

Evaluation Method for Time-Slot Availability of Crossing Air Route
-
摘要: 为了增加空域使用效率,建立了交叉航路入口放行策略模型.对多种交叉航路及放行策略组合,提出了 新的空域时隙资源可用性评估方法,研究了新策略下航路长度、航路交叉角和放行偏离角对交叉航路时隙可用 性的影响.仿真结果表明:当放行偏离角一定时,增加航路长度可有效提升时隙资源可用率,偏离角为10曘、20曘和 30曘时的最大时隙可用率分别为82%、90%和97%;航路长度具有边际效应,当航路长度超过阈值时,再增加航路 长度不会提高时隙资源可用率;在航路长度、放行偏离角相同的条件下,增加航路交叉角可增加时隙资源可用率.
-
关键词:
- 空中交通管制|空中交通管理|空域资源 /
- 时隙可用性|空域建模
Abstract: To increase the efficiency of airspace use, an entry clearance strategy of the crossing air route was proposed and a mathematical model was established. Then, a new method for evaluating the airspace time-slot availability, with different combinations of various crossing route structure patterns and entry clearance strategies, was provided. The influence on the time-slot availability of the crossing air route imposed by the structural constraints, such as route length and crossing angle, and the deviation angle were analyzed by simulation. The results show that extending the route length under the fixed deviation angles could enhance the airspace time-slot available rate to a maximum level as high as 82%, 90%, and 97% when the deviation angle is 10°, 20°, and 30°, respectively. However, the approach of extending route length has a marginal effect; that is, there is no more promotion effect in the time-slot availability when the route length exceeds a threshold. Under the same route length and deviation angle, increasing the crossing angle would also enhance the airspace time-slot availability.-
Key words:
- air traffic control /
- air traffic management
-
中低速磁浮作为现有城市轨道交通的有益补充,具有安全低碳、静音舒适等优点,在我国具有广阔的应用前景[1]. 制动控制系统是磁浮列车自动驾驶系统(ATO)的重要子系统,在保障列车运行安全、停车精度和舒适性方面起到关键作用[2]. 为有效调节列车速度,中低速磁浮列车主要采用电-液混合制动实现正常到站停车. 由于电制动与液压制动转换过程状态强耦合、液压制动力强非线性等特点,传统的列车制动控制方法难以保障中低速磁浮列车的停车精度和舒适性. 因此,研究中低速磁浮列车电-液混合制动动态特性、混合制动优化控制方法,对提升磁浮列车停站精度和舒适性具有重要意义.
目前,针对传统列车制动过程的研究主要关注制动特性建模和控制算法方面. 精确的制动模型和良好的控制算法是列车平稳、精准停车的重要保障. 李中奇等[3]针对高速动车组动力分散特点建立多质点制动模型,基于径向基神经网络的比例-积分-微分(PID)控制策略与Smith预估器结合对给定速度跟踪控制,满足高速动车组制动过程精准停车要求. 周嘉俊等[4]分析列车实际减速度的影响因素,提出改进史密斯预估器对减速度进行预估控制,提高列车减速度的跟踪精度. 但该方法未识别造成列车减速度偏差原因,只针对跟踪误差对制动力进行调节的方式容易造成实际减速度的震荡,列车平稳性有待提升. 马天和等[5]采用参数估计算法对城轨列车制动过程受到的扰动进行估计补偿,通过在线修正目标制动力实现列车制动力闭环控制. 崔俊锋等[6]针对中低速磁浮列车制动力时滞问题,提出一种时滞补偿的广义预测控制器,有效降低列车制动过程时滞特性影响,提高控制精度. 传统基于物理参数建模方法难以准确表征磁浮列车动态特性,模型误差较大导致列车制动效果不佳. 为准确描述列车制动特性,机器学习算法被广泛用于列车数据驱动建模方面研究[7-8]. Yin等[9]针对高速列车制动系统延时问题,构建了一种滞后信息的长短期记忆网络(LSTM)模型,预测精度有很大提升. Liu等[10-11]结合回声状态神经网络建立高速列车状态预测模型,满足高速列车运行中安全、节能、舒适等多目标优化控制.
近年来,强化学习算法凭借其强大行动决策能力和解决不确定环境下控制问题的优势,在电力系统[12]、能源管理[13]、机器人[14]等领域取得了大量应用研究成果. 已有不少学者尝试将强化学习方法用于列车运行优化控制:张淼等[15]凭借优秀司机驾驶经验,设计一种基于策略梯度的强化学习算法,满足地铁变化场景下的能耗和舒适度等多目标需求; 高豪等[16]利用强化学习方法中的动态规划法优化地铁列车站间运行时间分配问题,有效降低列车牵引能耗;蒋灵明等[17]利用多智能体强化学习对大规模货运列车运行计划进行动态调整,有效降低货运列车延误影响; Shang等[18]提出一种带有参考系统的深度强化学习方法,有效提高智能体的学习效率; Liu等[19]提出一种基于深度Q网络(DQN)的重载列车智能控制方法,解决了列车在长陡坡情况下的循环空气制动控制问题.
本文针对中低速磁浮列车自动驾驶混合制动问题,提出一种混合制动特征自学习的深度强化学习(BFS-DQN)磁浮列车制动优化控制方法. 采用LSTM学习混合制动系统的动态特征,结合强化学习方法进行磁浮列车停站制动控制策略优化,并通过仿真实验验证其在中低速磁浮列车制动优化控制中的有效性.
1. 混合制动特征自学习方法
中低速磁浮列车混合制动特征因电液混合制动状态耦合、液压制动非线性而动态变化,目前广泛采用理论、静态制动特征模型,难以在仿真实验中准确反映强化学习的环境对agent (制动控制器)的奖励情况. 在此,采用LSTM学习混合制动的动态特征,以准确描述强化学习的奖励函数关系.
1.1 中低速磁浮列车混合制动原理
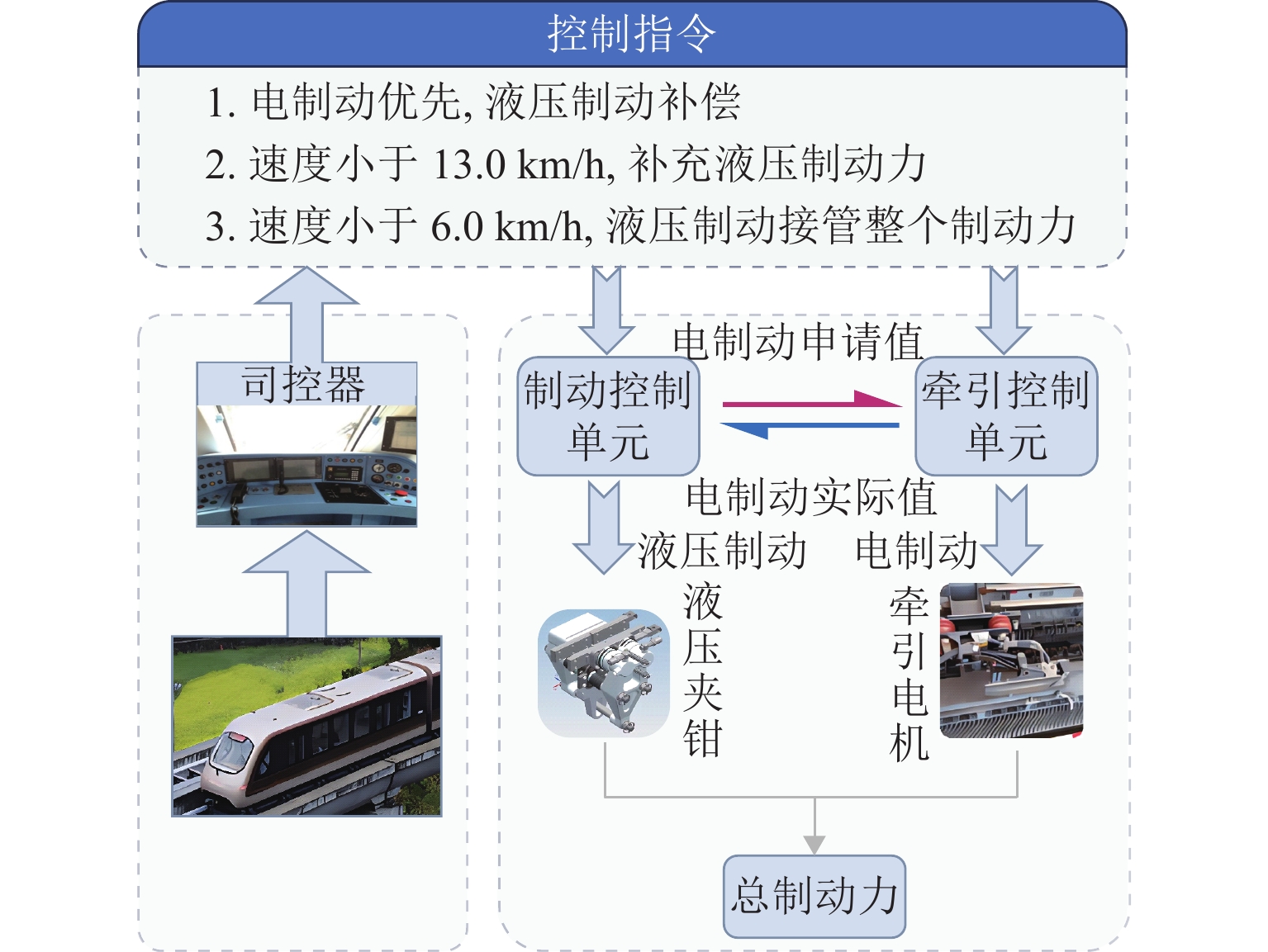
磁浮列车电-液混合制动原理如图1所示.
 图 1 中低速磁浮列车电-液混合制动控制原理Figure 1. Principle of electro-hydraulic hybrid braking control of medium and low-speed maglev trains
图 1 中低速磁浮列车电-液混合制动控制原理Figure 1. Principle of electro-hydraulic hybrid braking control of medium and low-speed maglev trainsATO发出一系列制动指令来操控磁浮列车减速停车. 磁浮列车制动过程遵循电制动优先、液压制动补偿的原则. 列车制动控制单元通过接收制动指令计算全列车所需制动力,按照电制动优先原则,向牵引控制单元发送电制动申请值,并根据反馈的电制动实际值计算所需补充的液压制动力. 然后,制动控制单元通过控制液压夹钳施加液压制动力,实现磁浮列车减速与停车控制.
1.2 混合制动力特征
中低速磁浮列车制动过程除了受到制动力控制外,还受到运行阻力的影响. 中低速磁悬浮列车的运行阻力比轮轨列车更为复杂,运行阻力包括空气阻力、涡流阻力以及附加阻力等.
空气阻力与列车运行速度及车辆编组相关,中低速磁浮列车空气阻力可表示为
Fa=(1.652+0.572N)v2, (1) 式中:$ N $为列车编组数,$ v $为列车速度.
集电器阻力Fc和电磁涡流阻力Fm为
{Fc=96N,Fm={3.354Mv,0<v⩽5.6m/s,(18.220+0.074v)M,v>5.6m/s, (2) 式中:$M$为列车质量.
附加阻力主要包括坡道阻力Fi和曲线阻力Fr,如式(3).
{Fi=Mgsin(arctanβ),Fr=600RMg, (3) 式中:$\;\beta $为坡度值,$R$为曲线半径.
由于中低速磁浮列车电-液混合制动力实际值未知,本文将列车制动力特性用函数$ g(x) $表示. 根据中低速磁浮列车制动特性和运行阻力,建立基于牛顿方程的单质点列车制动模型,如式(4).
{v=dsdt,a=dvdt,Ma=g(Fb,Fw)+ξ(t),Fw=Fa+Fc+Fm+Fr+Fi, (4) 式中:$s$和$a$为列车位置和加速度,${F_{\rm{b}}}$为列车制动力,${F_{\rm{w}}}$为列车运行阻力,$ \xi(t) $ 为未建模动态,t为时间.
1.3 混合制动动态特征自学习方法
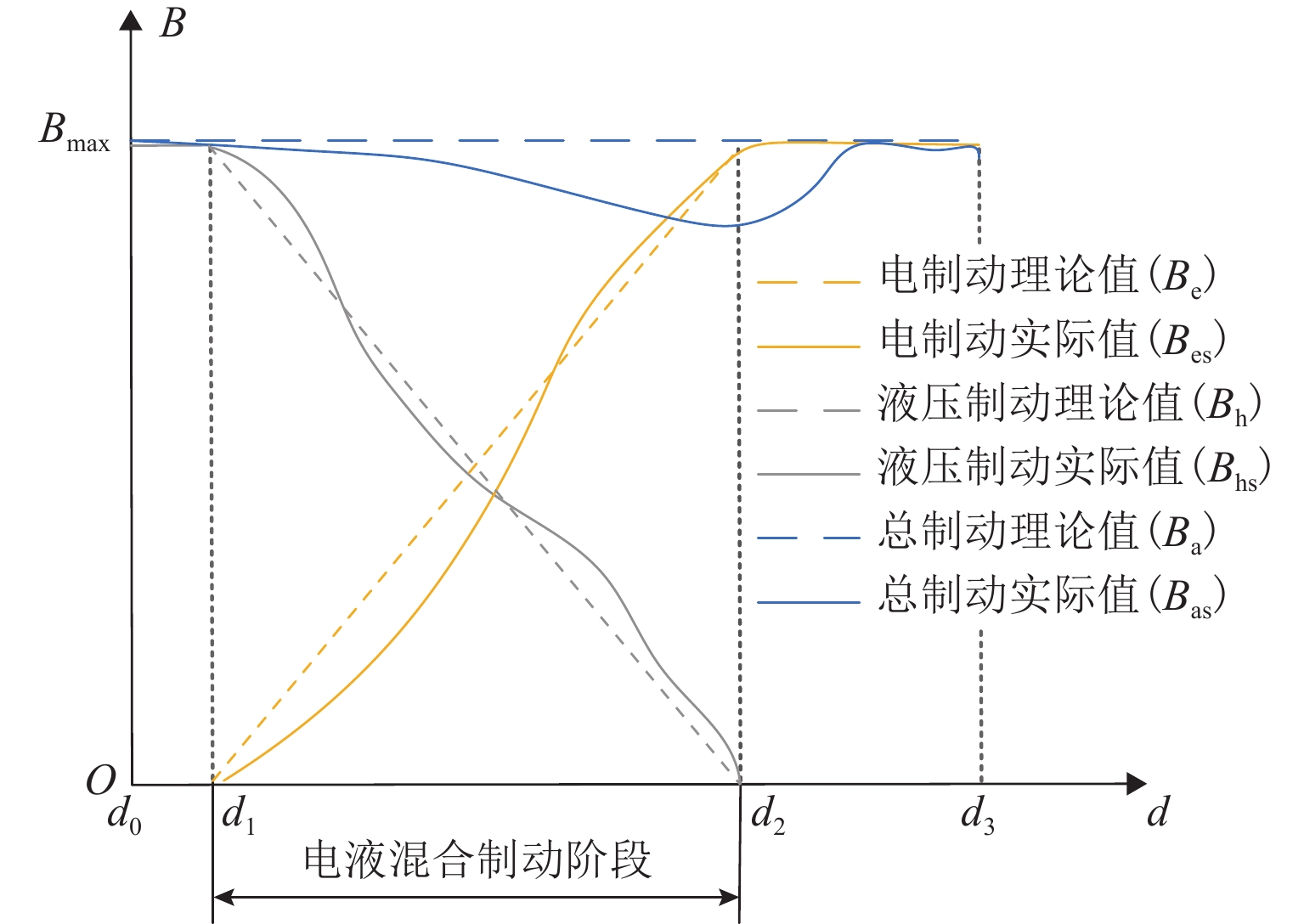
中低速磁浮列车制动过程电制动、液压制动及总制动力变化特性如图2所示,图中:Bmax为最大理论制动力,d为制动距离,B为制动力. 设列车制动系统控制单元发出制动指令时列车制动距离为${d_0}$,由于电制动力响应存在短暂延时$\tau $,列车空走一段时间后距离为${d_1}$. 此时,电制动力开始减小,液压制动开始补充;制动距离为${d_2}$,电制动撤离,液压制动接管整车制动;当制动距离为${d_3}$时,液压制动力达到最大值,列车准备停车.
磁浮列车制动特性受到电制动响应延迟、液压制动离散及运行阻力变化等因素影响,列车实际制动力$B_{{\rm{s}}}$与理论制动力$ B_{\mathrm{n}} $存在较大差距,影响列车到站的停车精度. 同时,电制动和液压制动两者强非线性耦合特点导致磁浮列车电-液混合制动过渡不平稳,容易产生较大纵向冲击,对乘坐舒适性造成影响.
传统的机理模型难以准确描述中低速磁浮列车运行动态,无法保障列车制动效果. LSTM在处理各种非线性时序问题具有良好的效果,本文采用LSTM网络建立磁浮列车数据驱动的制动模型,利用列车历史制动数据进行制动特征自学习,以更准确地描述列车动态特性和预测列车运行状态. 基于LSTM的磁浮列车动态模型为
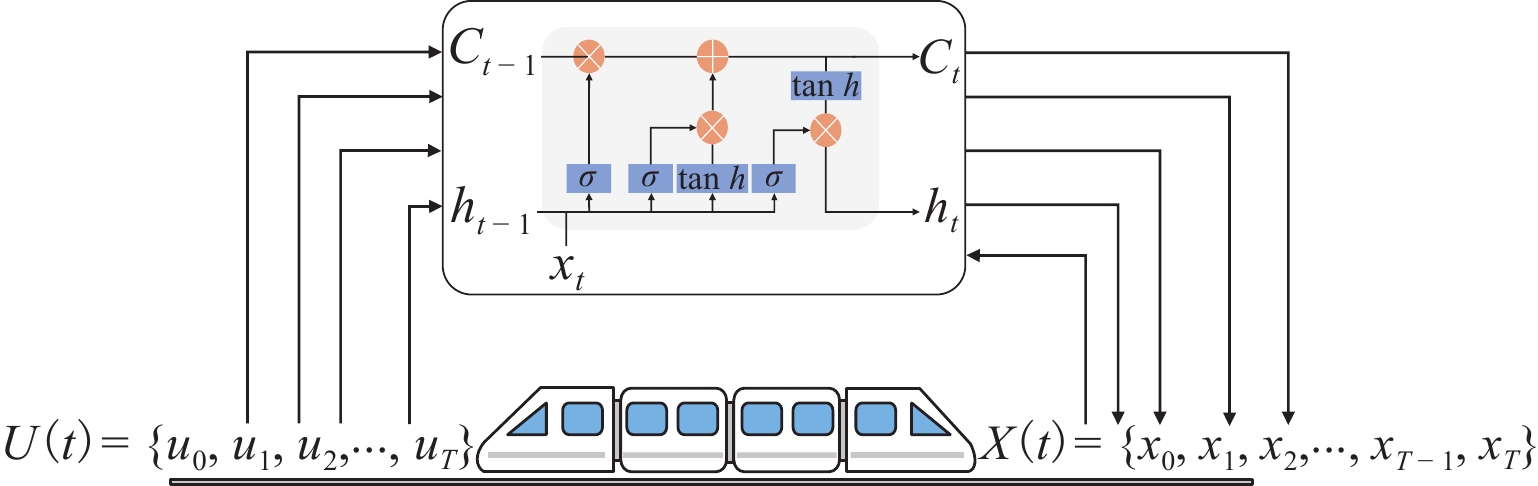
{xt+1=gLSTM(X(t),U(t),w)+ξ(t),X(t)={x1,x2,⋅⋅⋅,xT},U(t)={u0,u1,⋅⋅⋅,uT}, (5) 式中:${g_{{\rm{LSTM}}}}$(·)为基于磁浮列车动态模型网络;${x_{t + 1}} = \{ {d_{t + 1}},{v_{t + 1}}\} $,为列车下一时刻预测状态,即列车位置和速度;$U(t) $为列车前$T$时刻一系列的制动指令;$X(t) $为列车前$T$时刻的运行状态;$w = \{ {w_1},{w_2}, \cdot \cdot \cdot ,{w_n}\} $,为网络训练参数.
为了减小预测输出值与实际值之间的差距,采用均方根误差(RMSE)方法建立损失函数$l(\theta )$且使其最小化,如式(6).
minθl(θ)=(1NT∑t=1(xt−ˆxt)2)12, (6) 式中:${x_t}$和${\hat x_t}$分别为列车时刻$t$的实际状态值和预测值.
本文建立基于LSTM网络的磁浮列车动态模型的目的是准确预测列车未来状态,如图3所示. 图中:Ct为时刻t时LSTM单元状态,ht为时刻t时LSTM的输出值. 制动指令${u_0}$和列车初始状态$\{ {d_0},{v_0}\} $作为已知输入,选取磁浮列车历史制动数据中一系列制动指令$\left\{ {{u_0},{u_1}, \cdot \cdot \cdot ,{u_T}} \right\}$对模型进行训练,模型可以输出一系列观测到的状态$\{ {d_1},{v_1}, \cdot \cdot \cdot ,{d_T},{v_T}\} $,最后将预测状态与磁浮列车现场采集的制动数据比较,验证模型准确性.
2. 磁浮列车BFS-DQN制动控制方法
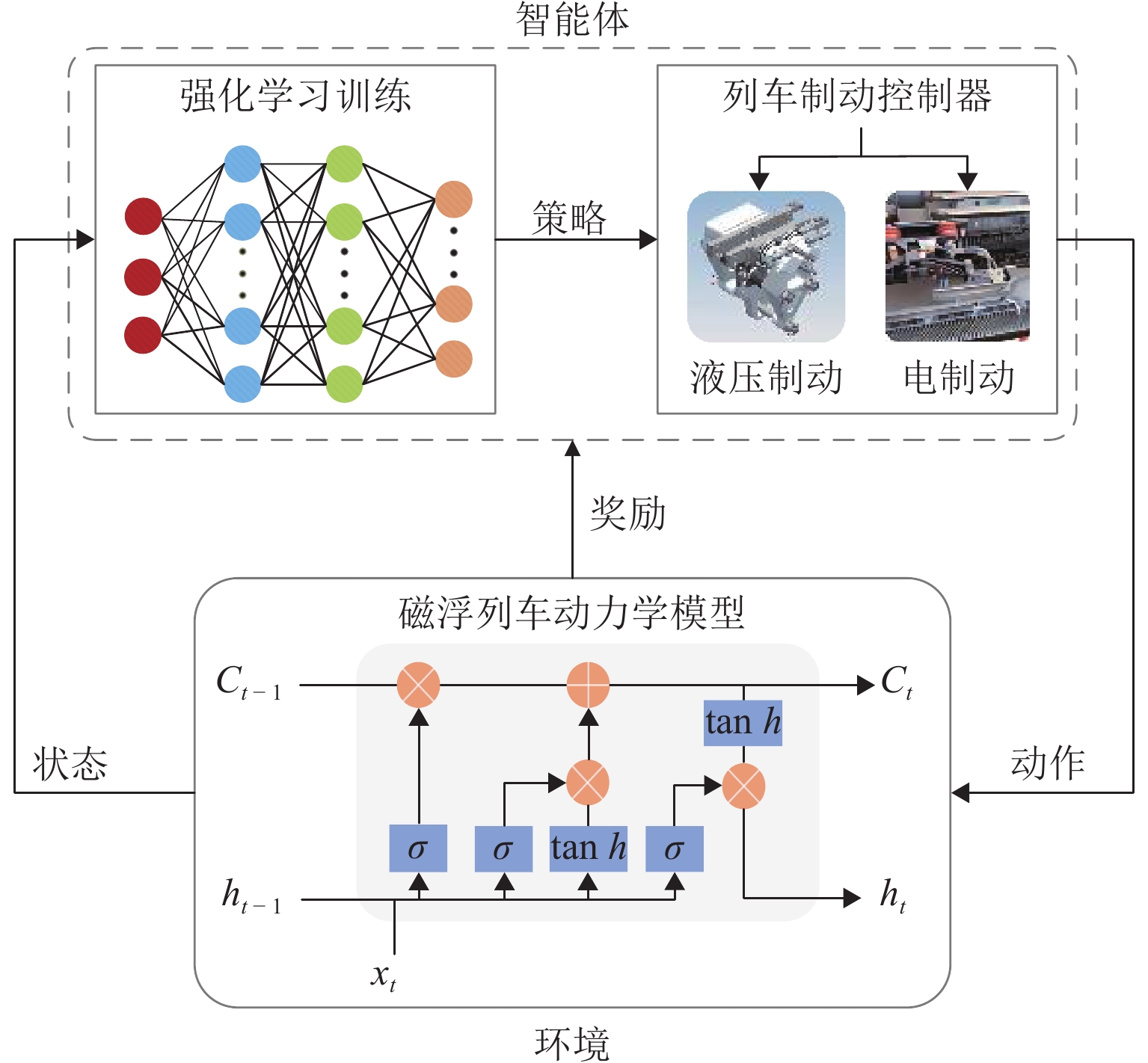
深度强化学习算法融合了深度学习和强化学习各自优势,具有优秀的状态感知能力和强化的决策能力[20]. 本文主要关注提出一种BFS-DQN磁浮列车制动控制方法,通过学习磁浮列车制动特性以便准确获取运行状态和计算优化目标,提高端到端的强化学习控制效果.
本文提出的BFS-DQN控制方法如图4所示. 首先,通过列车历史运行数据训练LSTM网络,学习列车制动特性与动态环境的关系; 然后,将观测到的列车运行状态作为强化学习算法的输入,列车制动等级作为智能体的动作输出,同时设计舒适性和精准停车奖励函数,通过与环境交互的方式训练列车控制器学习最优控制策略;最后,输出合理的制动力以实现磁浮列车制动优化控制.
2.1 状态空间
根据式(4)、(5),将预测到的列车运行状态,即列车位置$d$、速度$v$和加速度$a$组成的三维状态空间作为强化学习智能体的观测状态,该状态空间S定义为
S={s=[dva]T,d∈[0,ds],v∈[0,V0],a∈[−Amax,0]}, (7) 式中:${d_{\mathrm{s}}}$为列车目标停车位置,${V_0}$为列车电-液制动转换起始速度,${A_{\max }}$为列车最大减速度.
2.2 动作空间
磁浮列车制动过程中,ATO或司机根据运行状况操纵制动等级来调节列车制动力的大小,同样,本文选择列车制动等级作为智能体的动作,动作空间A定义为
A=[ui],ui∈[0,100%], (8) 式中:${u_i}$为磁浮列车电-液混合制动等级,0%表示惰行,100%表示施加最大制动力.
2.3 奖励机制
BFS-DQN中,智能体通过每个时间步采取最佳行动来获得更多的奖励回报,可靠的奖励机制对于引导智能体学习最佳行动策略具有重要作用. 因此,本文根据磁浮列车制动优化控制目标,设计关于舒适性和精准停车的奖励函数,最后通过加权求和的方式得到总奖励,该奖励函数定义为
{rtotal=λ1rcomfort+λ2rstop+rfail,rcomfort=1−a2error,aerror⩽1.0m/s3,rstop=1−d2error,derror⩽0.3m,rfail,aerror>1.0m/s3orderror>0.3m, (9) 式中:${r_{{\rm{total}}}}$为列车前后状态转移产生的即时总奖励;${\lambda _1}$,${\lambda _2}$为奖励权重;${r_{{\rm{confort}}}}$为乘客舒适性奖励函数;${a_{{\rm{error}}}}$为单位时间内减速度的变化激烈程度,用于描述乘客乘车体验[21];${r_{{\rm{stop}}}}$为列车精准停车的奖励函数;${d_{{\rm{error}}}}$为列车实际制动距离与目标制动距离的差值,用于描述停车精准性;为节省时间成本,设置了惩罚函数${r_{{\rm{fail}}}}$对停车失败和减速度剧烈变化的情况给予训练失败惩罚.
2.4 学习策略
本文定义列车控制器作为BFS-DQN中的智能体,采用价值迭代方式学习最优的制动策略. 首先,定义一个价值函数${Q_\pi }(s,u)$用于描述智能体从开始到结束时的预期未来总奖励,列车制动控制器采用随机策略$\pi $进行动作学习时,从当前时间$t\;(t = 0,1, 2,\cdots)$观察环境状态${s_t}$(${s_t} \in S$),控制器再从制动级位的集合$A$中选择一个动作${u_t}$. 然后,环境根据列车当前状态信息和制动级位给予一定奖励${r_t}$且列车转移到新的状态${s_{t + 1}}$. 列车控制器通过评估每个动作的价值,并采取最大价值更新${Q_\pi }({s_t},{u_t})$,更新方式为
Qπ(st,ut)=rt+γmaxQπ(st+1,ut+1), (10) 式中:γ为目标值的折扣系数.
为了得到最大的奖励回报,假设状态转移概率$p$已知,根据贝尔曼最优方程和最优性原理求得最优动作策略${\pi ^ * }({s_t}|{u_t})$,智能体经过多次价值迭代后其价值函数${Q_\pi }({s_t},{u_t})$收敛于最优价值函数$ Q_\pi ^ * ({s_t},{u_t}) $,此时,最优价值函数$ Q_\pi ^ * ({s_t},{u_t}) $等于最优状态值函数$ V_\pi ^ * ({s_t}) $,策略更新如式(10)[22].
V∗π(st)=Q∗π(st,ut)=maxu(rt+γ∑s∈Sp(st+1|st,ut)V∗(st)), (11) 式中:$ {V^ * }({s_t}) $为时刻$t$的状态价值函数.
2.5 学习过程
2.5.1 数据生成
列车制动控制器通过观测当前时刻运行状态${s_t}$,主Q网络对当前状态根据动作选择策略输出对应列车制动等级的动作${u_t}$,列车状态预测模型根据动作和当前状态生成新的状态${s_{t + 1}}$;环境根据列车制动过程优化目标设计的奖励函数,计算状态${s_t}$转移到新状态${s_{t + 1}}$的奖励${r_t}$.
2.5.2 经验回放
将时刻$t$状态、动作和奖励数据$ \lt {s_t},{u_t},{r_t},{s_{t + 1}} \gt $存入经验池中,作为列车制动控制器的学习数据. 训练时,随机从经验池中抽取一定数量的样本$ \lt {s_j}, {u_j},{r_j},{s_{j + 1}} \gt $作为训练数据,将状态和动作$ \lt {s_j},{u_j} \gt $输入到主Q网络得到对应动作的$Q({s_j},{u_j};{\theta _j})$($\theta_j $为当前神经网络权重系数),$ \lt {s_{j + 1}},{u_{j + 1}} \gt $输入到目标Q网络中得到目标值$\max \tilde Q({s_{j + 1}},{u_{j + 1}};{\theta _{j + 1}})$($\theta_{j+1} $为目标网络的权重系数).
2.5.3 网络更新
BFS-DQN中Q网络通过式(12)更新参数权重.
{L(θj)=E[(rj+γmaxu˜Q(sj+1,uj+1;θj+1)−Q2(sj,uj;θj)],θj+1=θj+αloss(θ)∇Q(sj,uj;θj), (12) 式中: $\alpha $为网络学习率.
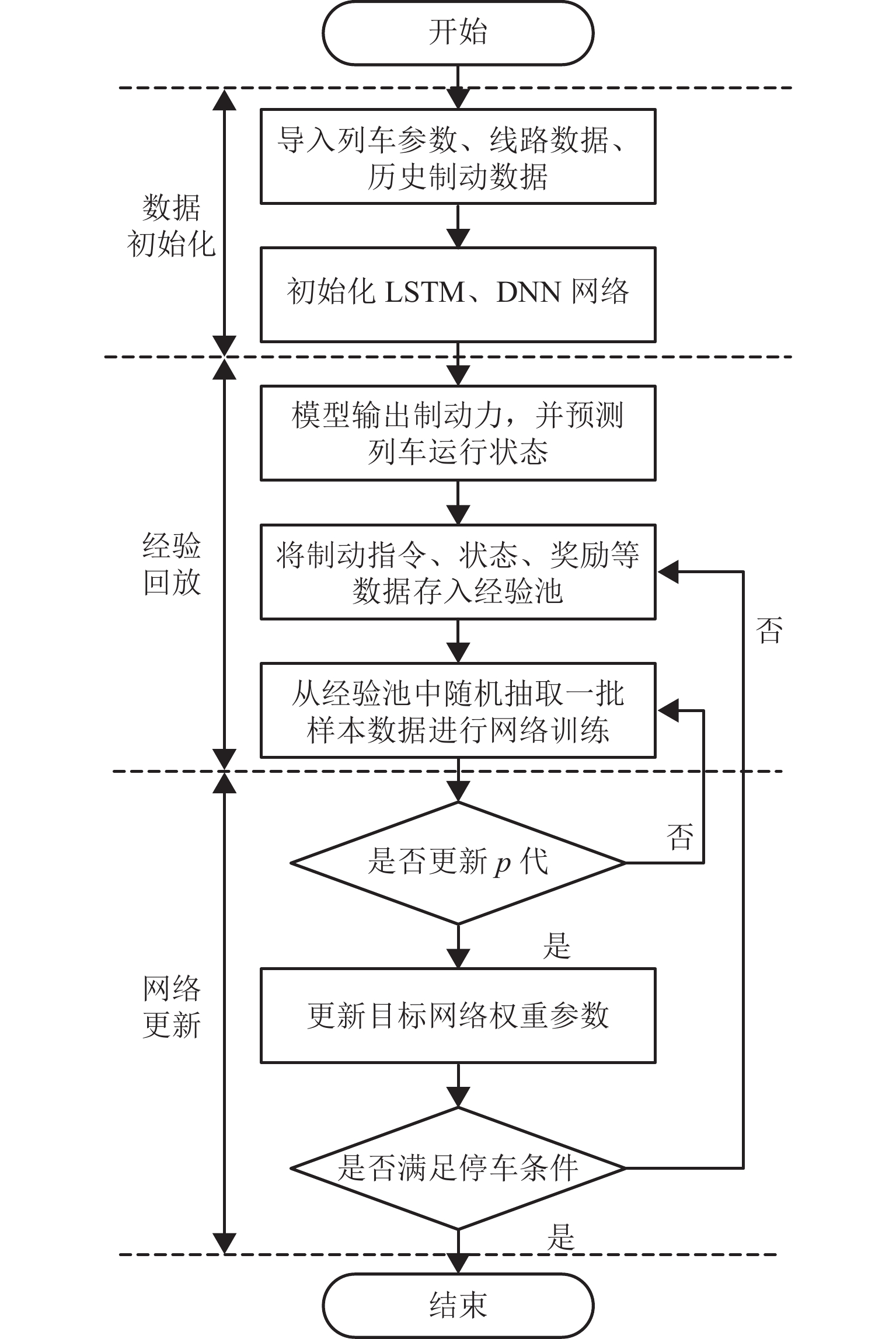
间隔一定训练次数复制主Q网络的权重参数到目标Q网络. 上述过程经过一定次数的循环训练,主Q网络收敛于目标Q网络,列车制动控制器学习到最优制动策略. BFS-DQN训练示意如图5.
 图 5 强化学习制动优化控制算法流程Figure 5. Flowchart of optimization control algorithm for reinforcement learning braking
图 5 强化学习制动优化控制算法流程Figure 5. Flowchart of optimization control algorithm for reinforcement learning braking3. 实验结果与分析
3.1 实验设置
为验证本文所提BFS-DQN方法有效性,以湖南省某条磁浮线路现场运营数据为例进行仿真验证,列车主要参数详见表1所示.
表 1 仿真列车参数Table 1. Simulation train parameters参数类别 参数特性 列车质量/t 75 线路最高限速/(km·h−1) 80 编组数量 3 最大常用制动力/kN 74.23 最大常用减速度/(m·s−2) 0.96 线路最大坡度/‰ 51.01 3.2 收敛性对比
本文采用传统DQN控制方法与BFS-DQN分别进行仿真,主要训练参数详见表2.
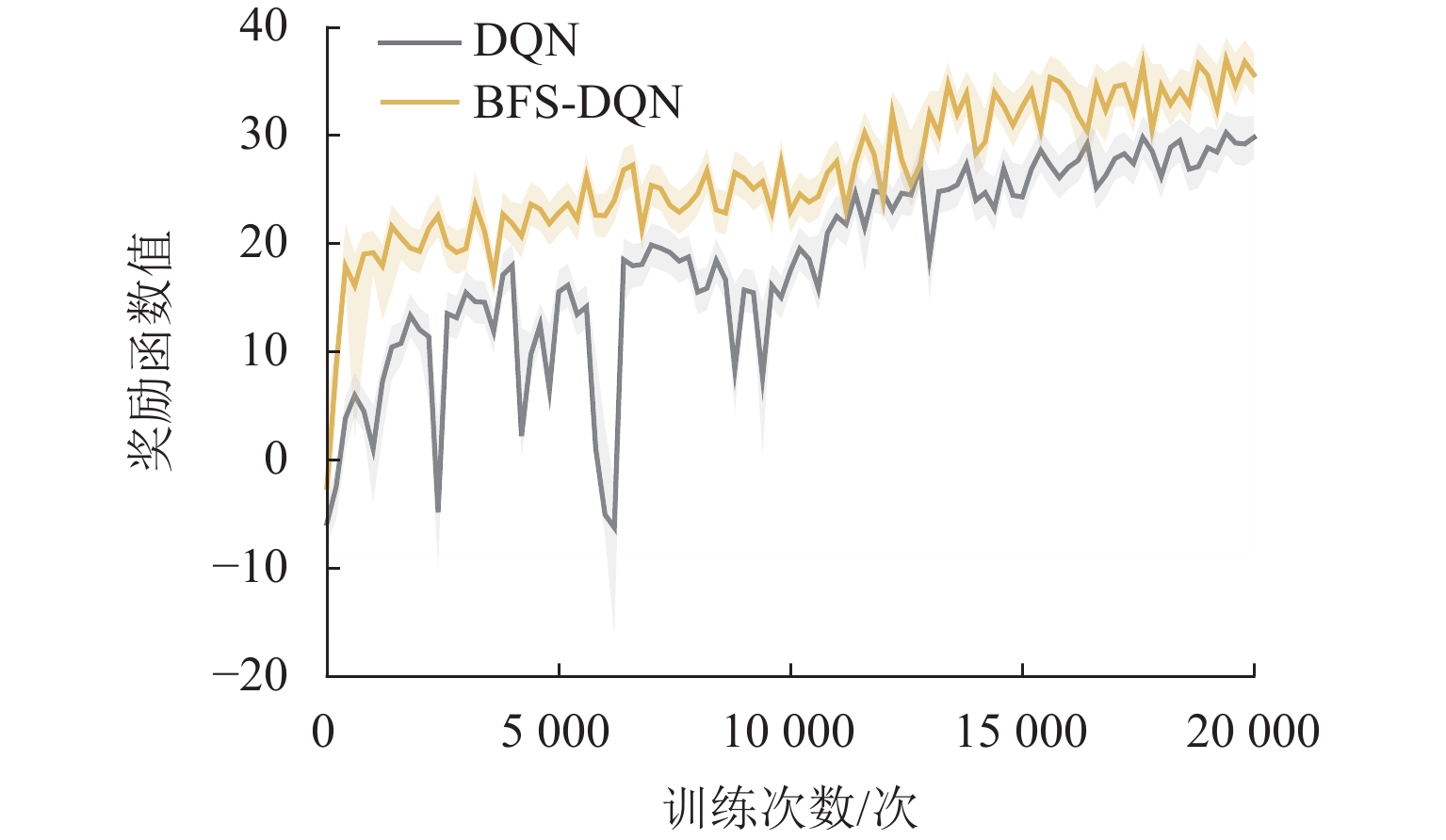
表 2 算法主要训练参数Table 2. Main training parameters for algorithm参数 BFS-DQN DQN LSTM 迭代次数/次 500 LSTM 学习率 0.001 LSTM 样本批量 50 单次训练最大步数/步 80 80 训练最大次数/次 20000 20000 Q 网络学习率 0.001 0.001 Q 网络更新频率 100 100 样本大小 32 32 经验池容量 2000 2000 折扣因子 0.96 0.96 贪婪率初始值 0.9 0.9 贪婪率最终值 0.1 0.1 同时,本文采用动态$ {\varepsilon {\text{-}} {\rm{greedy}}} $优化算法使智能体能够合理利用探索策略. 训练初期采用较大探索率,随着训练次数增加,探索率减小,智能体偏向选择奖励值最大的动作. 对列车控制器进行20000次训练,每250轮计算平均奖励值,通过观察奖励函数变化情况来判断算法是否收敛. BFS-DQN和DQN训练过程奖励变化情况详见图6所示.
从图6可以看出:训练初BFS-DQN和DQN的奖励值都呈现出明显上升趋势,说明智能体能够迅速找到合适的动作策略;训练次数达到12000次以上,2种优化算法平均奖励值缓慢上升并趋于稳定;BFS-DQN方法平均奖励高于传统DQN方法,制动特征自学习有助于强化学习智能体获取准确的状态信息和奖励,提高网络学习能力.
3.3 舒适性和停车精度
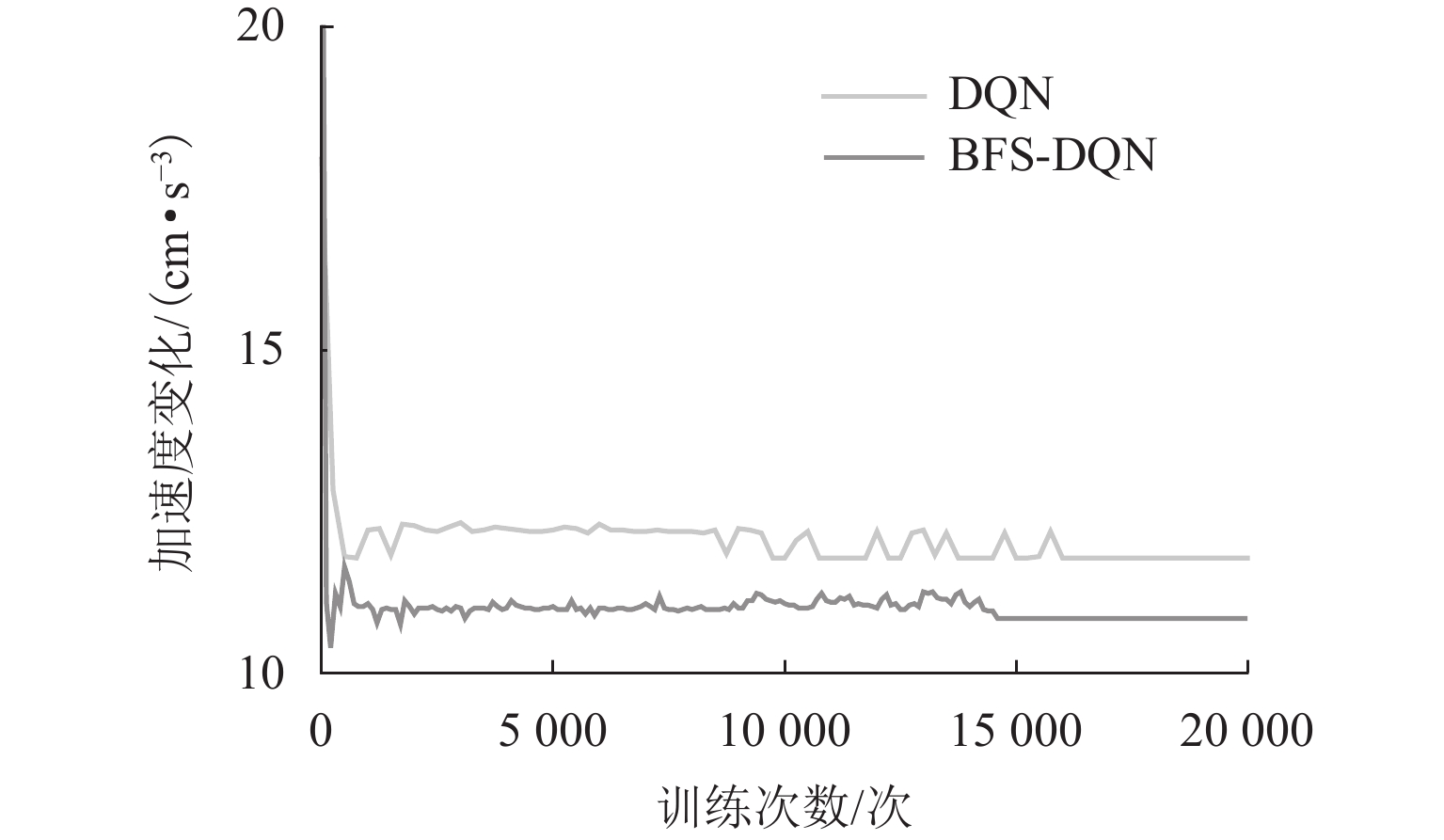
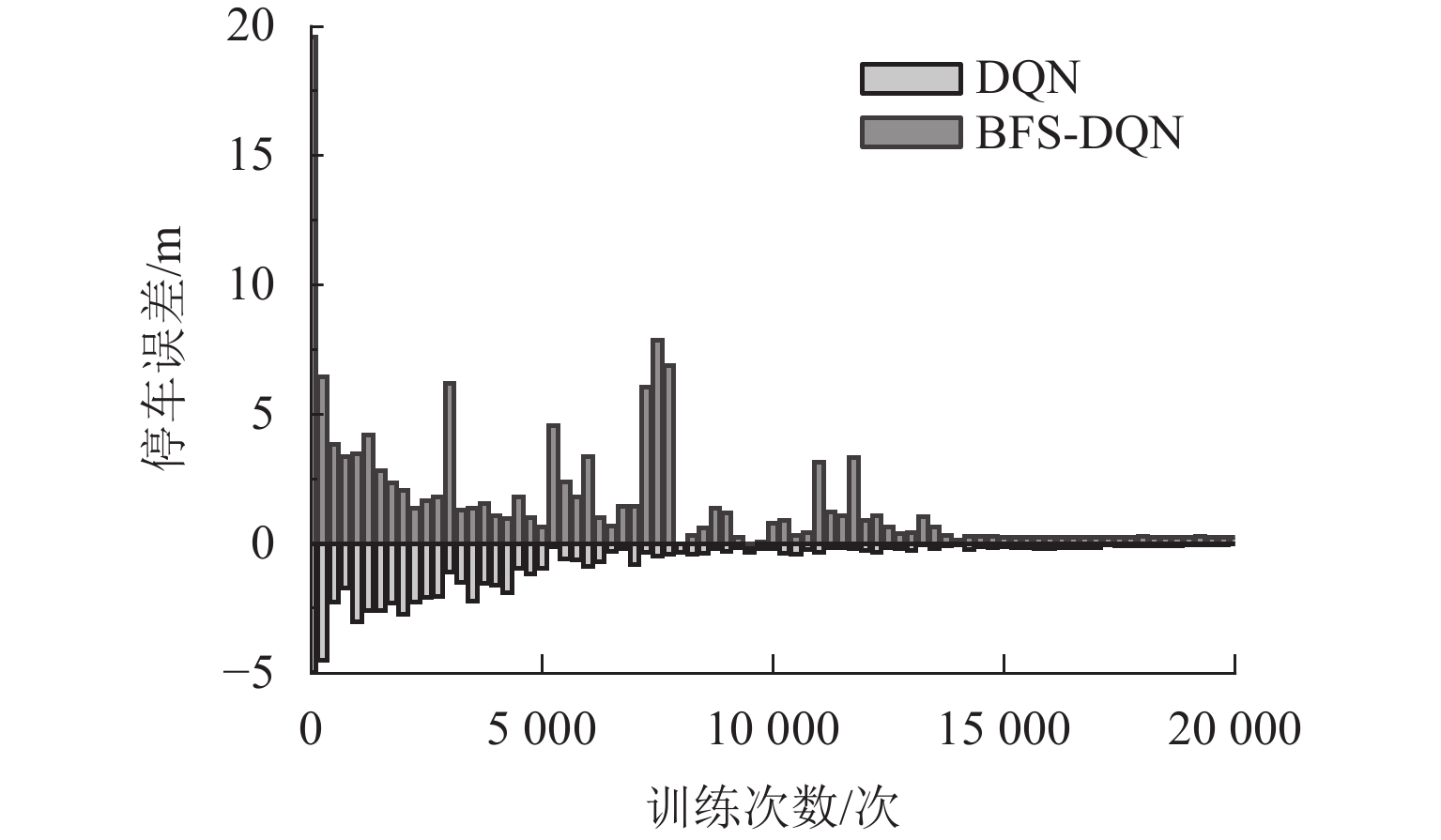
图7和图8分别为训练过程中平均加速度变化和平均停车误差变化情况. 统计最后5000次训练结果,加速度变化和停车误差情况如表3所示.
 图 8 停车误差收敛情况(DQN和BFS-DQN分别取停车误差的绝对值和绝对值负值)Figure 8. Convergence of parking errors (DQN and BFS-DQN take the absolute value and negative value of absolute value of parking error, respectively)
图 8 停车误差收敛情况(DQN和BFS-DQN分别取停车误差的绝对值和绝对值负值)Figure 8. Convergence of parking errors (DQN and BFS-DQN take the absolute value and negative value of absolute value of parking error, respectively)从图7和图8可以看出:初期加速度变化和停车误差都很大,但加速度变化很快收敛,由于停车奖励需要列车到站才能获得,智能体经过更多次的训练才寻得最优的停车策略. 由表3可得:BFS-DQN在舒适性和停车精度方面比传统DQN提高8.67%和33.33%. 训练结果表明:基于BFS-DQN磁浮列车制动优化控制方法取得了良好的控制效果,且比传统DQN方法在舒适性和停车精度方面更具有优越性.
表 3 算法训练结果Table 3. Training results for algorithm训练结果 BFS-DQN DQN 平均奖励值 33.5 27.8 平均状态转移次数/次 70 72 平均停车误差/m 0.10 0.15 平均加速度变化/(cm·s−3) 10.84 11.78 平均制动时间/s 14.0 14.4 3.4 实际运行数据验证实验
为验证BFS-DQN算法可行性,将训练好的列车控制器进行仿真测试,并记录50次测试的停车误差数据. 同时,本文分别采用均方根误差(RMSE)和标准差(SD)来评价不同制动算法的性能,结果如表4所示. 取其中一次数据的制动曲线如图9所示.
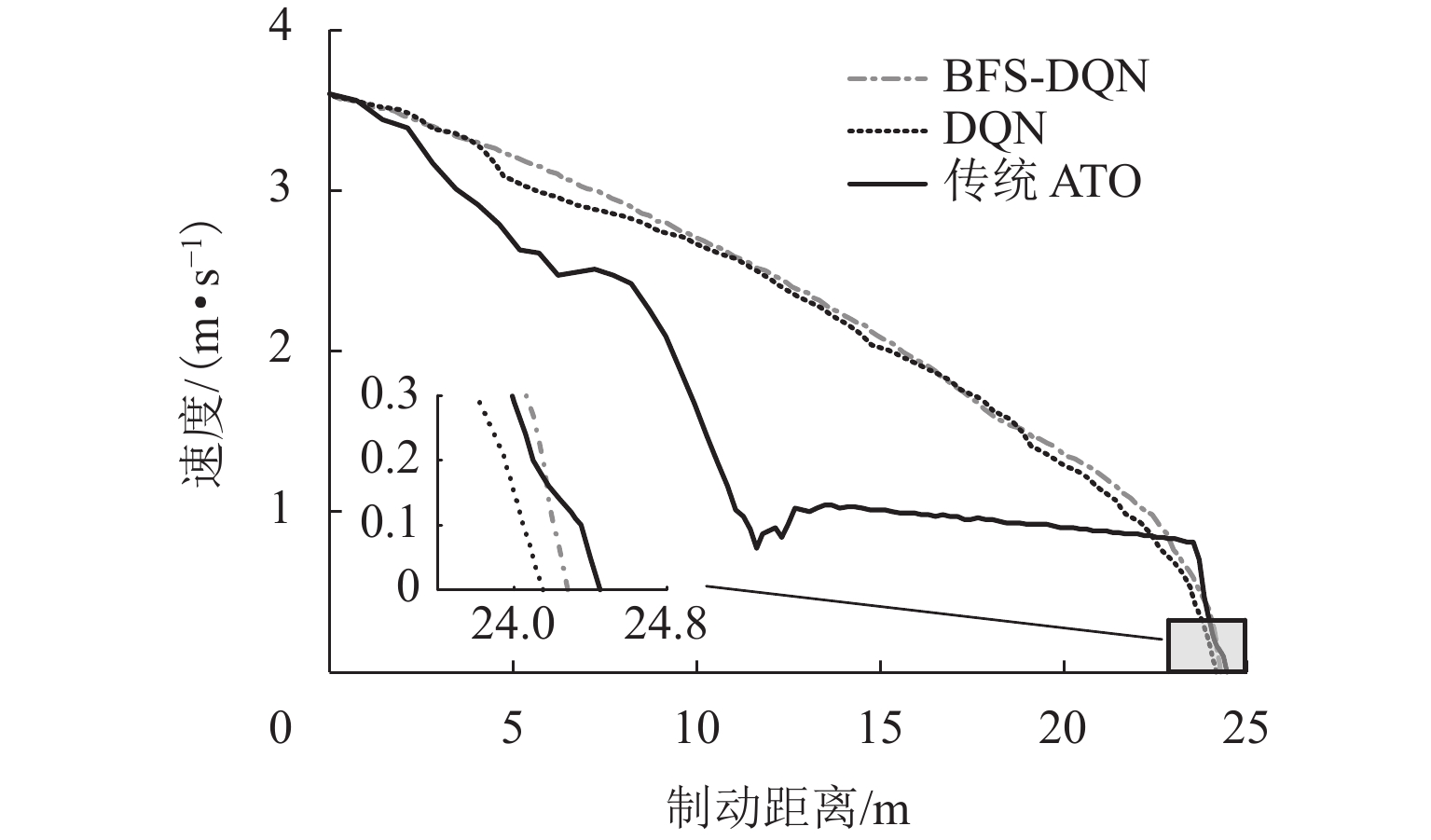
表 4 算法性能Table 4. Algorithm performance制动控制策略 RMSE SD BFS-DQN 0.099048 0.070652 DQN 0.142815 0.110446 传统 ATO 0.276103 0.140018 由表4可见:3种制动控制算法中,BFS-DQN制动控制算法的表现最好,停车误差小,且离散程度低,稳定性高. 由图9可知:采用传统ATO制动策略生成的制动曲线波动较大,而BFS-DQN和DQN制动策略生成的制动曲线较为平滑;停车精度方面,BFS-DQN、DQN和传统ATO 制动策略下的制动距离分别为24.26、24.19、24.45 m,停车误差分别为0.04、0.11、0.15 m,BFS-DQN和DQN方法都能够有效提高磁浮列车到站停车精度,且BFS-DQN方法更具优越性.
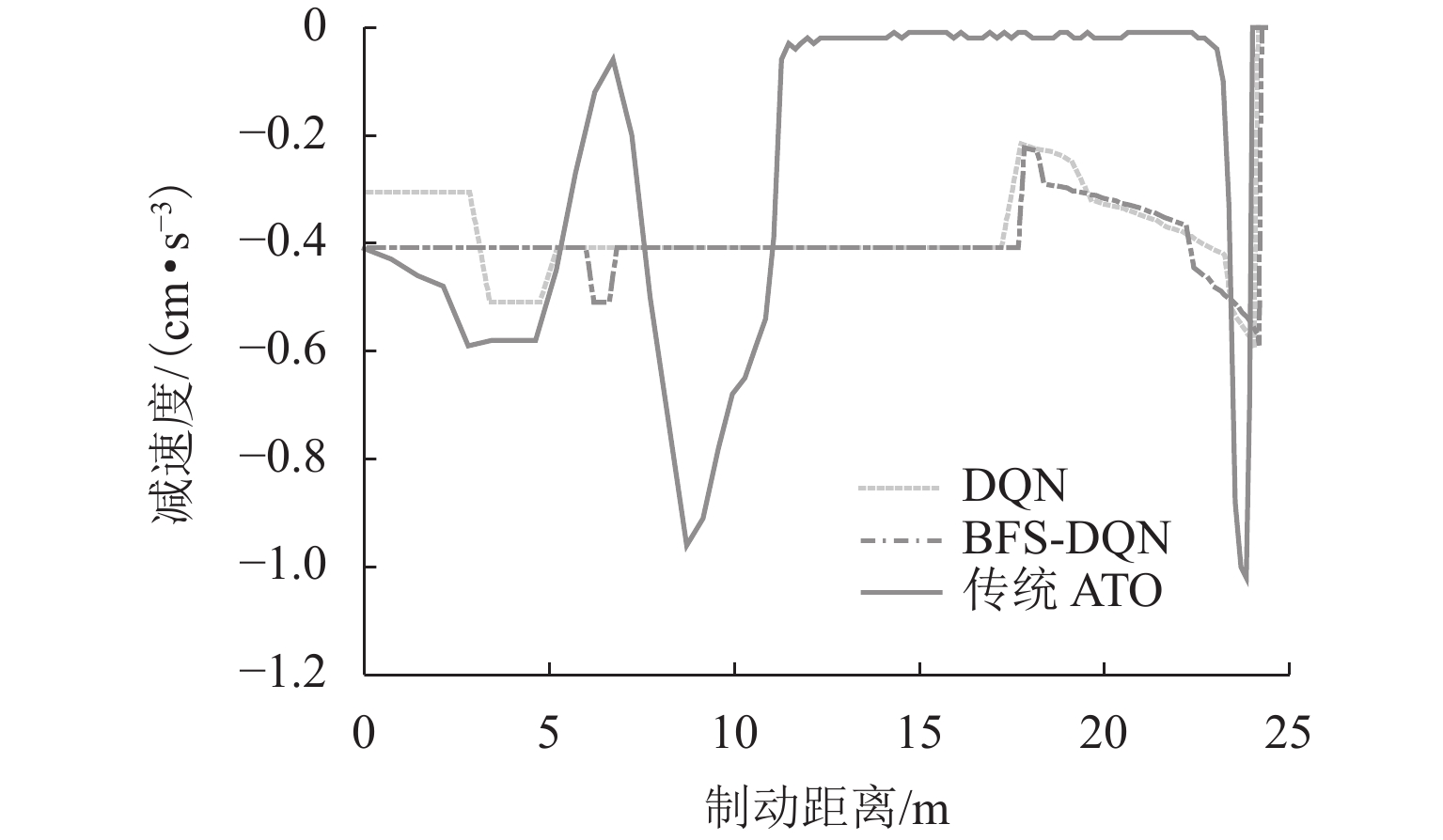
图10为3种制动策略下减速度变化情况,由图10分析可知:由于传统ATO制动策略采用电液混合制动-惰行-液压制动的方式进行制动停车,当磁浮列车制动距离为6.25、11.30、23.75 m时,由于电制动响应延迟和液压制动离散等特点,制动等级突变引起减速度剧烈变化,减速度最大改变量达到1.02 m/s3,较大的纵向冲击对乘客的安全性和舒适性造成影响;BFS-DQN方法在减速度控制方面更加合理,在列车停车的最后一刻的减速度最大改变量为0.6 m/s3,有效减少制动过程中产生的纵向冲击,舒适性上提高41.18%.
3.5 现场数据实验验证
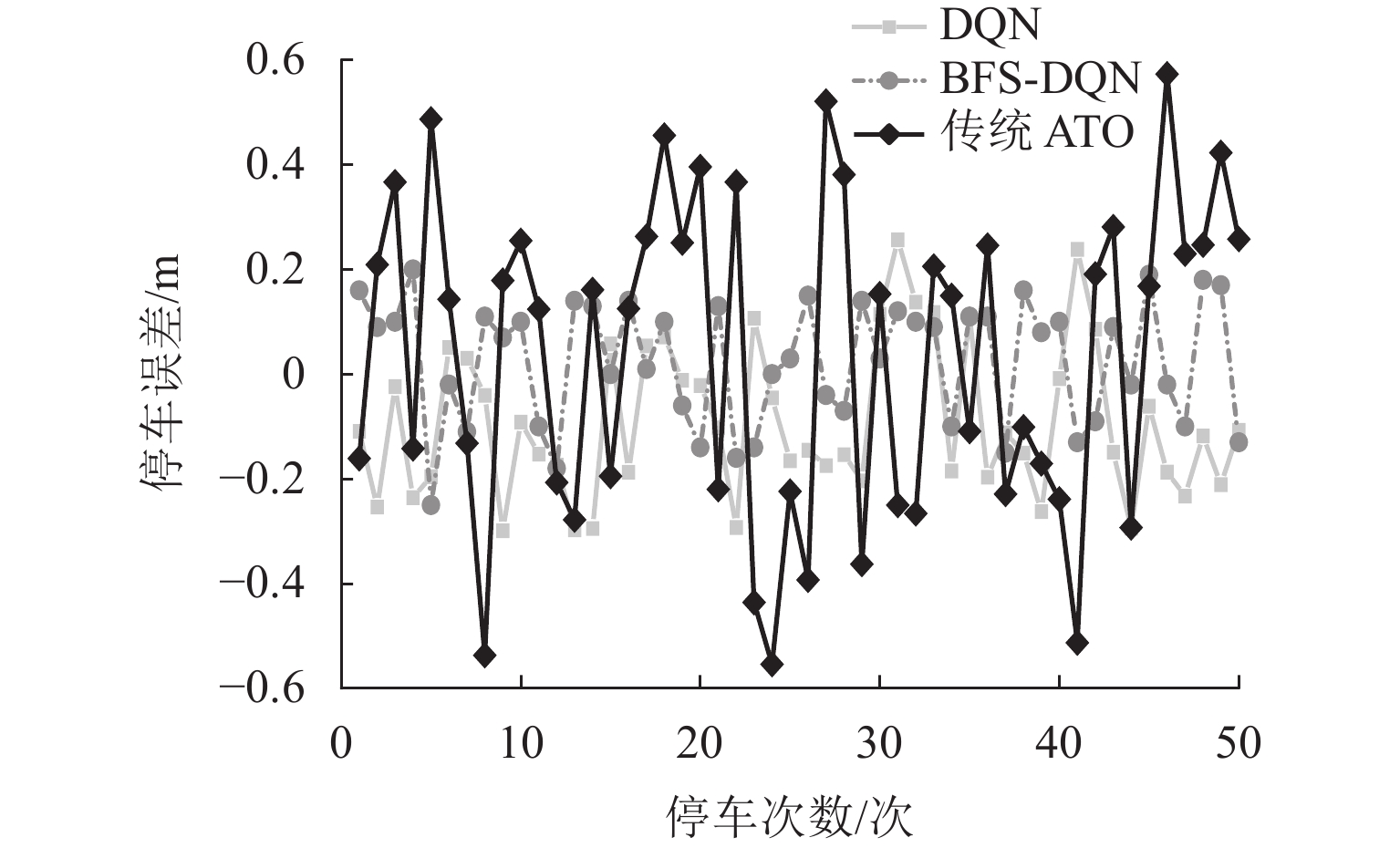
为进一步检验制动控制器的性能和稳定性,将目标制动距离设为24.60、24.90、25.10 m,依次进行精准停车测试,50次测试结果如表5和图11所示.
表 5 停车误差分布情况Table 5. Distribution of parking errors次 停车误差/m BFS-DQN DQN ATO $ x \lt - 0.5 $ 0 0 3 $ - 0.5 \leqslant x \leqslant - 0.3 $ 0 2 3 $ - 0.3 \lt x \leqslant 0 $ 18 19 16 $0 \lt x \leqslant 0.3$ 32 29 20 $ 0.3 \lt x \leqslant 0.5 $ 0 0 6 $ x \gt 0.5 $ 0 0 2 图11可以看出:BFS-DQN和DQN方法的停车误差分别在±20 cm与±24 cm之间波动,表明BFS-DQN在不同目标制动距离干扰下稳定性要高于DQN. 由表3数据统计得:当前ATO制动策略下列车满足±30 cm精准停车要求39次,占比78.0%;DQN方法的停车精度满足±30 cm内48次,占比96.0%;本文提出的BFS-DQN算法满足停车精度±30 cm内50次,占比100%.
4. 结 论
1) 本文针对磁浮列车电-液混合制动问题提出了基于混合制动特征自学习的磁浮列车强化学习制动控制方法. 利用磁浮列车运行数据进行仿真实验,结果验证所提控制策略可以帮助磁浮列车平稳度过电液制动转换阶段,减少列车制动过程产生的纵向冲击,保障乘客舒适性的同时也提高了列车到站停车精度.
2) 对于不同目标制动距离的干扰,所提策略能够根据列车反馈的运行状态及时调整制动策略,控制列车输出合理的制动力,确保列车满足精准停车要求,具有一定的稳定性和自适应能力.
-

 下载:
下载:

 点击查看大图
点击查看大图
计量
- 文章访问数: 1677
- HTML全文浏览量: 79
- PDF下载量: 734
- 被引次数: 0
 下载:
下载: