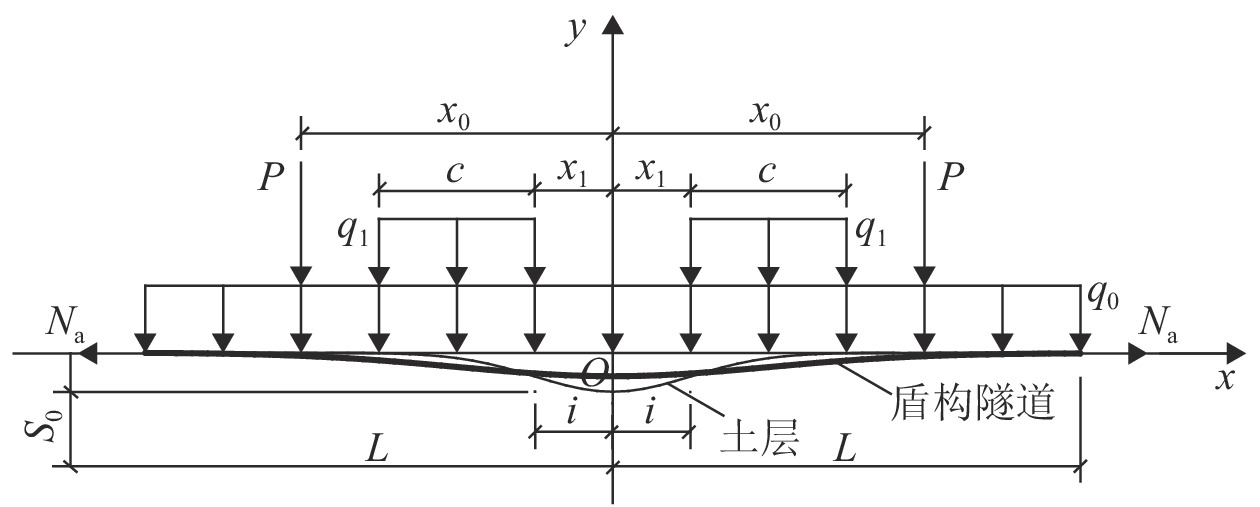
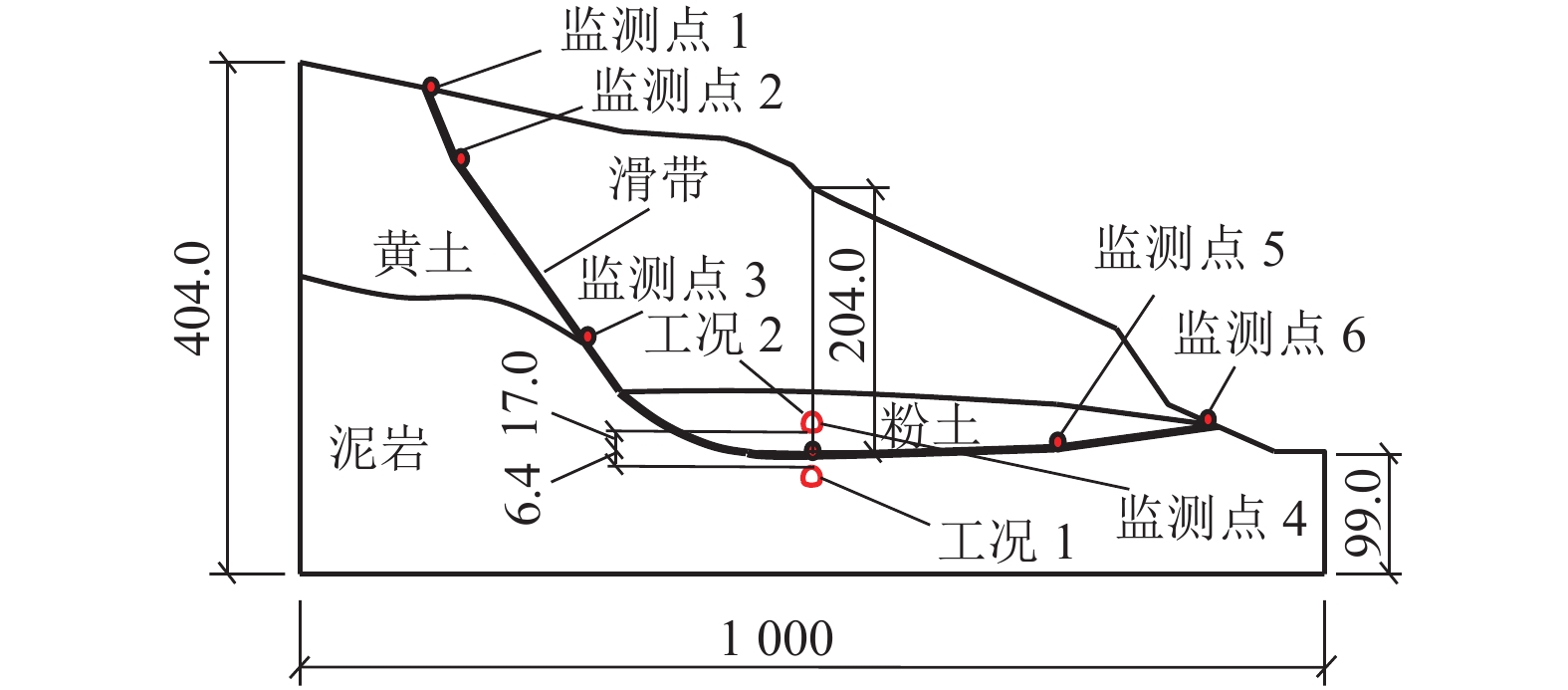
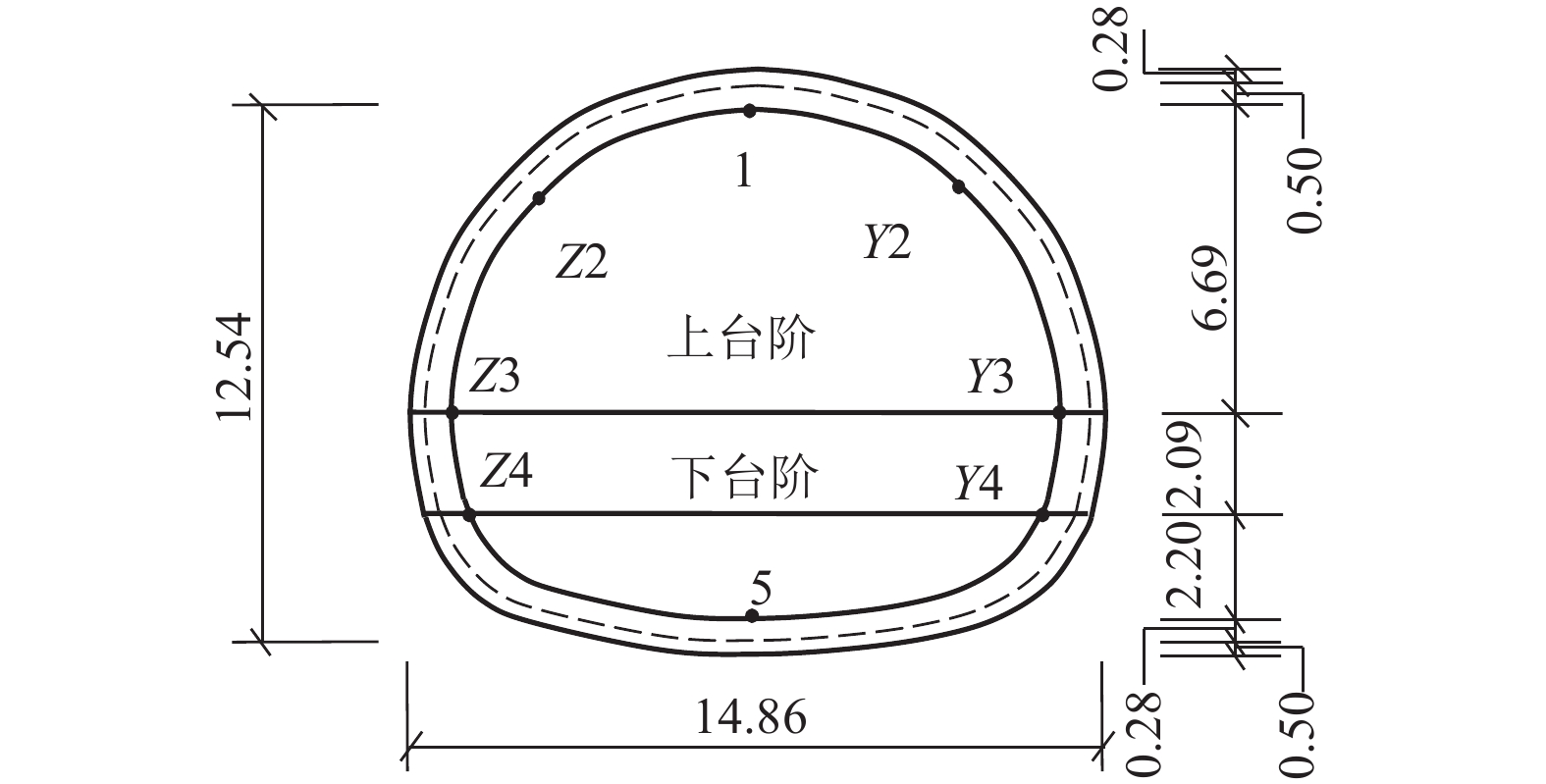
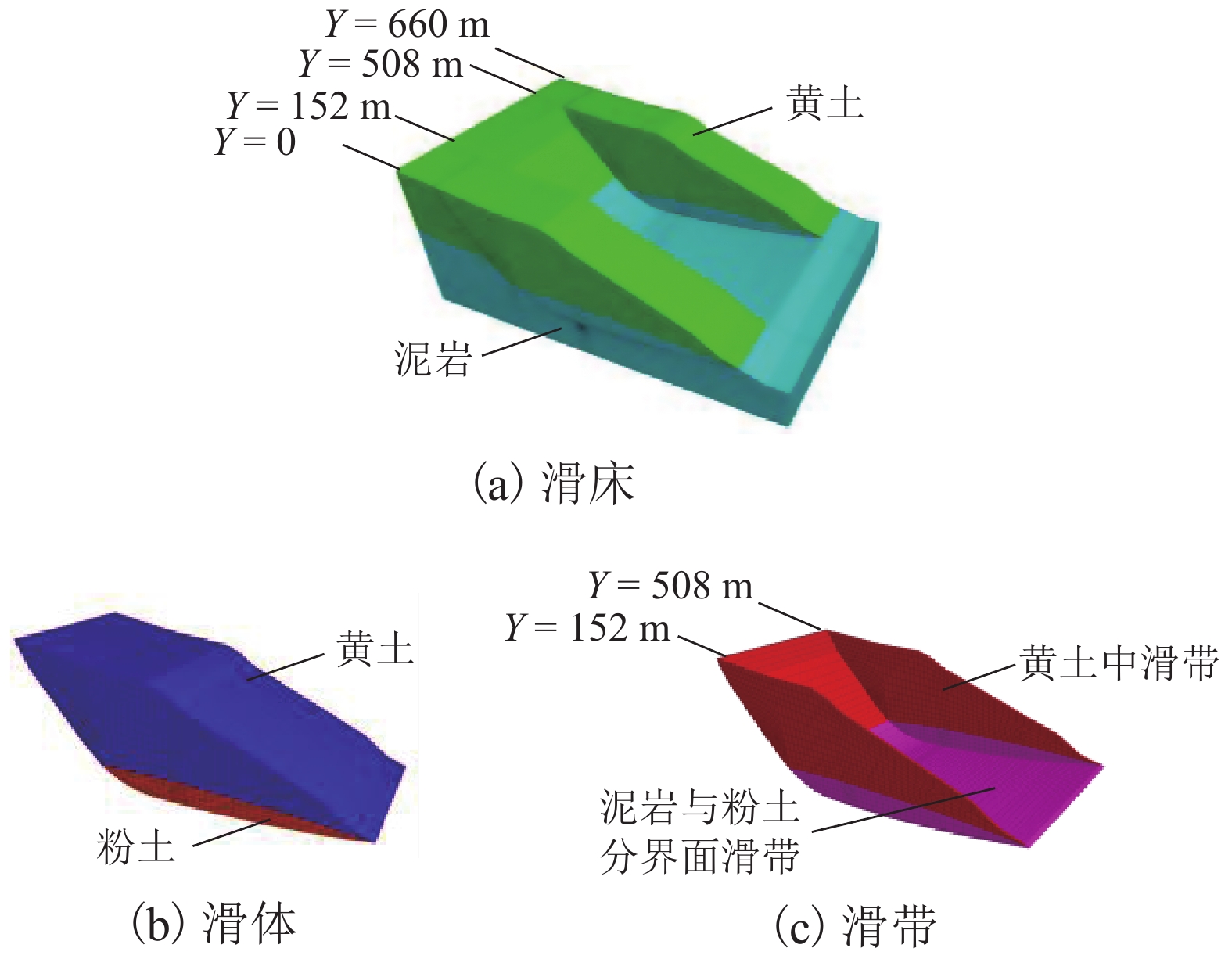
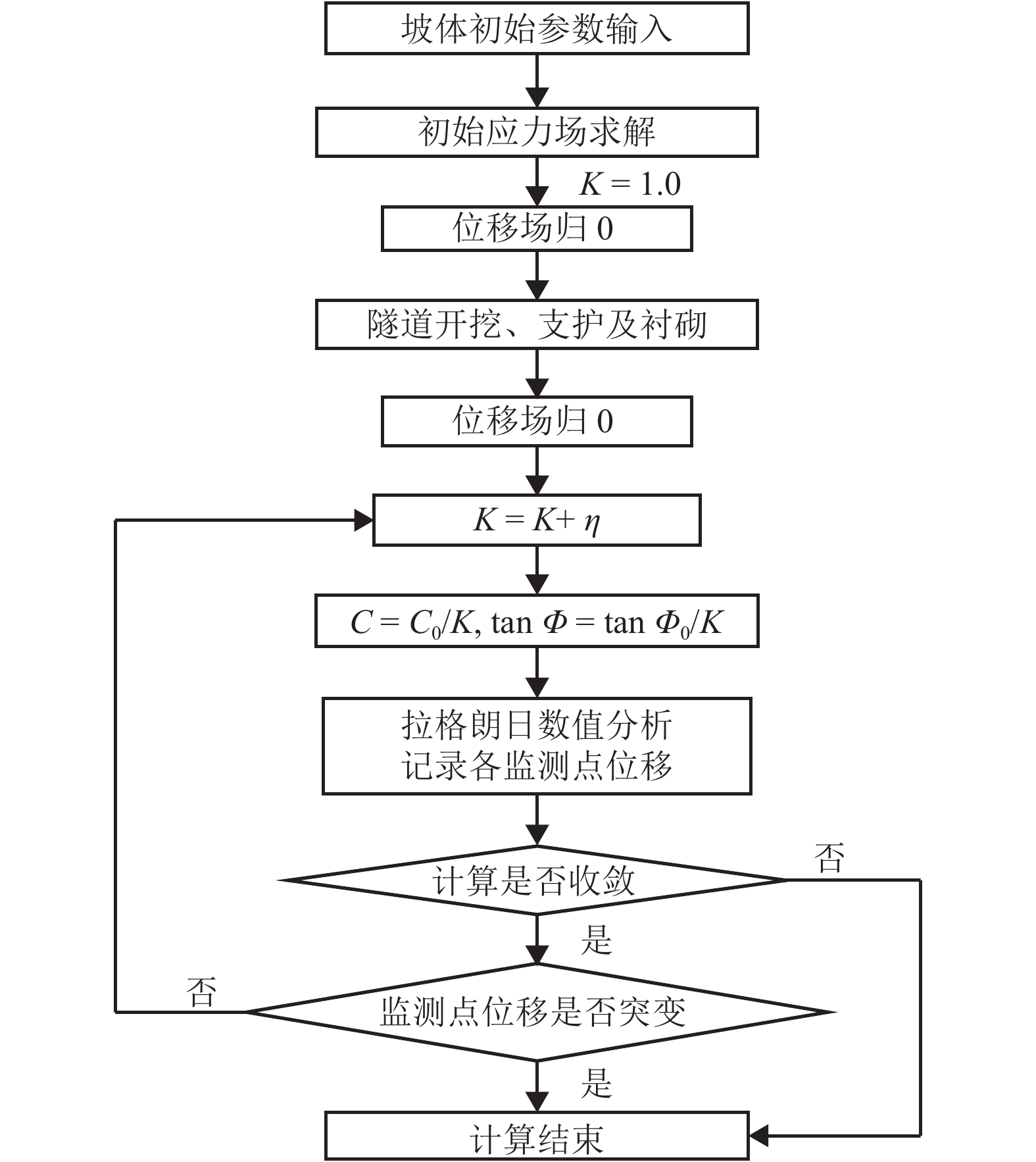
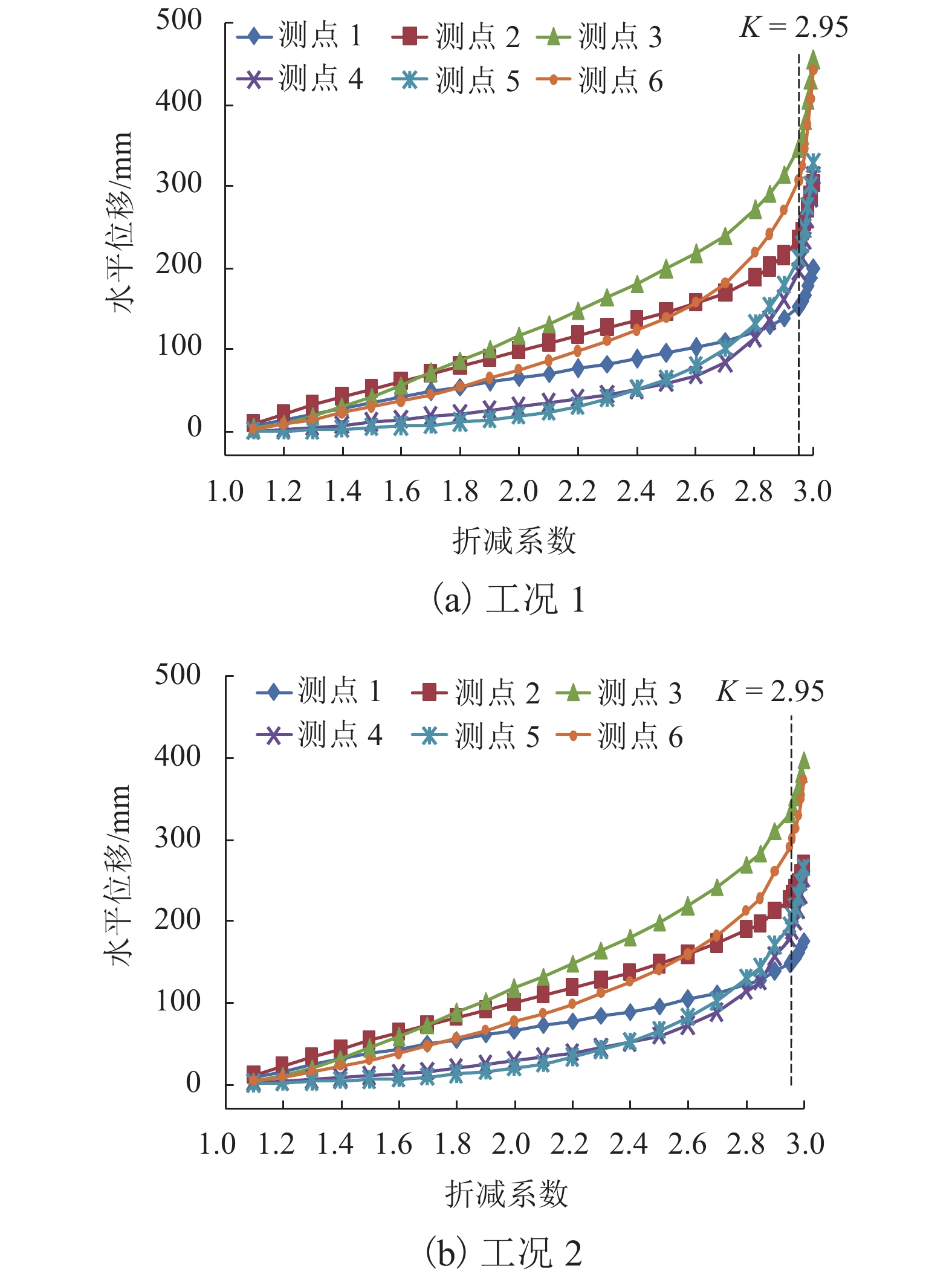
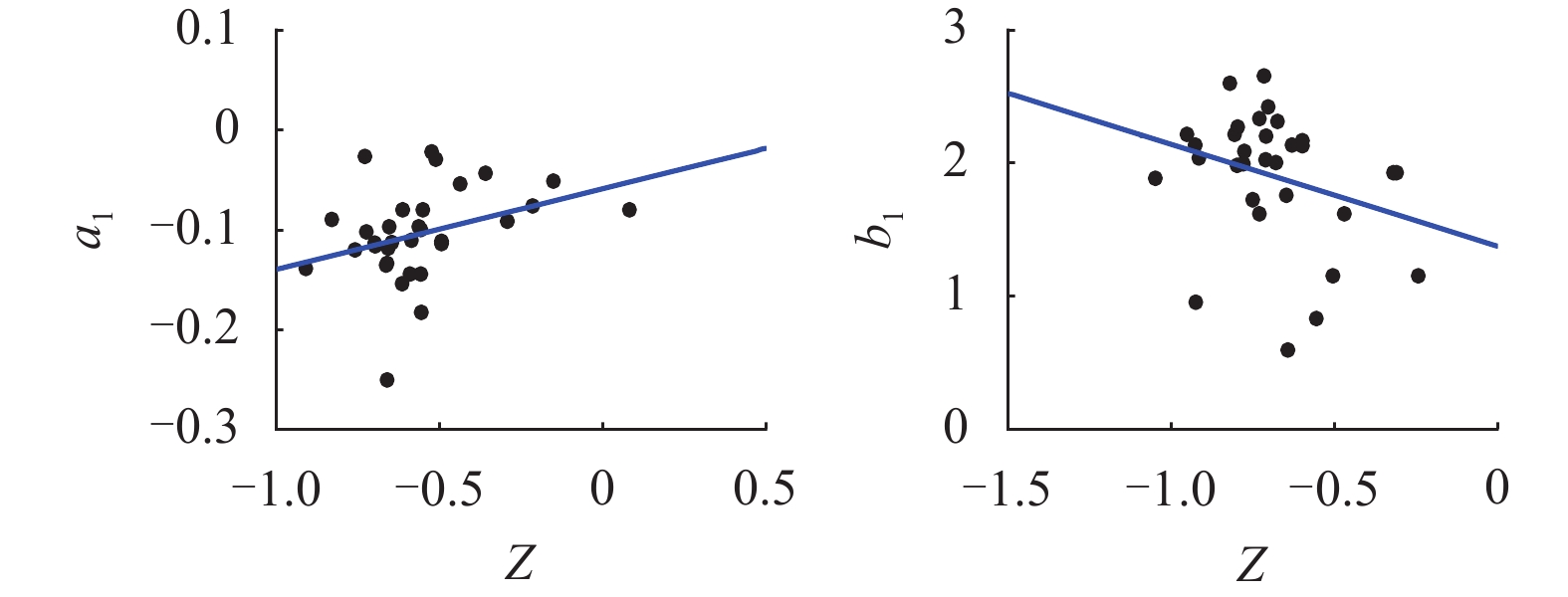
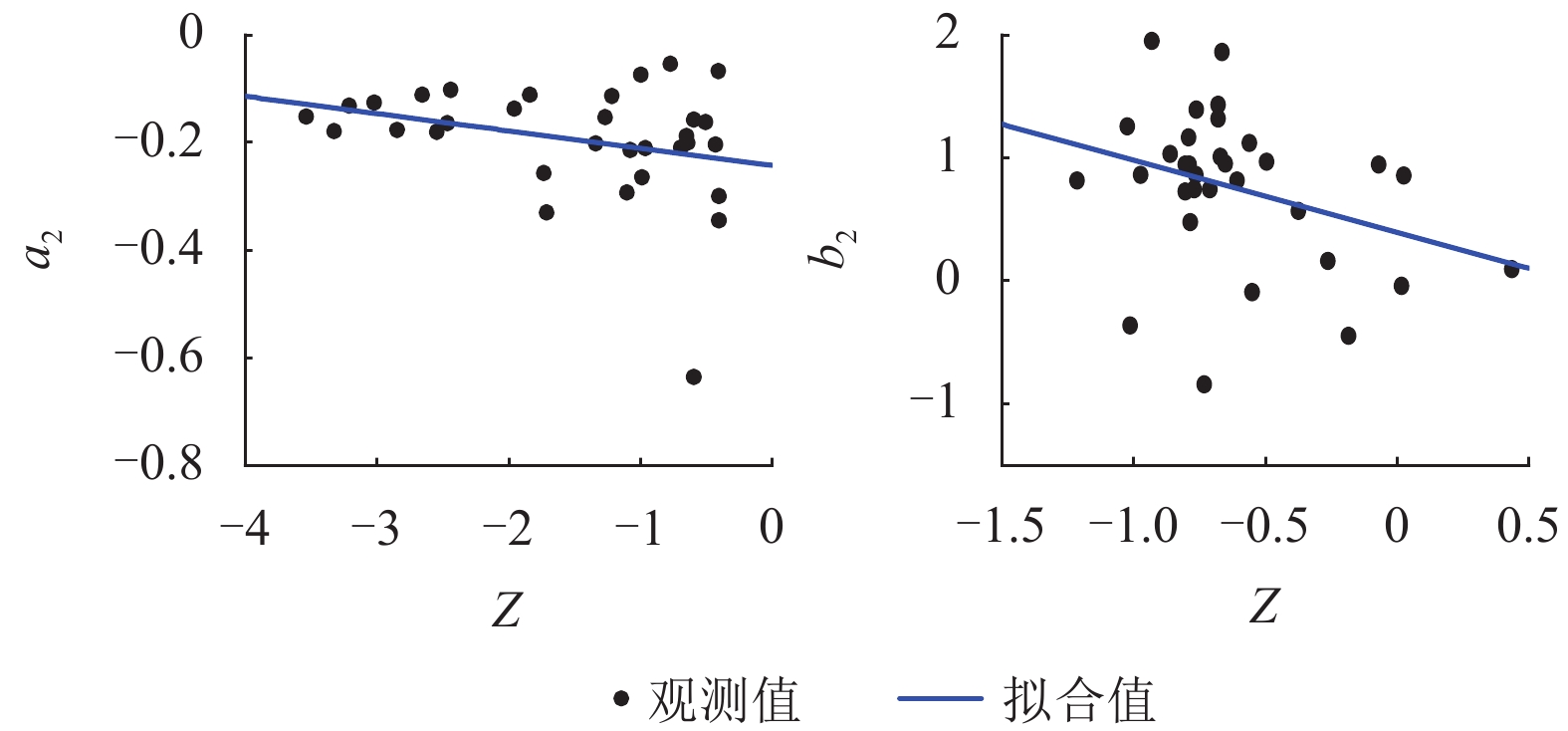
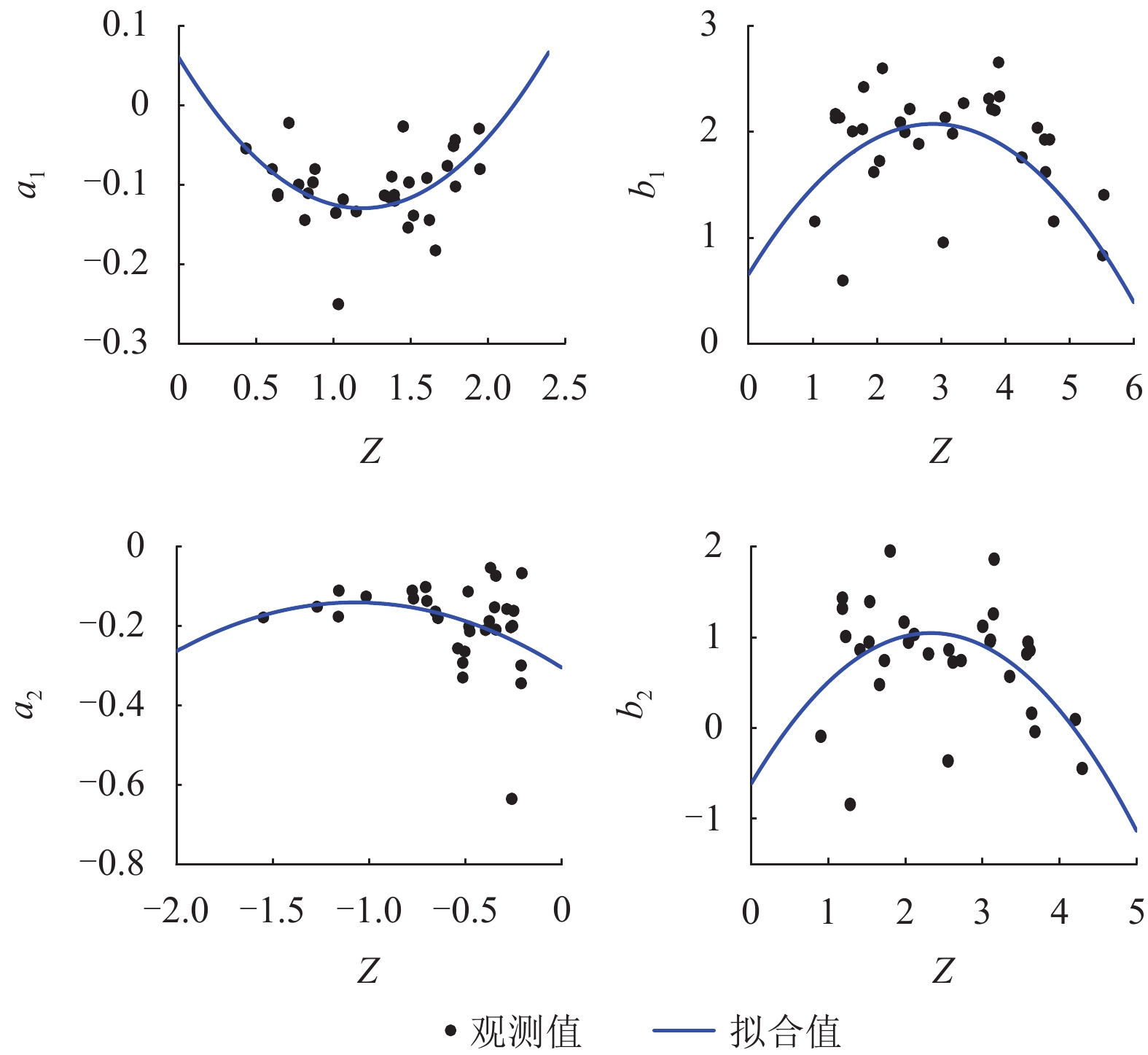
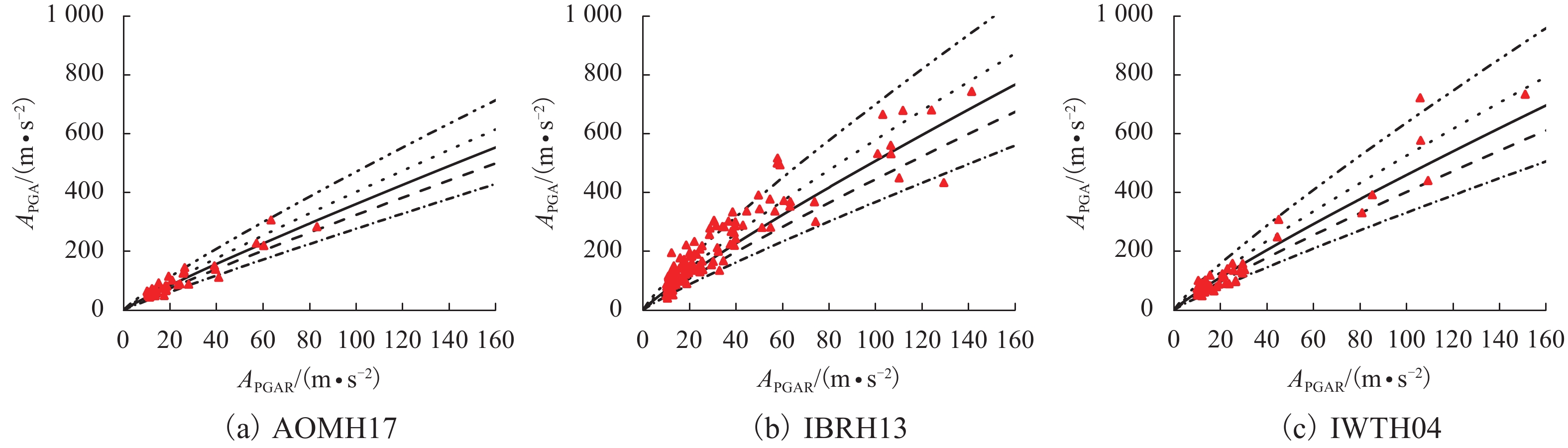
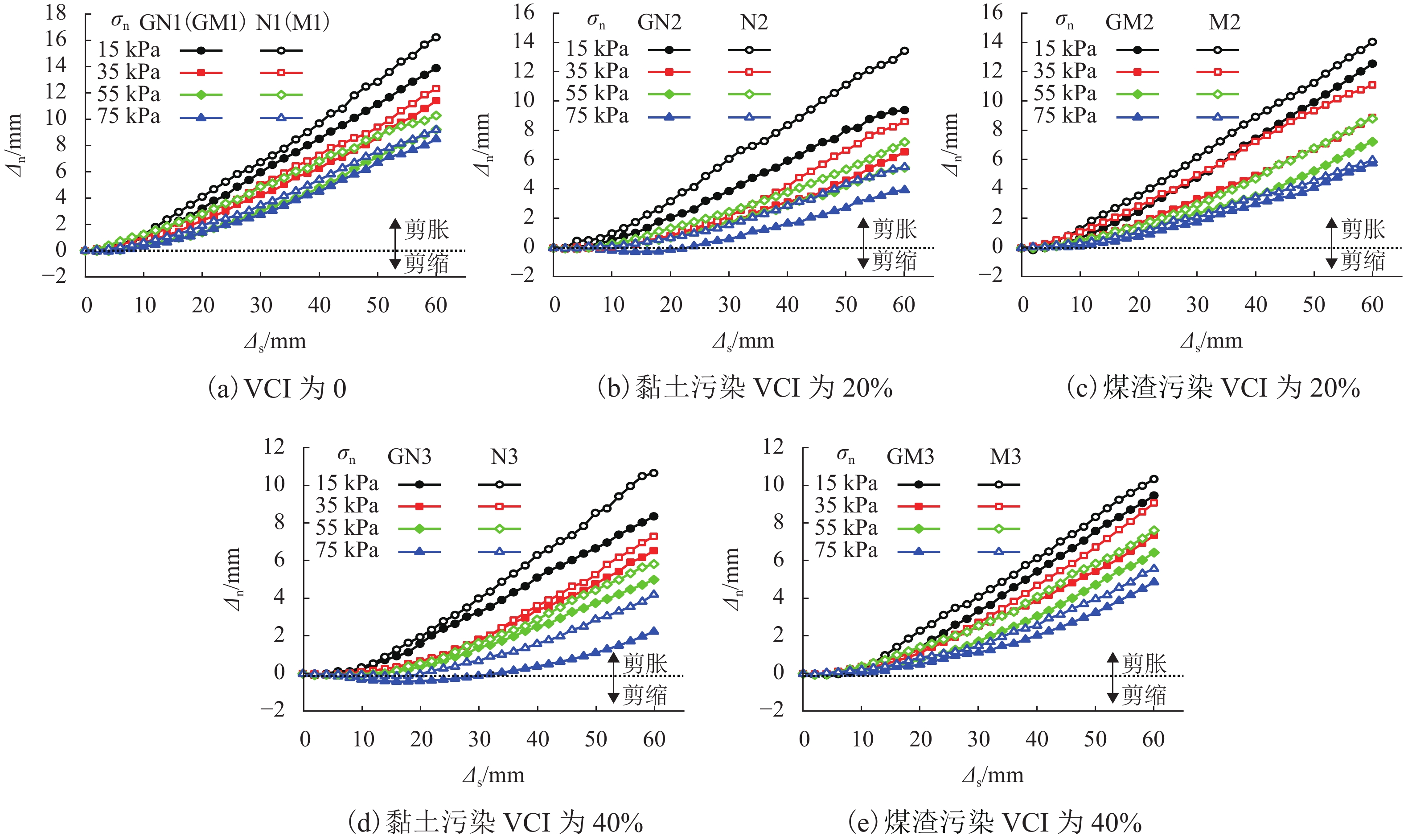
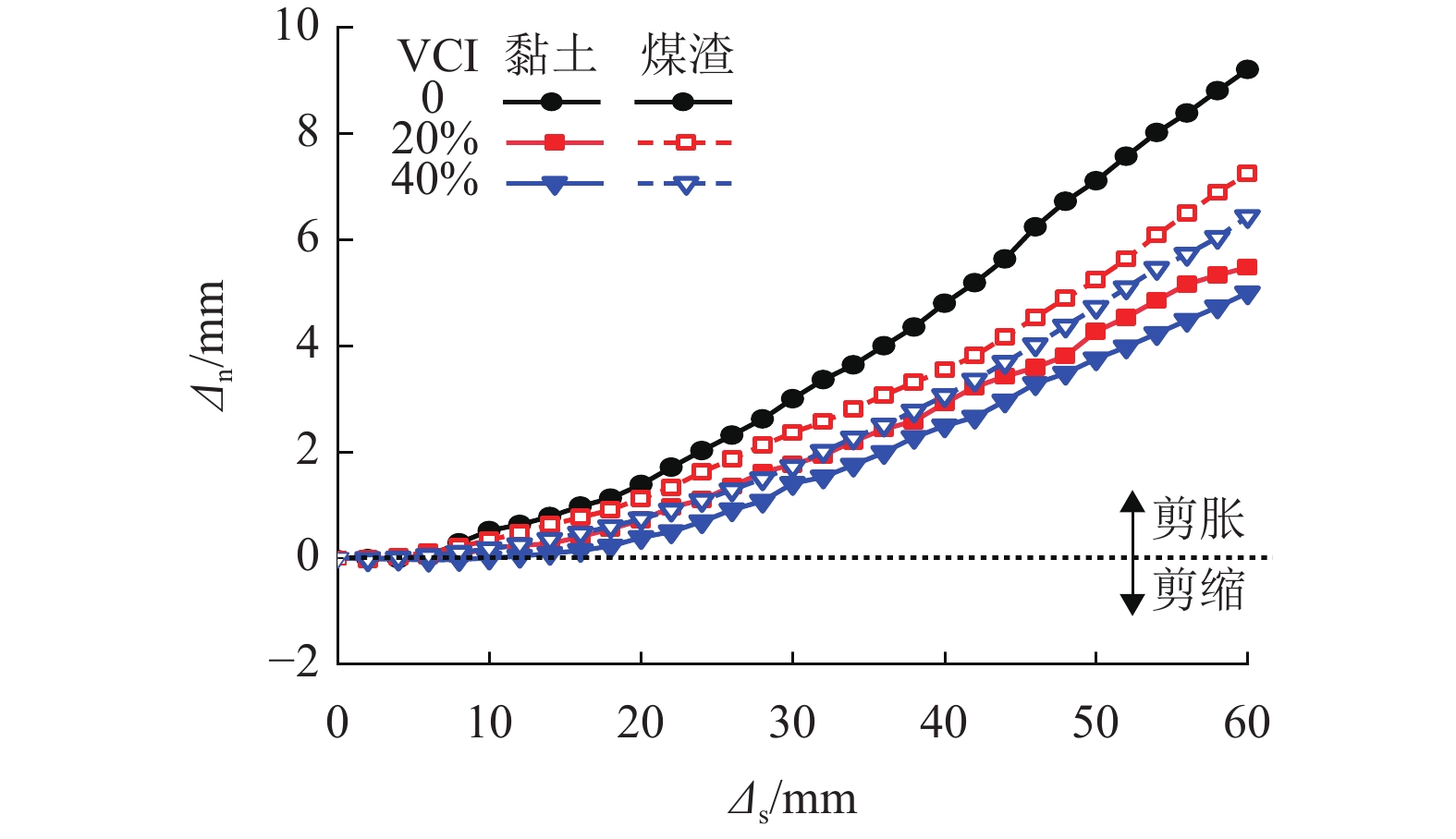
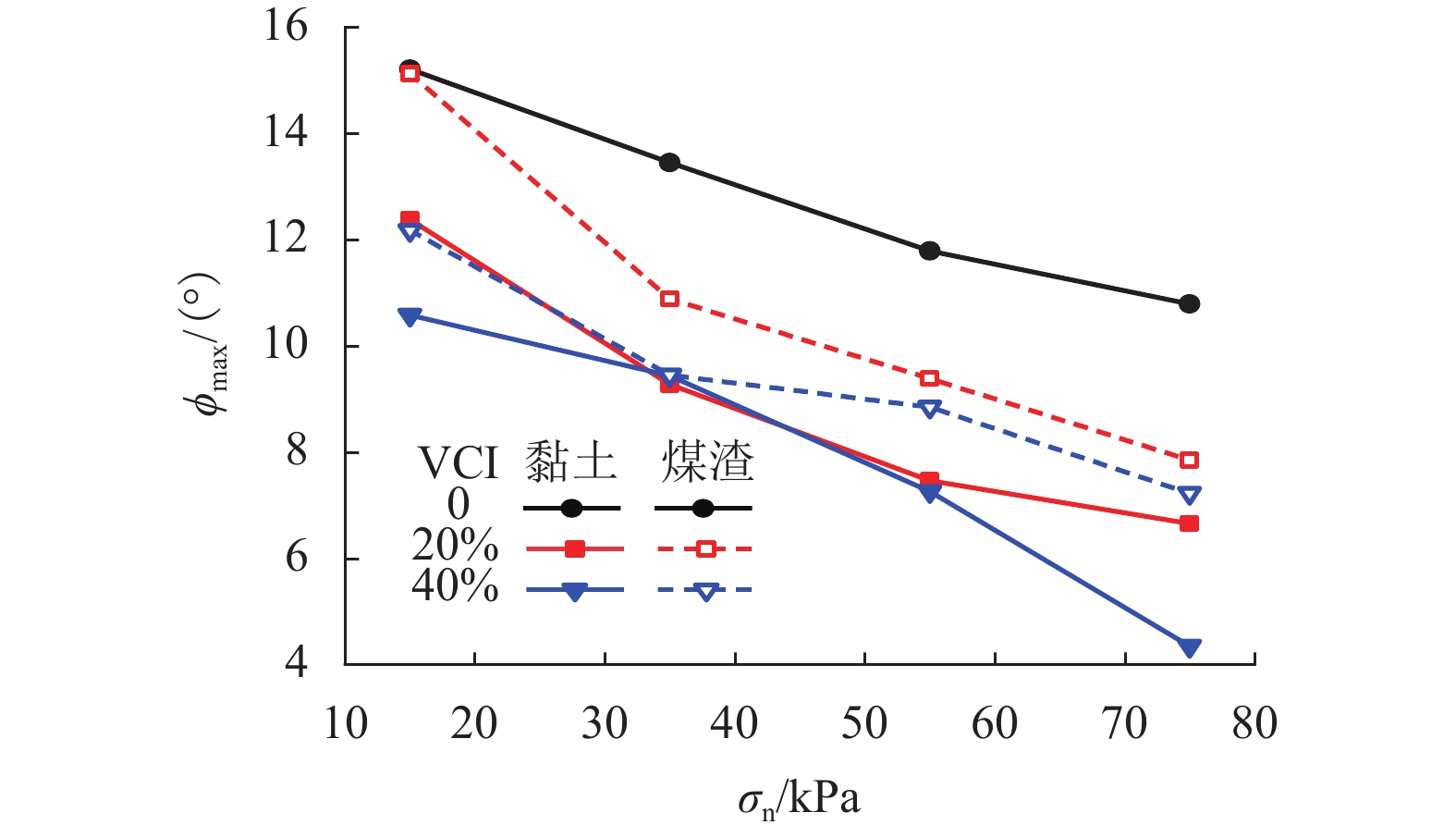
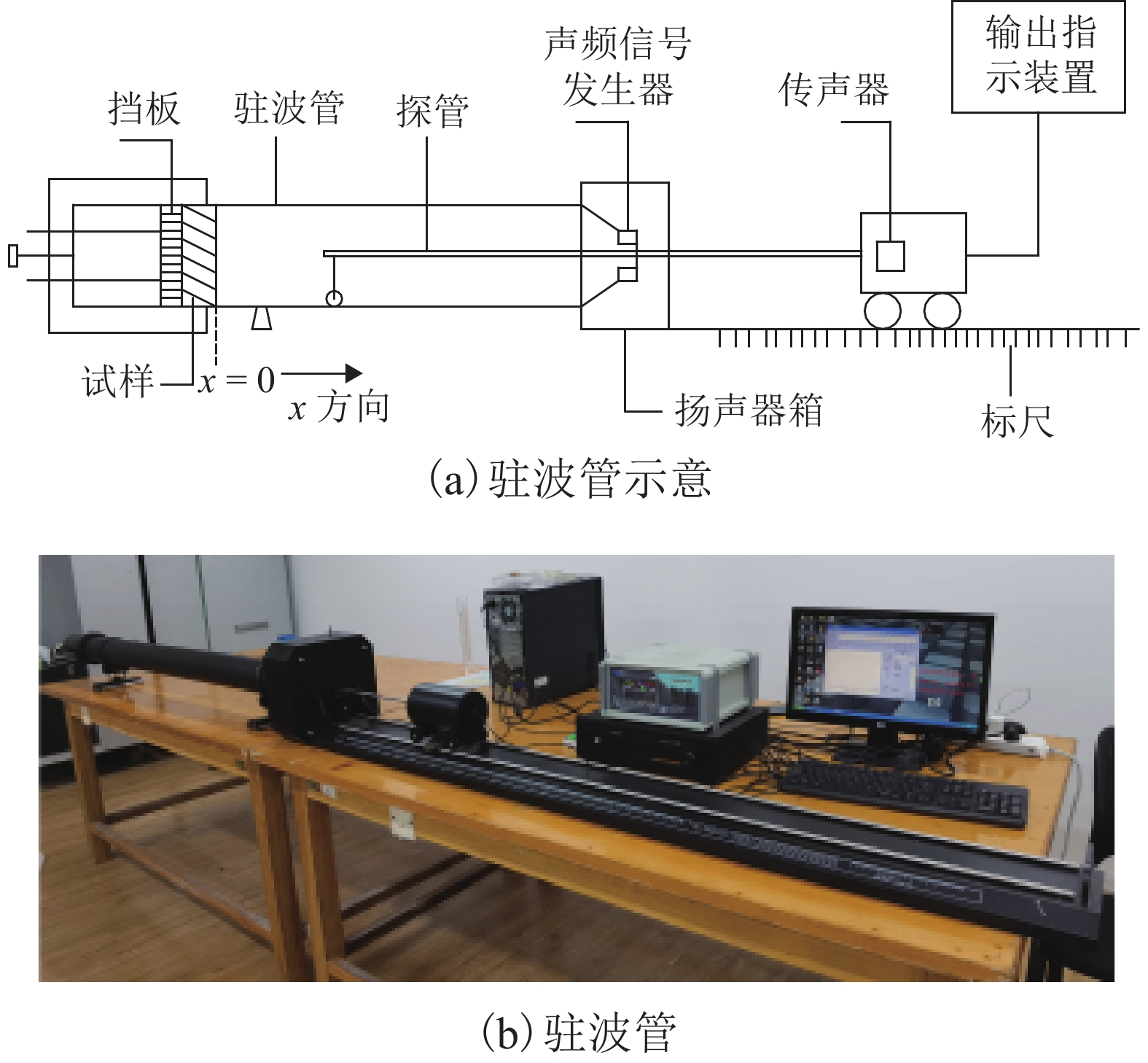
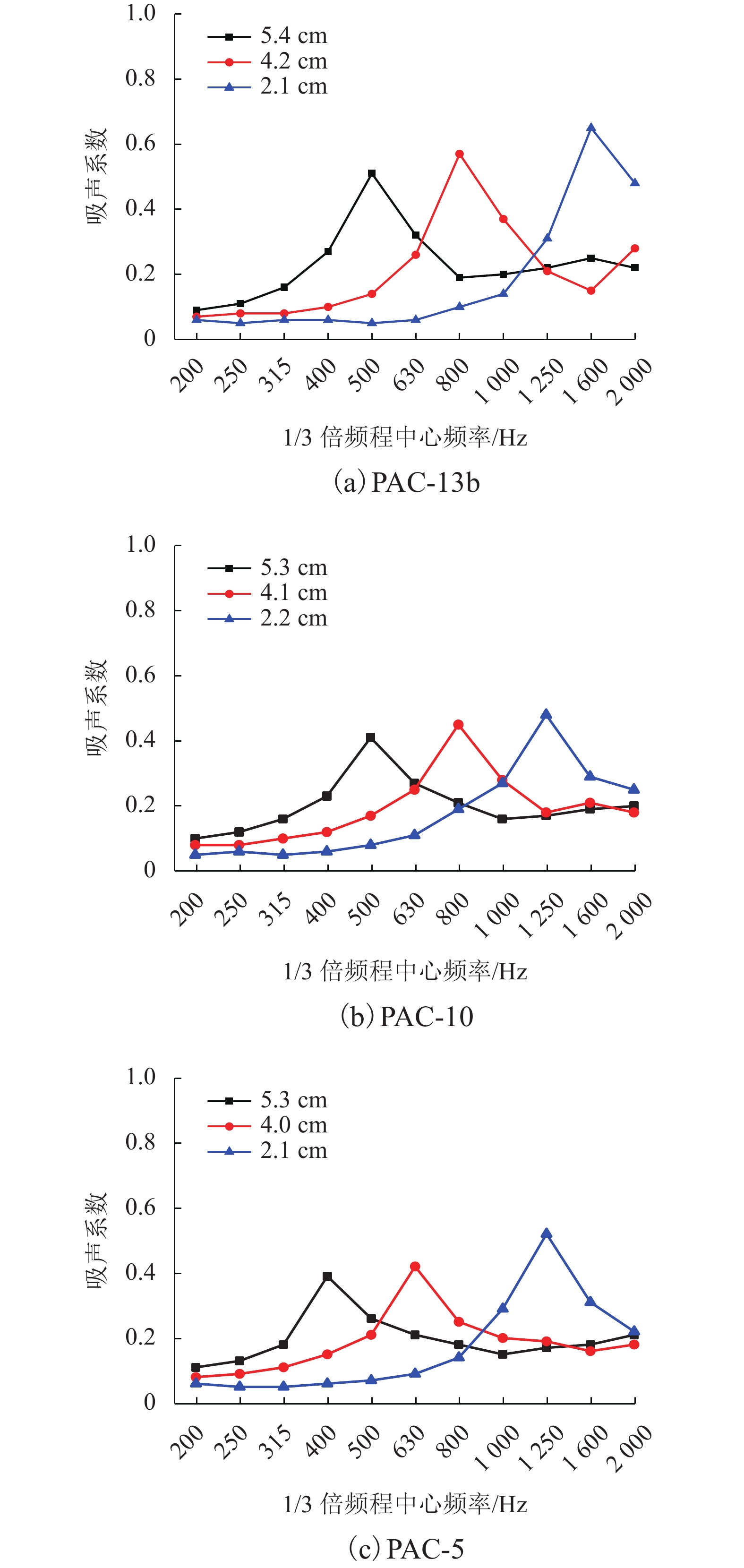
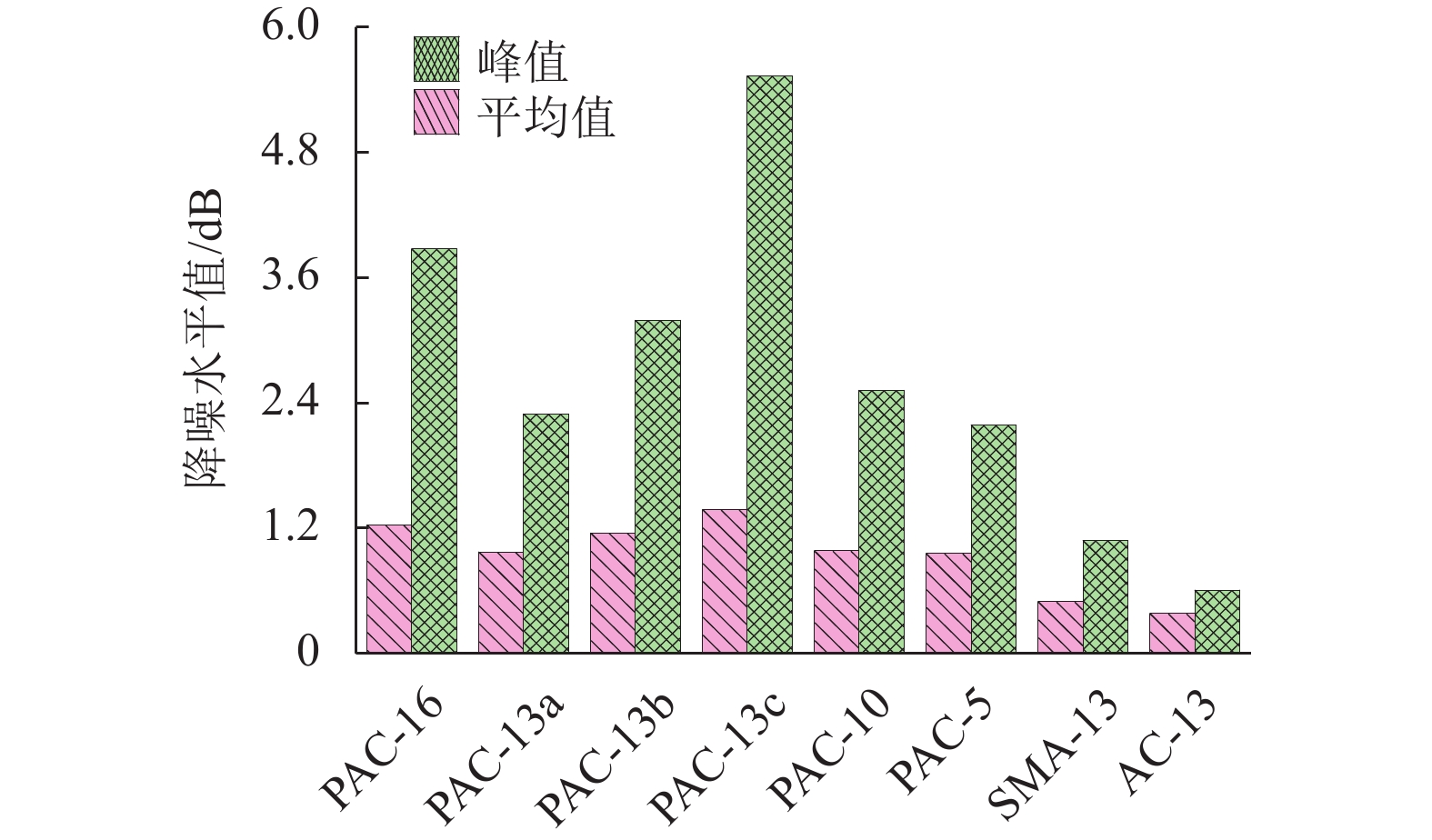
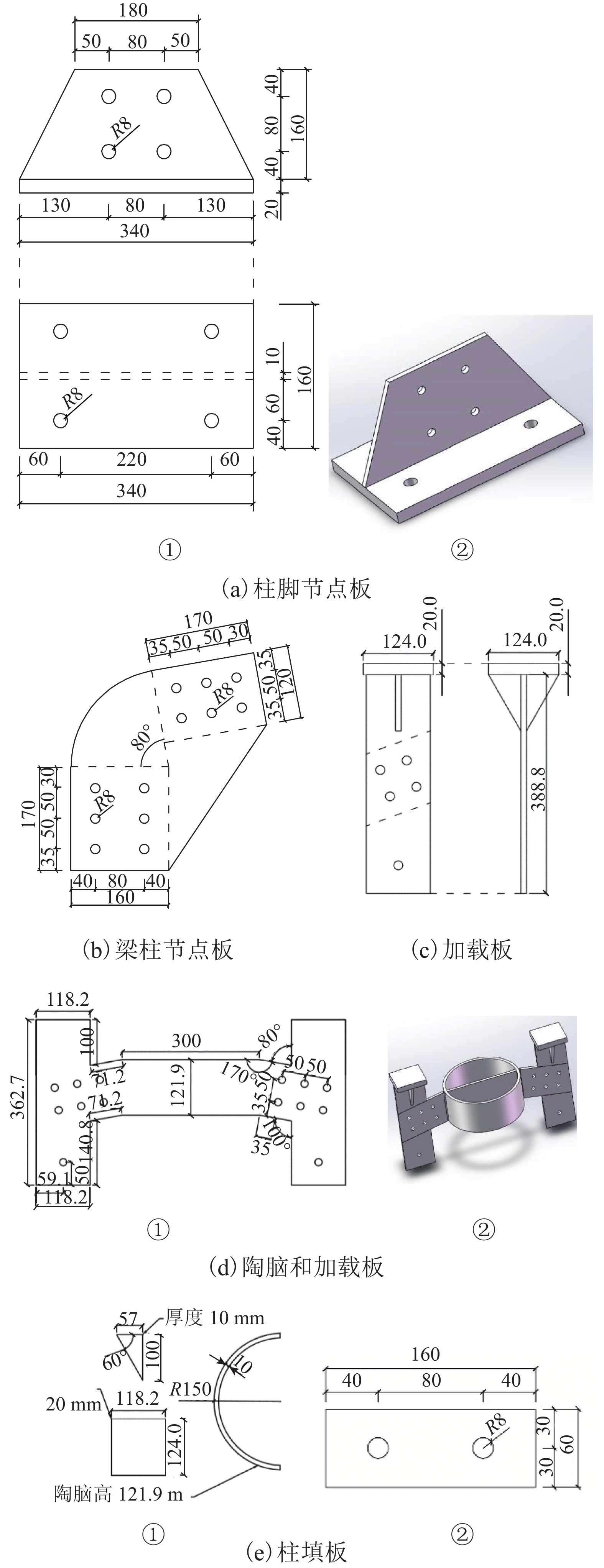
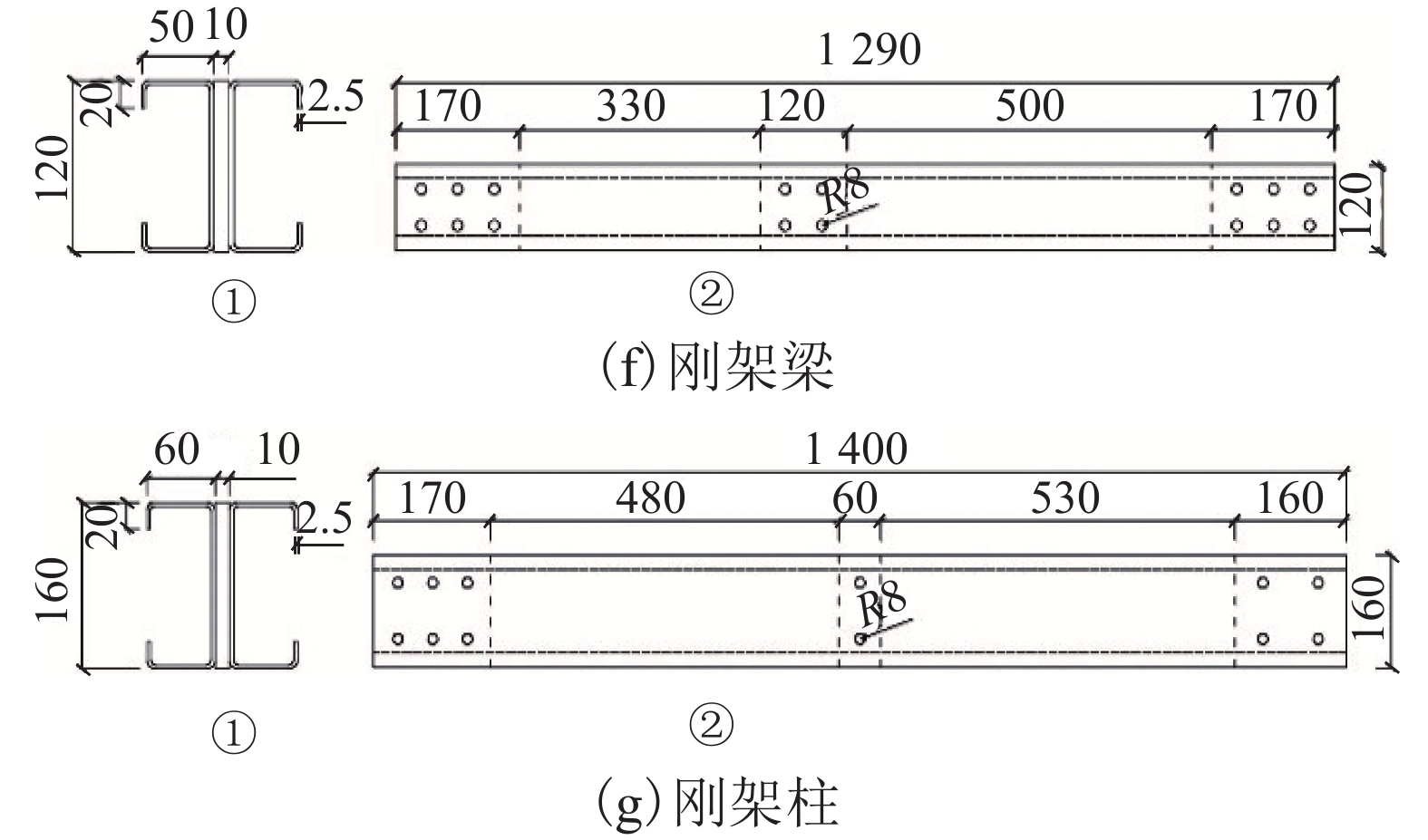
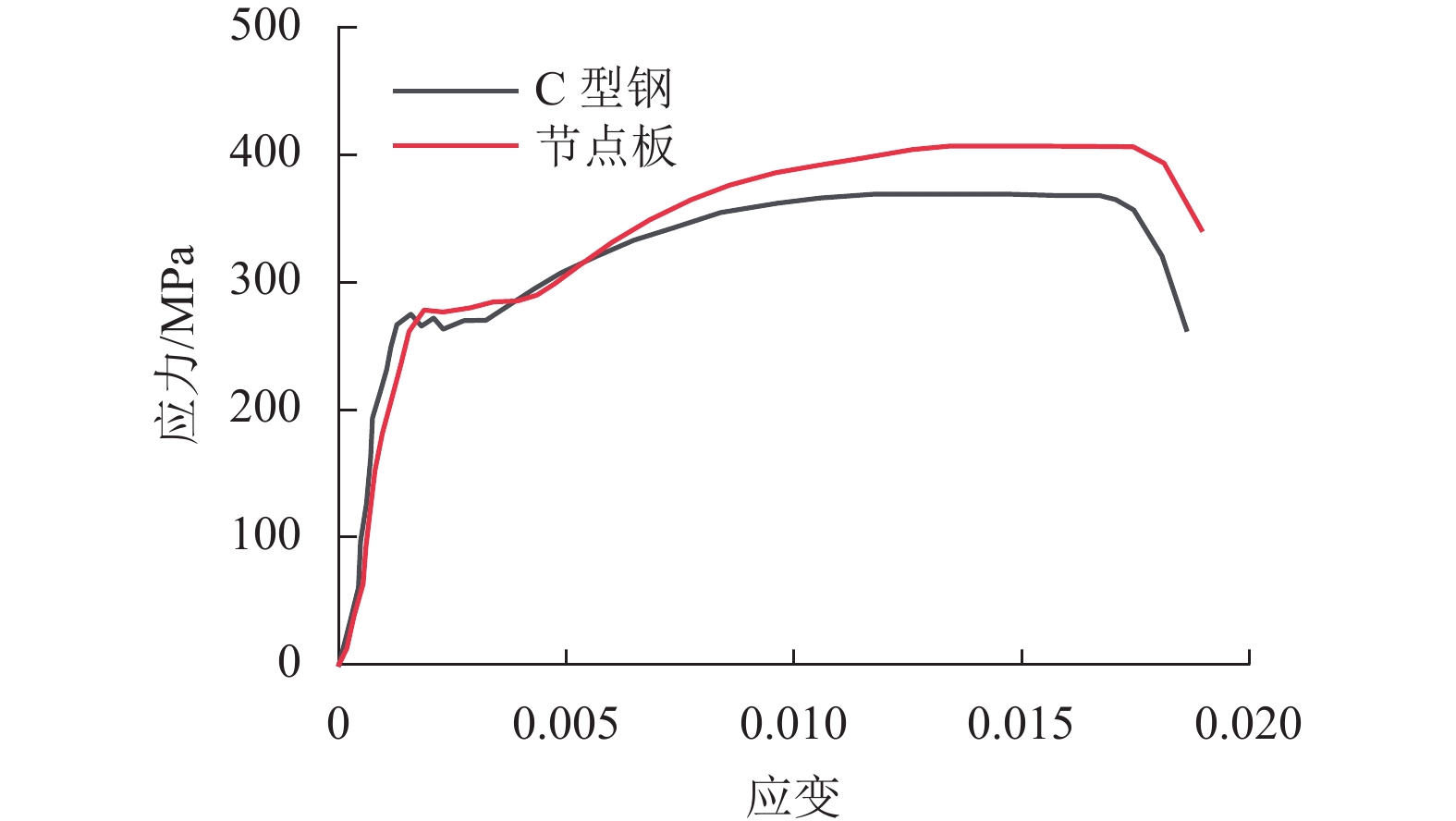
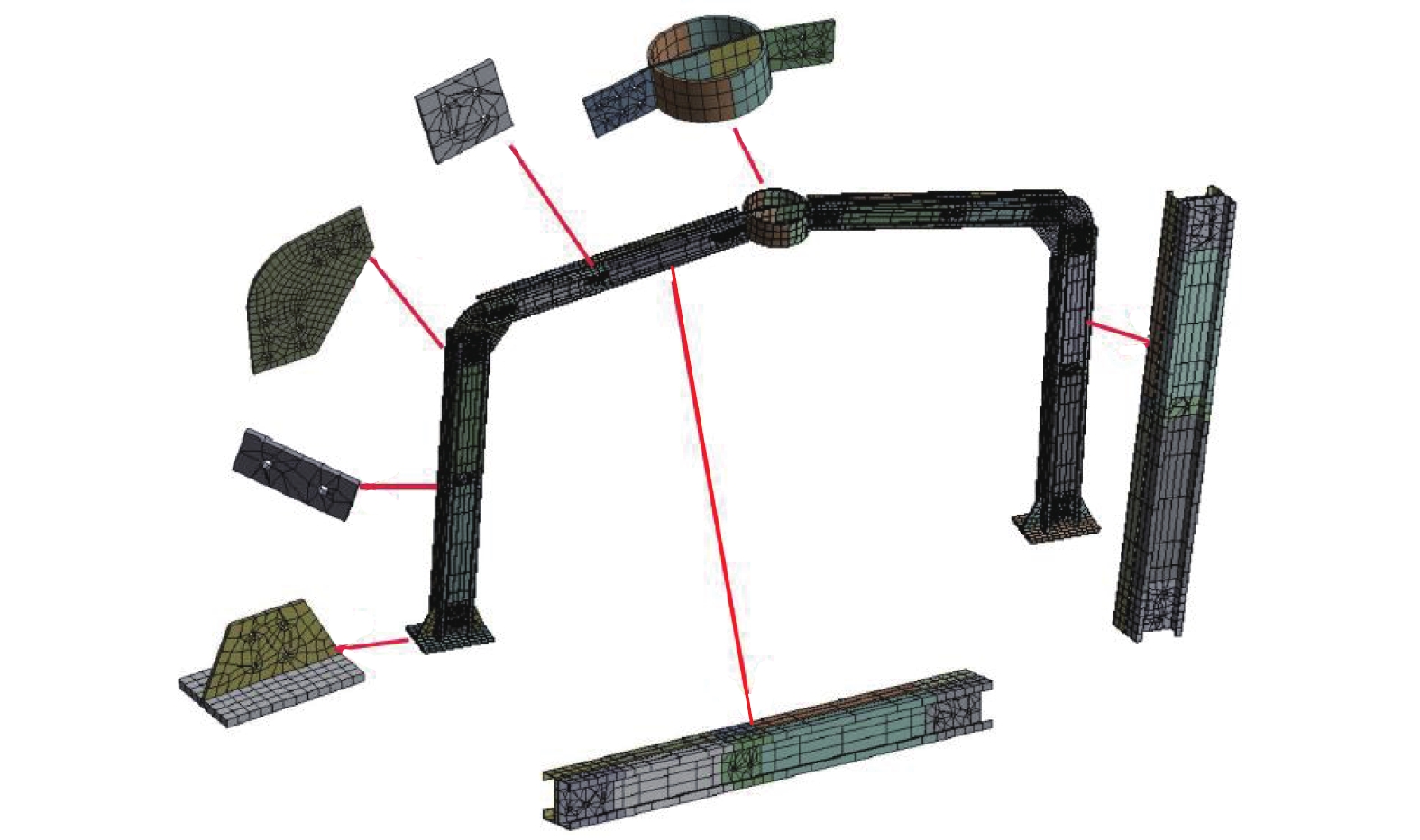
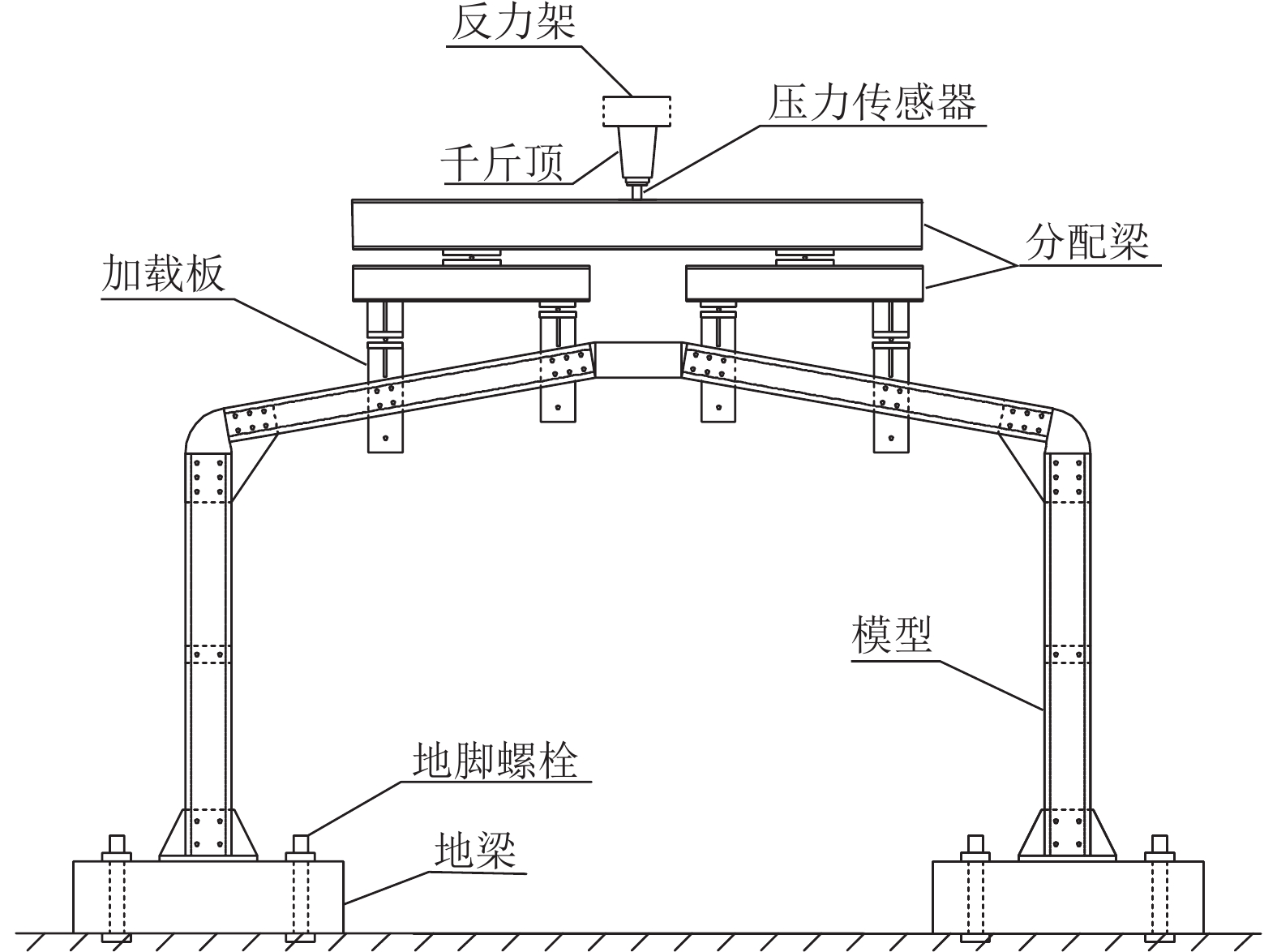
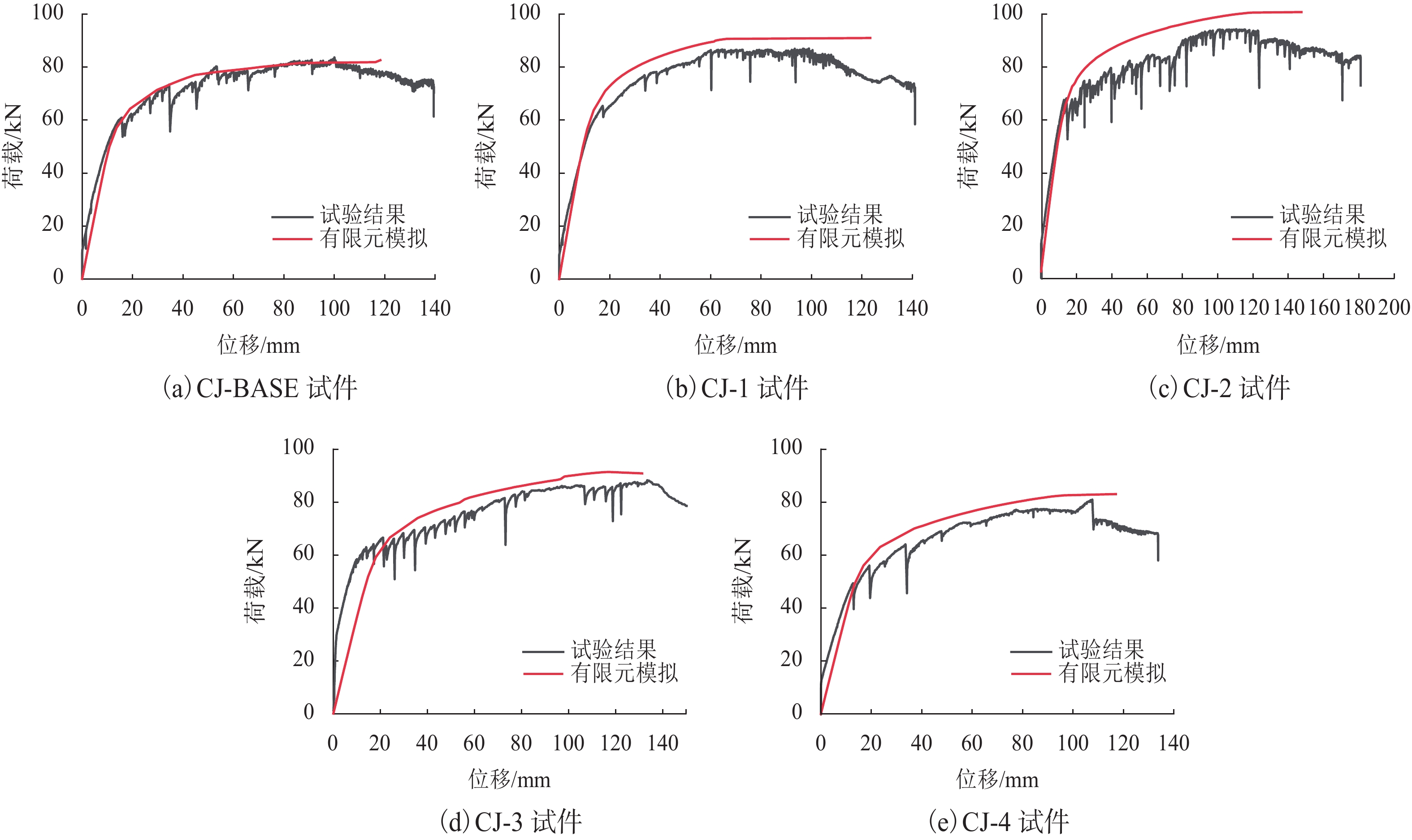
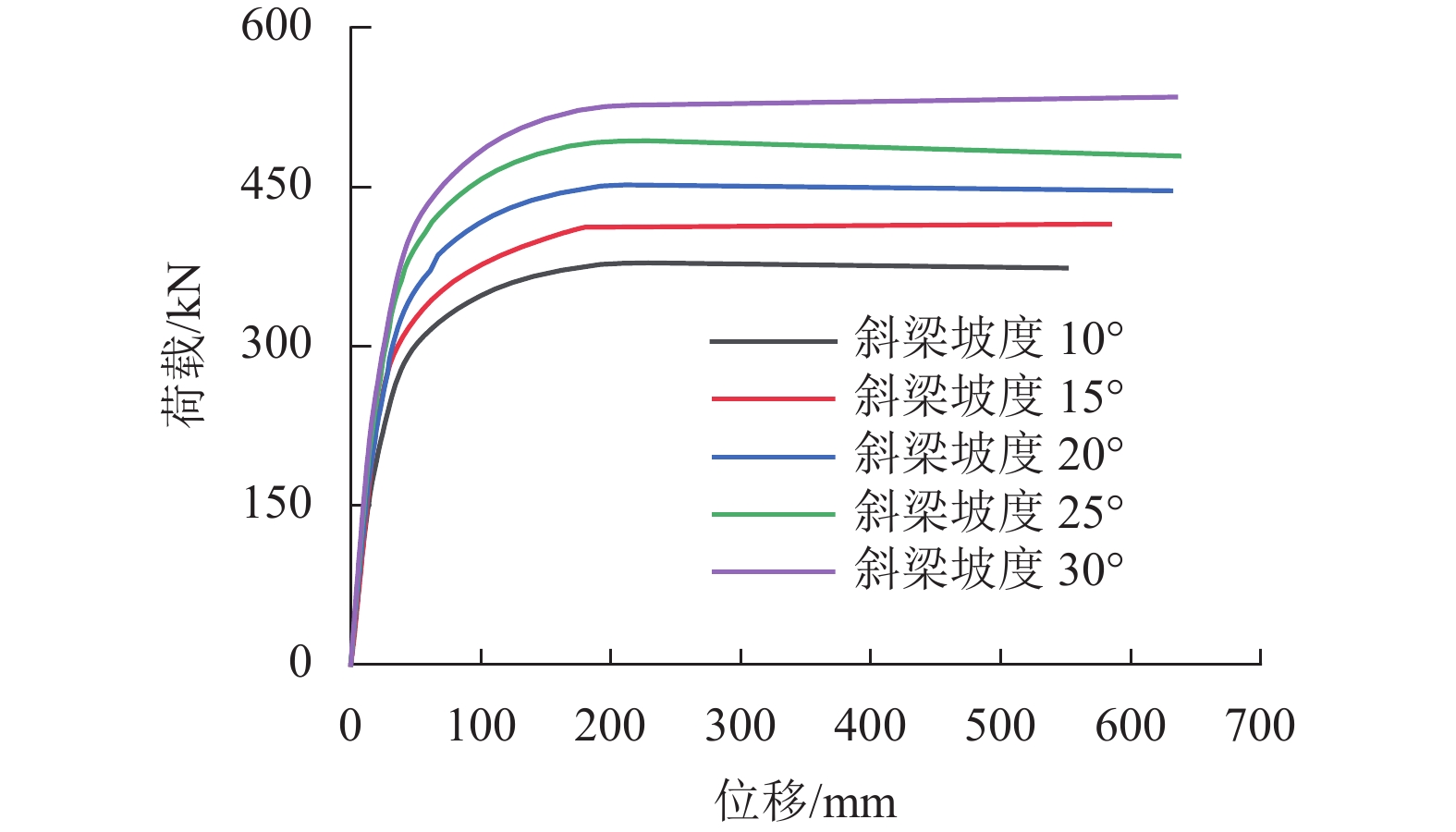
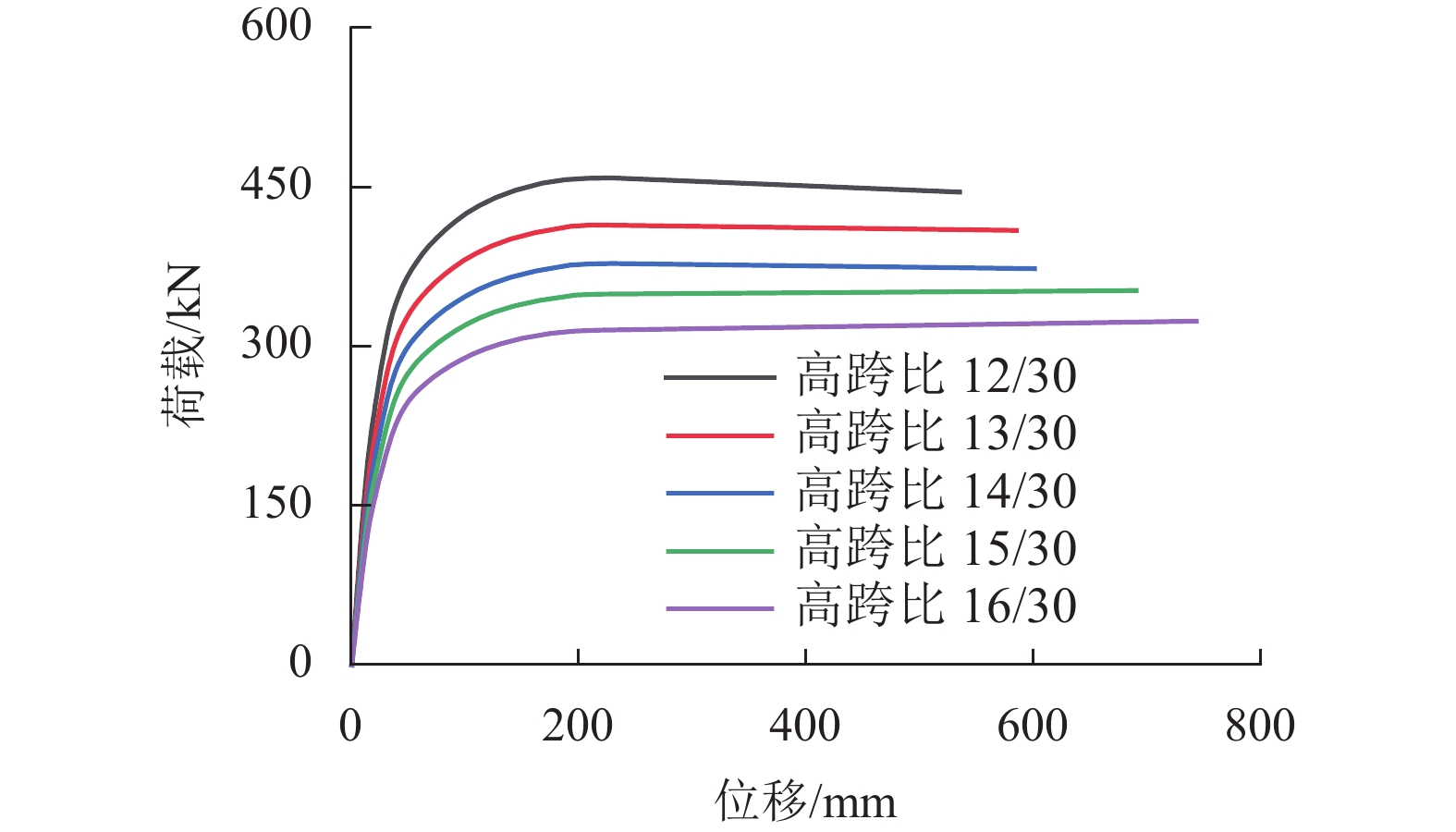
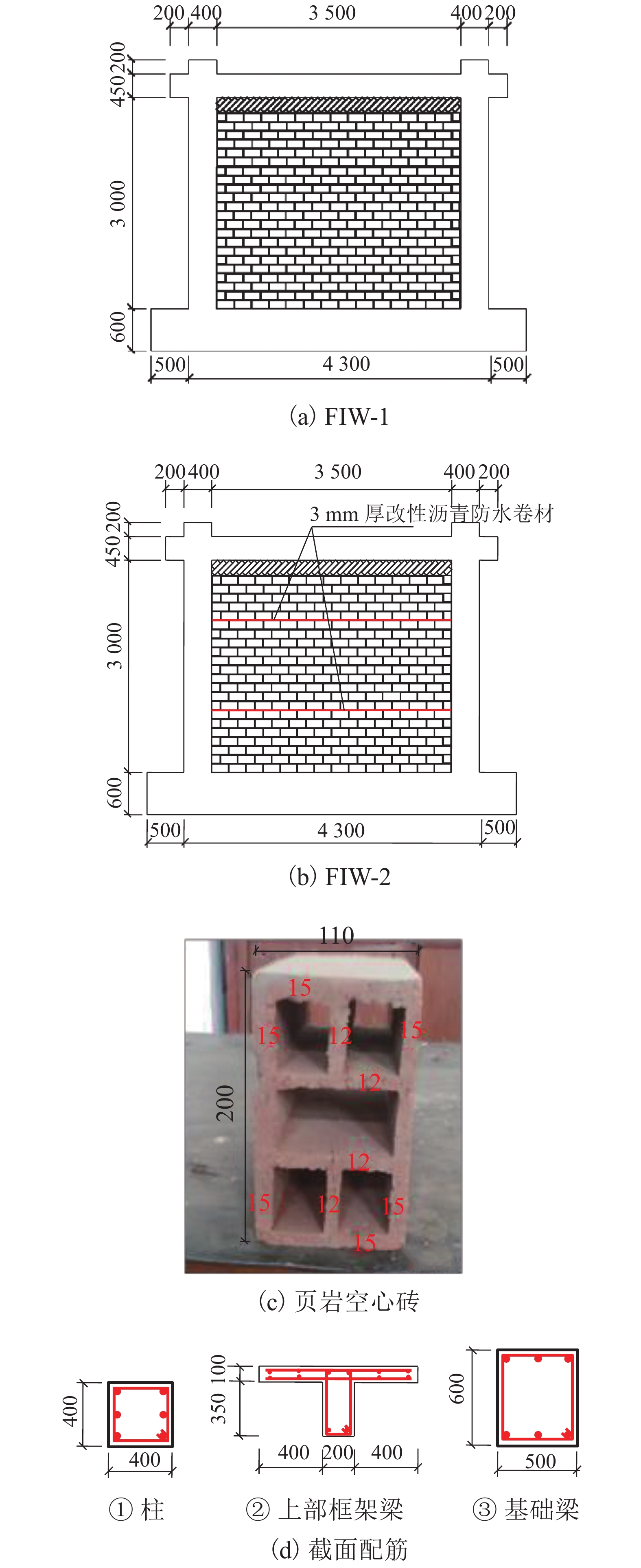
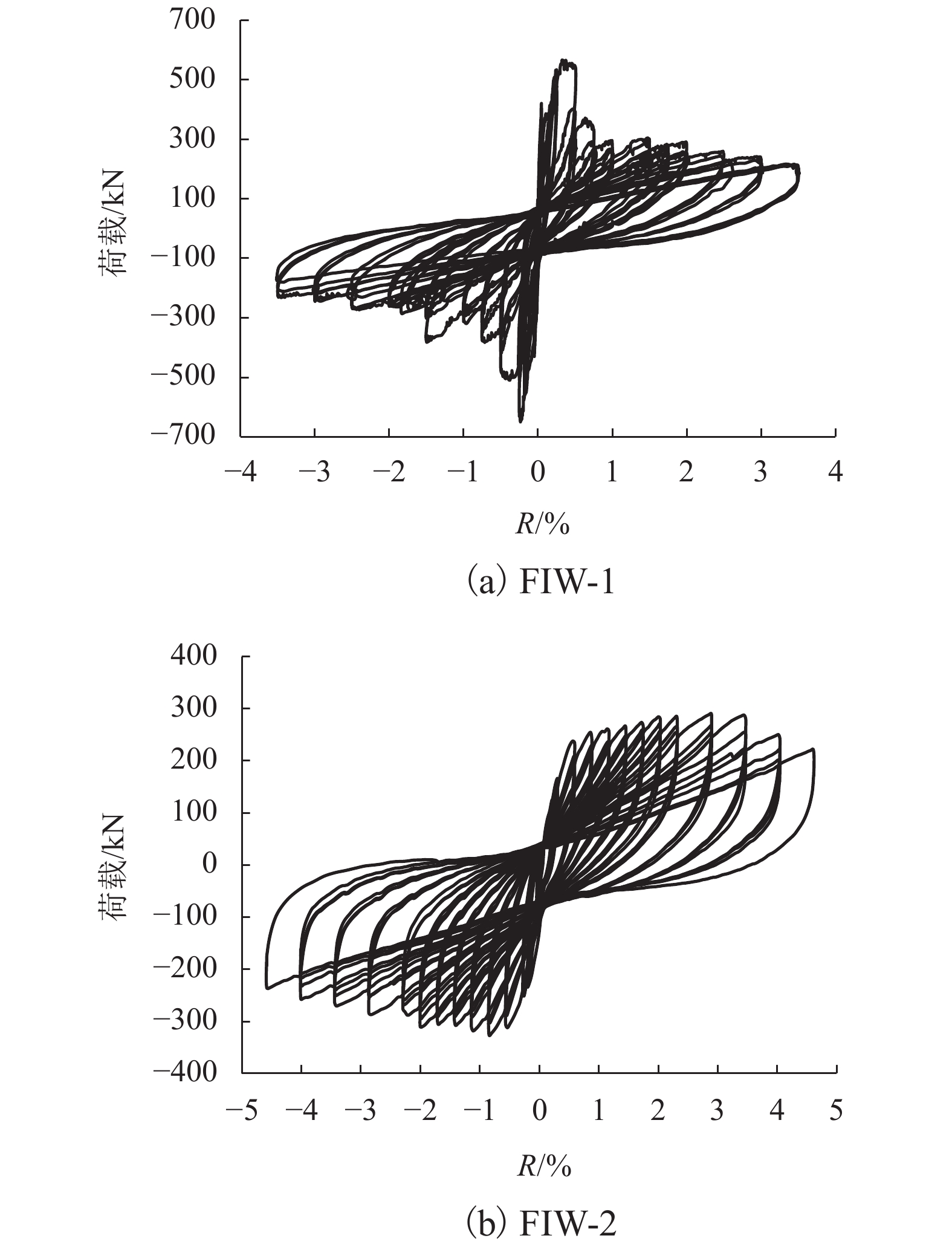
摘要:
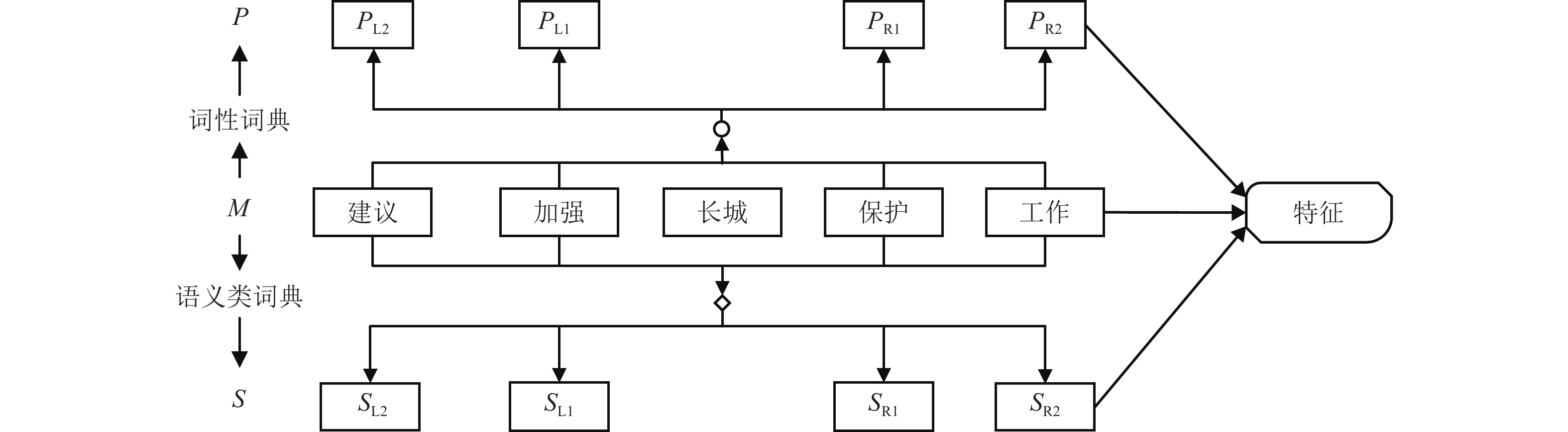
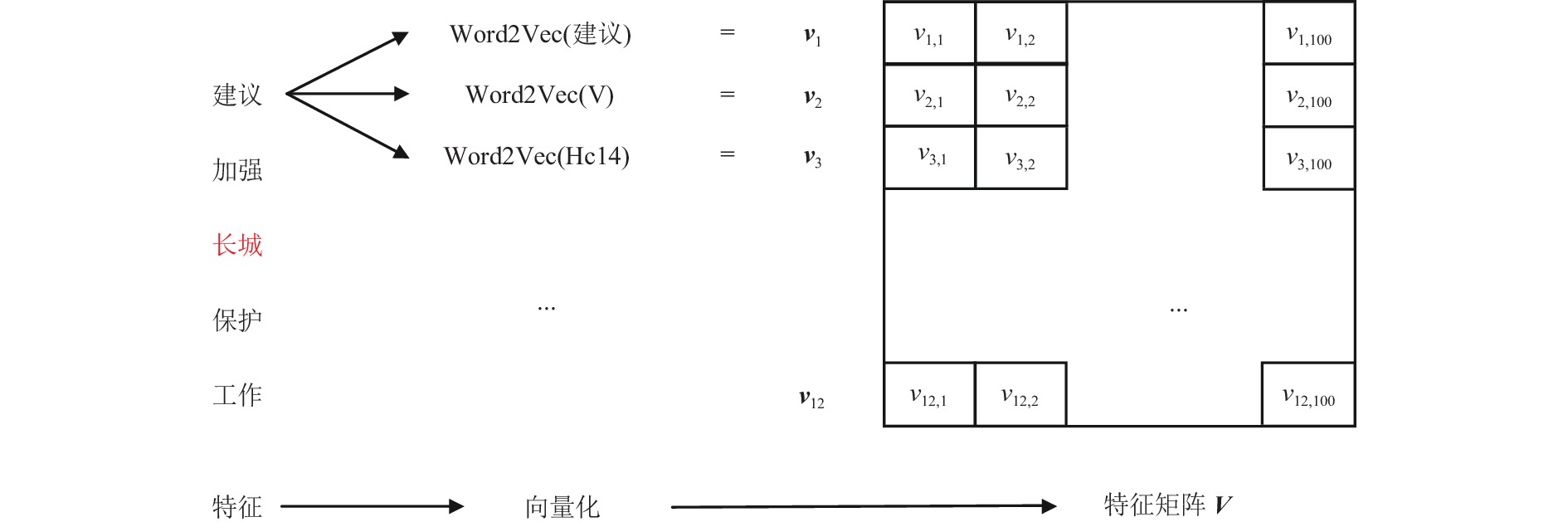
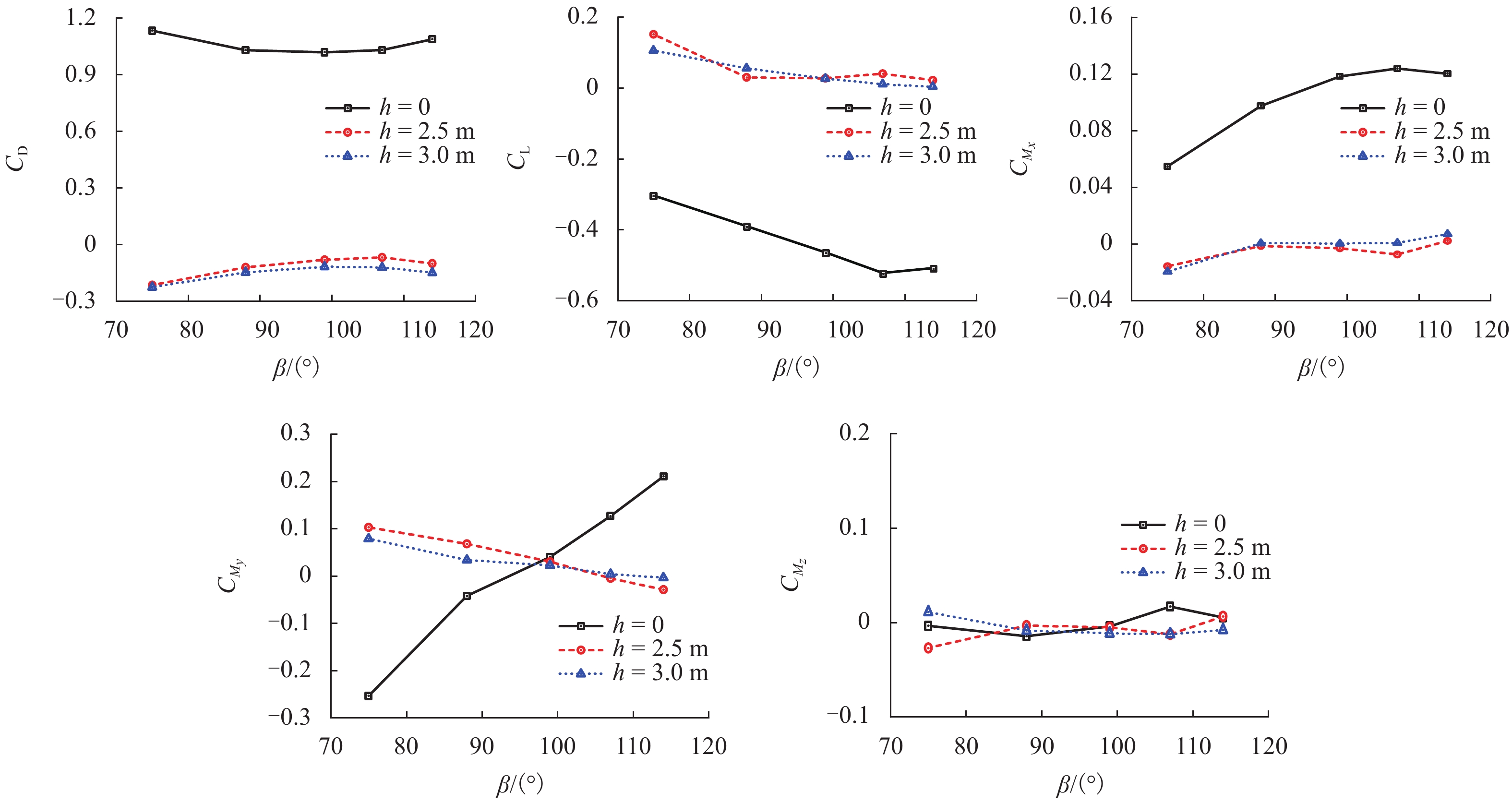
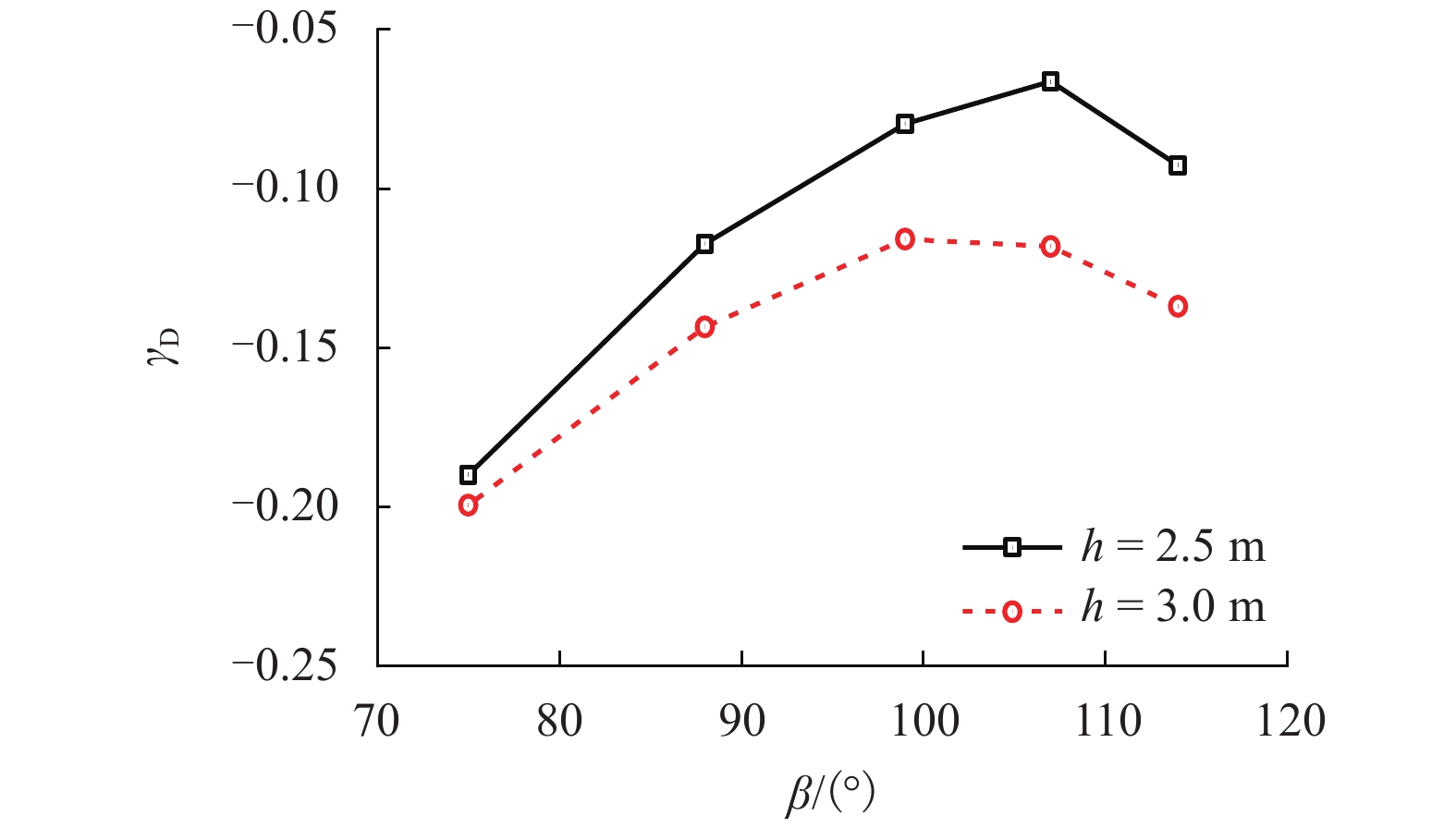
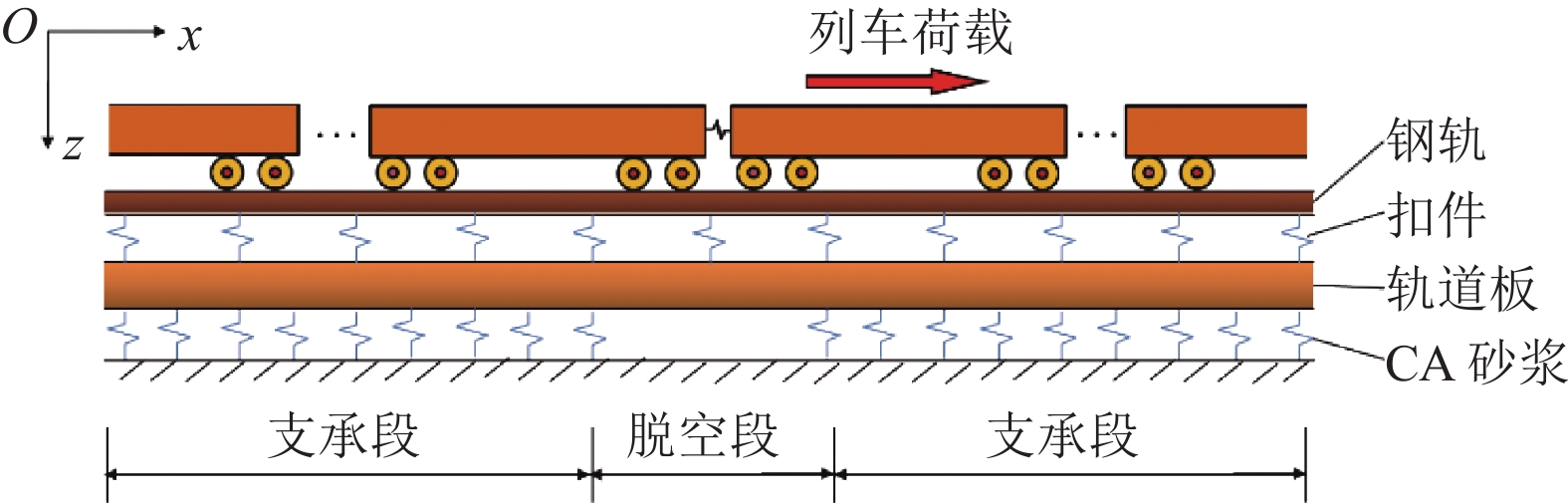
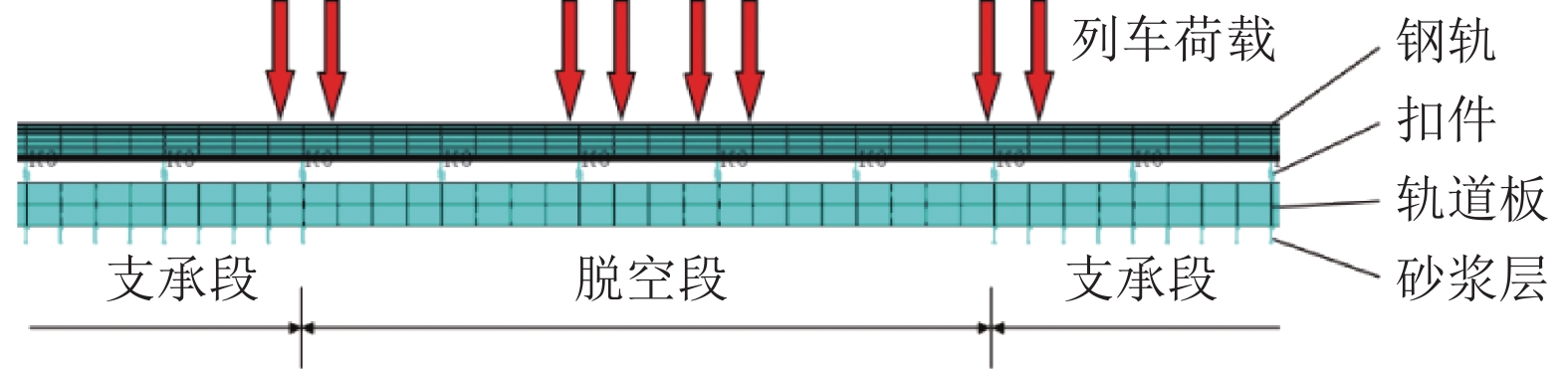
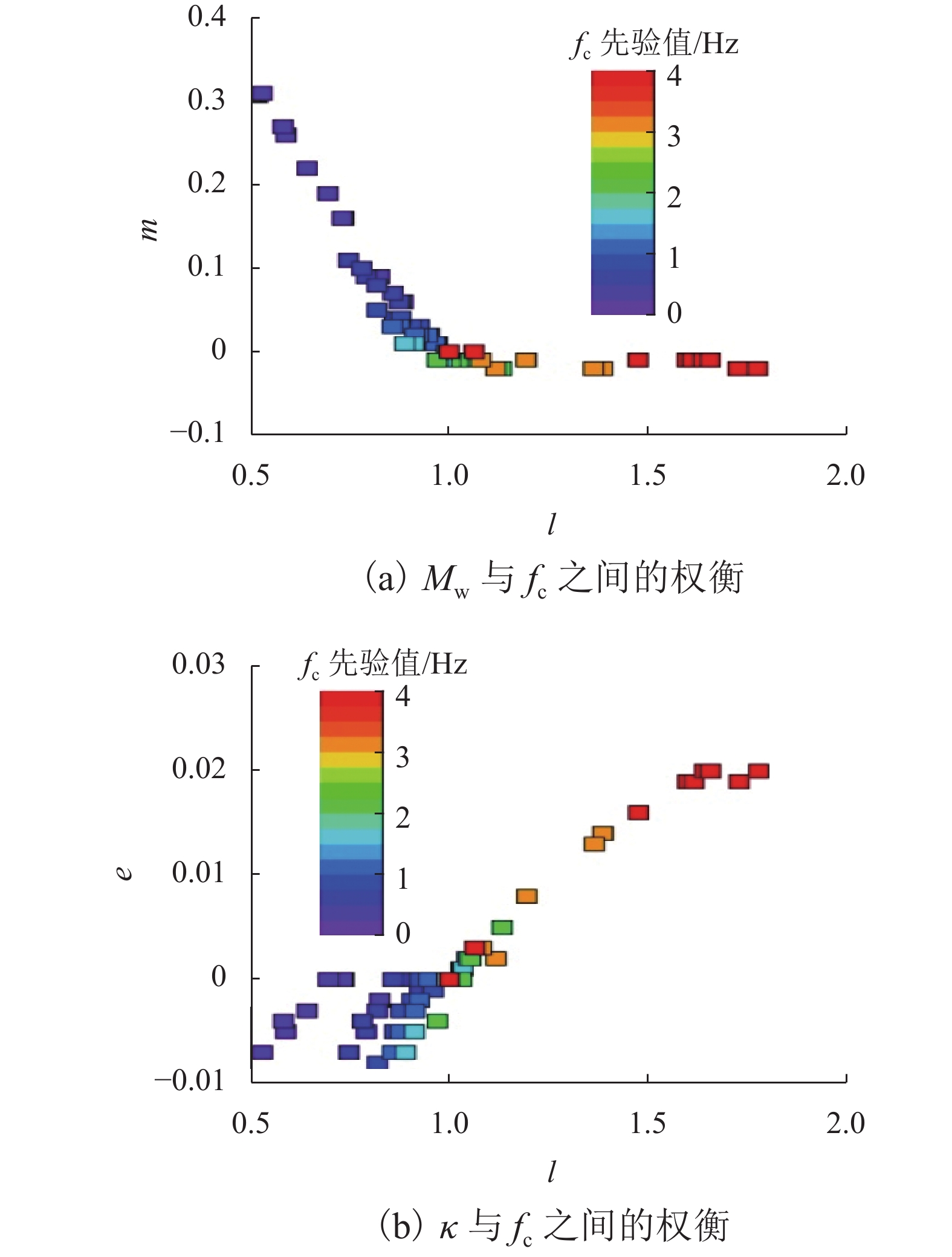
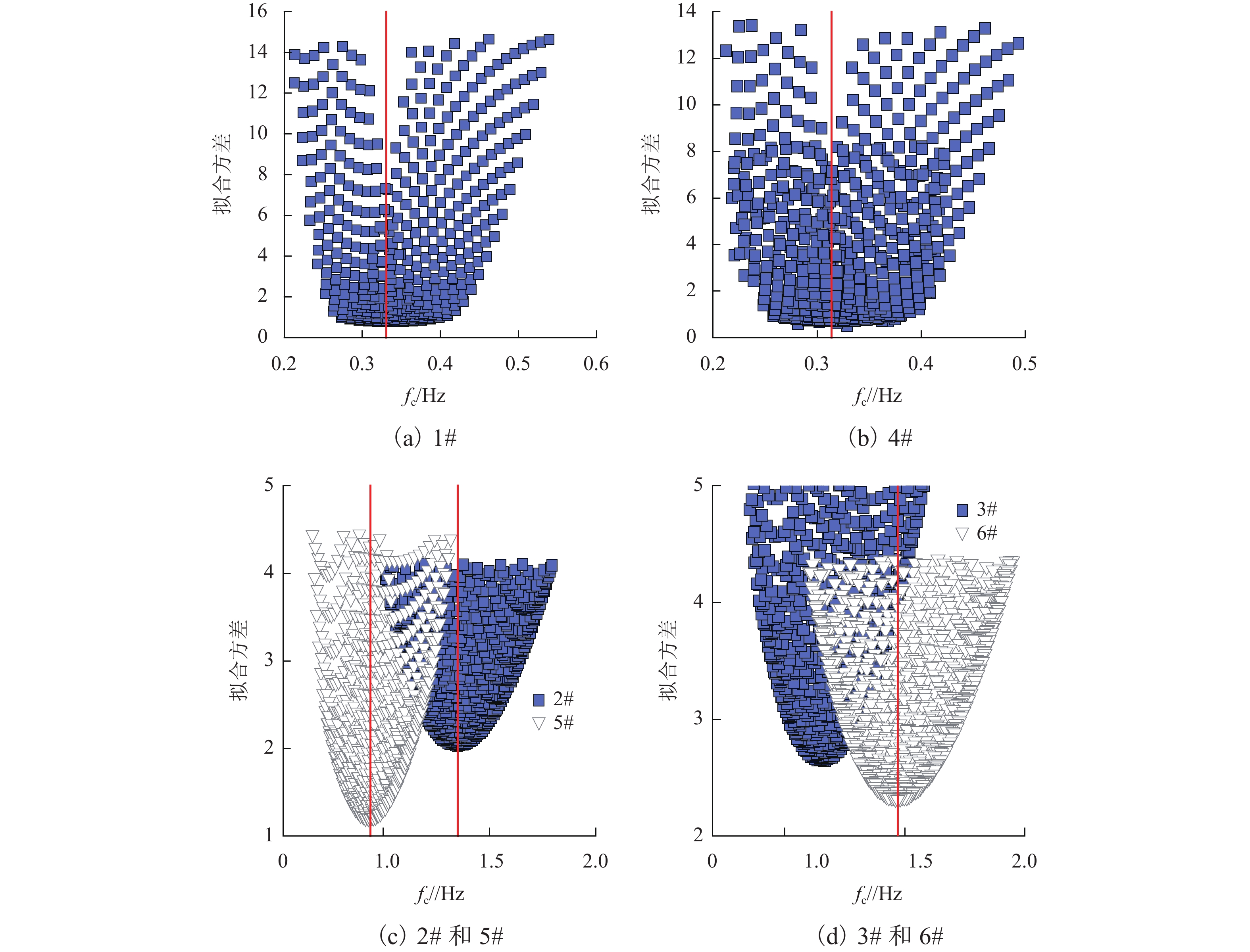
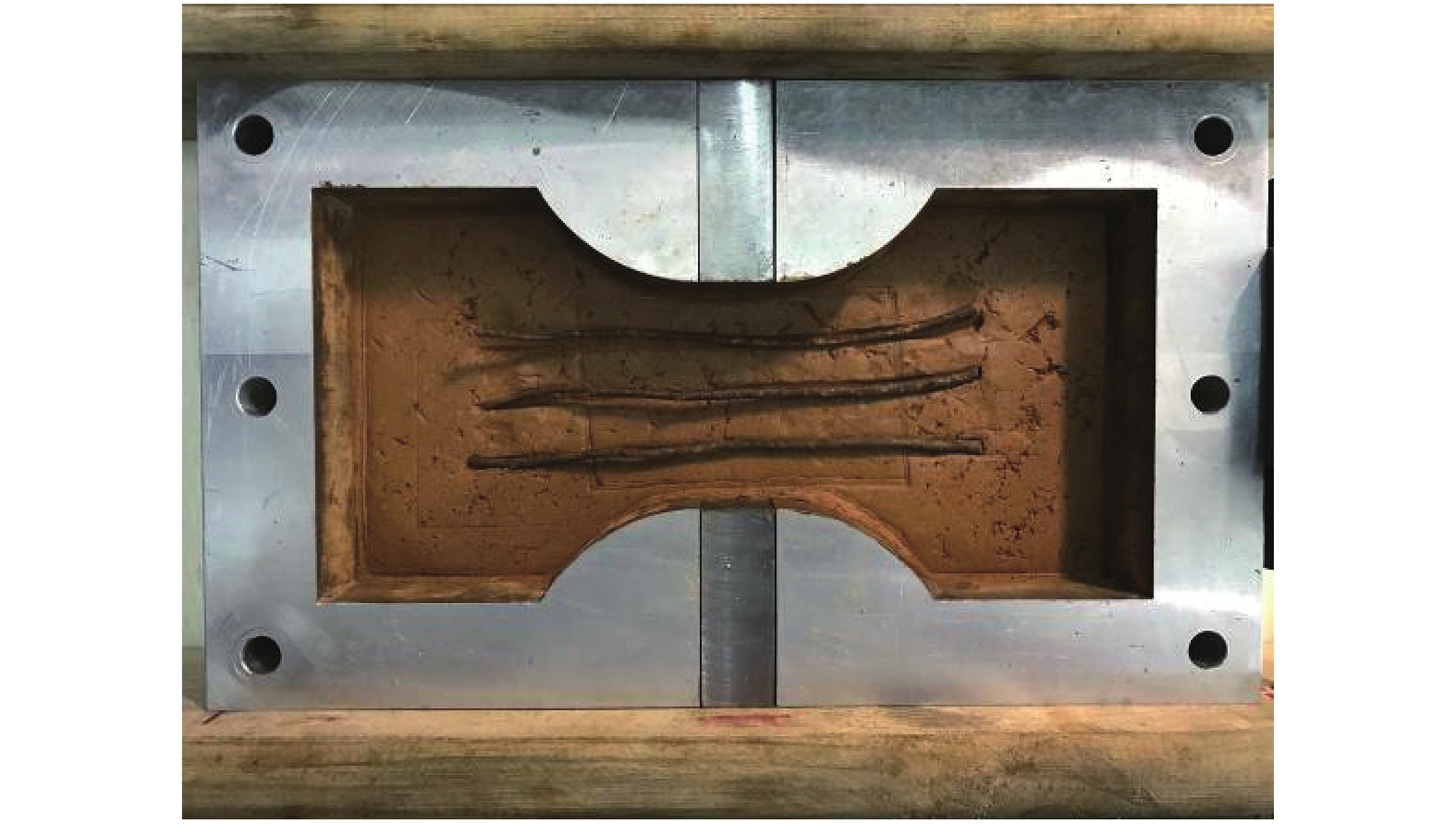
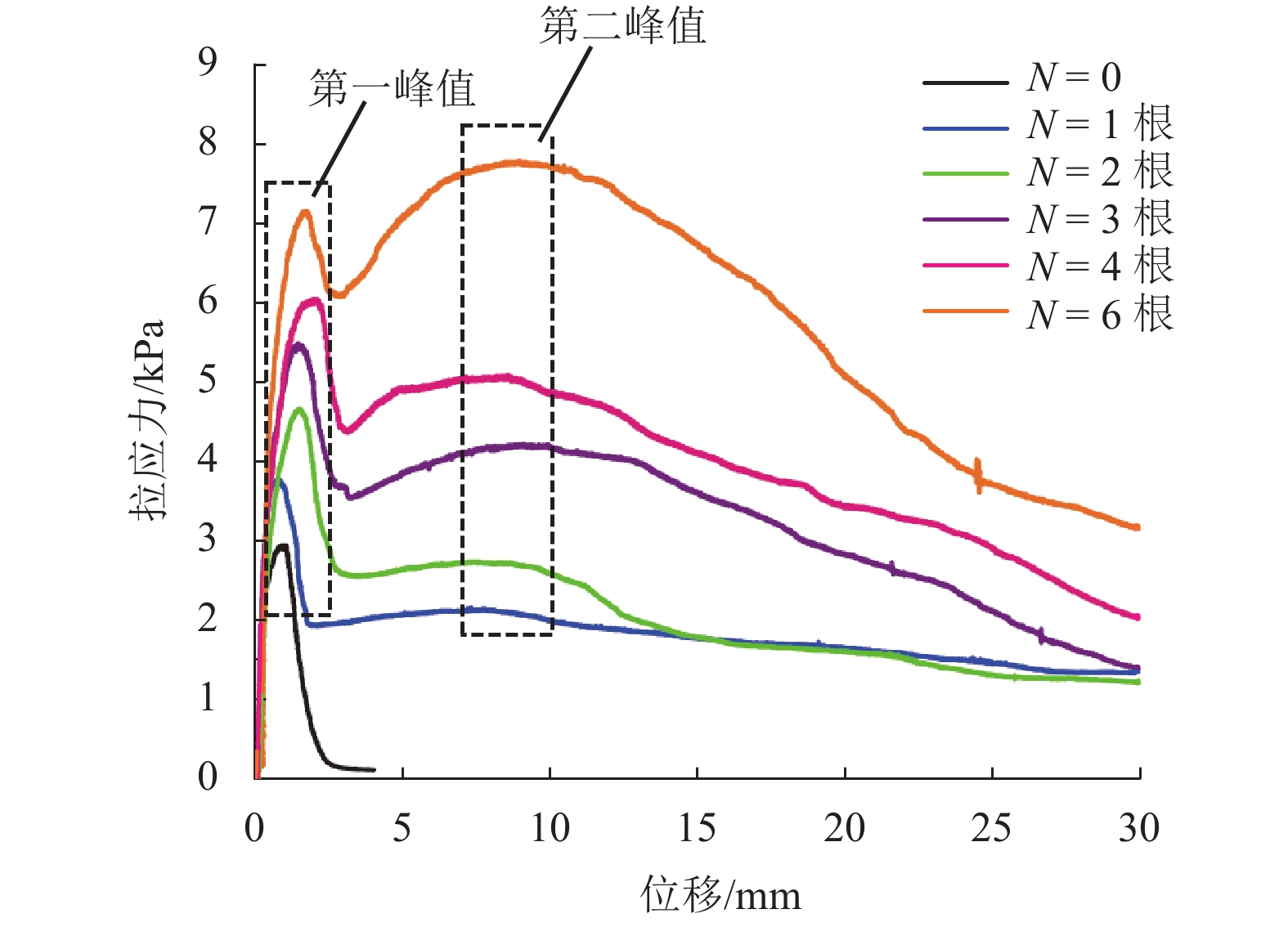
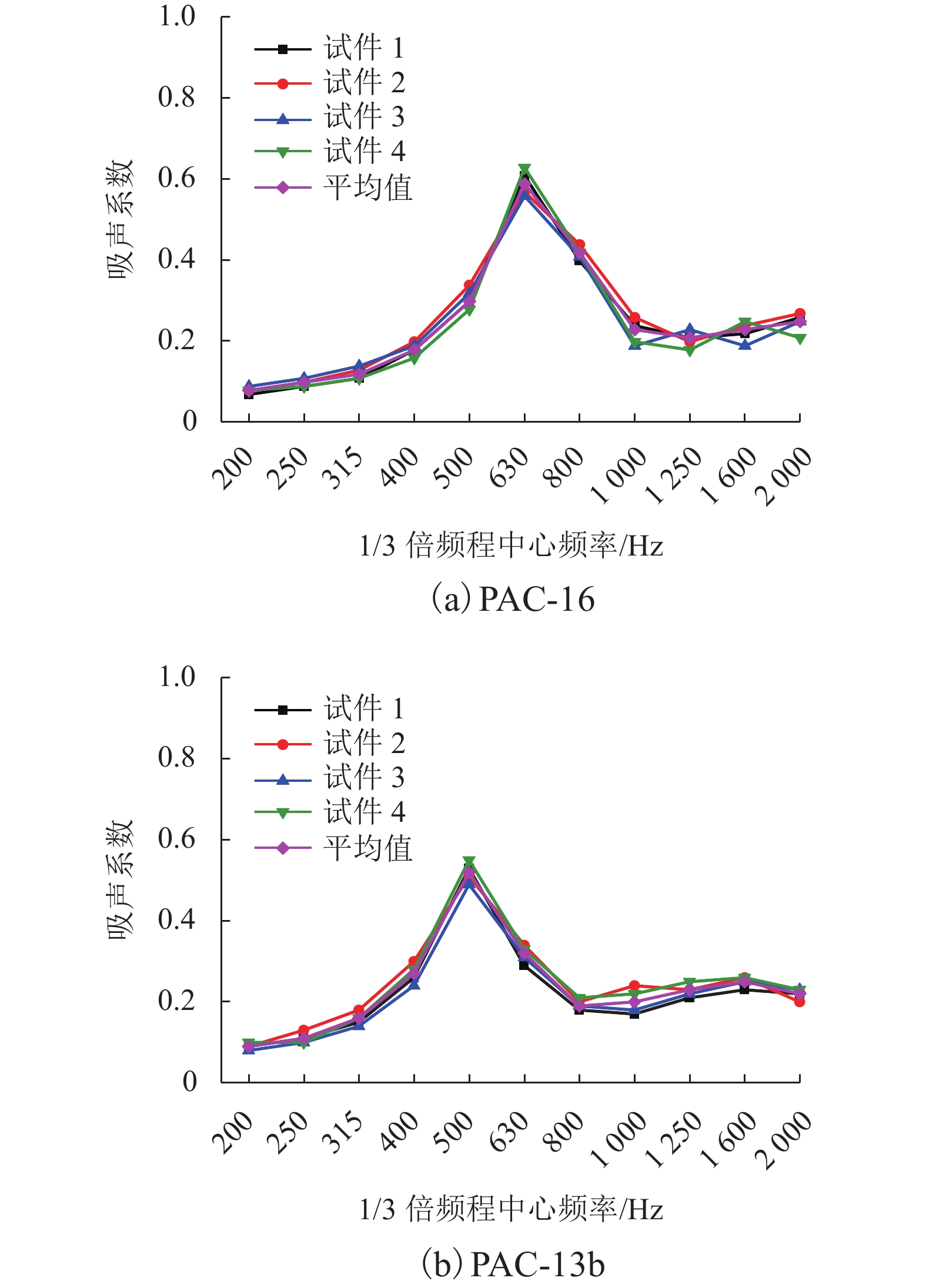
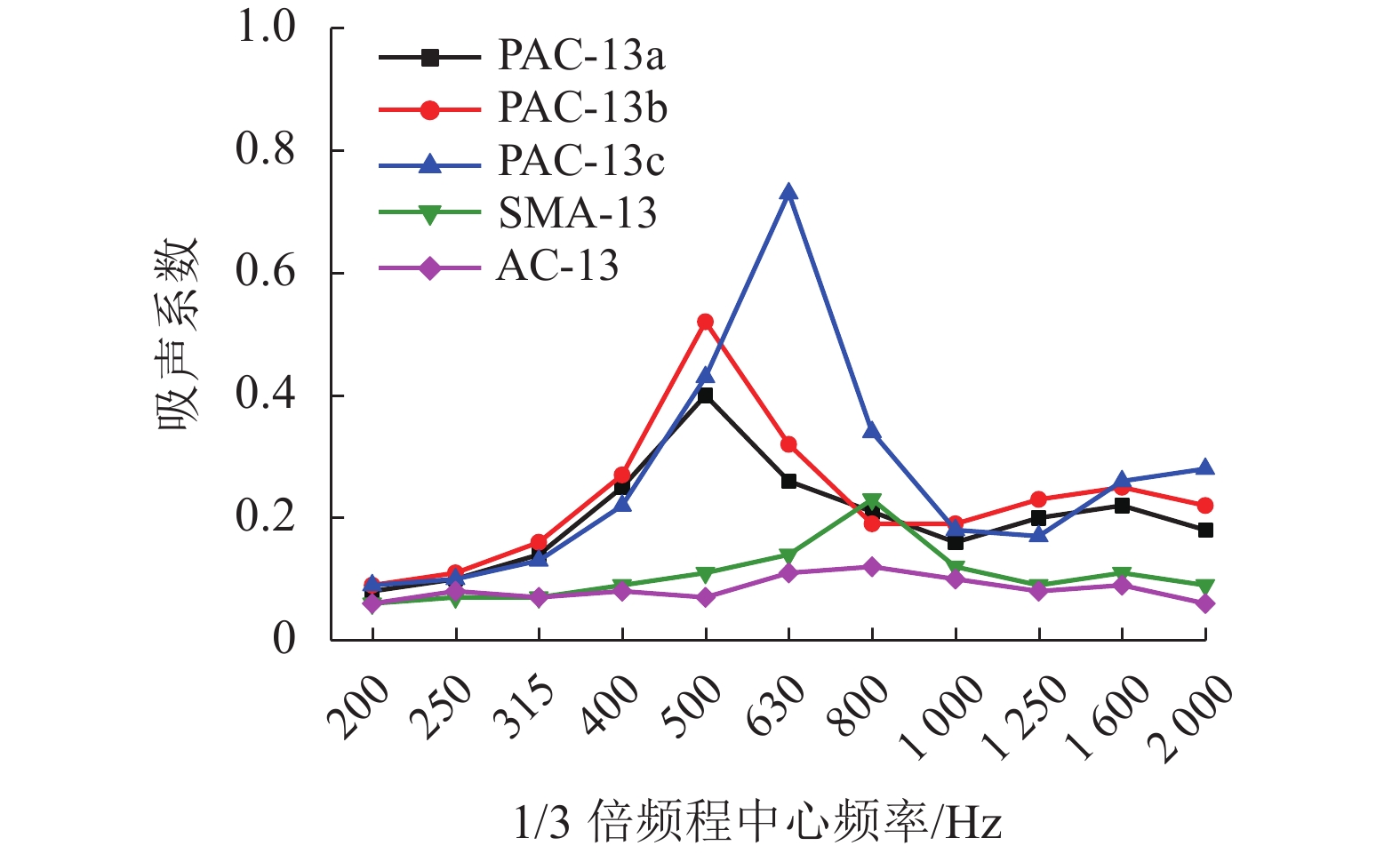
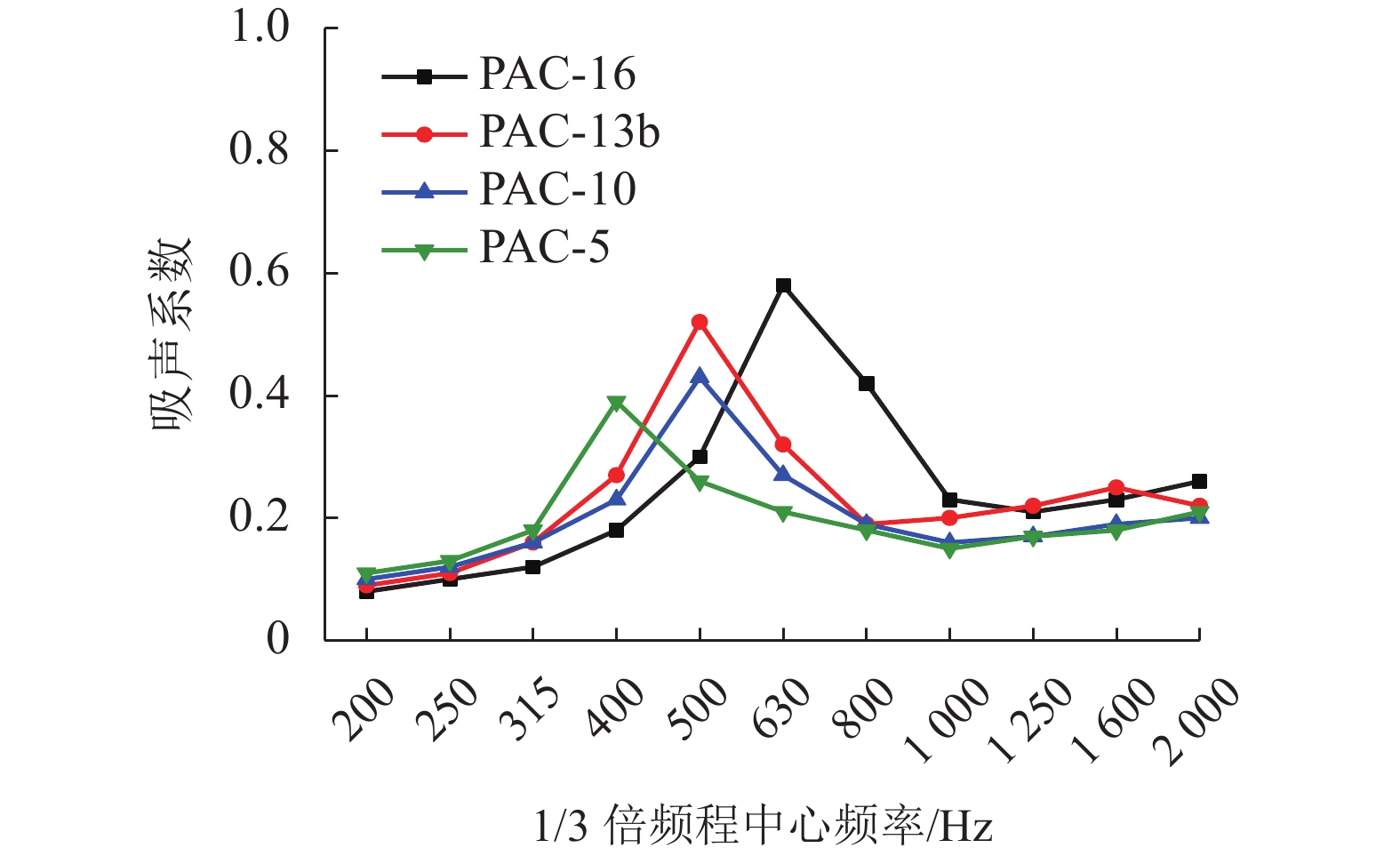
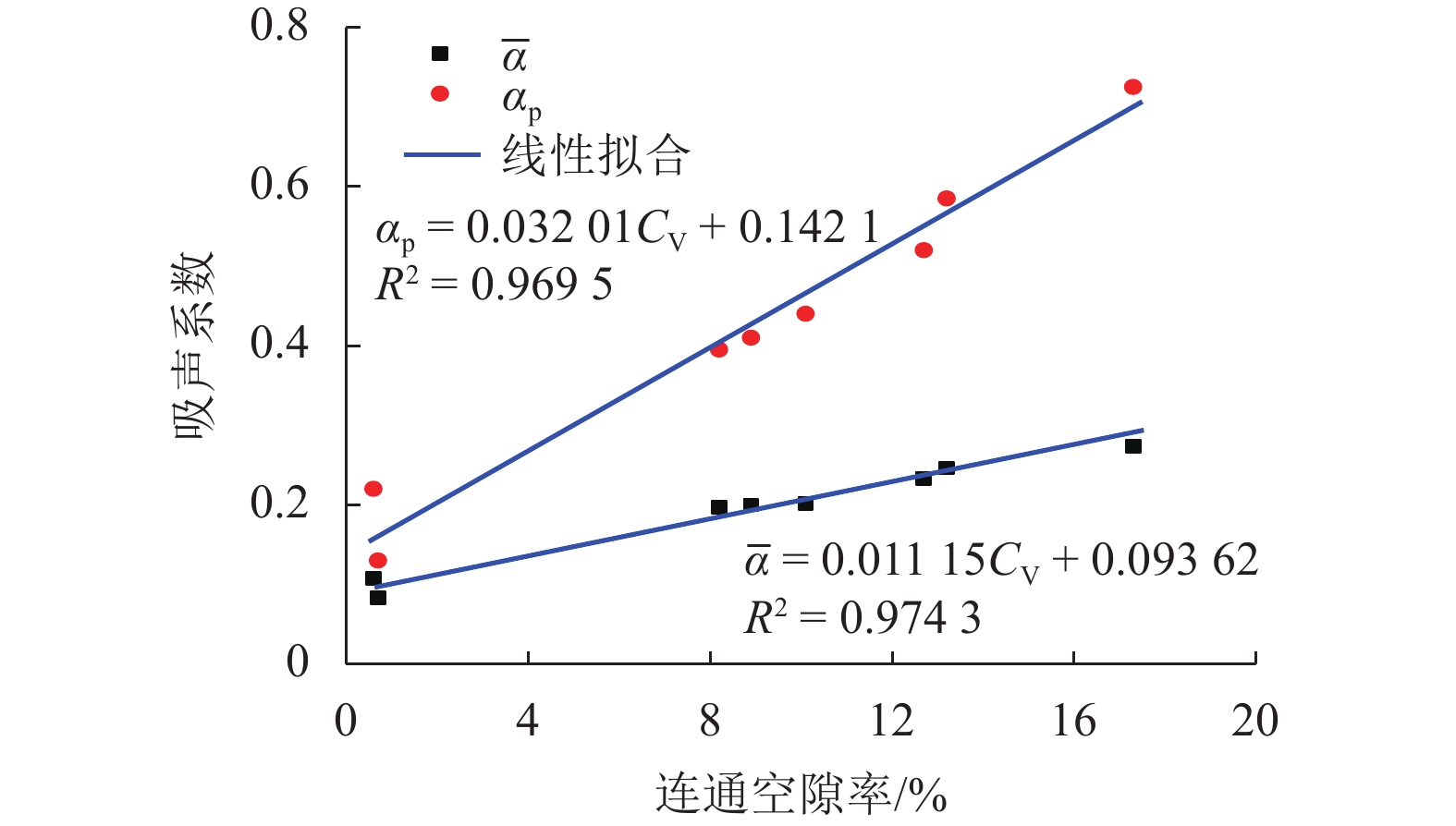
为了解决有标签语料获取困难的问题,提出了一种半监督学习的卷积神经网络(convolutional neural networks, CNN)汉语词义消歧方法. 首先,提取歧义词左右各2个词汇单元的词形、词性和语义类作为消歧特征,利用词向量工具将消歧特征向量化;然后,对有标签语料进行预处理,获取初始化聚类中心和阈值,同时,使用有标签语料对卷积神经网络消歧模型进行训练,利用优化后的卷积神经网络对无标签语料进行语义分类,选取满足阈值条件的高置信度语料添加到训练语料之中,不断重复上述过程,直到训练语料不再扩大为止;最后,使用SemEval-2007:Task#5作为有标签语料,使用哈尔滨工业大学无标注语料作为无标签语料进行实验. 实验结果表明:所提出方法使CNN的消歧准确率提高了3.1%.


 高级检索
高级检索
 Email alert
Email alert RSS
RSS 摘要
摘要 HTML全文
HTML全文 PDF 2368KB
PDF 2368KB 附件
附件 施引文献
施引文献