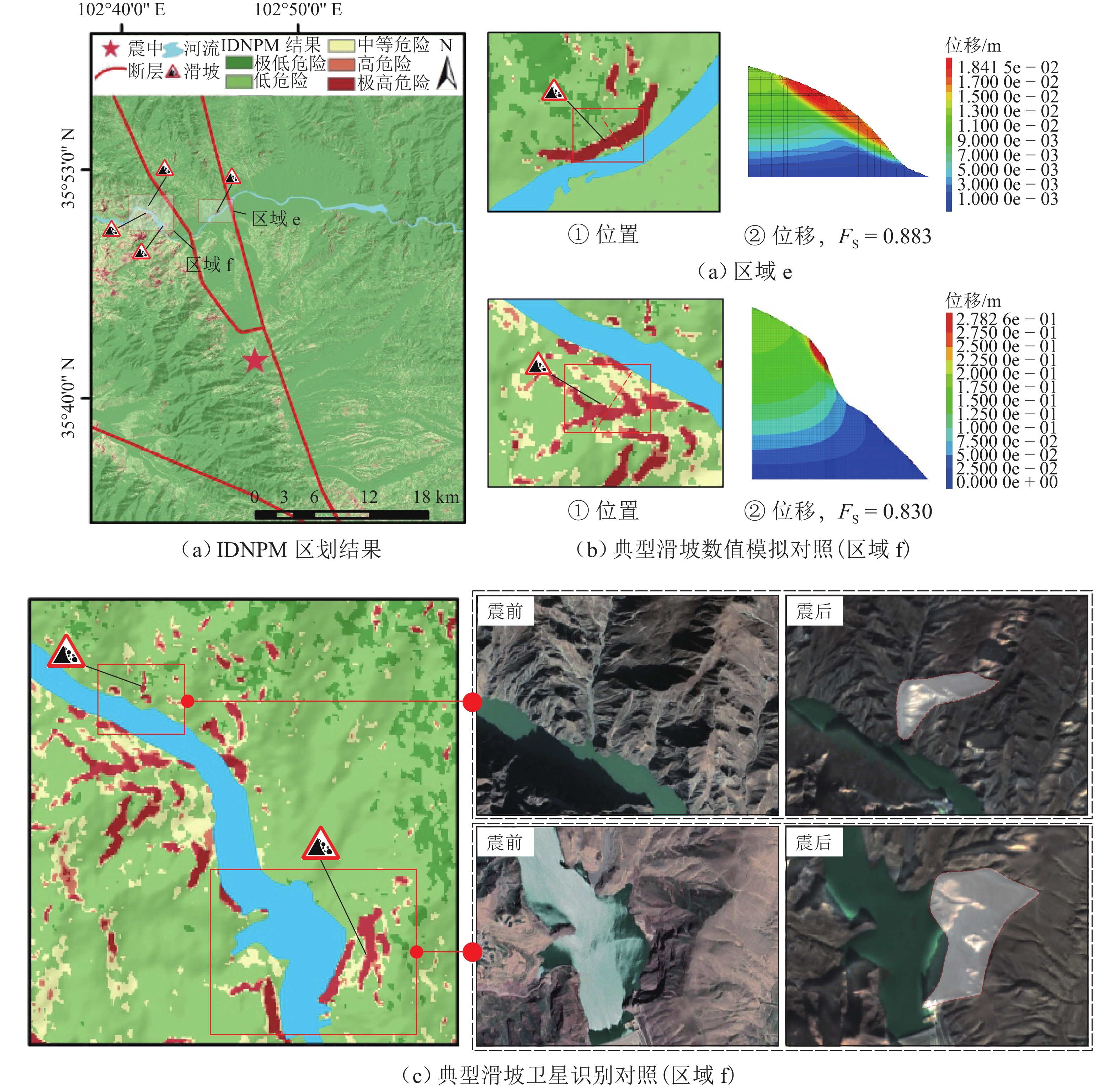
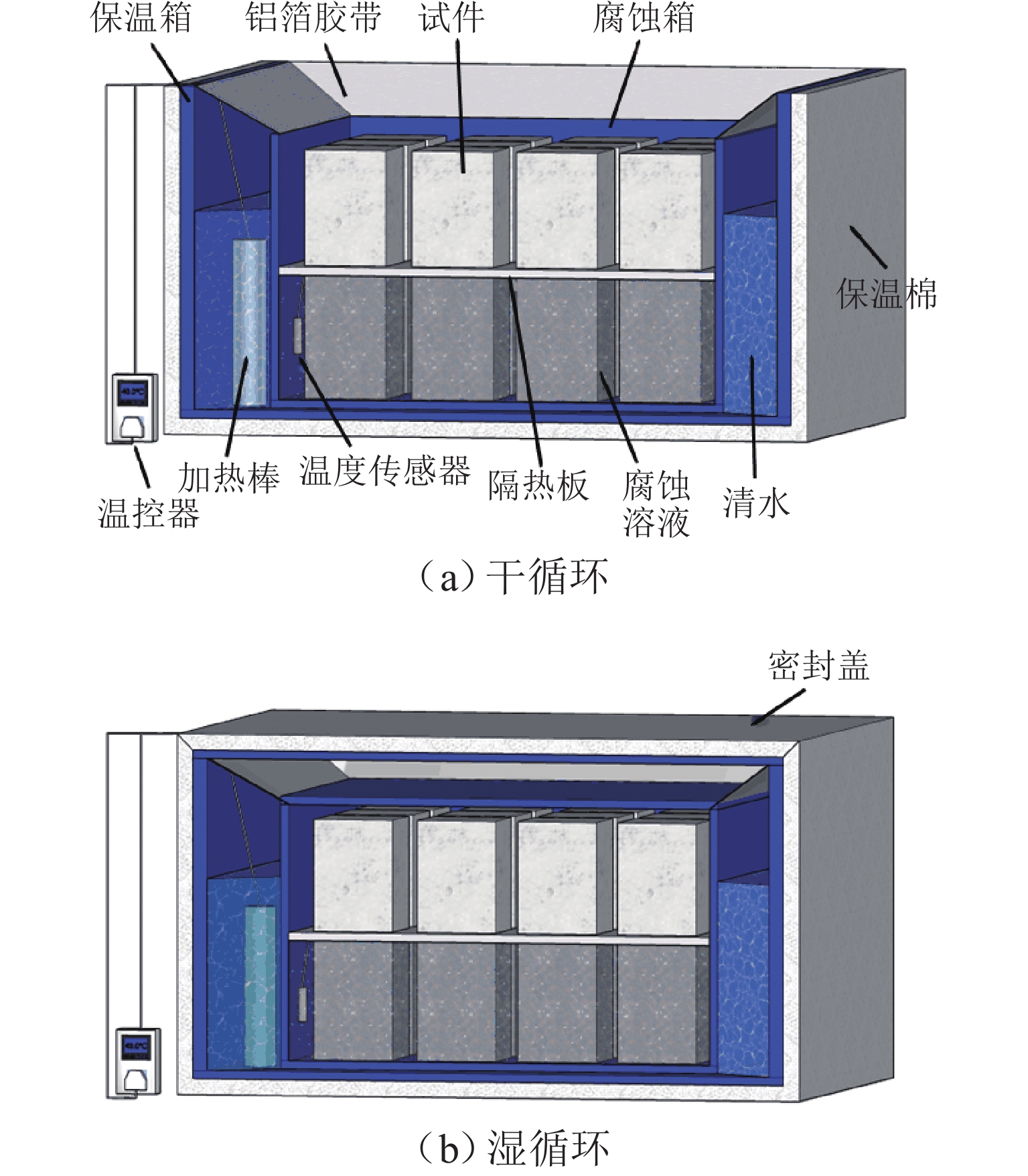
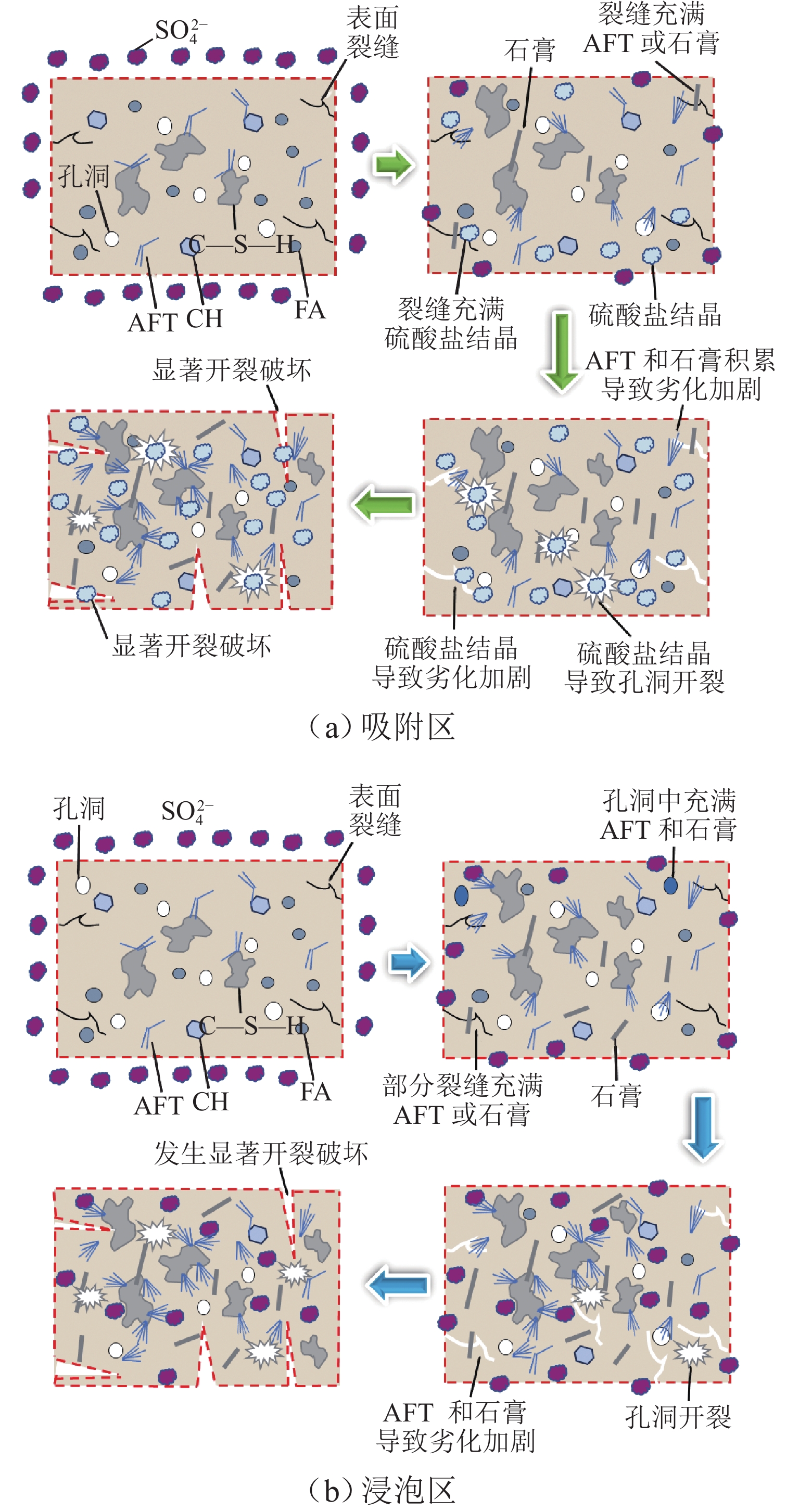
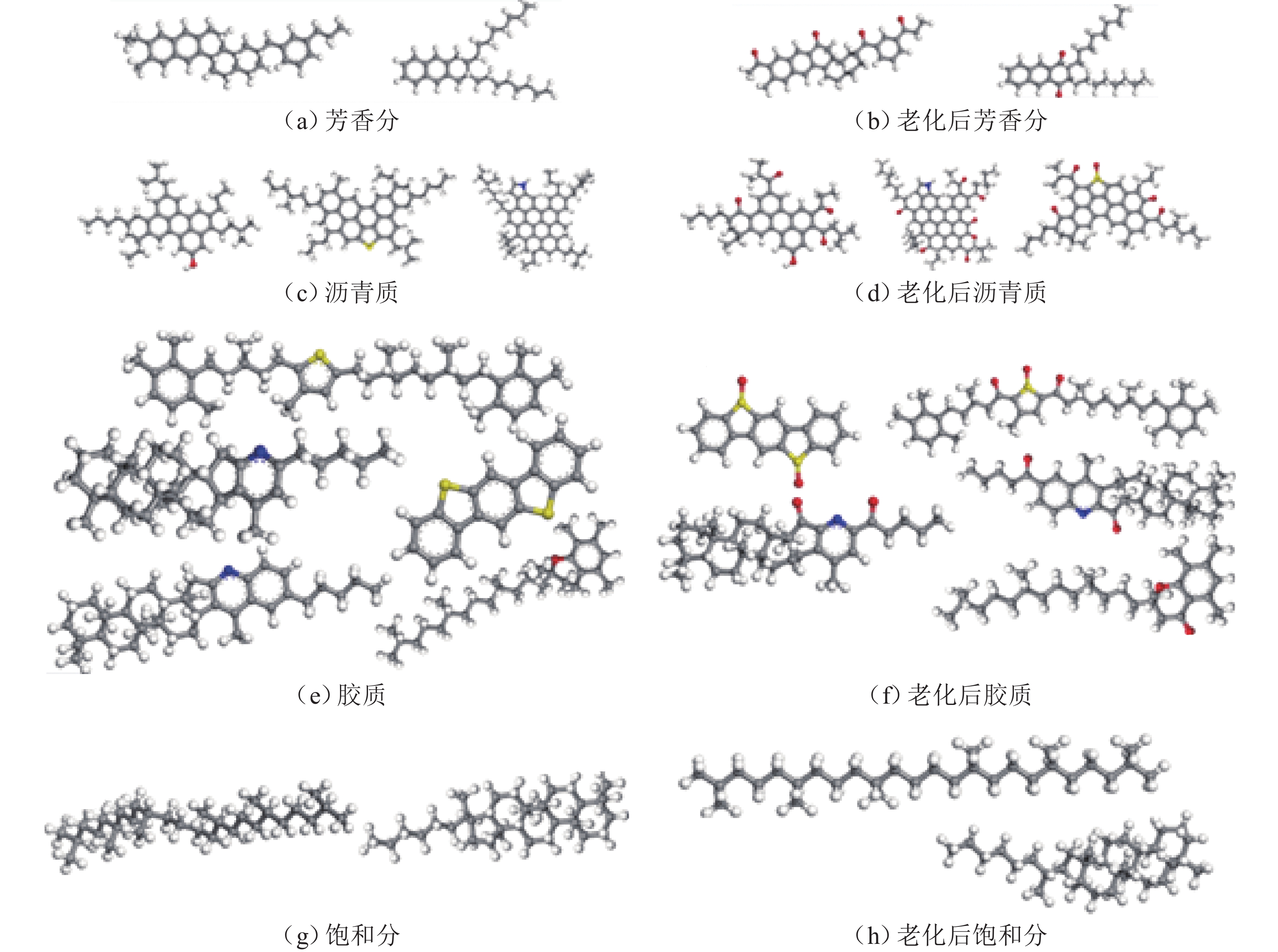
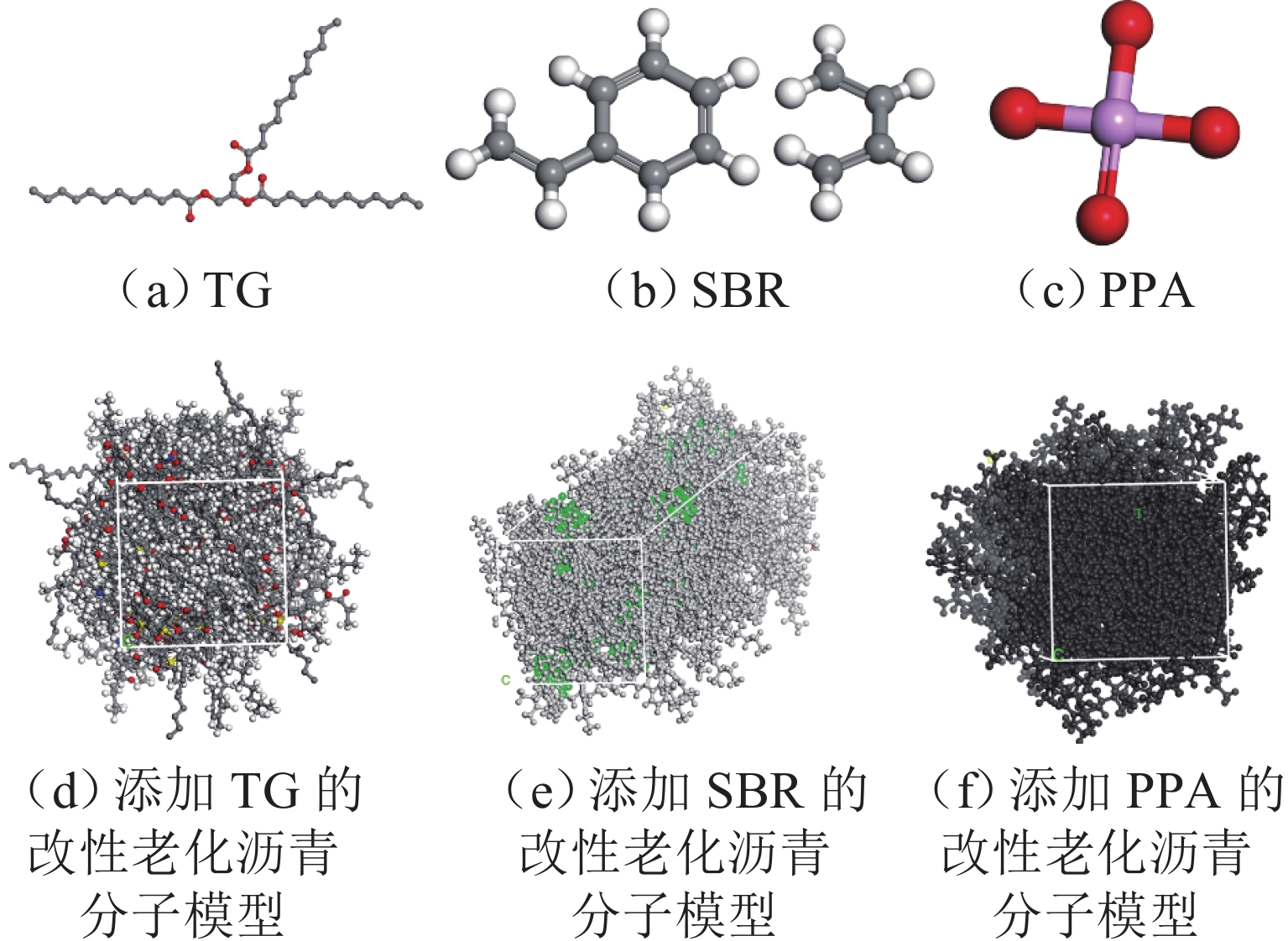
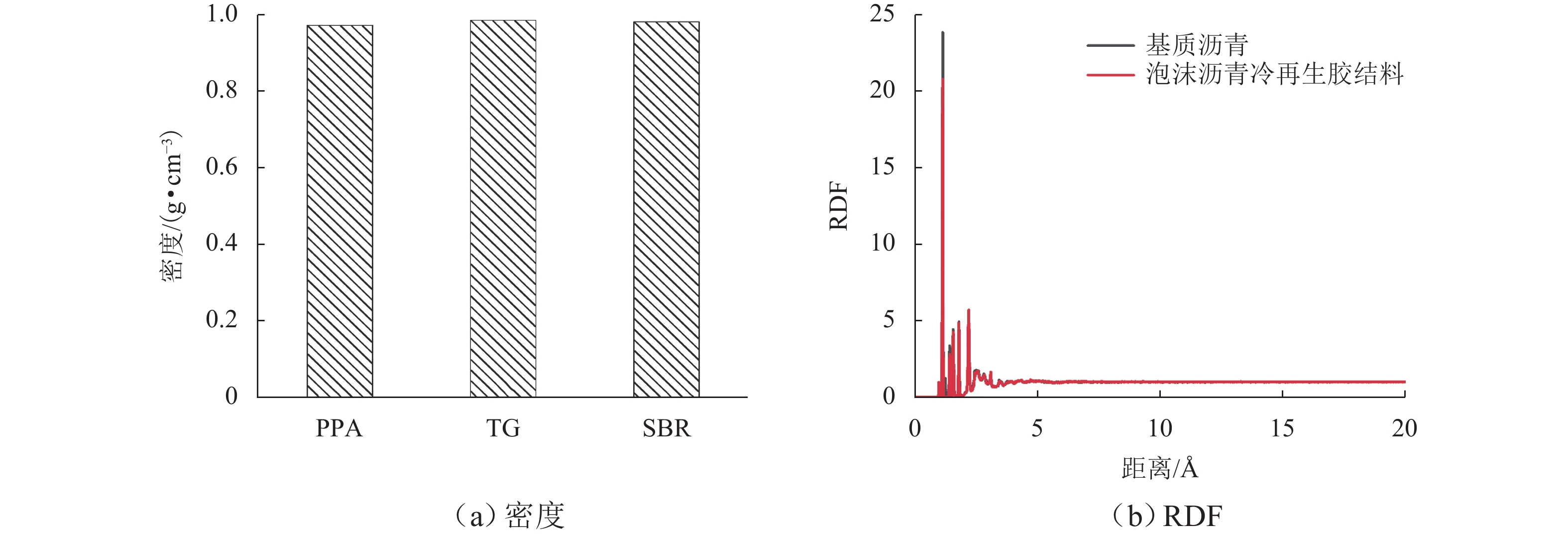
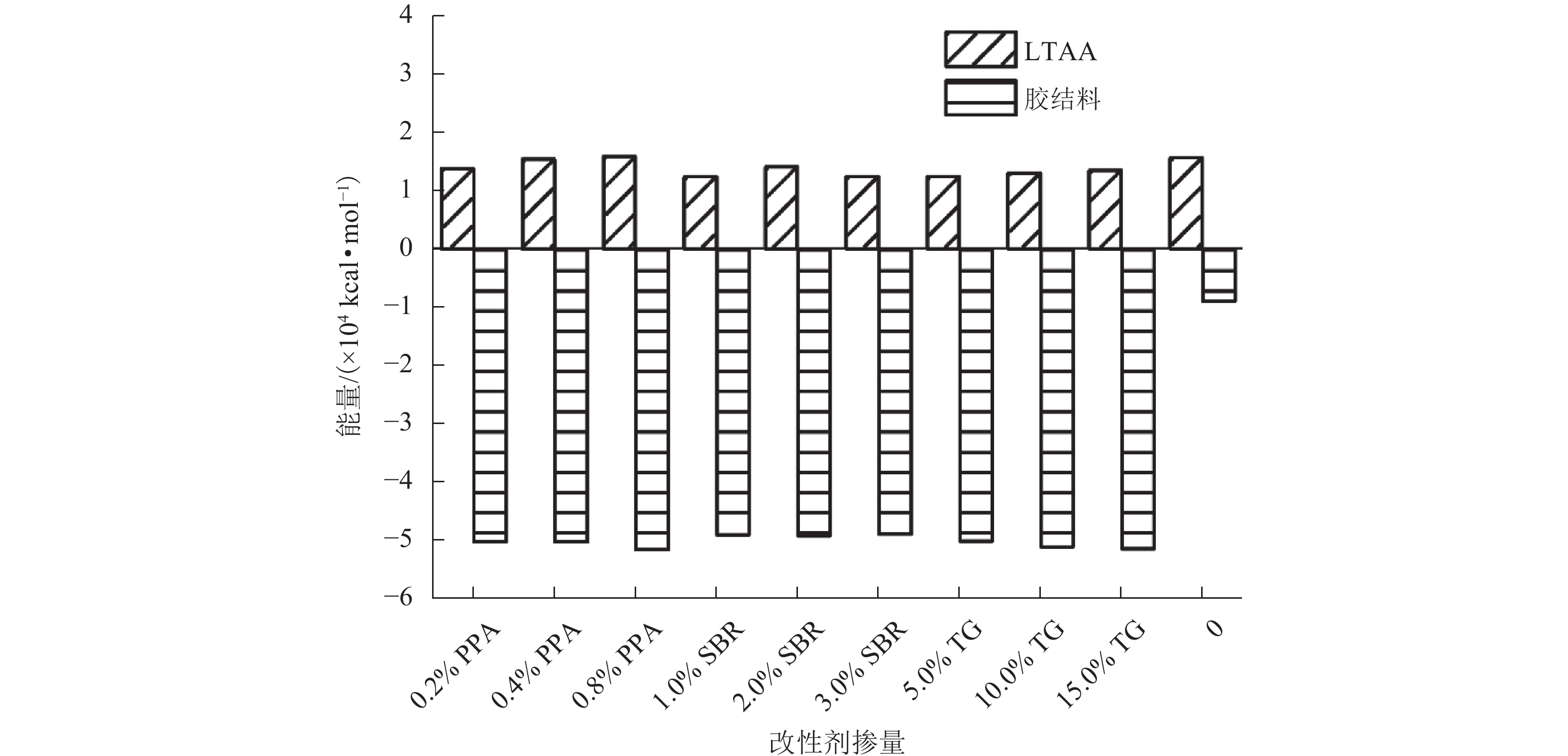
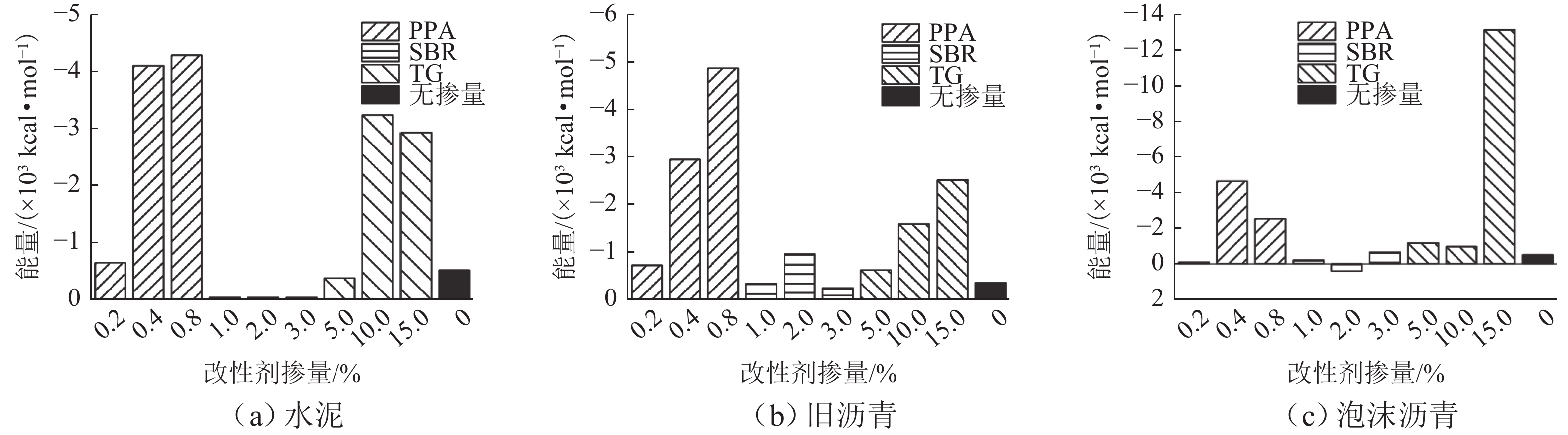
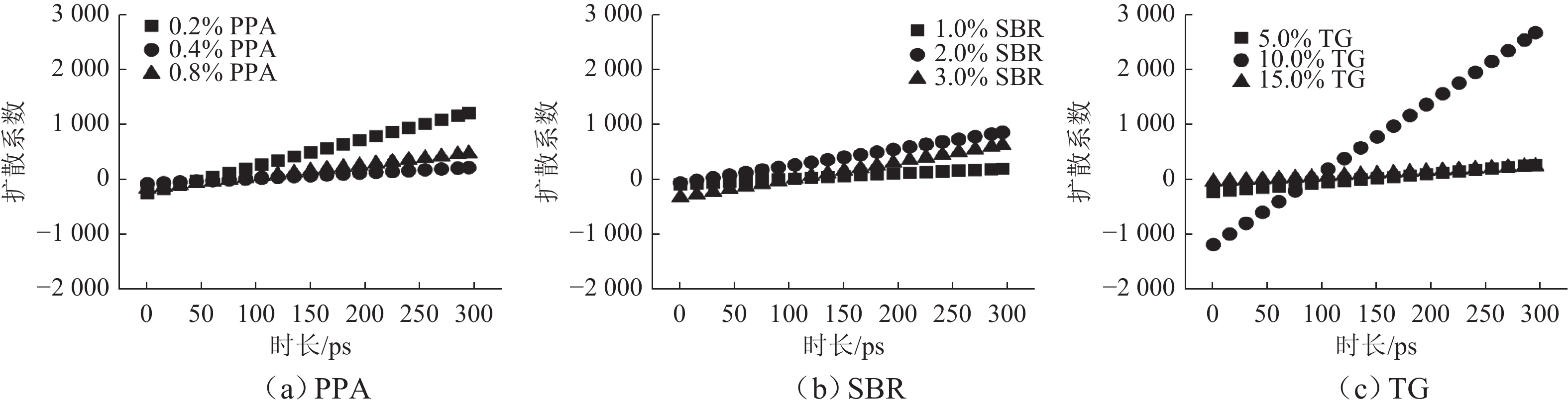
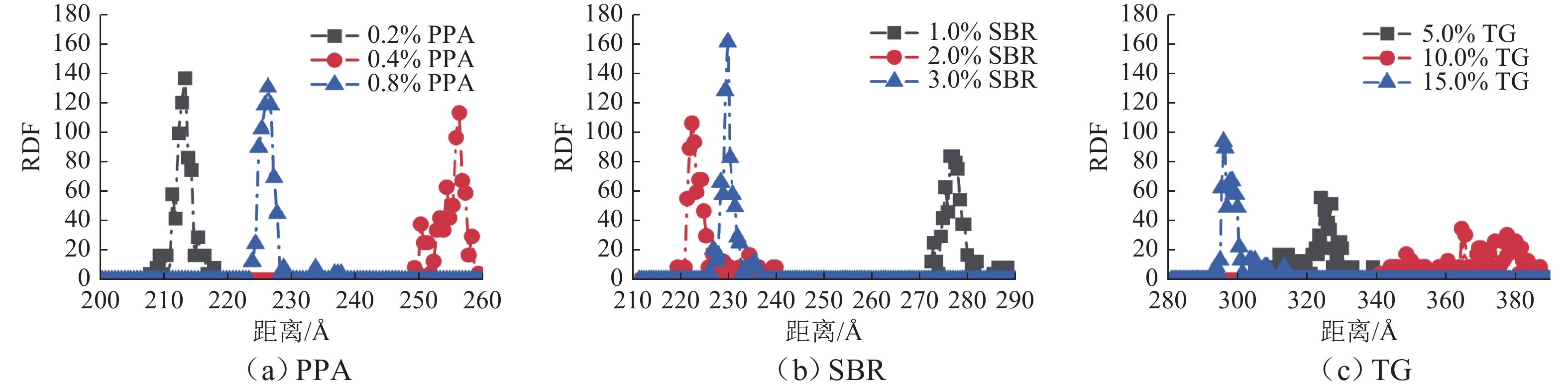
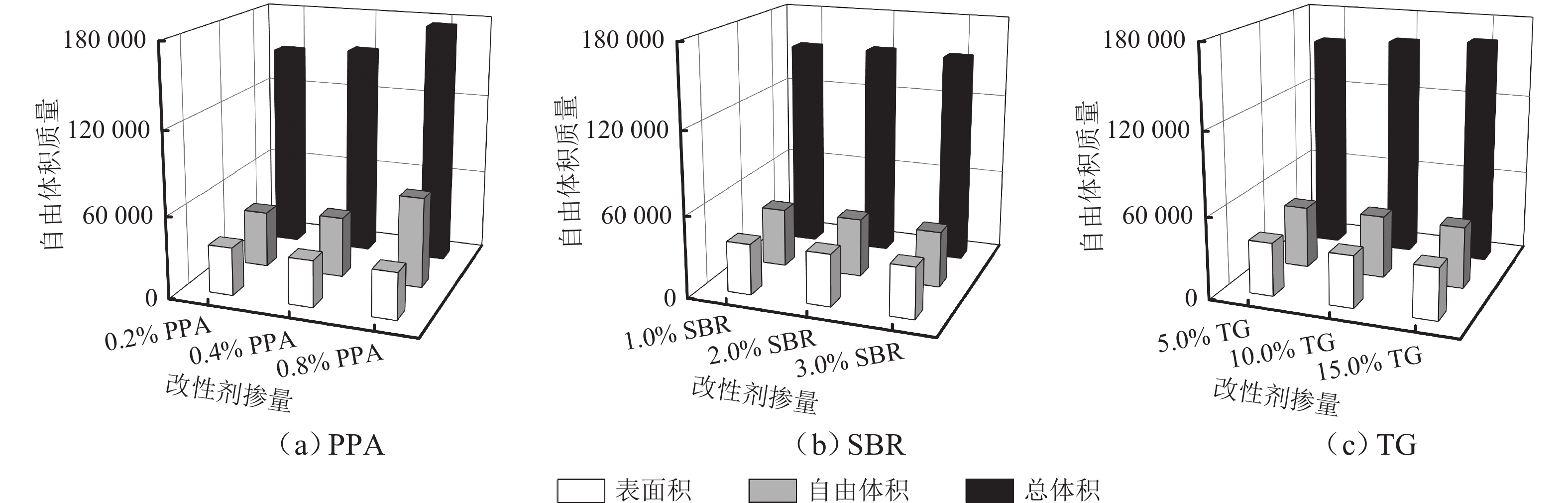
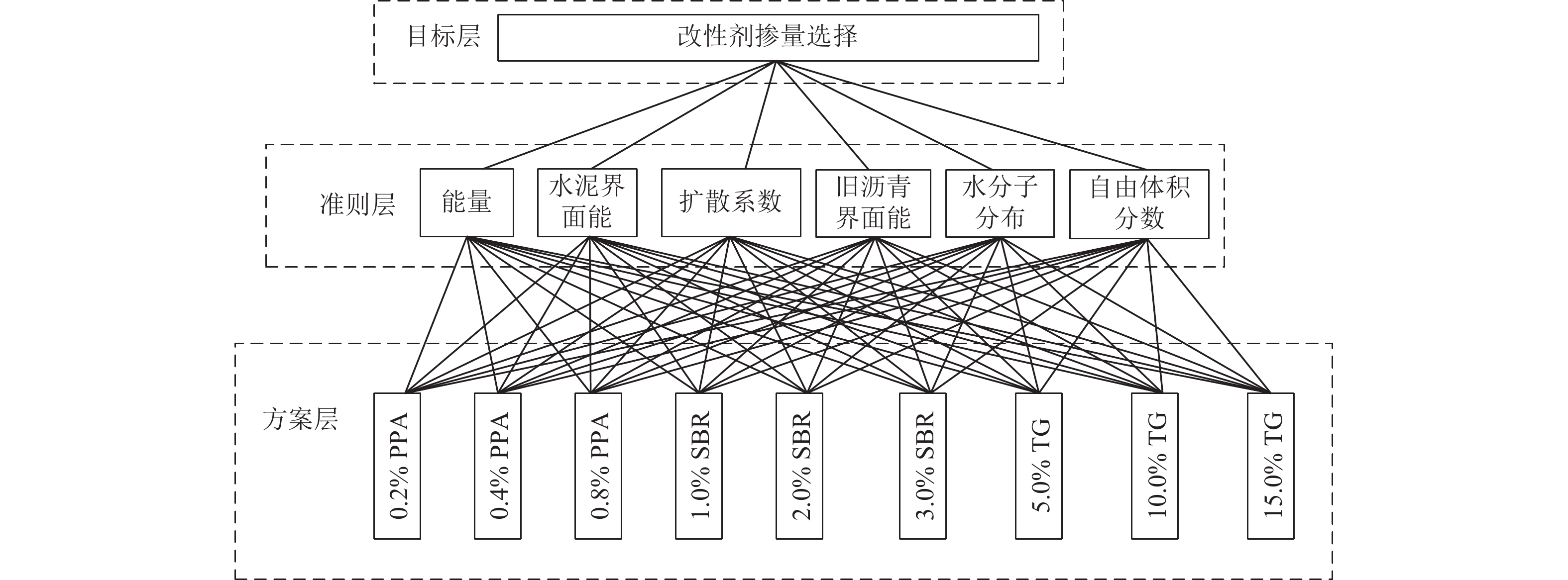
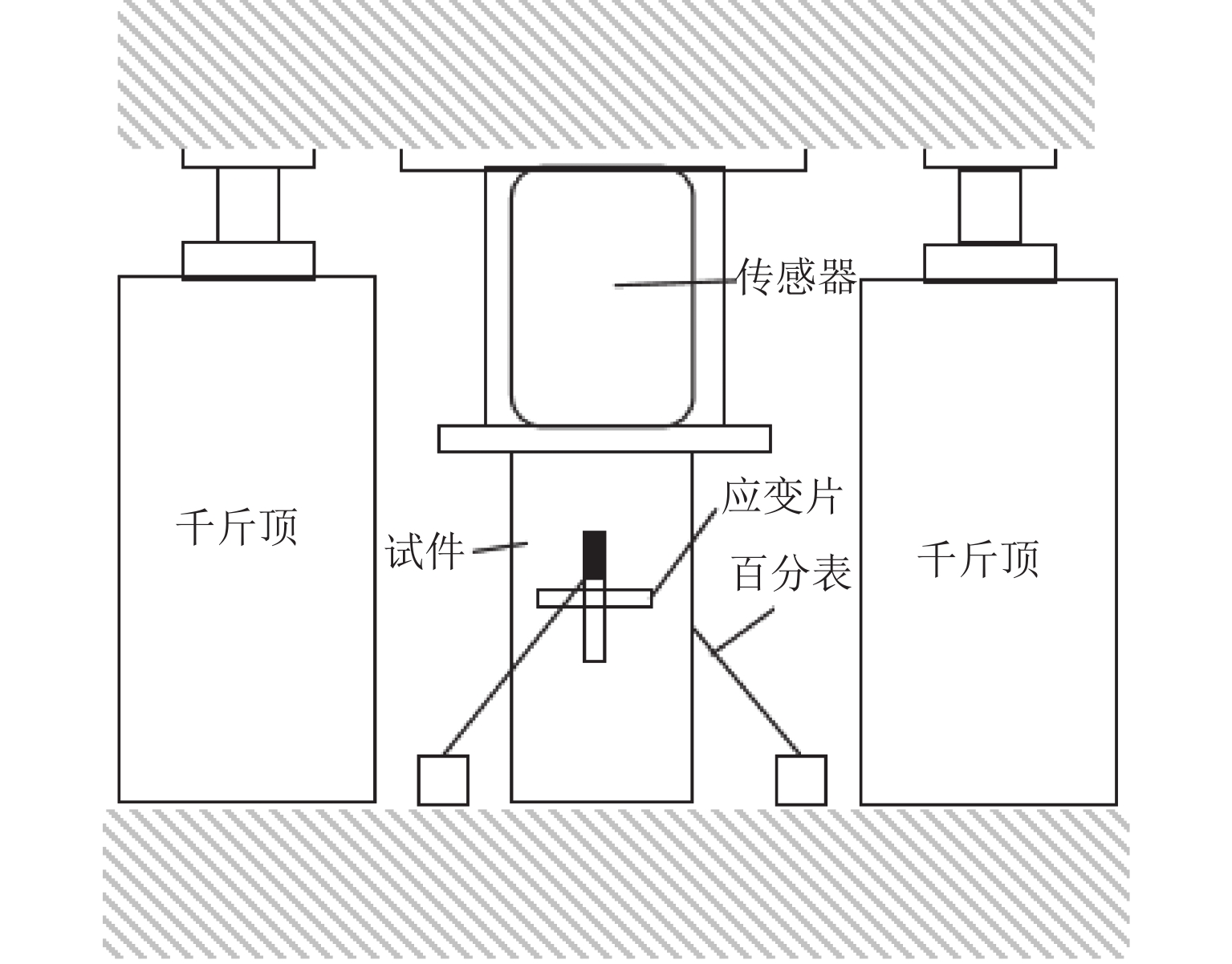
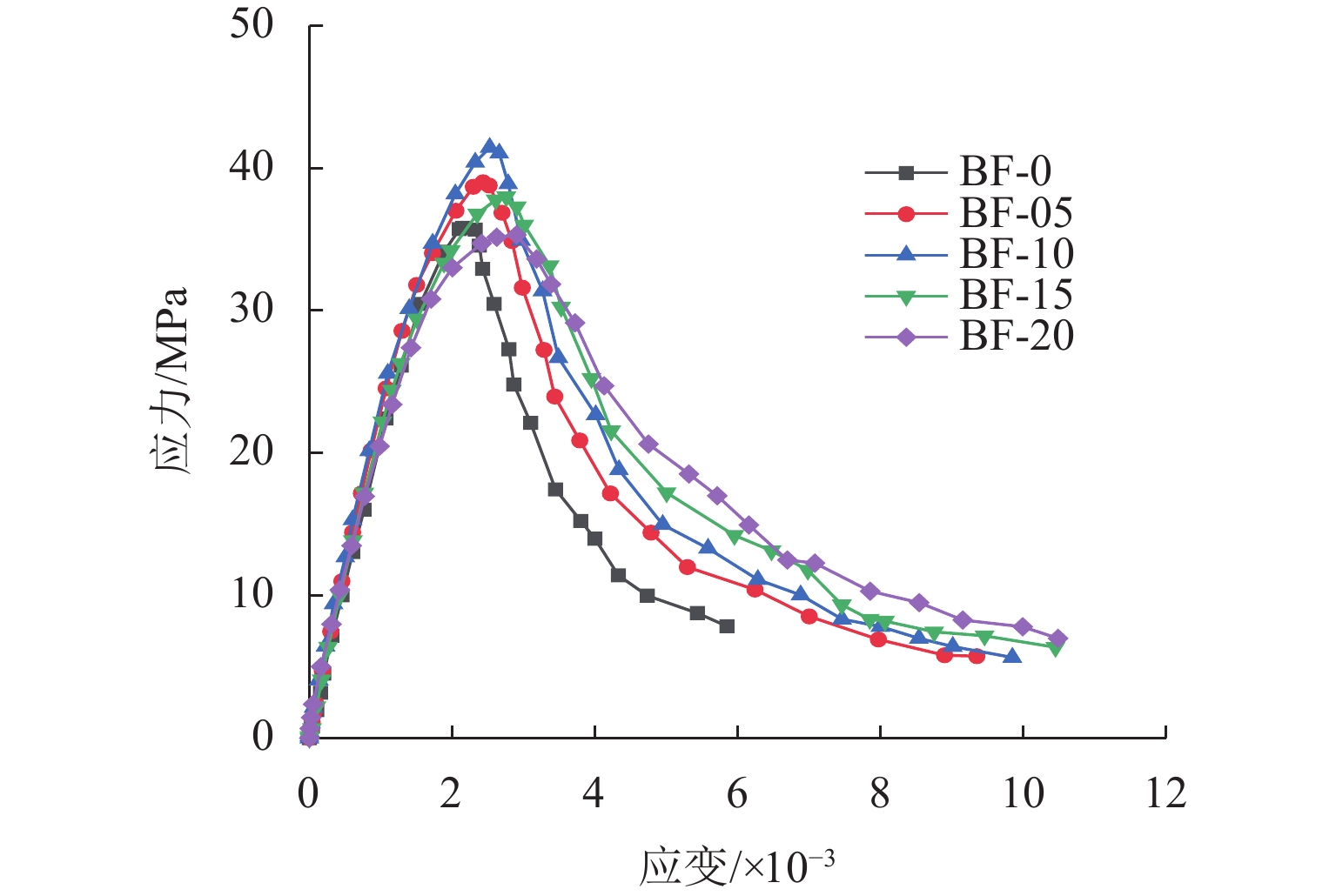
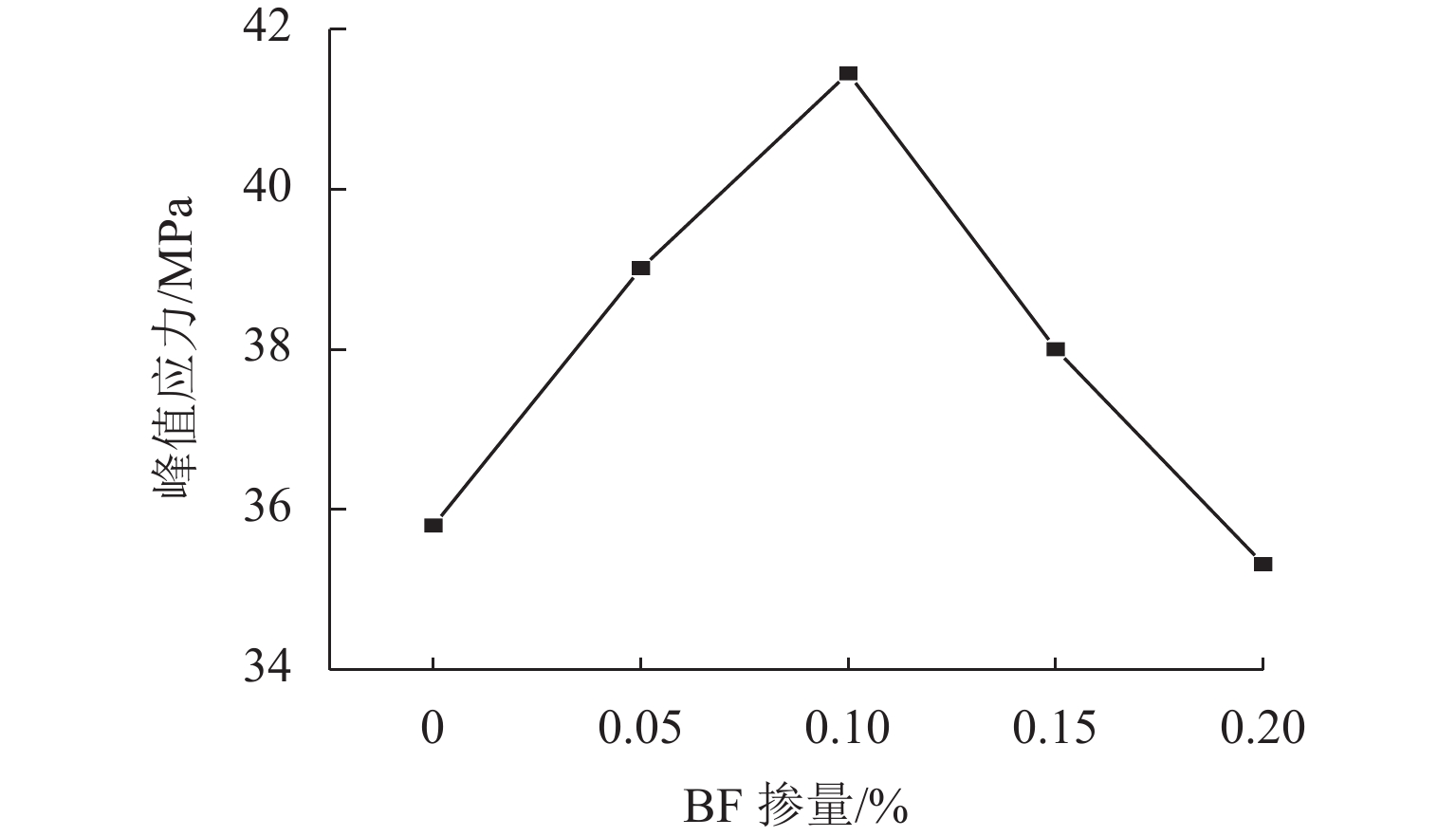
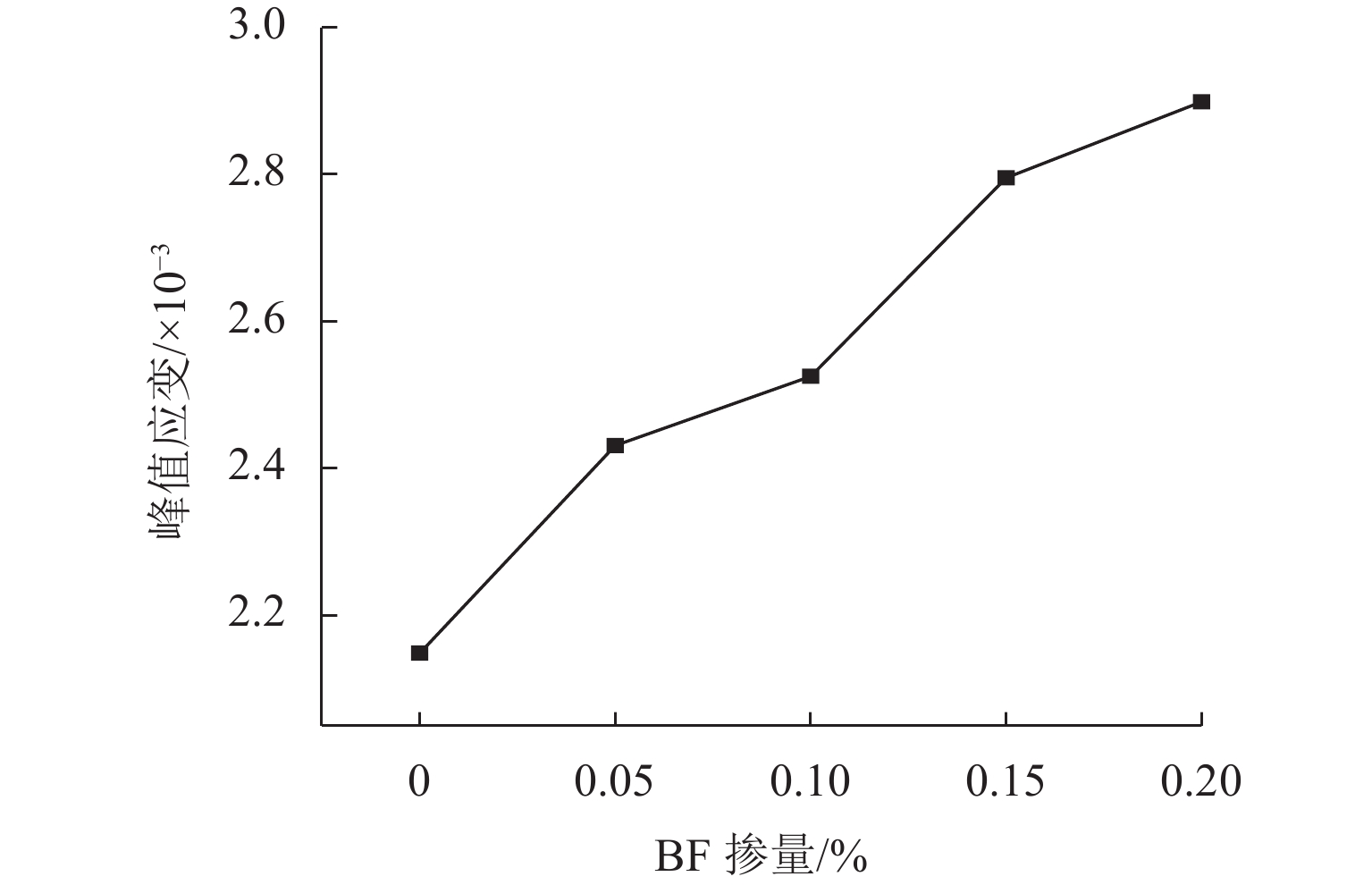
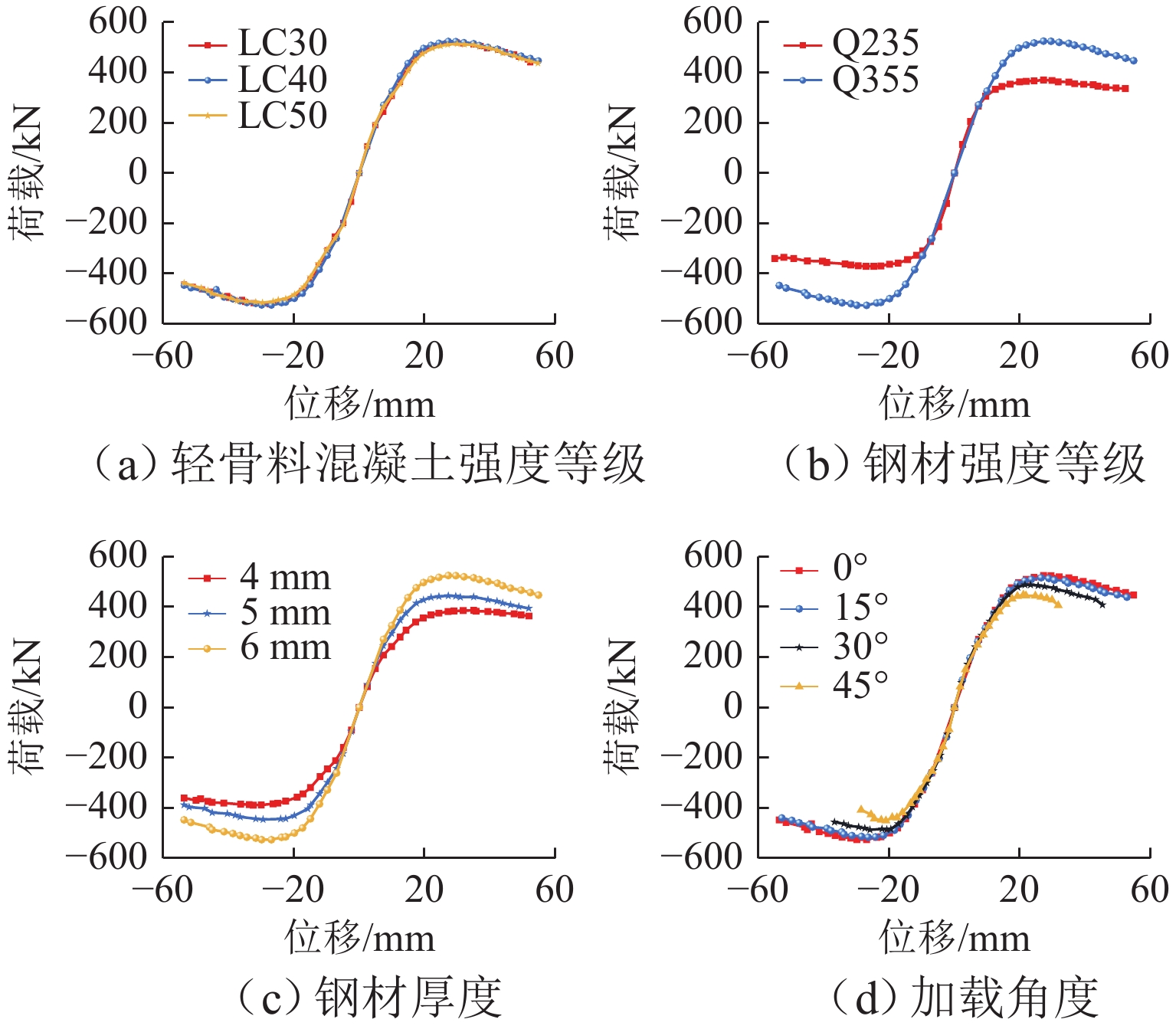
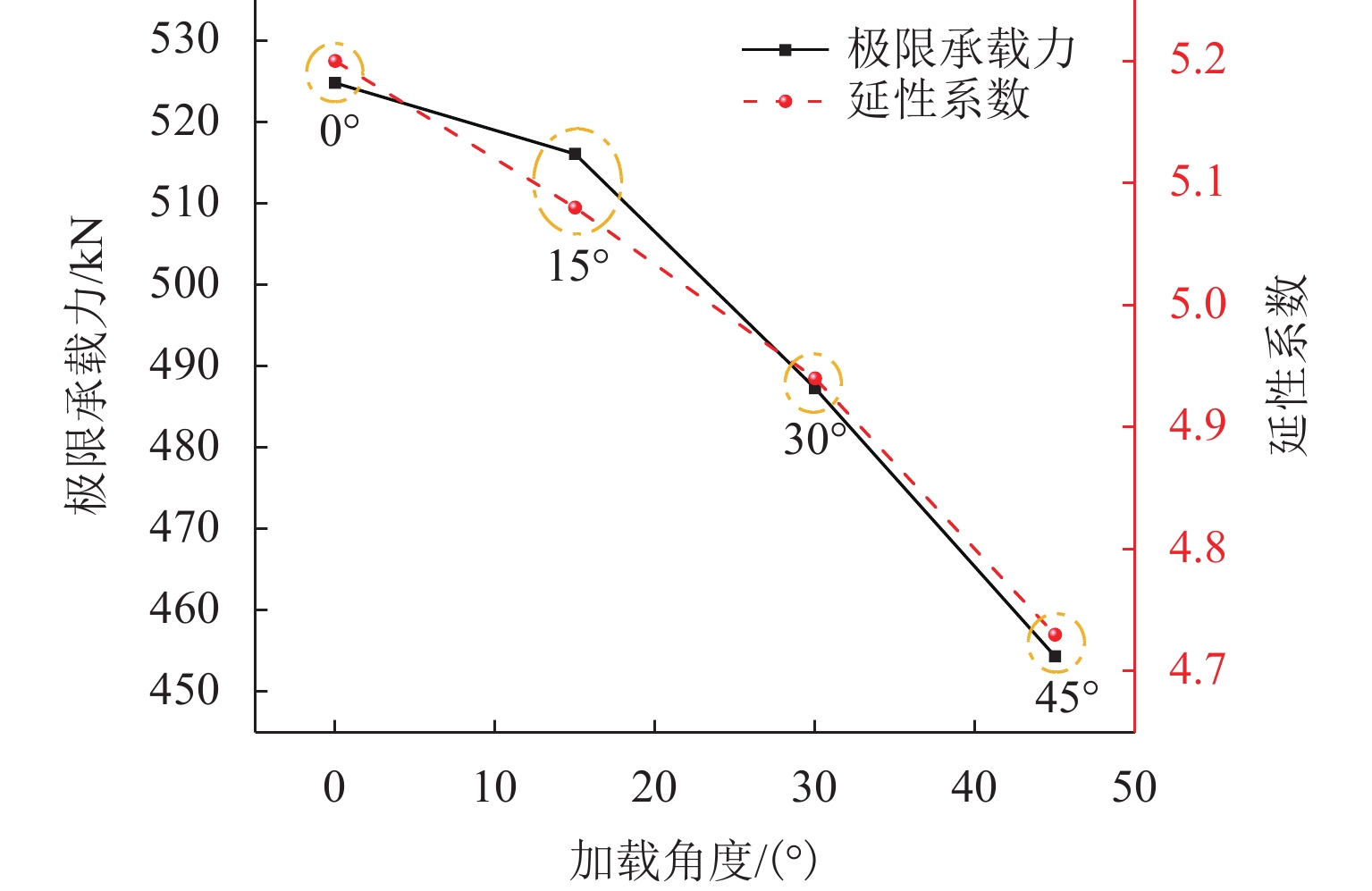
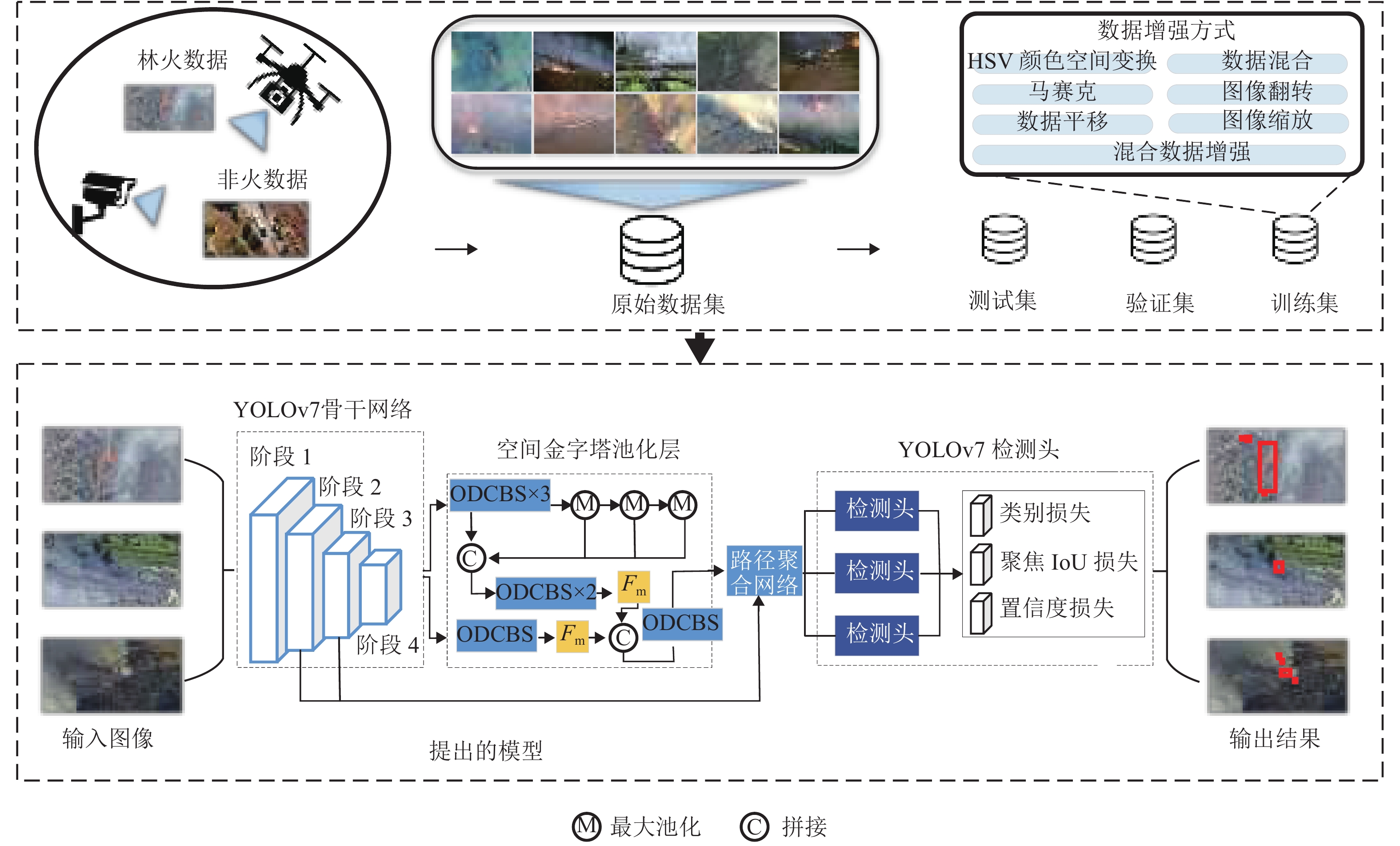
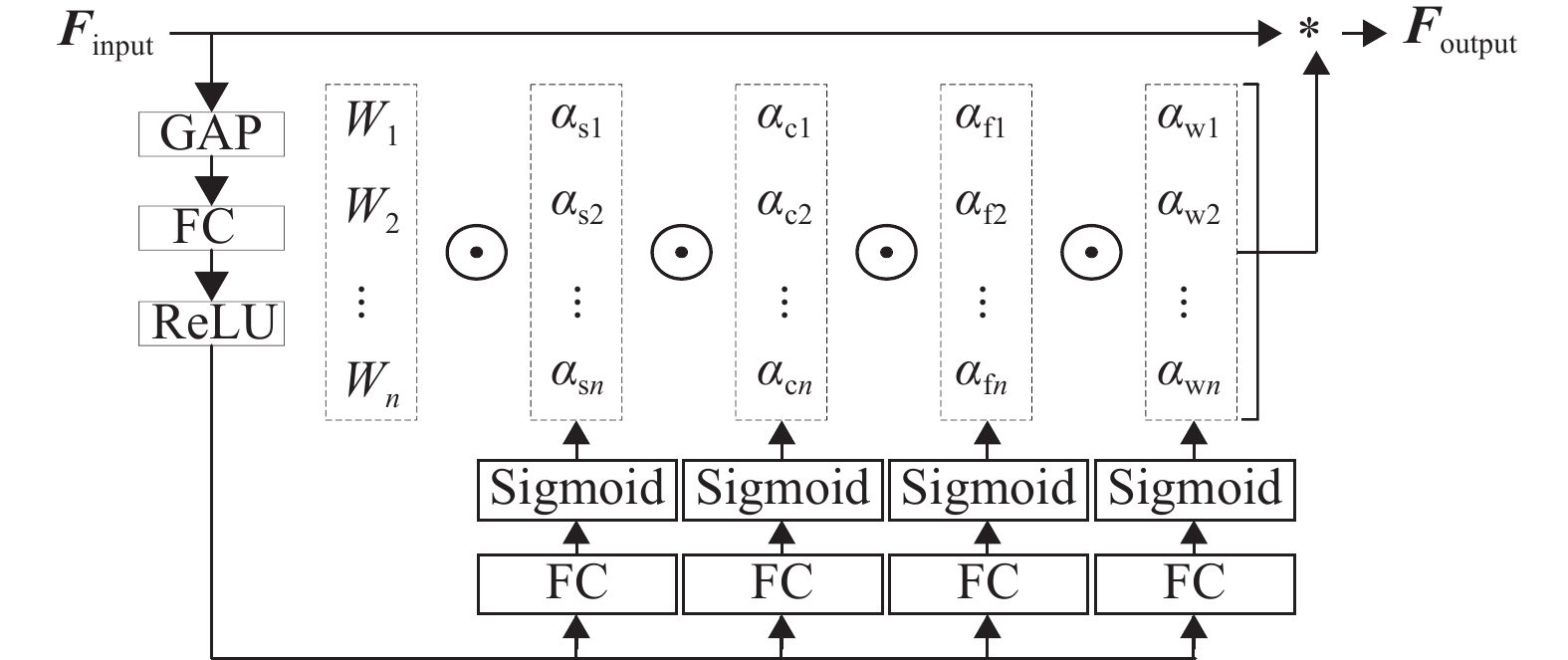
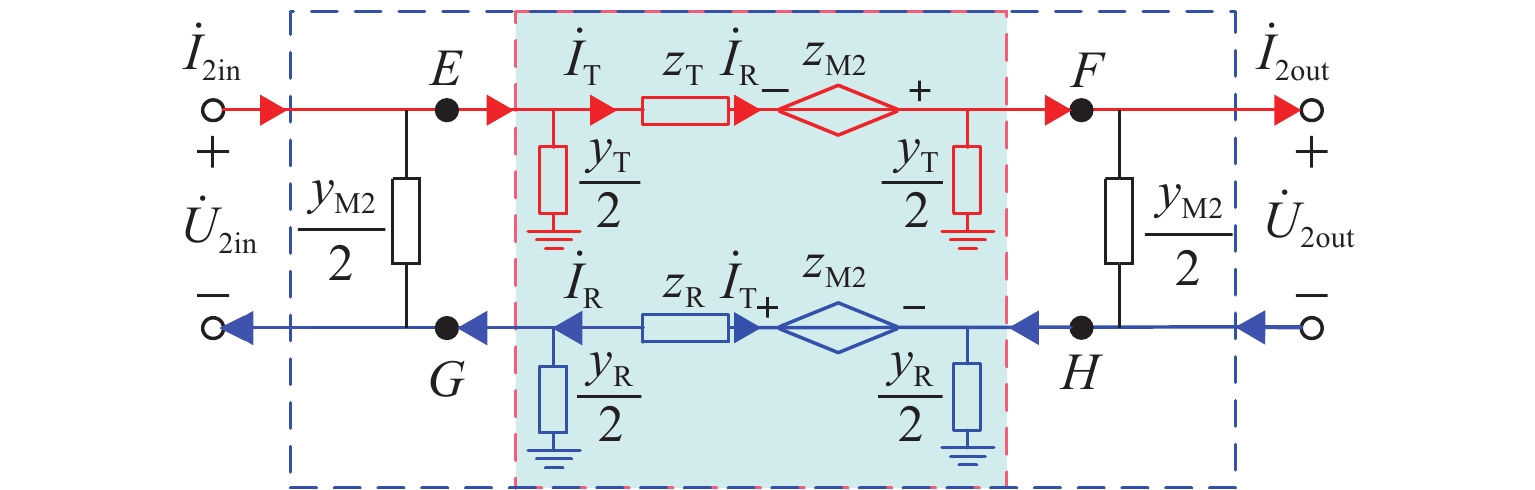
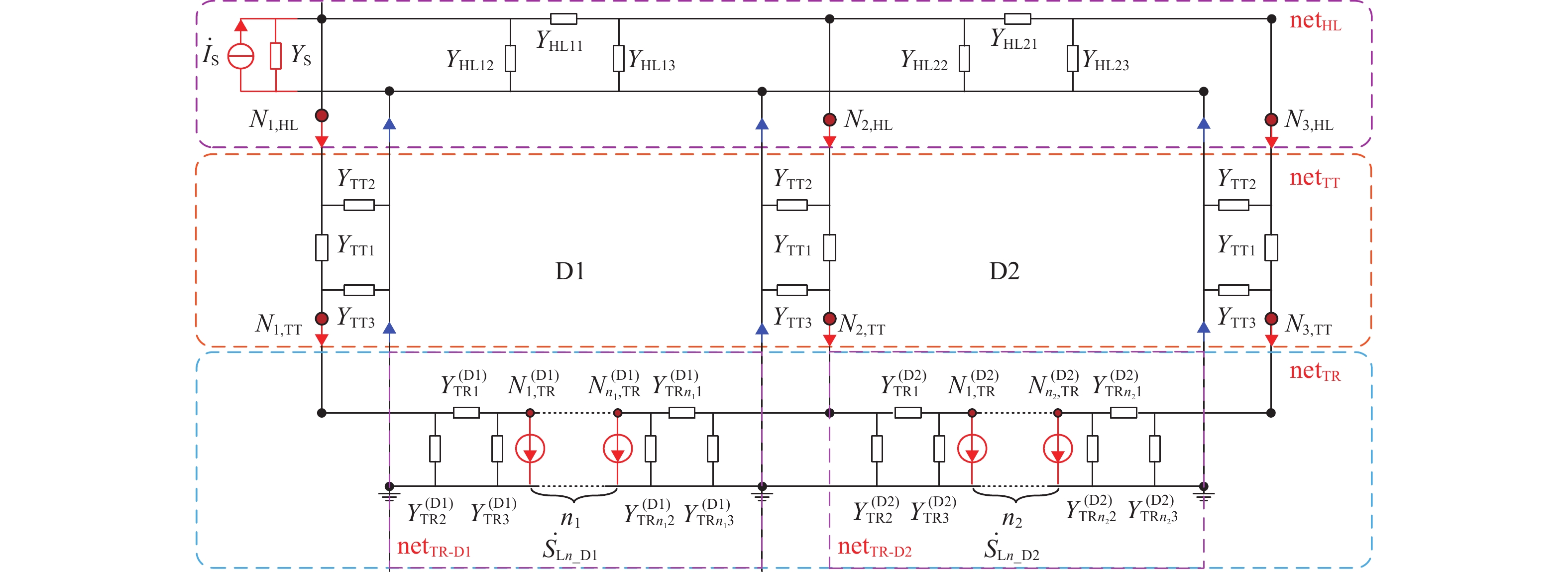
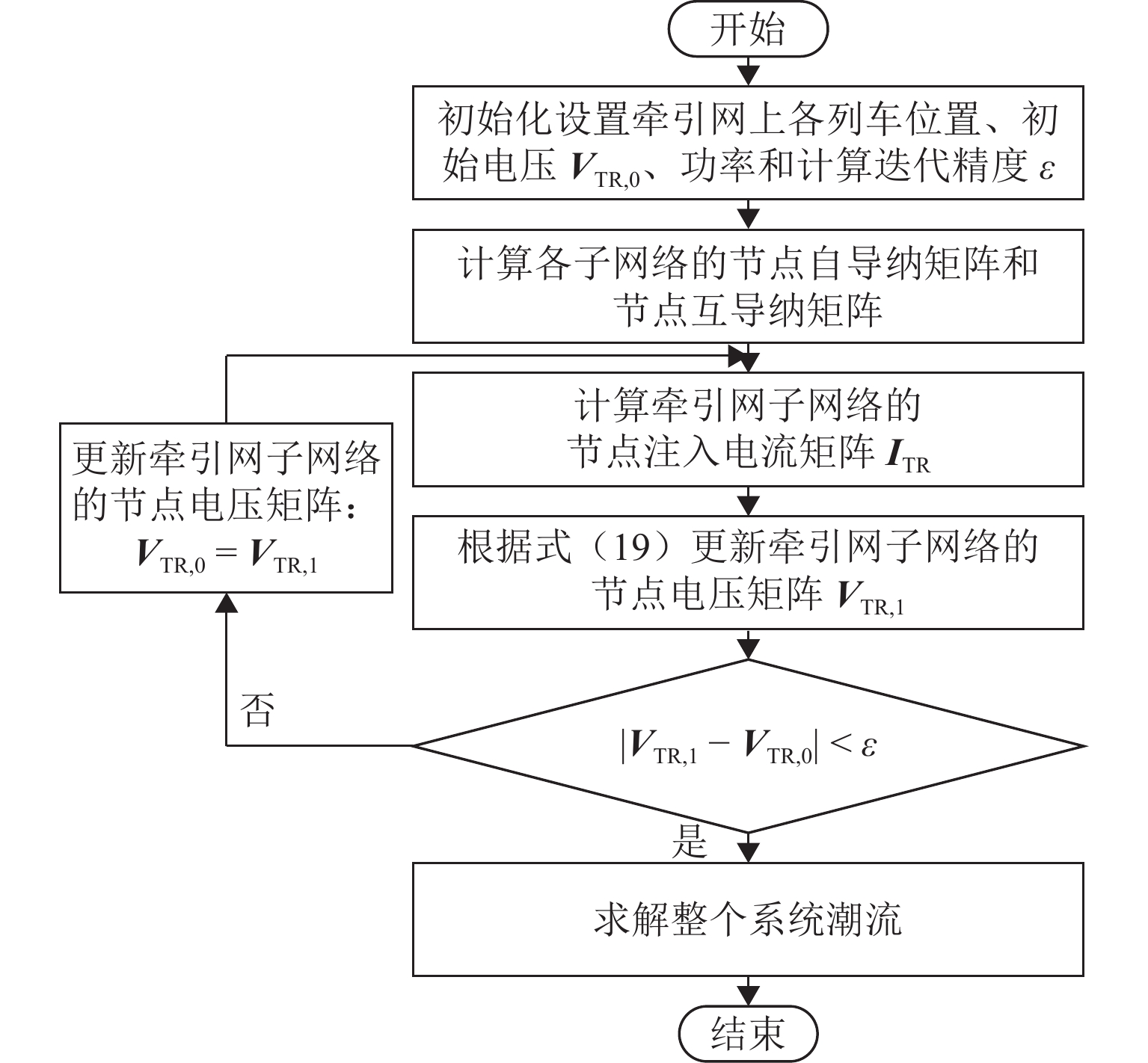
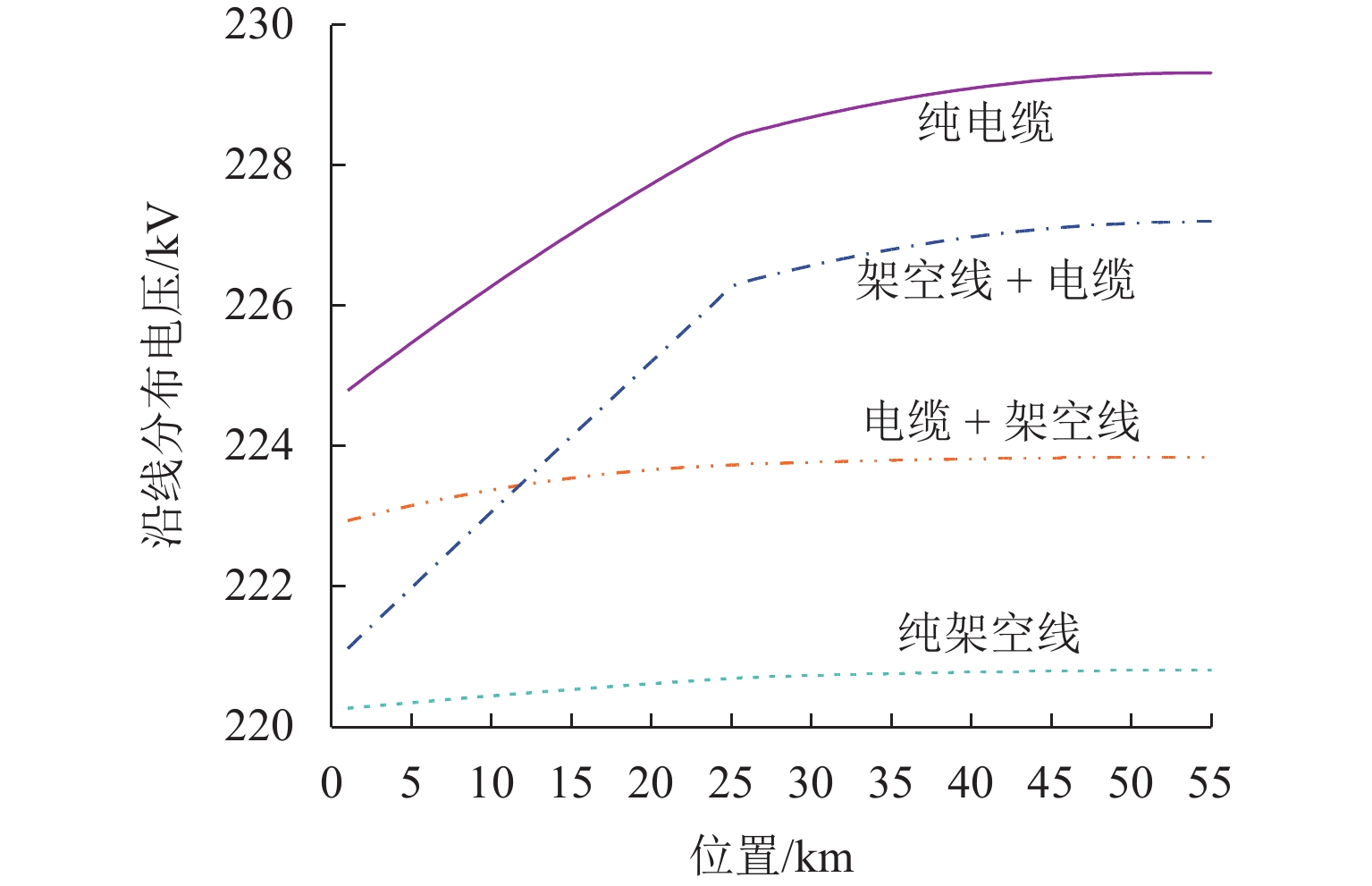
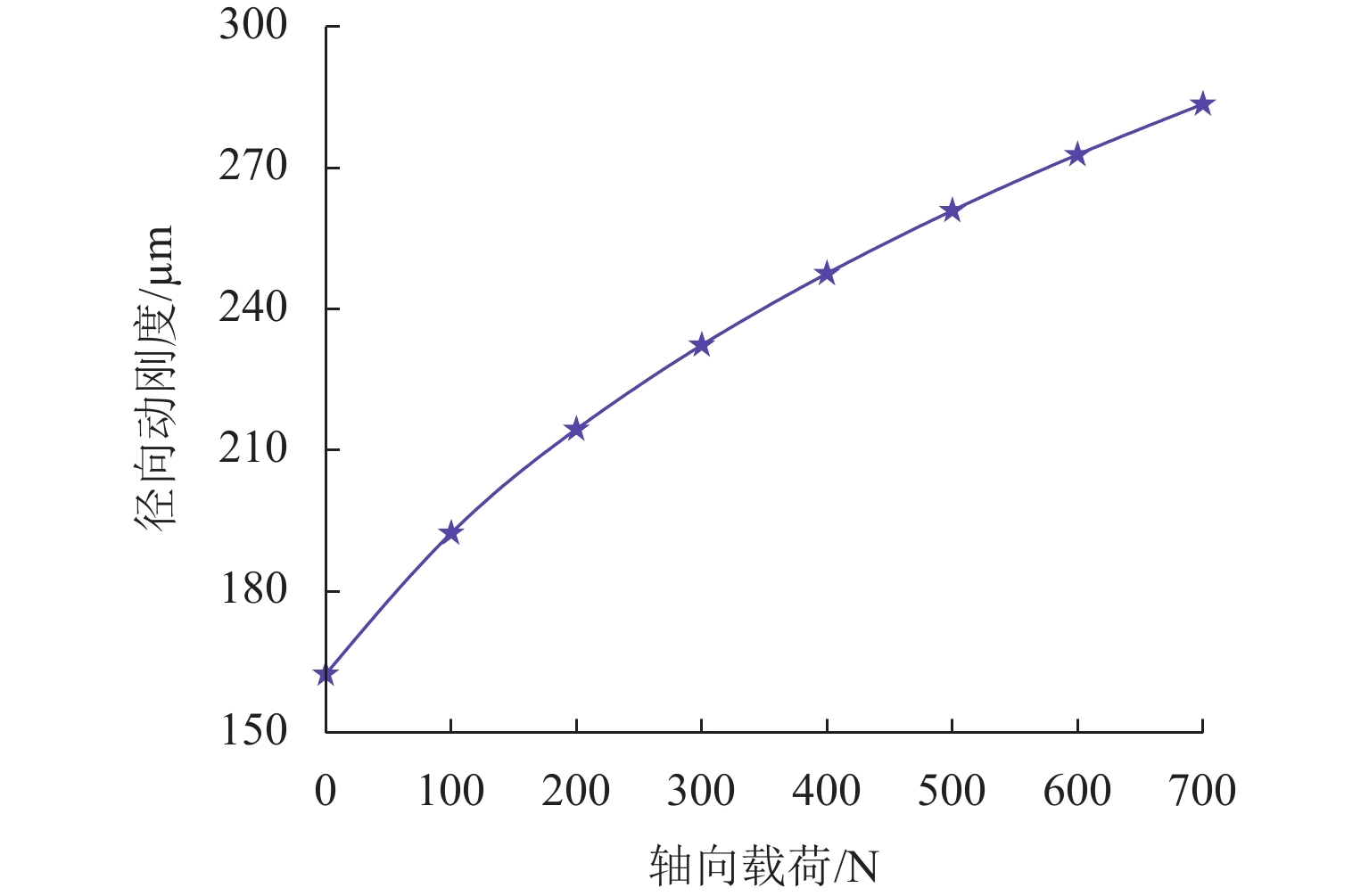
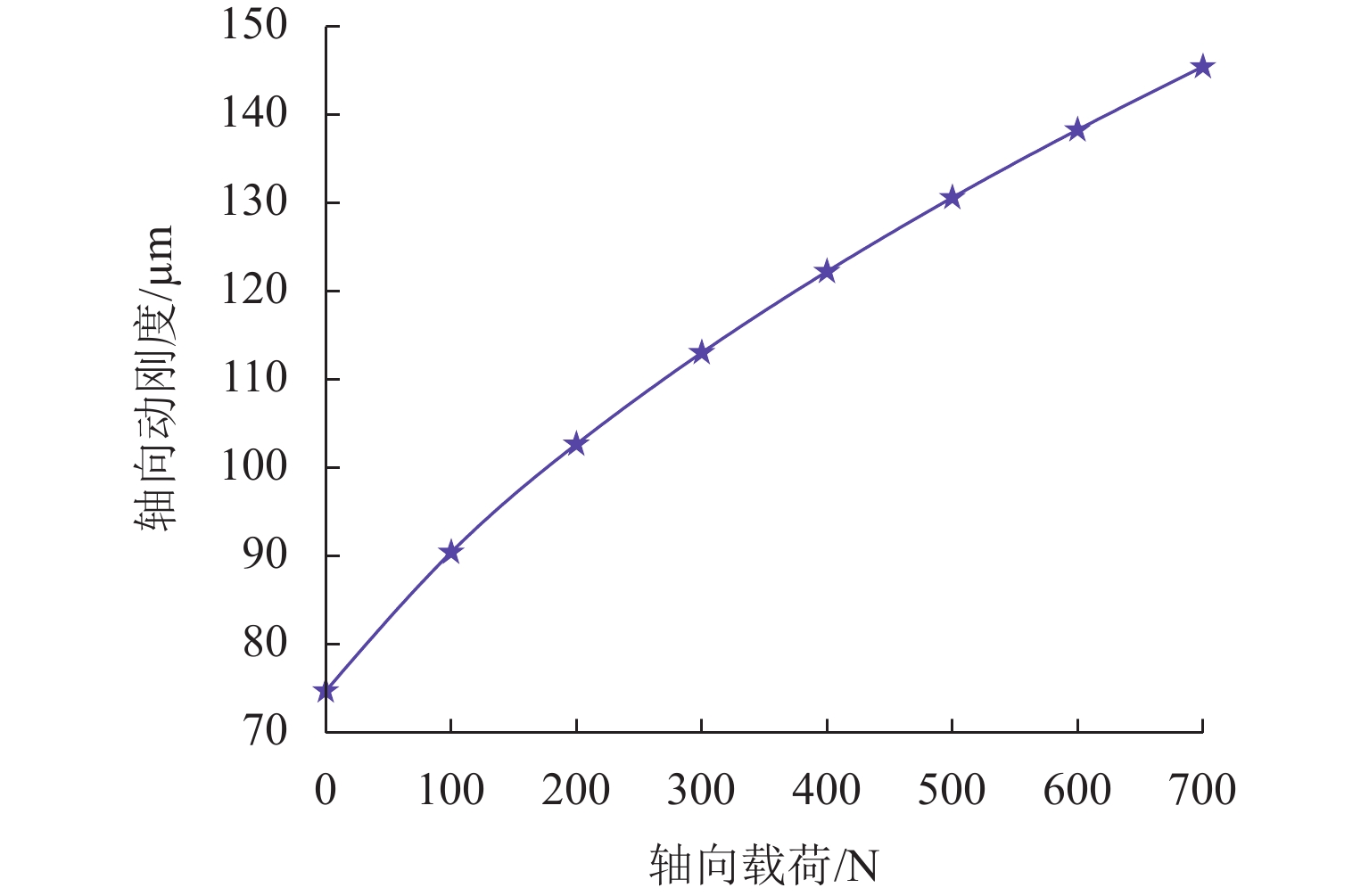
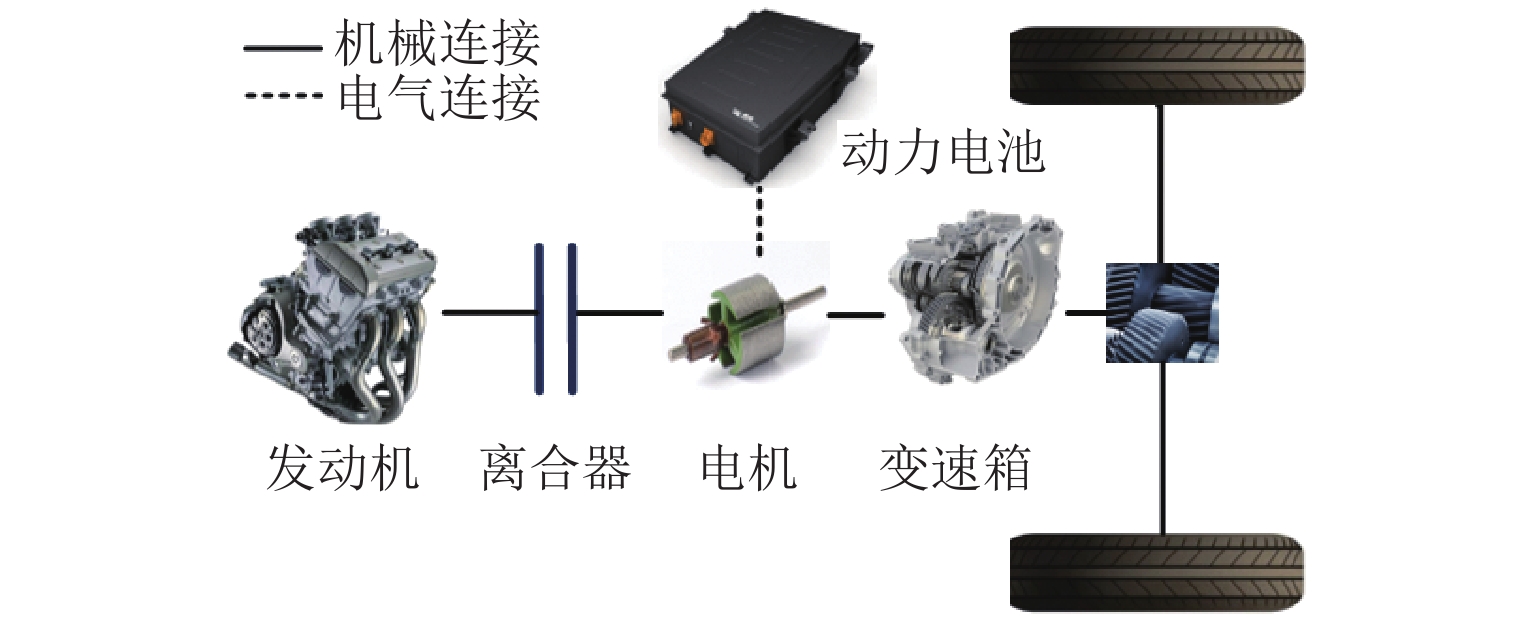
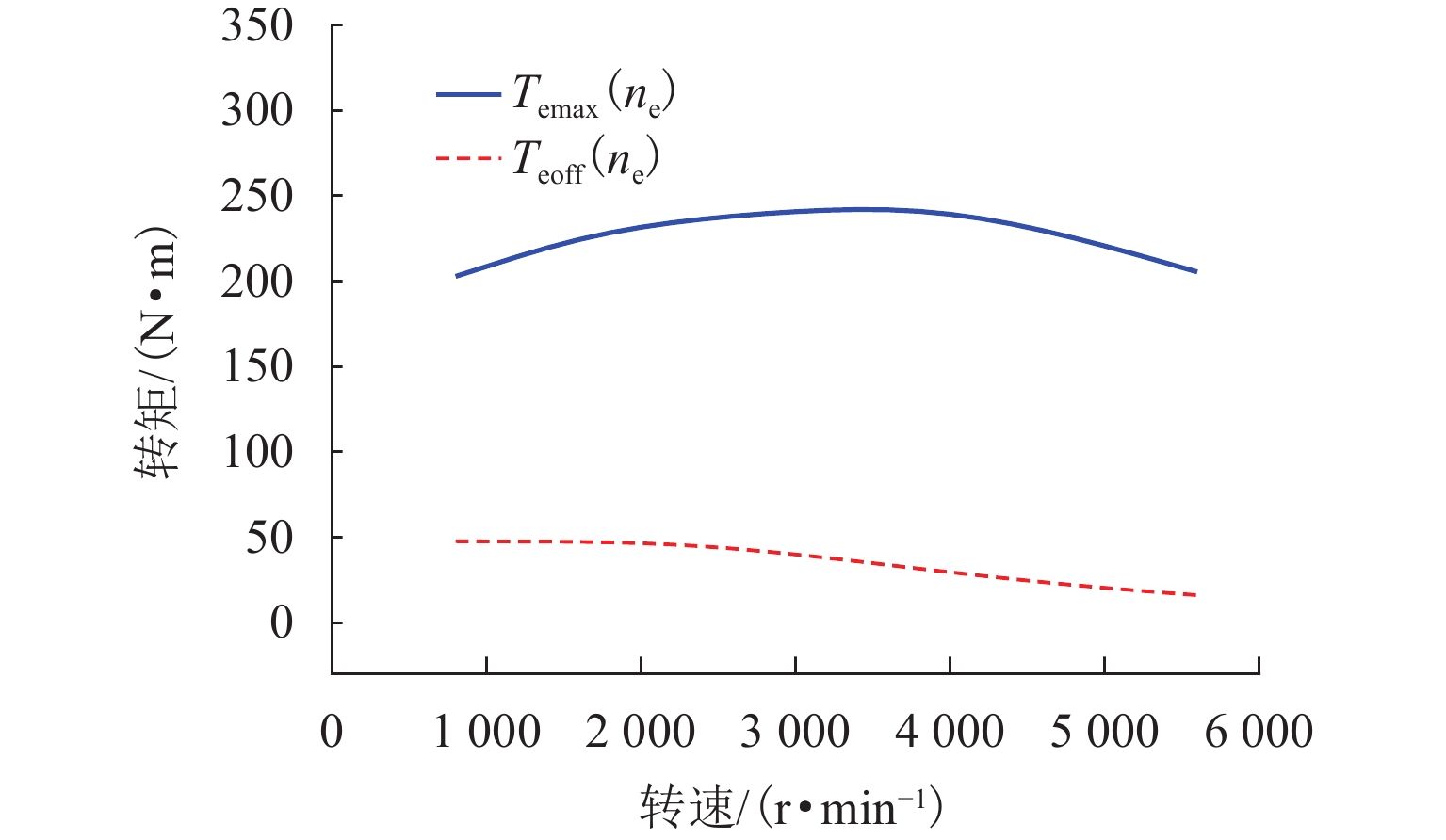
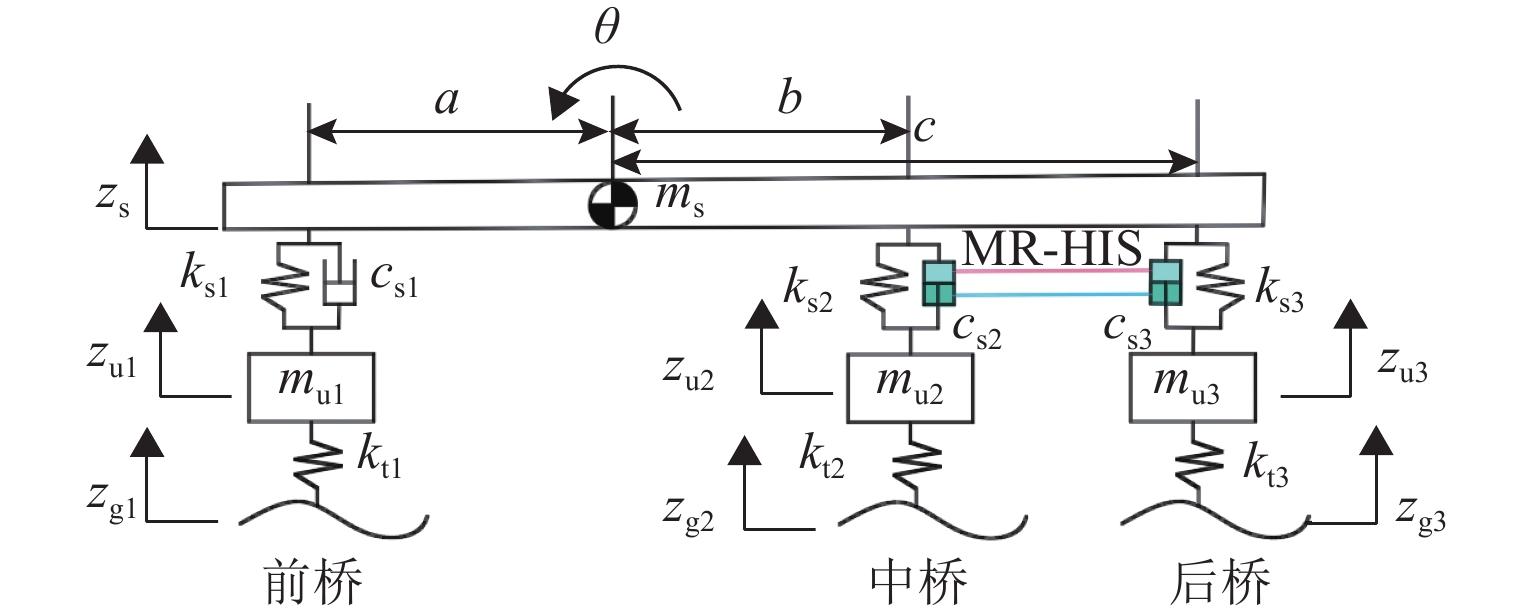
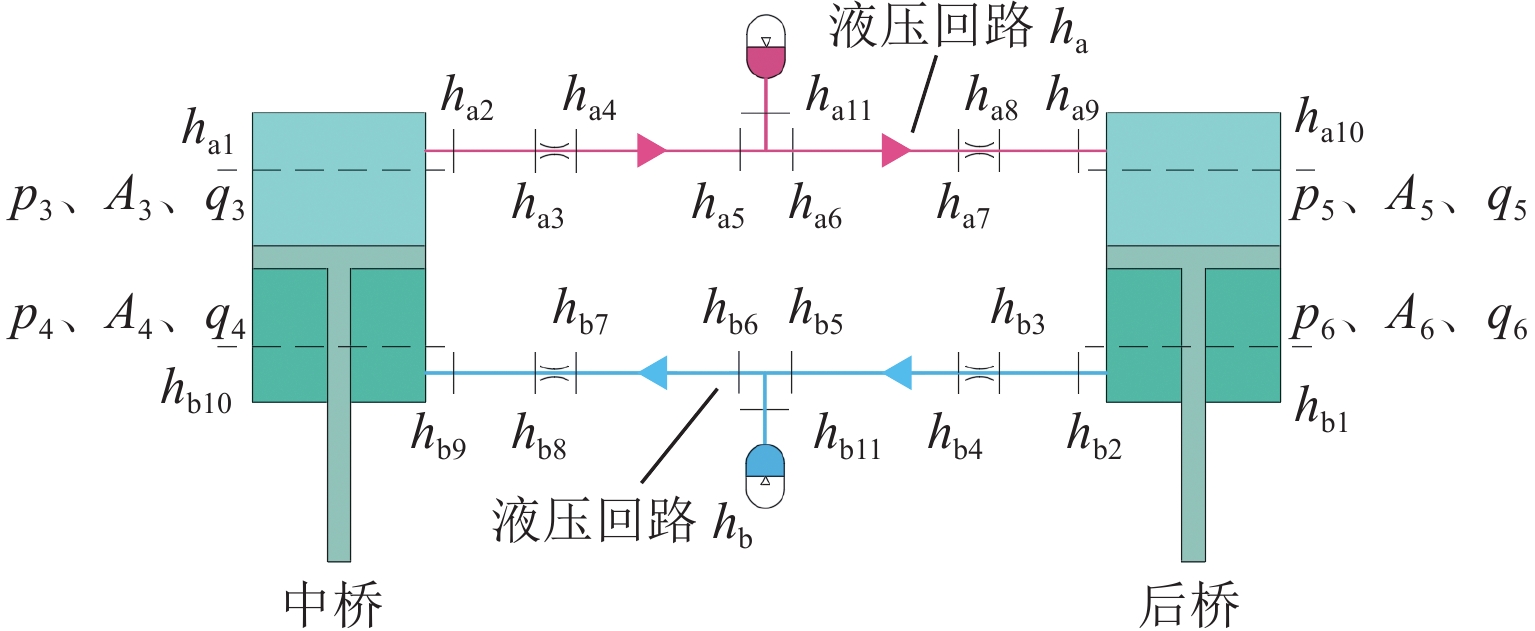
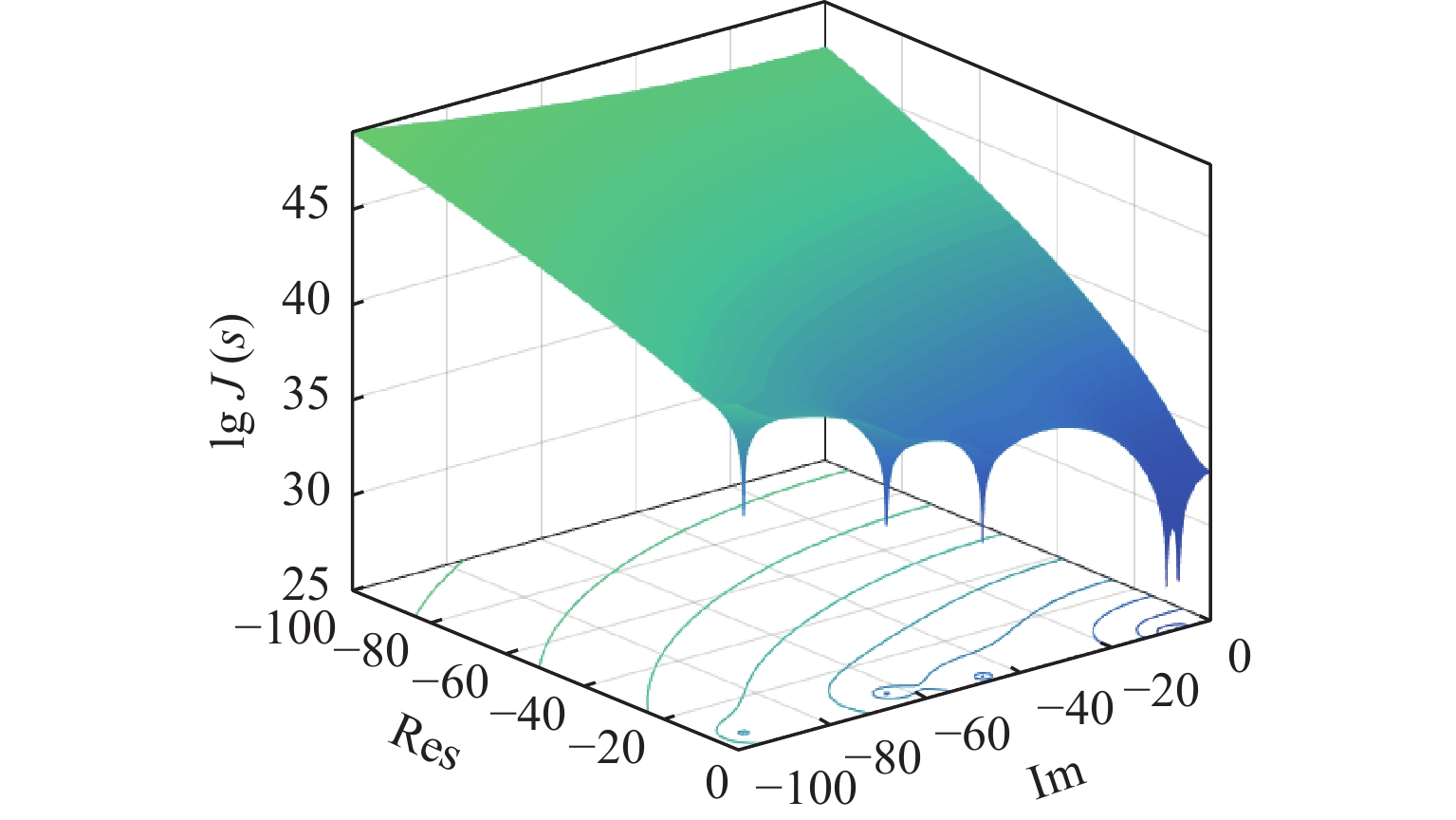
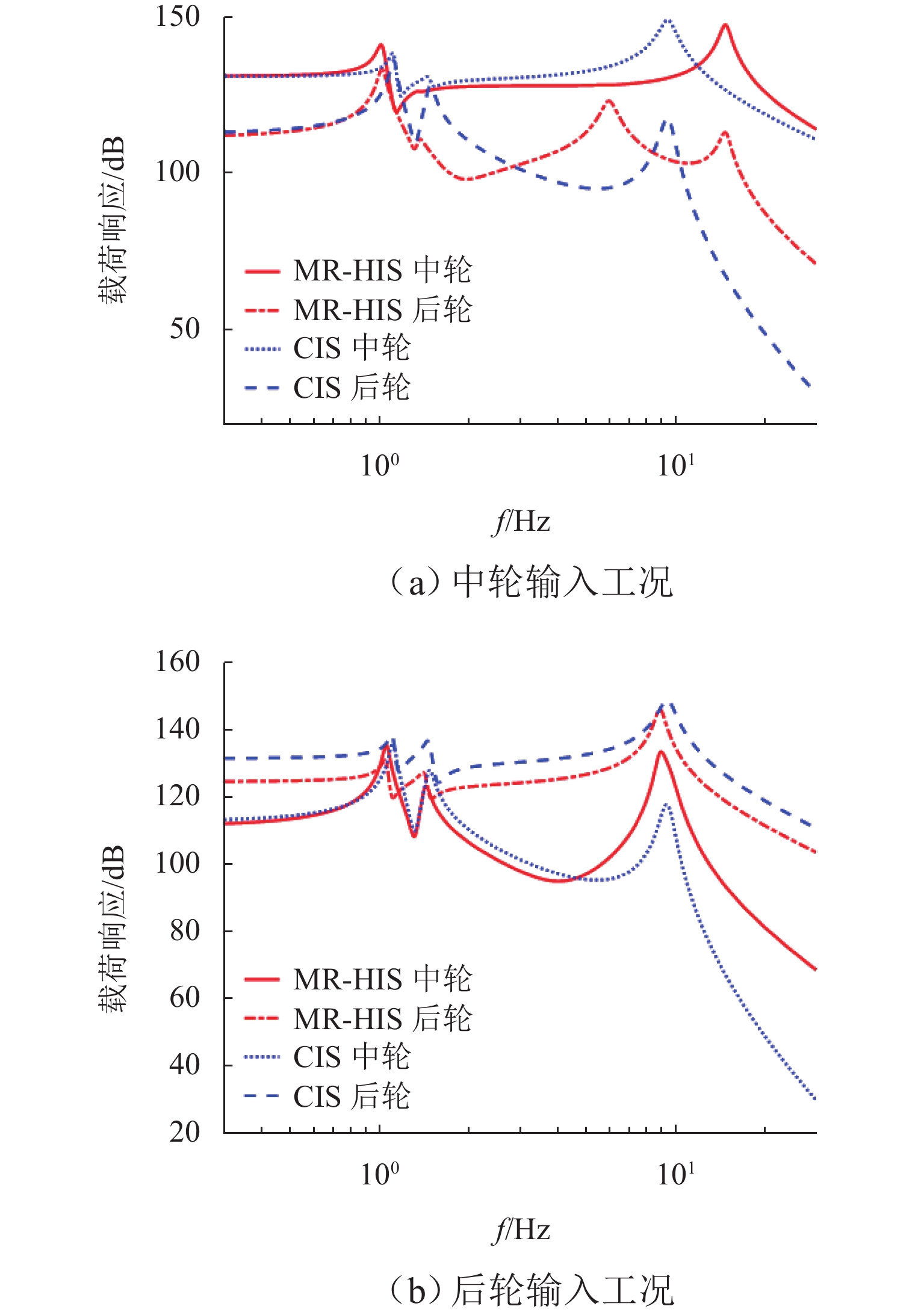
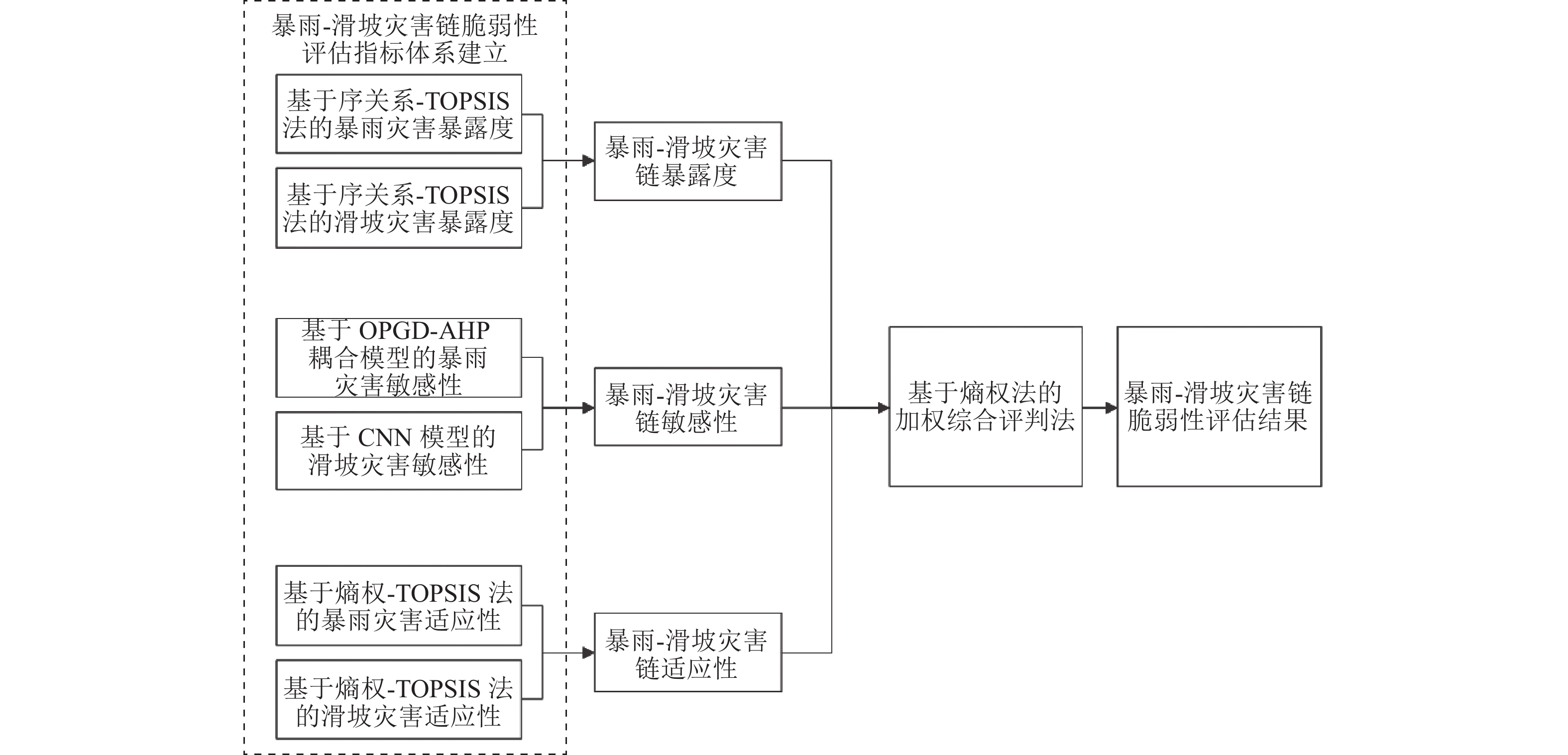
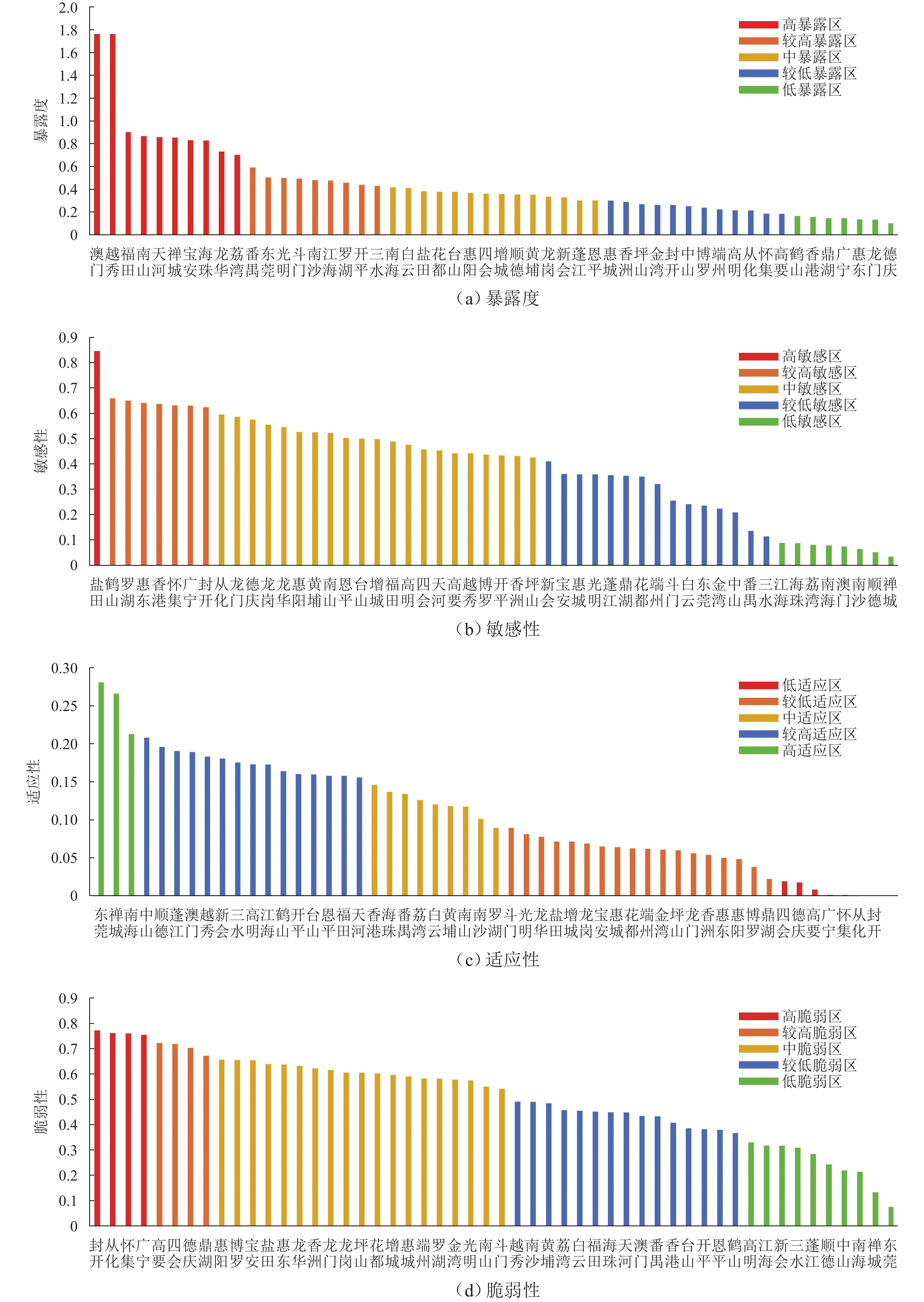
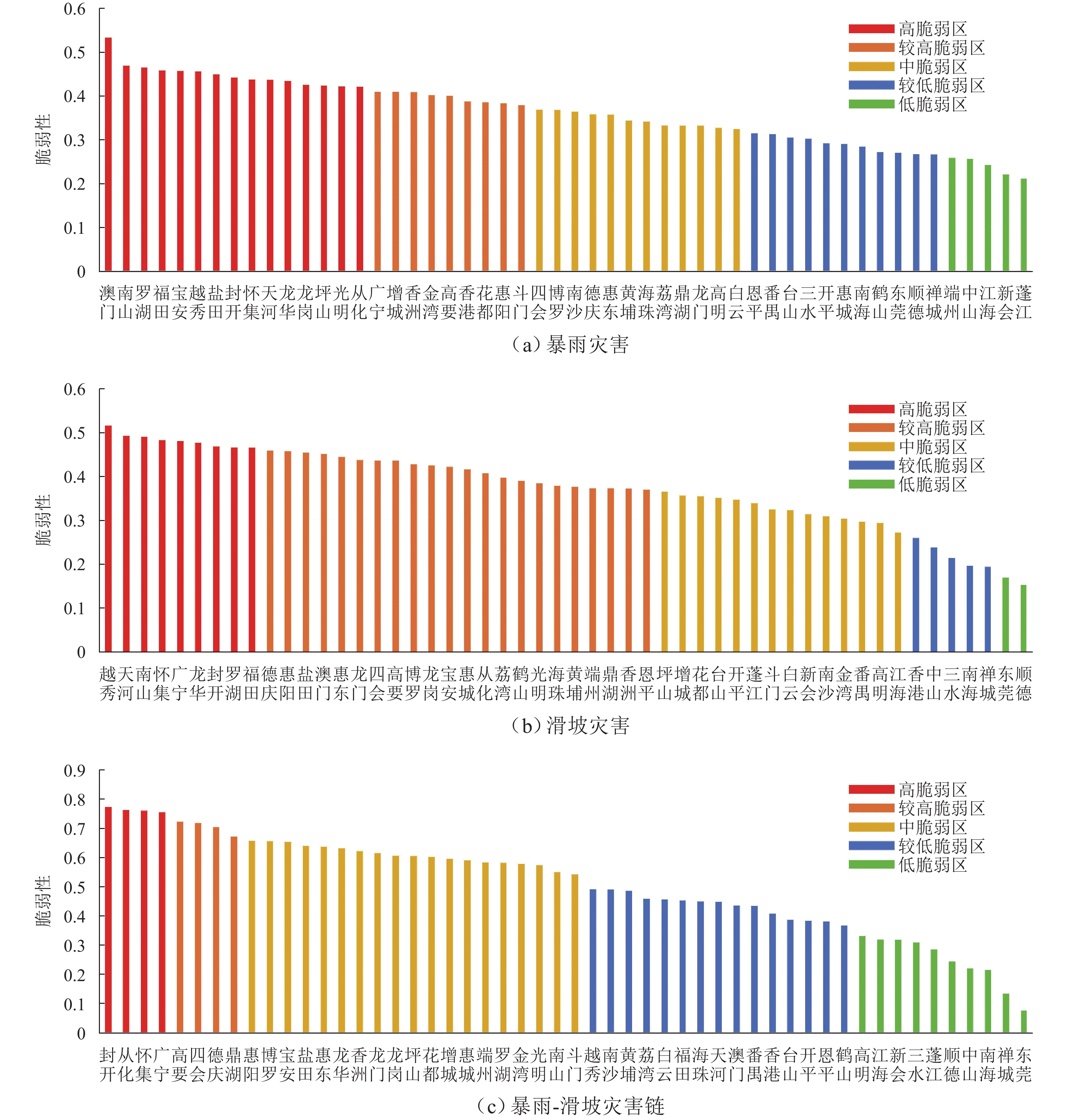
摘要:
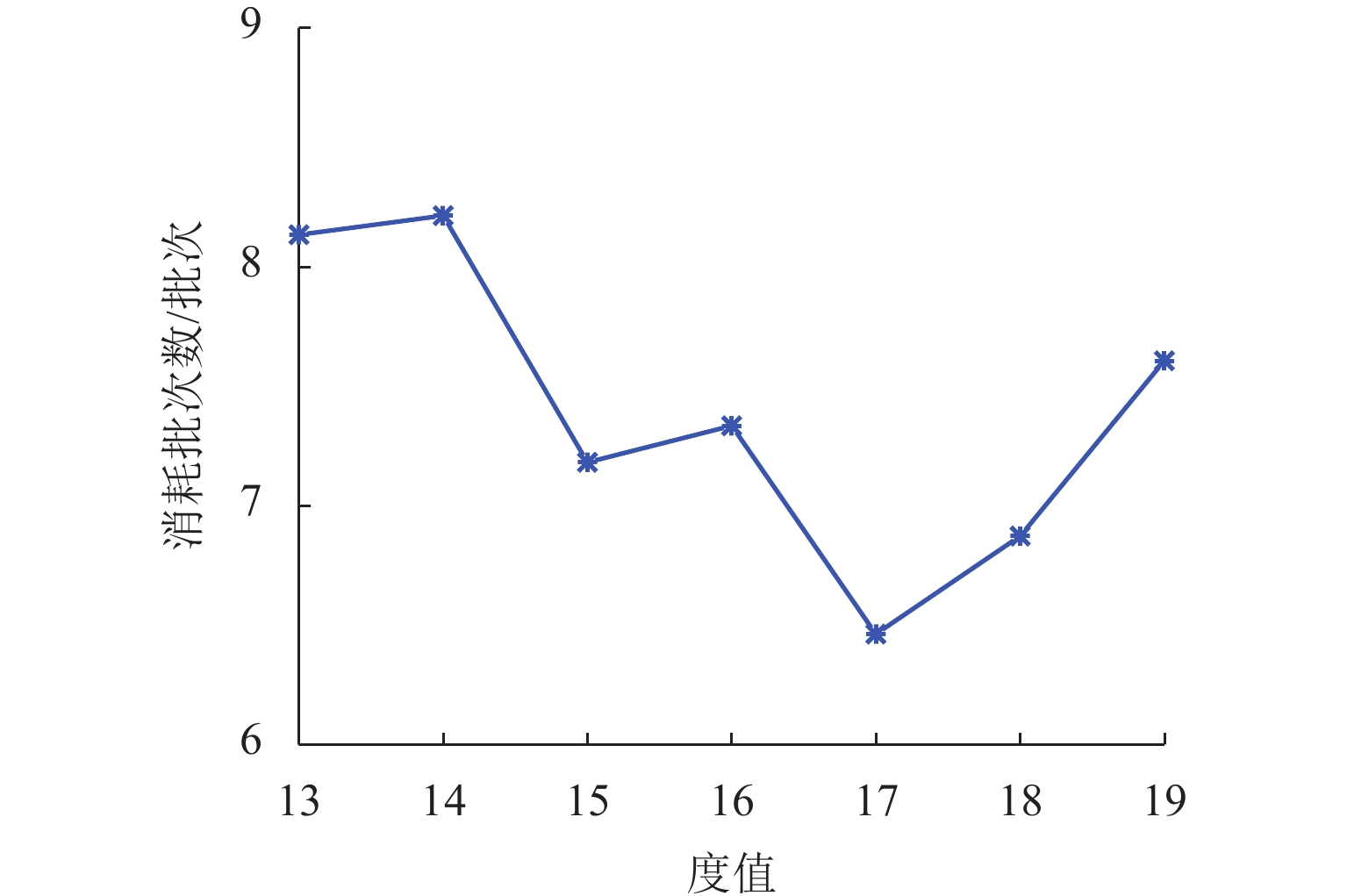
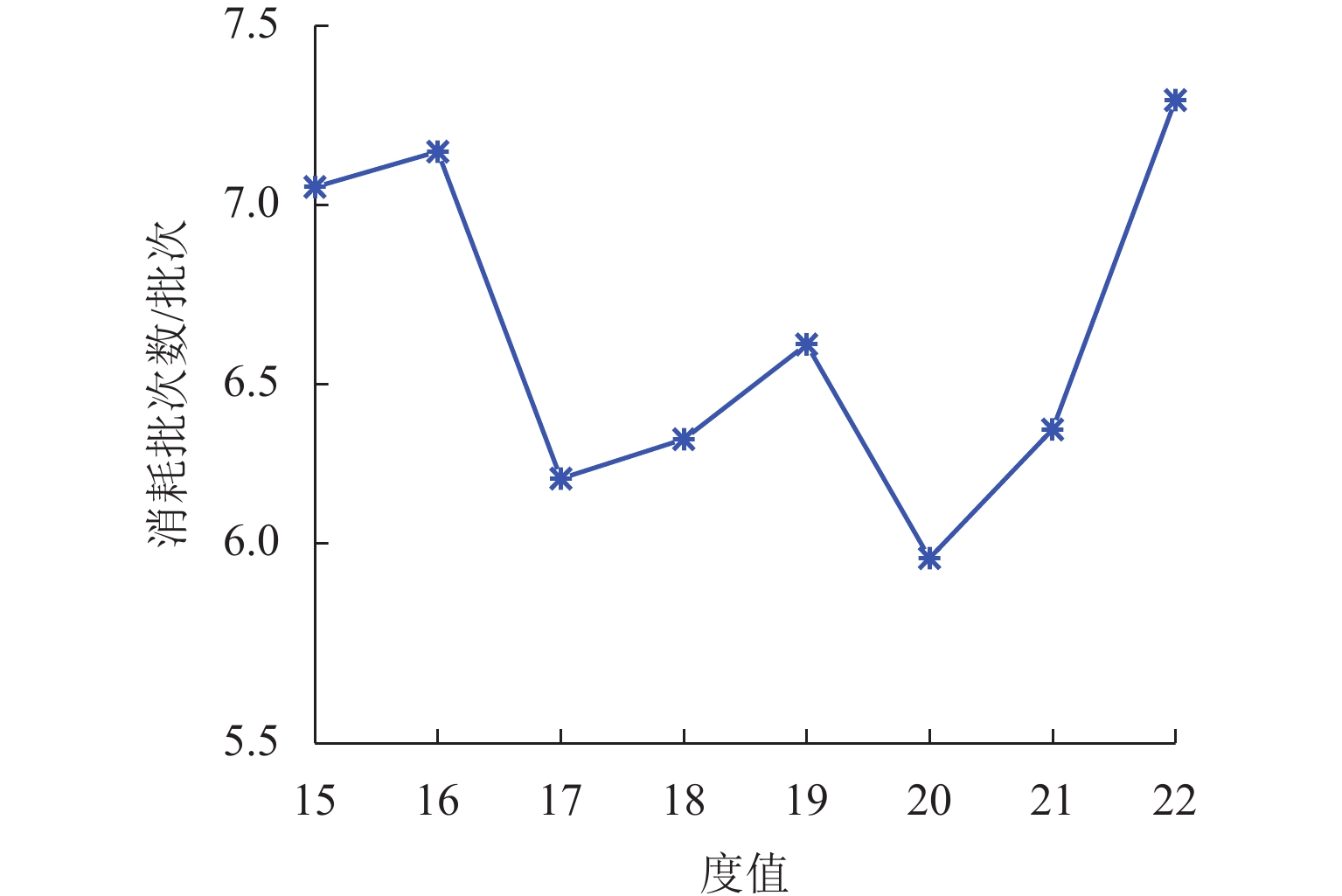
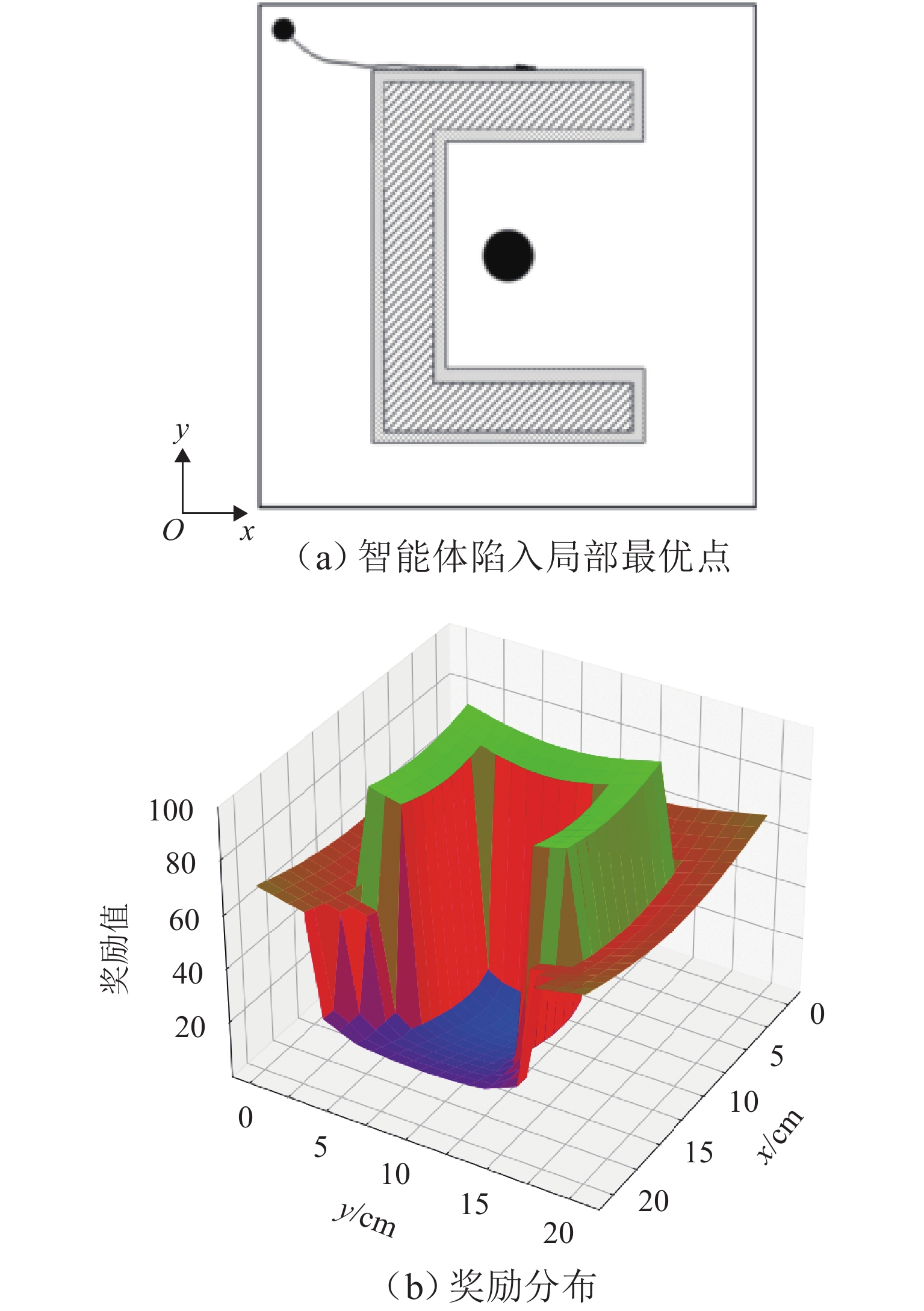
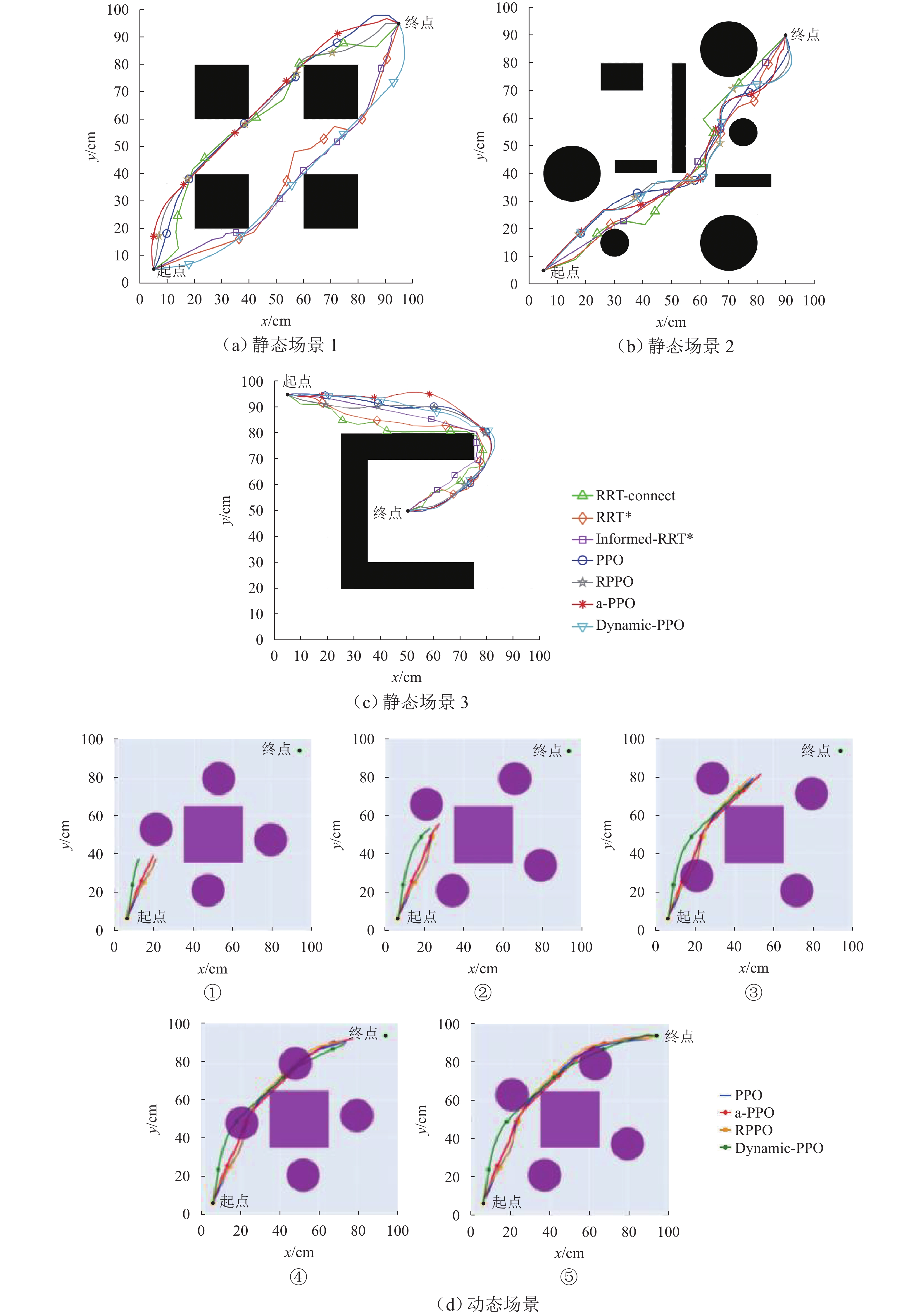
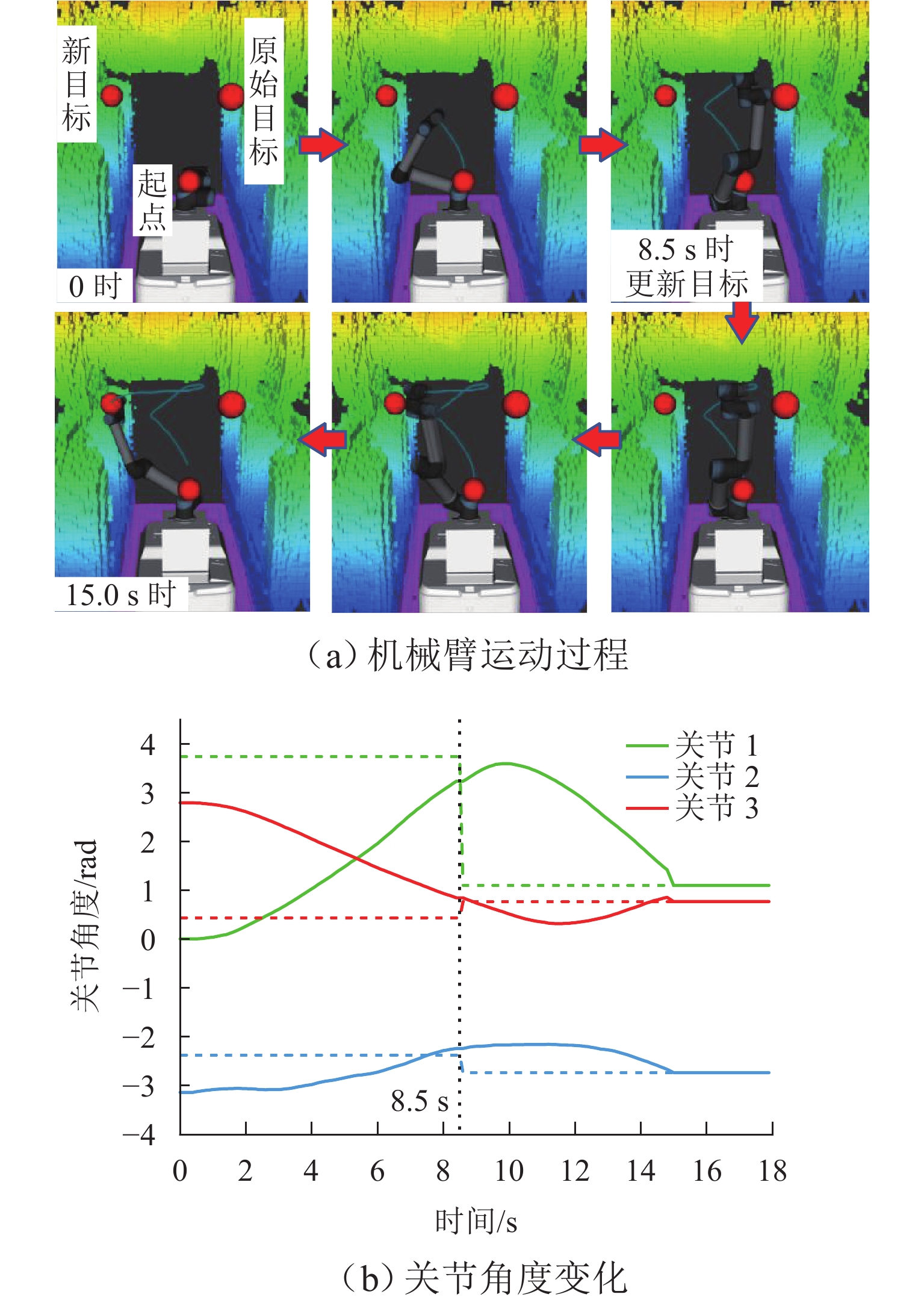
为满足列车底部场景中巡检机械臂主动配合工作人员的人机协作需求,并提高PPO (proximal policy optimization)算法的收敛速度,提出一种自适应PPO (adaptive-PPO, a-PPO)算法,并将其应用于列检机械臂的在线运动规划. 首先,设计系统模型,根据当前环境状态即刻输出策略动作;然后,引入几何强化学习构建奖励函数,通过智能体的探索不断优化奖励值分布;接着,基于策略更新前后的相似度自适应地确定裁剪值,形成a-PPO算法;最后,通过在二维地图上对比分析a-PPO算法的改进效果,并验证其在仿真和真实列车场景中的可行性和有效性. 结果表明:在二维平面仿真中,a-PPO算法在收敛速度上优于其他PPO算法,且路径稳定性显著提高,路径长度标准差平均比PPO算法低16.786%,比Informed-RRT* 算法低66.179%;仿真与真实列车场景的应用实验中,机械臂可实现运动过程中动态更改目标点和主动规避动态障碍物,展现出对动态环境的适应能力.


 高级检索
高级检索
 Email alert
Email alert RSS
RSS 摘要
摘要 HTML全文
HTML全文 PDF 2382KB
PDF 2382KB 附件
附件 施引文献
施引文献