

Detection Method for Stator Surface of Maglev Tracks Based on Vision-Language Fusion
-
摘要:
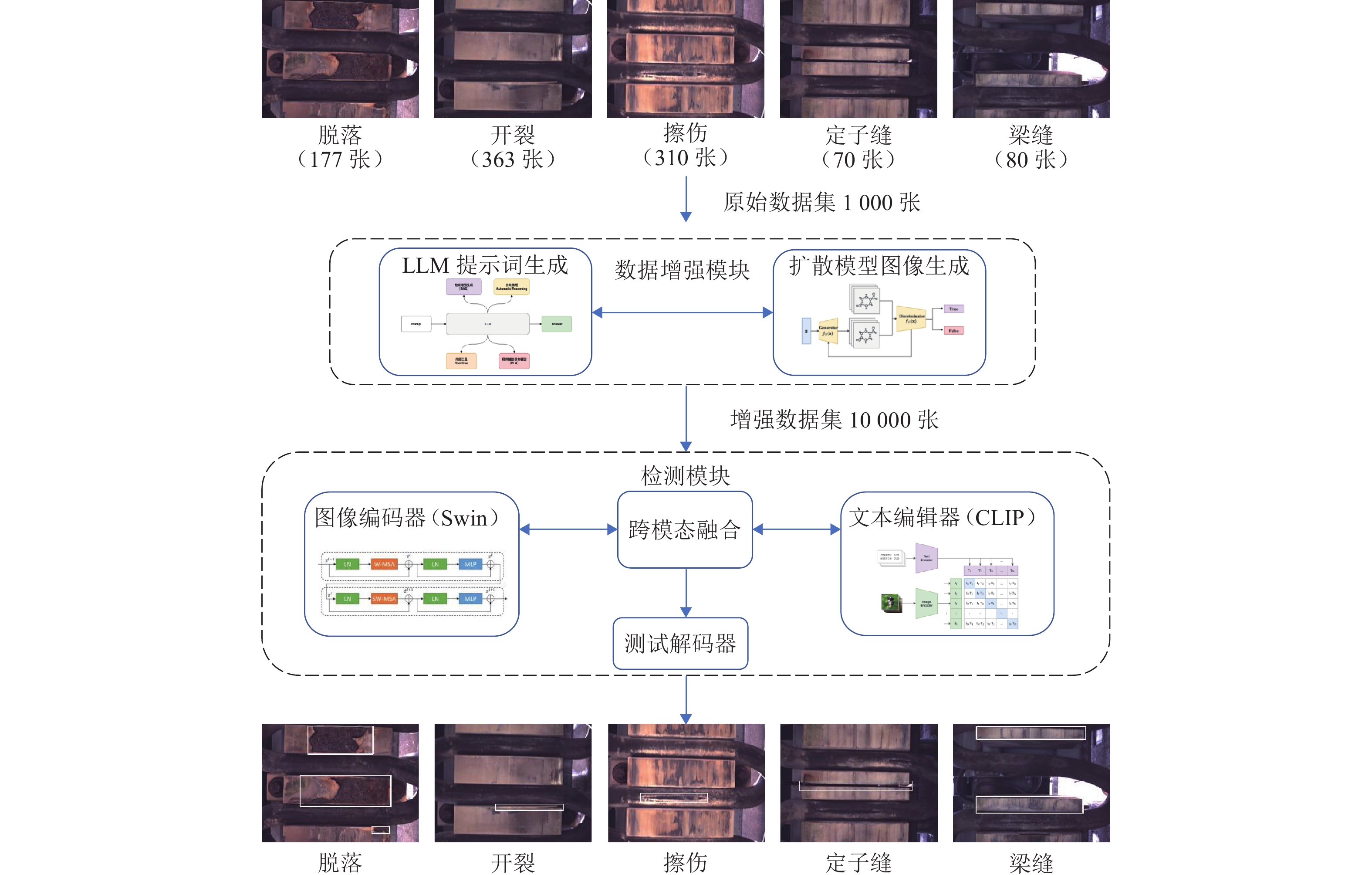
为解决磁浮轨道定子面检测中数据量不足、类别分布不均衡的问题,提出一种基于大语言模型引导扩散模型的视觉-语言融合检测方法. 首先,针对脱落、开裂、擦伤、定子缝、梁缝5类类别样本稀缺且分布失衡的现状,设计大语言模型引导的提示词生成策略,通过链式推理生成多样化的缺陷语义描述;其次,将生成的提示词与空间掩码约束输入潜在扩散模型,生成高质量且相似分布的样本,有效扩充稀缺类别数据;最后,构建融合视觉与语言模态的检测网络,通过特征增强器实现图像与文本的双向交叉注意力融合,采用语言引导查询选择机制动态生成检测查询,并设计跨模态解码器完成多阶段特征交互. 研究结果表明:在采用大语言模型实现数据增强的情况下,生成样本质量较传统生成方法提高约15%,且检测网络在5类检测类别的平均检测精度较基线方法提升约7%.
Abstract:To solve the problems of insufficient data volume and unbalanced category distribution in the detection of the stator surface of maglev tracks, a vision-language fusion detection method based on a large language model-guided diffusion model was proposed. First, given the current situation of scarcity and unbalanced distribution of five types of samples (spalling, cracking, scratching, stator gap, and beam gap), a prompt word generation strategy guided by a large language model was designed to generate diversified semantic descriptions of defects through chain-of-thought reasoning. Secondly, the generated prompt words and spatial mask constraints were input into a latent diffusion model to generate high-quality samples with similar distributions, effectively expanding the data of scarce categories. Finally, a detection network fusing vision and language modalities was constructed, where bidirectional cross-attention fusion of images and texts was achieved through a feature enhancer, a language-guided query selection mechanism was adopted to dynamically generate detection queries, and a cross-modal decoder was designed to complete multi-stage feature interaction. The research results indicate that under the condition of data augmentation assisted by the large language model, the quality of generated samples increases by approximately 15% compared with traditional generation methods, and the average detection accuracy of the detection network on the five categories increases by approximately 7% compared with baseline methods.
-
Key words:
- maglev track /
- defect detection /
- computer vision /
- data augmentation /
- object detection
-

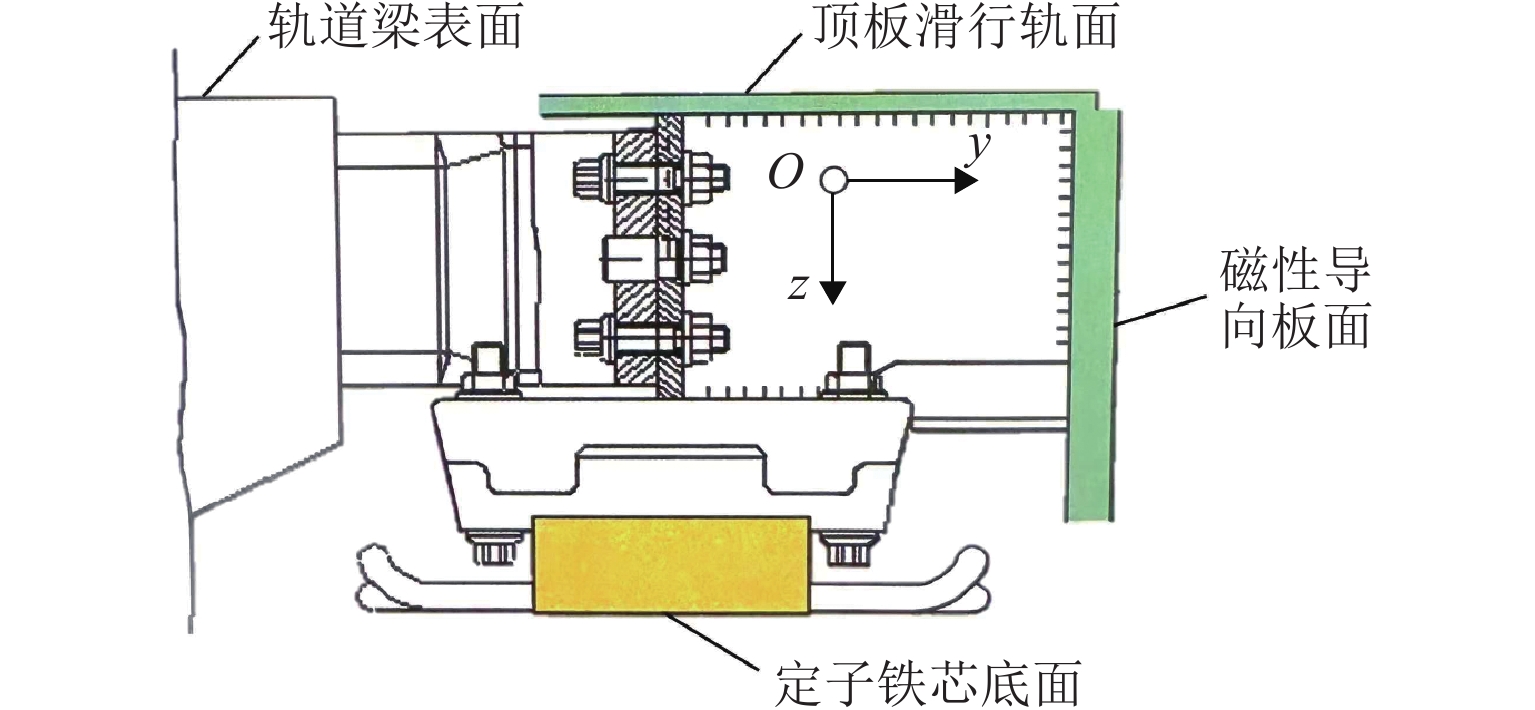
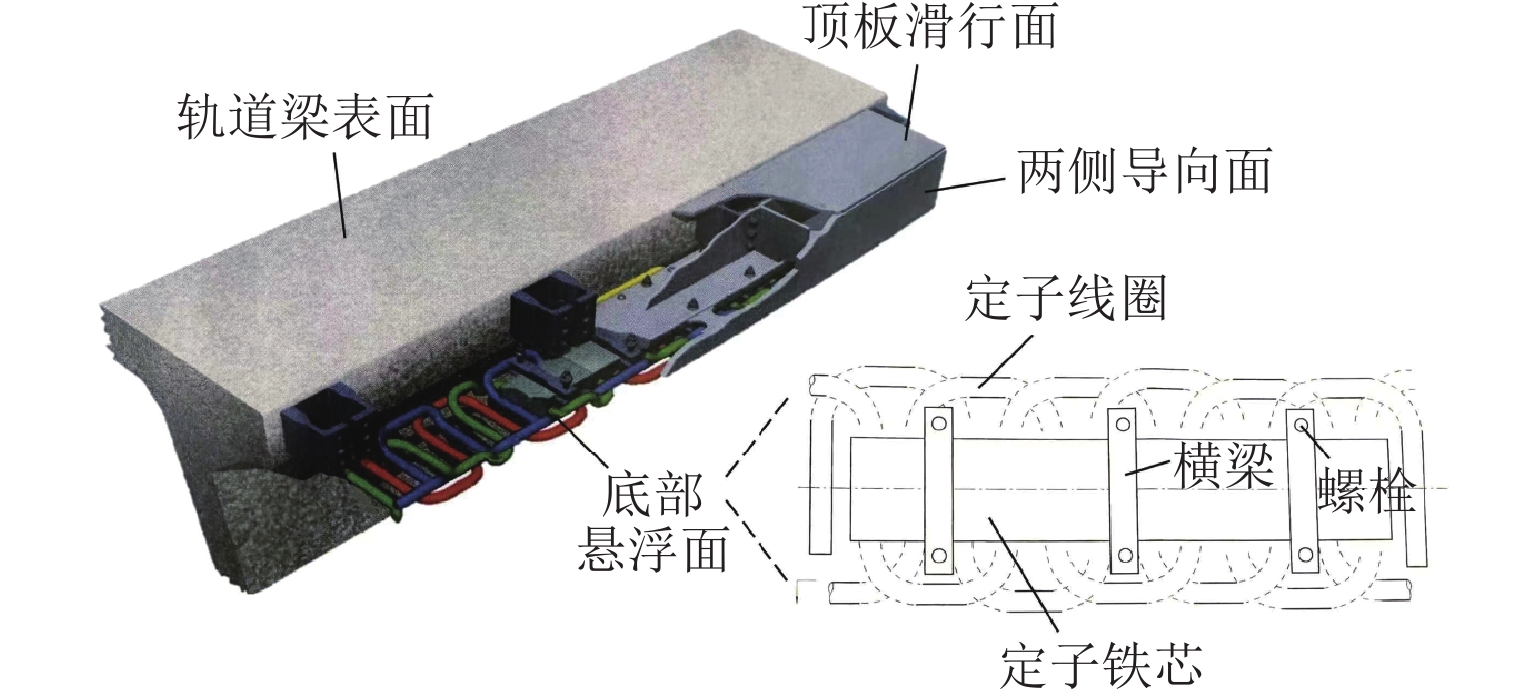
图 3 磁浮轨道定子面图像采集试验小车
Figure 3. Image acquisition vehicle for stator surface of maglev track
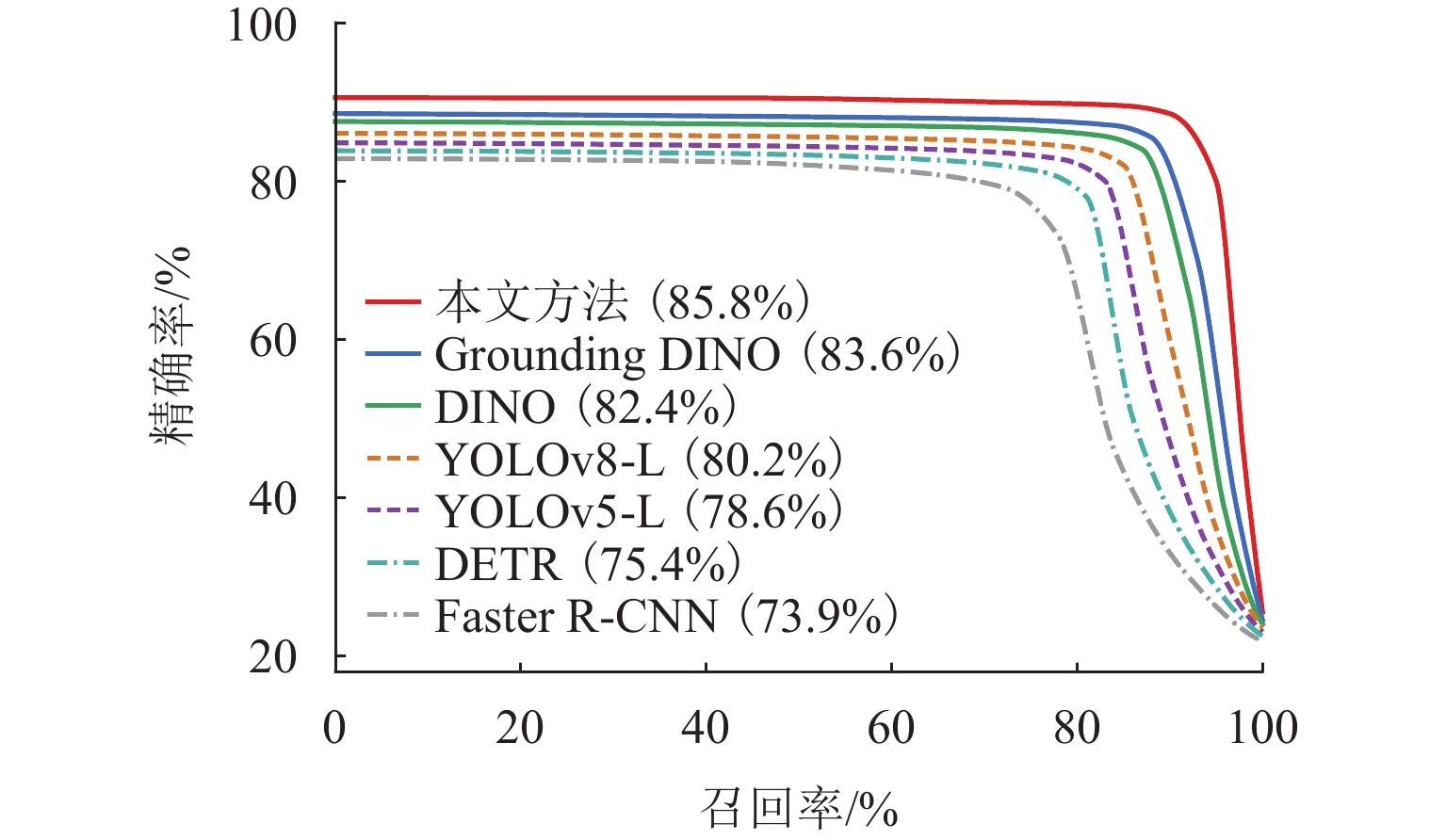
图 7 不同检测方法的 P-R 曲线对比
Figure 7. Comparison of P-R curves for different detection methods
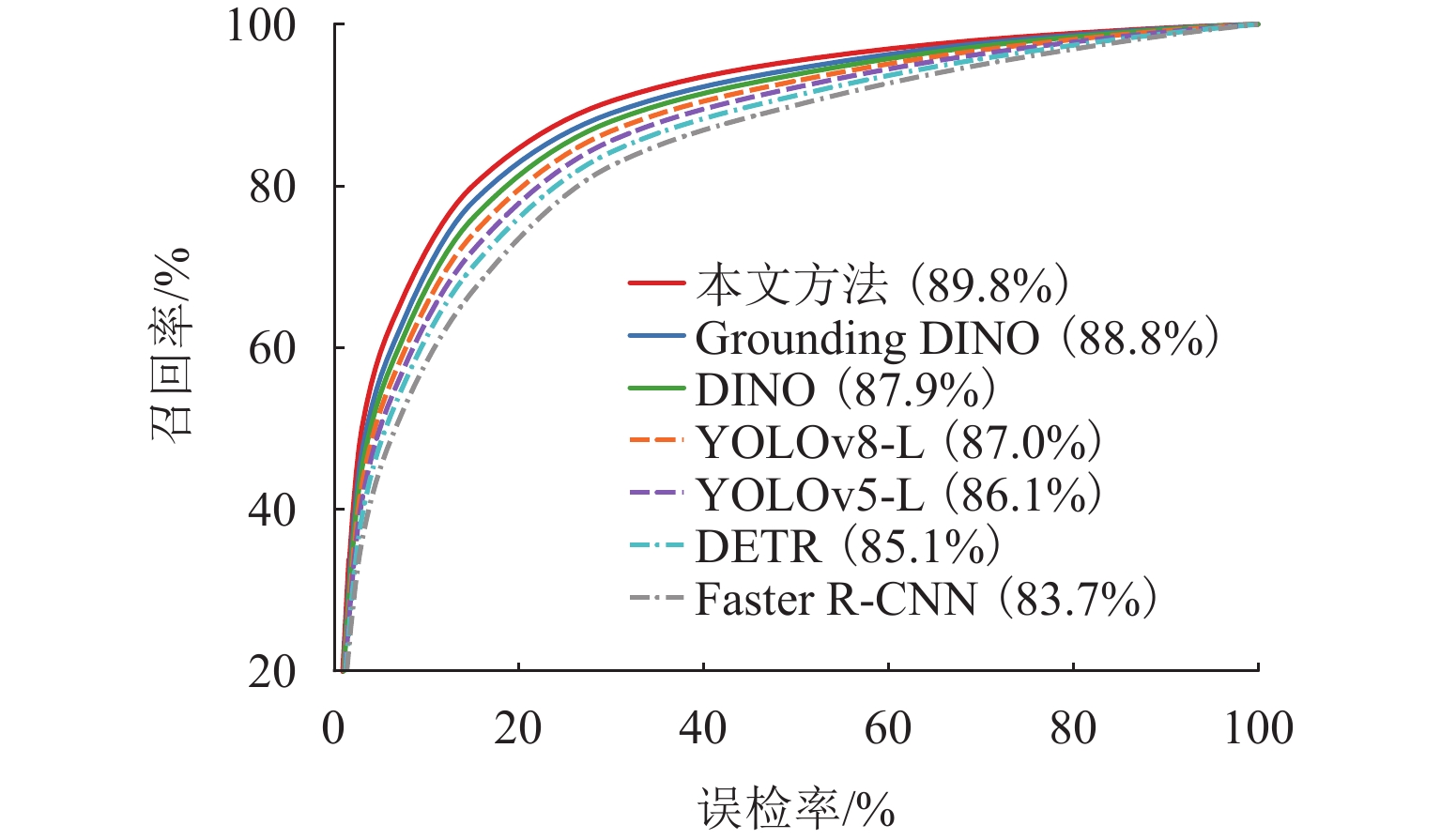
图 8 不同检测方法的 ROC 曲线对比
Figure 8. Comparison of ROC curves for different detection methods
表 1 磁浮定子面数据集统计
Table 1. Statistical of maglev stator surface dataset
类型 样本数量/张 脱落 177 开裂 363 擦伤 310 定子缝 70 梁缝 80  下载: 导出CSV
下载: 导出CSV
表 2 不同图像生成方法效果对比
Table 2. Comparison of FID scores for different generation methods
方法 FID IS VAE 21.3 2.75 GAN 19.8 2.90 DDPM 18.1 3.05 Stable Diffusion 17.4 3.15 Stable Diffusion + 链式推理提示词 16.5 3.28 Stable Diffusion + 注意力空间约束 16.8 3.22 本文方法 15.6 3.40
下载: 导出CSV
表 4 数据增强对检测性能的影响
Table 4. Effects of data augmentation on detection performance
% 数据增强方法 P R mAP@50 F1 无增强(原始数据集) 78.3 75.6 68.5 76.9 传统增强 82.1 79.8 73.2 80.9 Diffusion 增强 88.4 86.2 80.2 87.3 本文方法增强 92.6 91.0 85.8 91.8
下载: 导出CSV
表 5 不同LoRA秩$ r $对生成质量的影响
Table 5. Effects of different LoRA ranks on generation quality
秩r FID IS 4 18.2 3.05 8 16.8 3.22 16 15.6 3.40 32 15.9 3.35 64 16.4 3.18
下载: 导出CSV
表 6 不同检测方法性能对比
Table 6. Comparison of performance for different detection methods
方法 P/% R/% mAP@50/% F1/% FPS/(帧·s−1) Faster R-CNN[25] 82.13 ± 1.07 79.30 ± 1.05 74.26 ± 0.85 80.68 ± 0.65 22 RetinaNet 84.77 ± 0.70 84.08 ± 0.57 76.17 ± 1.16 84.42 ± 0.48 35 Efficient Det[26] 85.28 ± 0.82 86.48 ± 0.67 76.98 ± 0.71 85.87 ± 0.46 32 YOLOv5-L 87.19 ± 0.62 85.84 ± 0.51 78.40 ± 0.88 86.51 ± 0.47 40 YOLOv8-L 88.18 ± 0.82 87.53 ± 0.81 80.08 ± 0.84 87.85 ± 0.56 45 DETR[27] 83.42 ± 1.17 82.22 ± 1.03 75.80 ± 1.33 82.81 ± 0.62 18 DINO[28] 89.16 ± 0.51 88.67 ± 0.64 82.80 ± 0.50 88.91 ± 0.38 15 Grounding DINO 90.25 ± 0.39 89.15 ± 0.82 83.64 ± 0.48 89.69 ± 0.39 10 GPT4[29] 87.39 ± 0.73 85.63 ± 1.15 80.90 ± 0.88 86.49 ± 0.64 Qwen3.7[30] 85.72 ± 0.88 84.28 ± 1.02 79.88 ± 1.19 84.99 ± 0.69 本文方法 92.48 ± 0.54 91.26 ± 0.36 85.86 ± 0.37 91.87 ± 0.39 28
下载: 导出CSV
表 7 不同检测方法的类别级性能对比(mAP@50)
Table 7. Comparison of category-level performance for different detection methods (mAP@50)
% 方法 脱落 开裂 擦伤 定子缝 梁缝 YOLOv8 82.5 84.3 83.1 74.1 74.3 Grounding DINO 85.2 86.8 85.4 79.5 81.2 本文方法 88.4 89.2 87.5 82.3 81.7
下载: 导出CSV
-
[1] 邓自刚, 刘宗鑫, 李海涛, 等. 磁悬浮列车发展现状与展望[J]. 西南交通大学学报, 2022, 57(3): 455-474, 530.Deng Zigang, Liu Zongxin, Li Haitao, et al. Development status and prospect of maglev train[J]. Journal of Southwest Jiaotong University, 2022, 57(3): 455-474, 530. [2] 张雯柏, 林国斌, 康劲松, 等. 考虑相移补偿的磁浮列车长定子高频注入无传感控制方法[J]. 西南交通大学学报, 2025, 60(4): 1032-1041. doi: 10.3969/j.issn.0258-2724.20240310Zhang Wenbai, Lin Guobin, Kang Jinsong, et al. Sensorless control method of high-frequency injection for long-stator synchronous motor of maglev trains considering phase shift compensation[J]. Journal of Southwest Jiaotong University, 2025, 60(4): 1032-1041. doi: 10.3969/j.issn.0258-2724.20240310 [3] Wang T G, Zhang Z J, Tsui K L. A deep generative approach for rail foreign object detections via semisupervised learning[J]. IEEE Transactions on Industrial Informatics, 2023, 19(1): 459-468. doi: 10.1109/TII.2022.3149931 [4] Zheng X Y, Zhang L F, Luo Y H, et al. A generation-based defect detection system for rail transit infrastructure[J]. High-speed Railway, 2026, 4(1): 1-9. doi: 10.1016/j.hspr.2025.09.004 [5] Wang T G, Zhang Z J, Yang F F, et al. Automatic rail component detection based on AttnConv-net[J]. IEEE Sensors Journal, 2022, 22(3): 2379-2388. doi: 10.1109/JSEN.2021.3132460 [6] Zheng X Y, He Y F, Luo Y H, et al. Railway side slope hazard detection system based on generative models[J]. IEEE Sensors Journal, 2025, 25(9): 16281-16296. doi: 10.1109/JSEN.2025.3538529 [7] Guan L, Jia L M, Xie Z Y, et al. A lightweight framework for obstacle detection in the railway image based on fast region proposal and improved YOLO-tiny network[J]. IEEE Transactions on Instrumentation and Measurement, 2022, 71: 5009116. [8] Zhao Z Y, Kang J H, Sun Z F, et al. A real-time and high-accuracy railway obstacle detection method using lightweight CNN and improved transformer[J]. Measurement, 2024, 238: 115380. doi: 10.1016/j.measurement.2024.115380 [9] Zhang Z P, Chen P R, Huang Y J, et al. Railway obstacle intrusion warning mechanism integrating YOLO-based detection and risk assessment[J]. Journal of Industrial Information Integration, 2024, 38: 100571. doi: 10.1016/j.jii.2024.100571 [10] 彭龙, 叶丰, 曾国锋, 等. 高速磁浮“车-轨-人”动力系统建模与实测验证[J]. 西南交通大学学报, 2026, 61(4): 2026-01-14.Peng Long, Ye Feng, Zeng Guofeng, et al. Modeling and experimental validation of the “vehicle-guideway-human” dynamic system for high-speed maglev[J]. Journal of Southwest Jiaotong University, 2026, 61(4): 2026-01-14. [11] Wang T G, Zhang Z J, Tsui K L. A hierarchical transfer-generative framework for automating multianalytical tasks in rail surface defect inspection[J]. IEEE Internet of Things Journal, 2024, 11(12): 21513-21526. doi: 10.1109/JIOT.2024.3374751 [12] 田阳, 刘桂卫, 崔庆国, 等. 铁路隧道衬砌病害轻量化智能检测技术研究[J]. 铁道工程学报, 2025, 42(2): 85-90. doi: 10.3969/j.issn.1006-2106.2025.02.016Tian Yang, Liu Guiwei, Cui Qingguo, et al. Research on lightweight intelligent detection technology of railway tunnel lining disease[J]. Journal of Railway Engineering Society, 2025, 42(2): 85-90. doi: 10.3969/j.issn.1006-2106.2025.02.016 [13] Guo F, Qian Y, Wu Y P, et al. Automatic railroad track components inspection using real-time instance segmentation[J]. Computer-Aided Civil and Infrastructure Engineering, 2021, 36(3): 362-377. doi: 10.1111/mice.12625 [14] Liu D C, Wu D H, Xu J Q, et al. Machine learning in maglev transportation systems: review and prospects[J]. Actuators, 2025, 14(12): 576. doi: 10.3390/act14120576 [15] Zeng B J, Zheng X Y, Zhang L F, et al. Enhancing road slope detection with generative models and vision-language models for infrastructure safety[C]//2025 11th International Conference on Computer and Communications (ICCC). Piscataway: IEEE, 2025: 1348-1354. [16] Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models[PP/OL]. V2. arXiv (2020-12-16)[2025-12-01]. https://doi.org/10.48550/arXiv.2006.11239. [17] Rombach R, Blattmann A, Lorenz D, et al. High-resolution image synthesis with latent diffusion models[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2022: 10674-10685. [18] Zhang L M, Rao A Y, Agrawala M. Adding conditional control to text-to-image diffusion models[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 3813-3824. [19] Xie Y L, Pi X N, Zhang Y, et al. Structured guided diffusion models for industrial defect image generation[J]. Knowledge-Based Systems, 2025, 330: 114642. doi: 10.1016/j.knosys.2025.114642 [20] Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//Proceedings of the 38th International Conference on Machine Learning. New York: PMLR, 2021: 8748-8763. [21] Liu S L, Zeng Z Y, Ren T H, et al. Grounding DINO: marrying DINO with grounded pre-training for open-set object detection[C]//Computer Vision—ECCV 2024. Cham: Springer, 2025: 38-55. [22] He H B, Garcia E A. Learning from imbalanced data[J]. IEEE Transactions on Knowledge and Data Engineering, 2009, 21(9): 1263-1284. doi: 10.1109/TKDE.2008.239 [23] Heusel M, Ramsauer H, Unterthiner T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6629-6640. [24] Salimans T, Goodfellow I, Zaremba W, et al. Improved techniques for training GANs[C]//Proceedings of the 30th International Conference on Neural Information Processing Systems. New York: ACM, 2016: 2234-2242. [25] Girshick R. Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2015: 1440-1448. [26] Tan M X, Pang R M, Le Q V. EfficientDet: scalable and efficient object detection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2020: 10778-10787. [27] Zhu X Z, Su W J, Lu L W, et al. Deformable DETR: deformable transformers for end-to-end object detection[PP/OL]. V4. arXiv (2021-03-18)[2025-11-05]. https://doi.org/10.48550/arXiv.2010.04159. [28] Zhang H, Li F, Liu S L, et al. DINO: DETR with improved DeNoising anchor boxes for end-to-end object detection[PP/OL]. V4. arXiv (2022-07-11)[ 2025-11-06]. https://doi.org/10.48550/arXiv.2203.03605. [29] OpenAI, Achiam J, Adler S, et al. GPT-4 technical report[PP/OL]. V6. arXiv (2024-03-04)[2025-11-10]. https://doi.org/10.48550/arXiv.2303.08774. [30] Bai J Z, Bai S, Chu Y F, et al. Qwen technical report[PP/OL]. V1. arXiv (2023-09-28)[2025-11-06]. https://doi.org/10.48550/arXiv.2309.16609. -

 下载:
下载:












 点击查看大图
点击查看大图
计量
- 文章访问数: 26
- HTML全文浏览量: 20
- PDF下载量: 2
- 被引次数: 0