

Method for Crack Detection of Ancient Bridges Based on Computer Vision and Deep Learning
-
摘要:
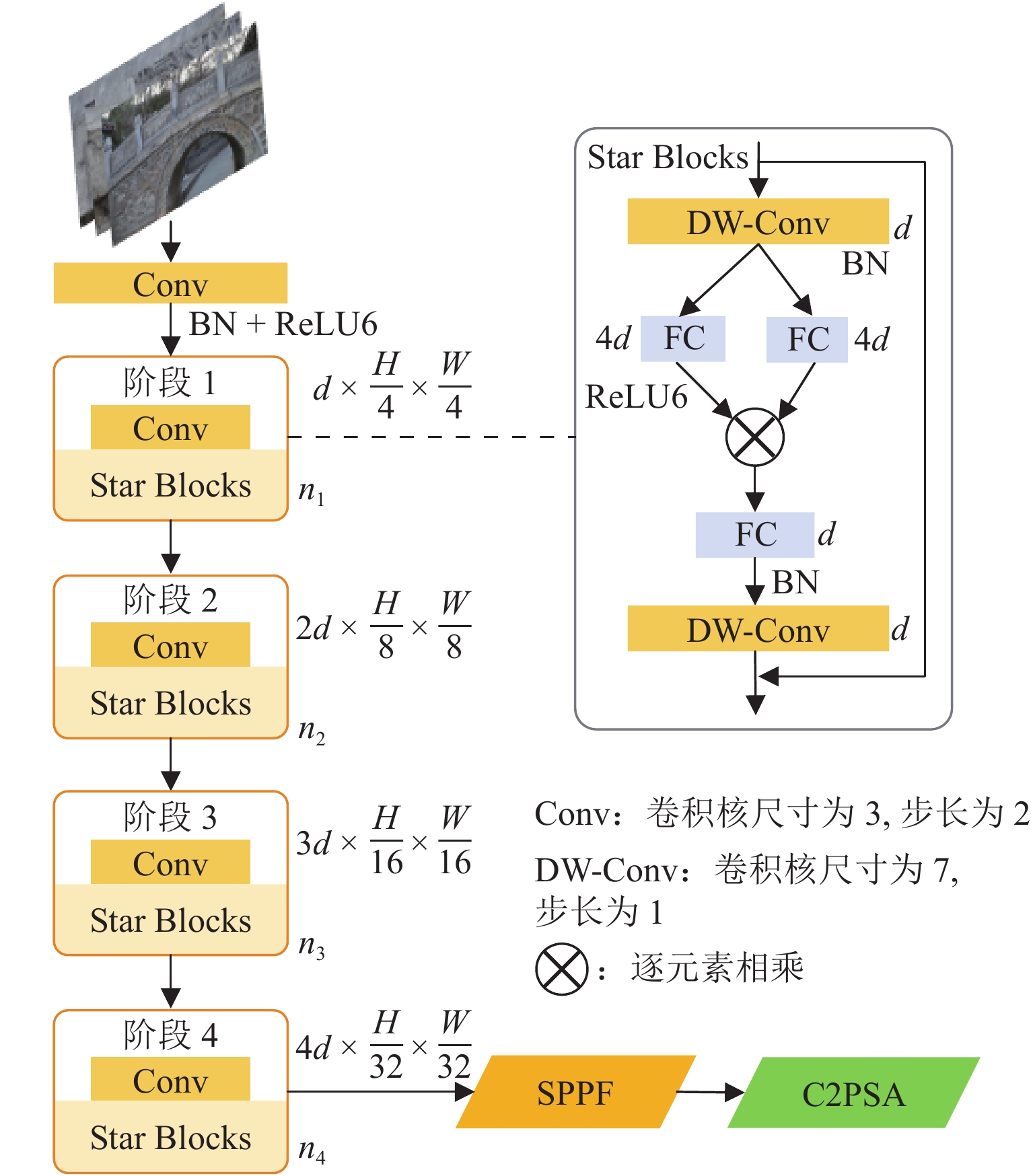
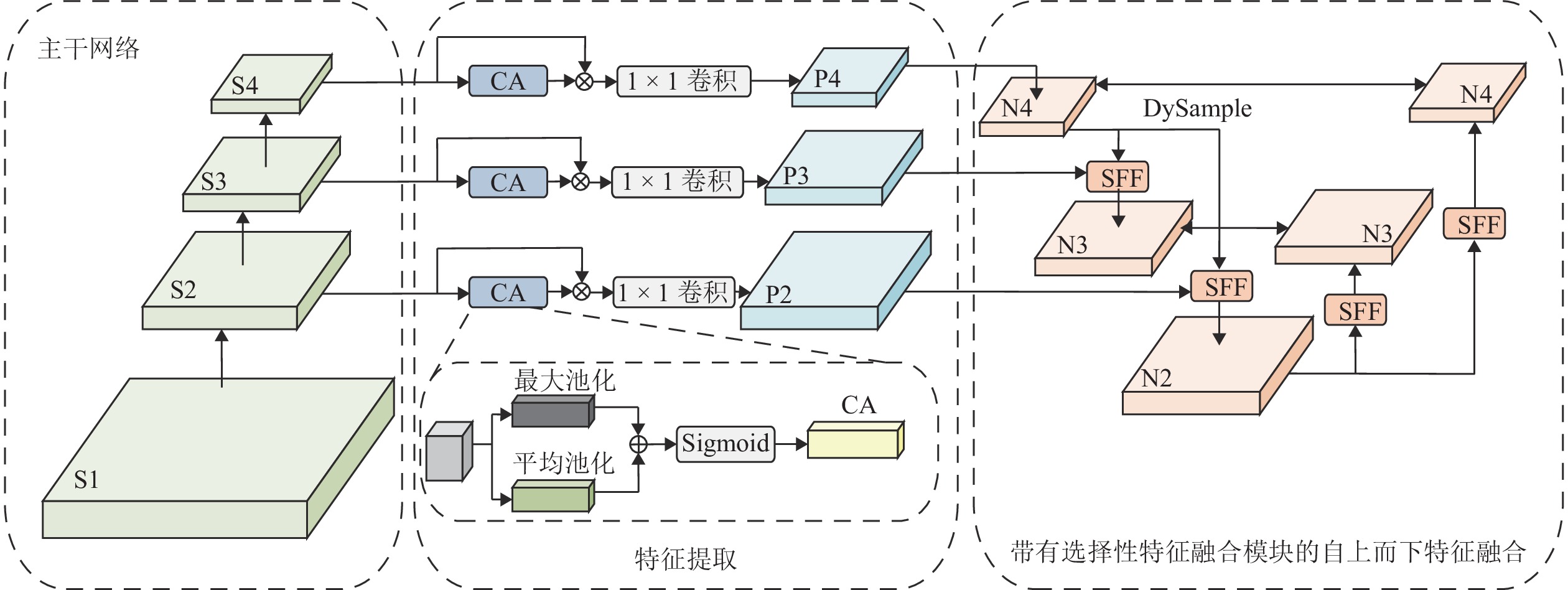
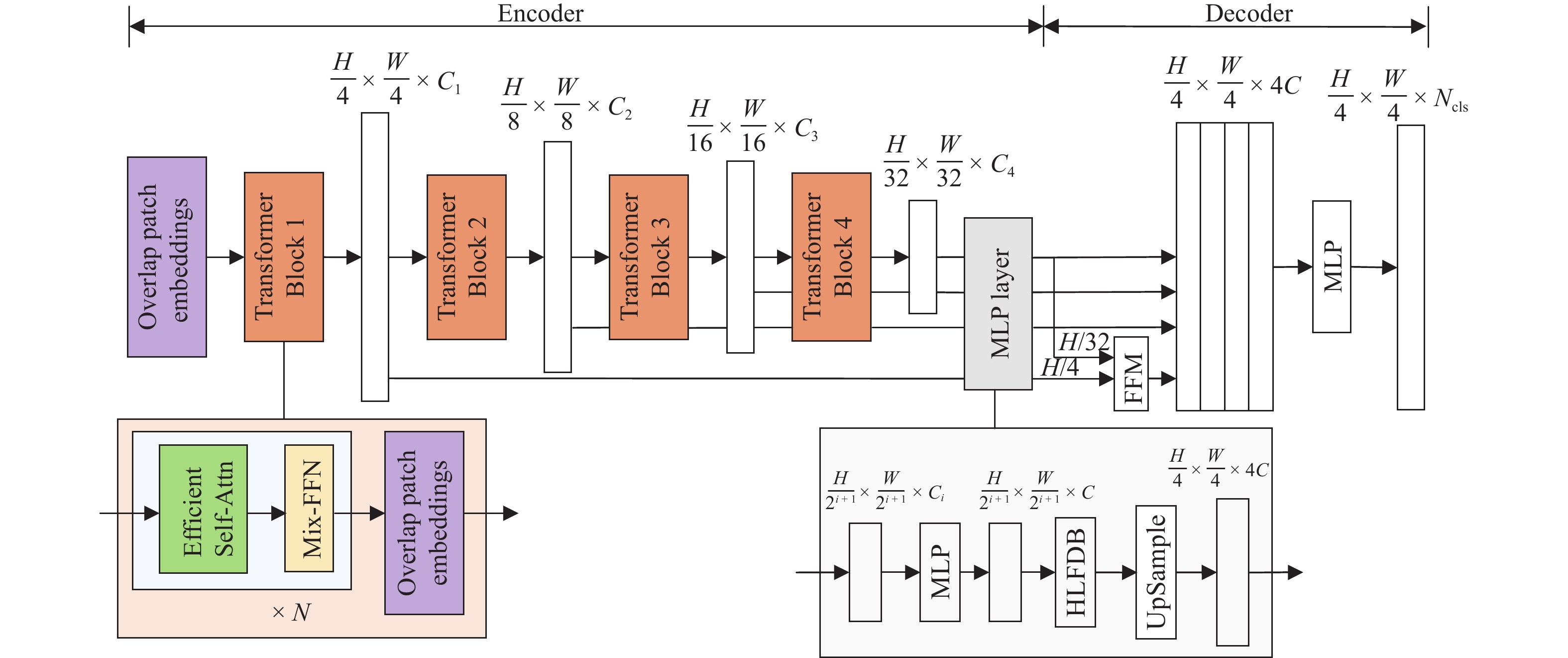
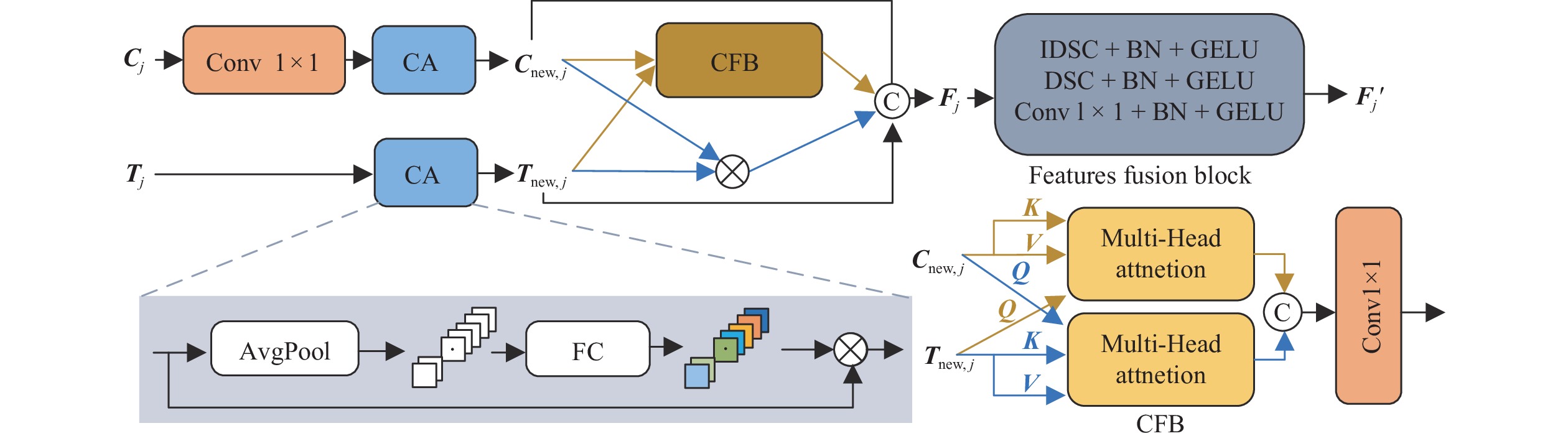
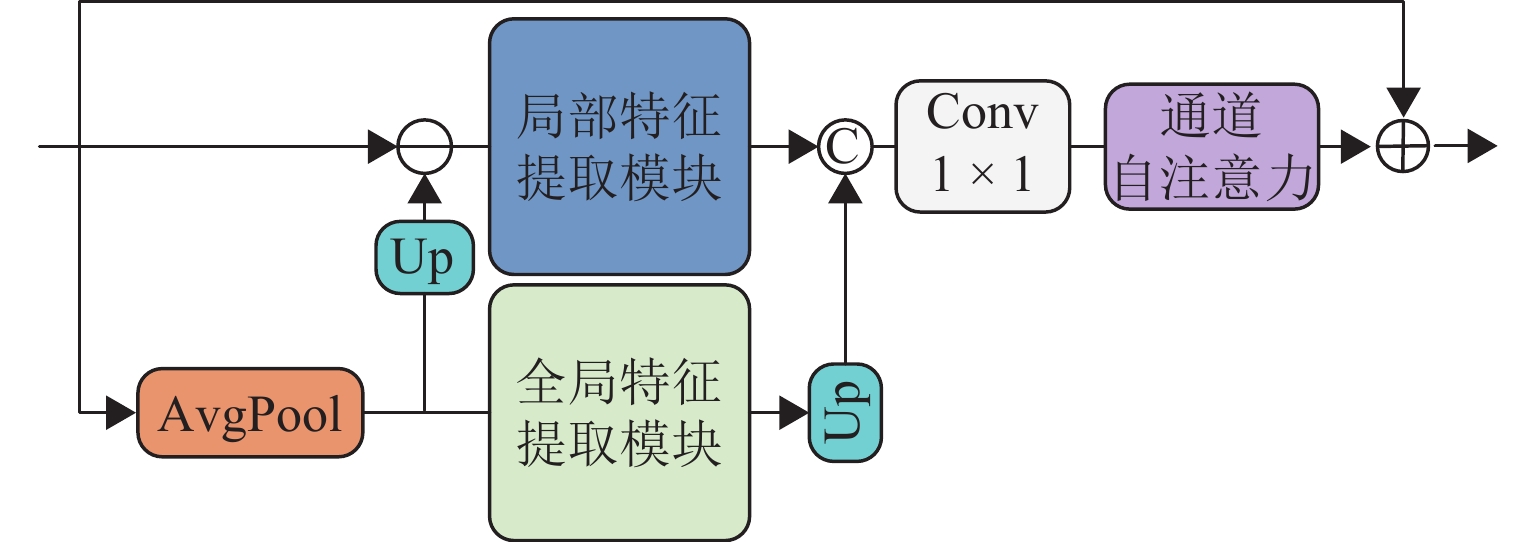
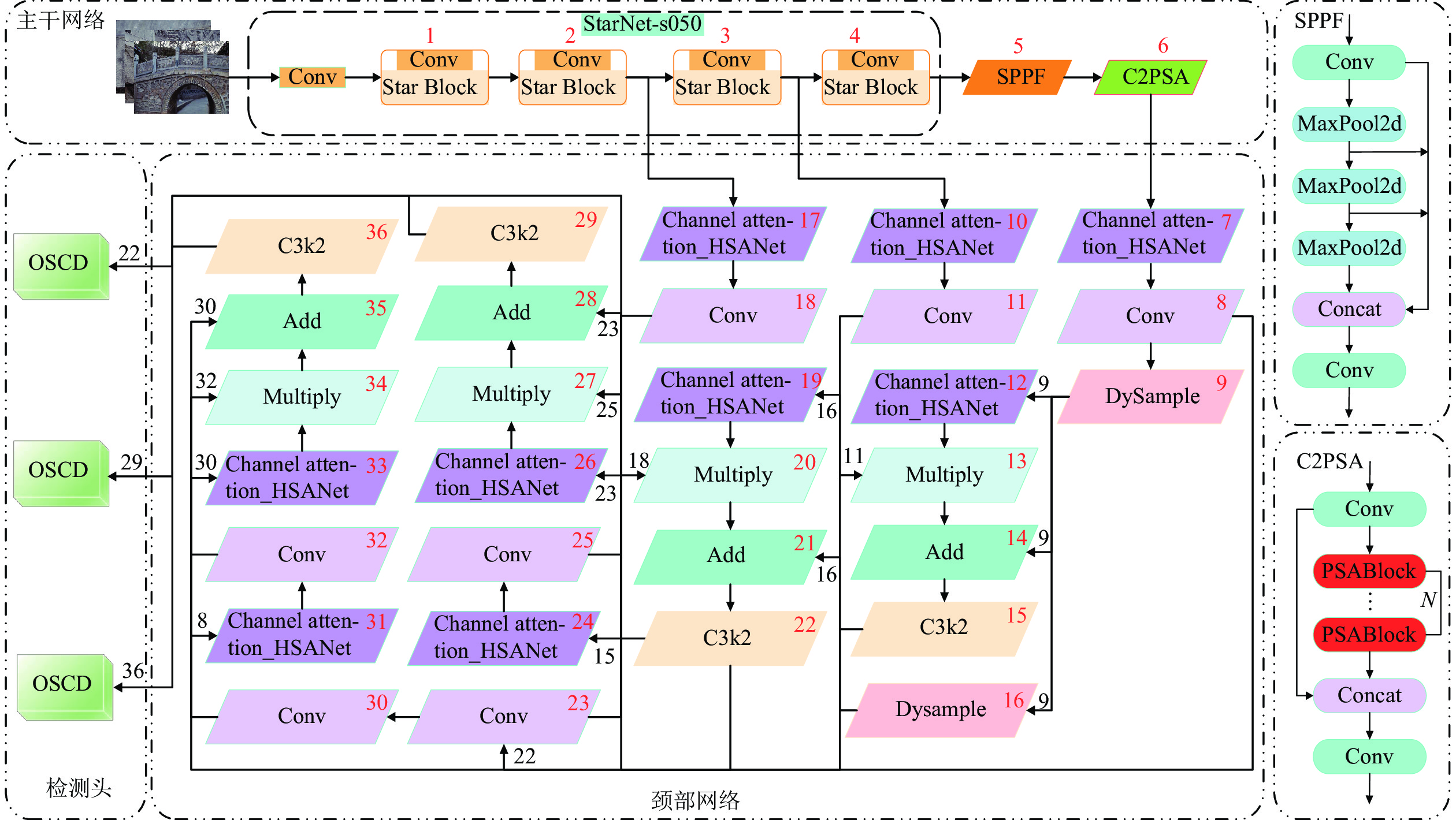
为提升古桥裂缝检测的精度与效率,解决传统传感器检测方法易导致信息缺失及二次损伤的问题,提出一种基于改进YOLO11与SegFormer的裂缝识别与测量方法. 首先,针对YOLO11模型参数量大、推理速度受限的缺陷,提出YOLO-CD (You Only Look Once-Crack Detect)目标检测模型:通过StarNet轻量化主干网络降低计算成本,结合HSANet颈部网络增强裂缝边缘细节保留能力,并设计优化空间上下文(OSCD)检测头优化多尺度检测效率;其次,提出改进的SegFormer-HF语义分割模型,通过特征融合模块(FFM)与高低频分解块(HLFDB)抑制下采样信息丢失,提升裂缝分割的语义一致性;最后,提出先检测后分割的联合方案,结合骨架线算法实现裂缝长度与宽度的自动化计算. 基于研究获取的古桥裂缝数据集进行实验,结果表明:YOLO-CD模型的F1分数、mAP50与mAP50-95分别为
0.678 、0.715 与0.464 ,浮点运算量(GFLOPs)较YOLO11降低了47.62%;SegFormer-HF的F1分数、mIoU与mPA分别为0.915 、0.852 与0.905,优于现有的主流模型. 研究证明了该方法在兼顾检测速度与精度的情况下,模型更小、检测效率更高,可适合部署于摄像头和无人机等移动设备.Abstract:To enhance the accuracy and efficiency of crack detection of ancient bridges and address the issues of information loss and secondary damage caused by traditional sensor detection methods, a crack identification and measurement method was proposed based on an improved You Only Look Once 11 (YOLO11) and SegFormer. First, to overcome the limitations of the YOLO11 model, including its large parameter size and restricted inference speed, the You Only Look Once-crack detect (YOLO-CD) object detection model was introduced. The StarNet lightweight backbone network was employed to reduce computational costs. The HSANet neck network was integrated to enhance the ability to preserve the crack edge detail, and an optimized spatial context detection (OSCD) head was designed to improve multi-scale detection efficiency. Second, an enhanced SegFormer-HF semantic segmentation model was proposed, which incorporated a feature fusion module (FFM) and a high-low frequency decomposition block (HLFDB) to mitigate information loss during sampling and improve semantic consistency in crack segmentation. Finally, a joint detection-segmentation framework was developed, combining a skeleton line algorithm to achieve automatic calculations of crack length and width. Based on the experiments conducted on the crack dataset of ancient bridges, the results have demonstrated that the YOLO-CD model achieves F1 score, mAP50, and mAP50-95 values of 0.678, 0.715, and 0.464, respectively, while reducing floating-point operations (GFLOPs) by 47.62% compared to YOLO11. The SegFormer-HF model achieves superior performance with F1-score, mIoU, and mPA of 0.915, 0.852, and 0.905, respectively, outperforming existing mainstream models. The results validate that the proposed method achieves higher efficiency and compact model size while balancing detection speed and accuracy, which is suitable for deployment on mobile devices such as cameras and drones.
-
Key words:
- ancient bridge /
- crack detection /
- deep learning /
- object detection /
- semantic segmentation
-
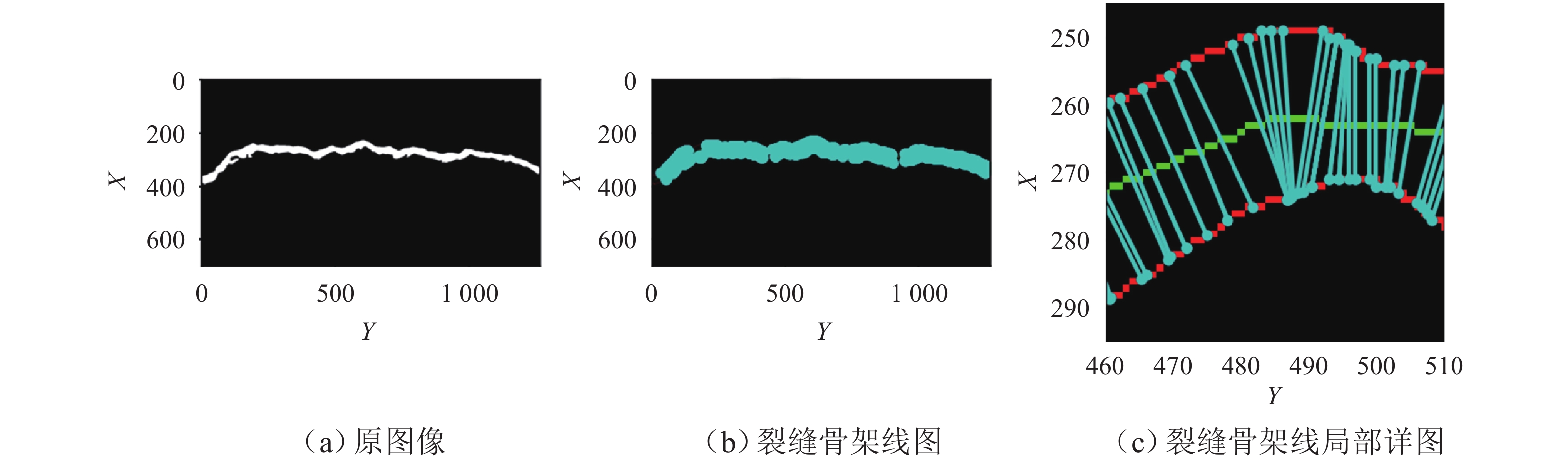
图 10 基于裂缝骨架线的裂缝特征计算示意
Figure 10. Crack feature calculation based on crack skeleton line
表 1 各数据集占比情况
Table 1. Percentage of datasets
% 数据集 自建 Crack500 Crack-seg crack-detect 72 10 18 crack-mask 59 16 25  下载: 导出CSV
下载: 导出CSV
表 2 消融实验结果
Table 2. Results of ablation experiments
模型 ZF1 ZmAP50 ZmAP50-95 ZGFLOPs YOLO11 0.644 0.686 0.446 6.3 Starnet 0.651 0.685 0.445 5.0 HSANet 0.660 0.687 0.444 5.3 OSCD 0.680 0.724 0.488 5.7 Starnet + HSANet 0.658 0.679 0.435 3.9 HSANet + OSCD 0.670 0.713 0.472 4.6 YOLO-CD 0.678 0.715 0.464 3.3
下载: 导出CSV
表 3 对比实验结果
Table 3. Comparative experimental results
模型 ZF1 ZmAP50 ZmAP50-95 ZGFLOPs YOLO11 0.644 0.686 0.446 6.3 YOLOv5 0.652 0.661 0.401 4.1 YOLOv8 0.638 0.667 0.434 8.1 YOLO-CD 0.678 0.715 0.464 3.3
下载: 导出CSV
表 4 基于SegFormer-B0的消融实验结果
Table 4. Results of ablation experiments based on SegFormer-B0
模型 ZmIou ZmPA ZF1 SegFormer_B0 0.840 0.895 0.905 FFM 0.848 0.900 0.912 HLFDB 0.846 0.898 0.911 SegFormer-HF 0.852 0.905 0.915
下载: 导出CSV
表 5 基于SegFormer-B0的对比实验结果
Table 5. Comparative experimental results based on SegFormer-B0
模型 ZmIou ZmPA ZF1 SegFormer_B0 0.841 0.895 0.905 DeepLabelv3+ 0.835 0.888 0.900 Unet 0.838 0.889 0.905 PSPnet 0.839 0.892 0.899 SegFormer-HF 0.852 0.905 0.915
下载: 导出CSV
表 6 模型泛化实验结果
Table 6. Experimental results of model generalization
数据集 YOLO-CD SegFormer-HF ZF1 ZmAP50 ZmAP50-95 ZGFLOPs ZmIOU ZmPA ZF1 crack-detect 0.661 0.705 0.455 3.3 0.842 0.898 0.907 deep-crack 0.654 0.696 0.448 3.3 0.840 0.894 0.901
下载: 导出CSV
表 7 裂缝长度与宽度计算结果
Table 7. Calculation results of length and width of cracks
编号 长度测量 宽度测量 像素长
度/像素实际长度/mm 人工测量/mm 绝对误差/mm 相对误差/% 像素宽
度/像素实际宽度/mm 人工测量/mm 绝对误差/mm 相对误差/% ① 1892.73 327.82 317.50 10.32 3.25 129.10 22.36 21.50 0.86 4.00 ② 4322.11 748.59 766.75 18.16 2.37 14.03 2.43 2.25 0.18 8.00 ③ 3484.76 603.56 612.80 9.24 1.51 155.49 26.93 26.35 0.58 2.20 ④ 3658.84 633.71 653.40 19.69 3.01 82.91 14.36 13.75 0.21 4.44 注:尺度因子为 0.1732 .
下载: 导出CSV
-
[1] 韩晓健, 赵志成. 基于计算机视觉技术的结构表面裂缝检测方法研究[J]. 建筑结构学报, 2018, 39(增1): 418-427.HAN Xiaojian, ZHAO Zhicheng. Structural surface crack detection method based on computer vision technology[J]. Journal of Building Structures, 2018, 39(S1): 418-427. [2] 谢明志, 樊丁萌, 蒋志鹏, 等. 基于计算机视觉的混凝土结构裂缝检测研究现状与展望[J/OL]. 西南交通大学学报, 1-20[2025-08-17]. https://link.cnki.net/urlid/51.1277.u.20240913.1853.002. [3] 杨国俊, 齐亚辉, 石秀名. 基于数字图像技术的桥梁裂缝检测综述[J]. 吉林大学学报(工学版), 2024, 54(2): 313-332.YANG Guojun, QI Yahui, SHI Xiuming. Review of bridge crack detection based on digital image technology[J]. Journal of Jilin University (Engineering and Technology Edition), 2024, 54(2): 313-332. [4] 唐钱龙, 谭园, 彭立敏, 等. 基于数字图像技术的隧道衬砌裂缝识别方法研究[J]. 铁道科学与工程学报, 2019, 16(12): 3041-3049.TANG Qianlong, TAN Yuan, PENG Limin, et al. On crack identification method for tunnel linings based on digital image technology[J]. Journal of Railway Science and Engineering, 2019, 16(12): 3041-3049. [5] 刘宇飞, 樊健生, 聂建国, 等. 结构表面裂缝数字图像法识别研究综述与前景展望[J]. 土木工程学报, 2021, 54(6): 79-98.LIU Yufei, FAN Jiansheng, NIE Jianguo, et al. Review and prospect of digital-image-based crack detection of structure surface[J]. China Civil Engineering Journal, 2021, 54(6): 79-98. [6] 杨军, 高志明, 李金泰, 等. 基于注意力机制的三维点云模型对应关系计算[J]. 西南交通大学学报, 2024, 59(5): 1184-1193.YANG Jun, GAO Zhiming, LI Jintai, et al. Correspondence calculation of three-dimensional point cloud model based on attention mechanism[J]. Journal of Southwest Jiaotong University, 2024, 59(5): 1184-1193. [7] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. doi: 10.1109/TPAMI.2016.2577031 [8] 周中, 闫龙宾, 张俊杰, 等. 基于YOLOX-G算法的隧道裂缝实时检测[J]. 铁道科学与工程学报, 2023, 20(7): 2751-2762.ZHOU Zhong, YAN Longbin, ZHANG Junjie, et al. Real-time detection of tunnel cracks based on YOLOX-G algorithm[J]. Journal of Railway Science and Engineering, 2023, 20(7): 2751-2762. [9] CHEN L C, ZHU Y K, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Computer Vision–ECCV 2018. Cham: Springer, 2018: 833-851. [10] 王青原, 许颖, 钱胜. 基于机器视觉和数字图像相关技术的混凝土损伤演化研究[J]. 湖南大学学报(自然科学版), 2023, 50(11): 169-180.WANG Qingyuan, XU Ying, QIAN Sheng. Study on damage evolution of concrete specimens based on machine vision and digital image correlation technology[J]. Journal of Hunan University (Natural Sciences), 2023, 50(11): 169-180. [11] 王耀东, 朱力强, 余祖俊, 等. 基于样本自动标注的隧道裂缝病害智能识别[J]. 西南交通大学学报, 2023, 58(5): 1001-1008, 1036.WANG Yaodong, ZHU Liqiang, YU Zujun, et al. Intelligent tunnel crack recognition based on automatic sample labeling[J]. Journal of Southwest Jiaotong University, 2023, 58(5): 1001-1008, 1036. [12] NISHIYAMA S, MINAKATA N, KIKUCHI T, et al. Improved digital photogrammetry technique for crack monitoring[J]. Advanced Engineering Informatics, 2015, 29(4): 851-858. doi: 10.1016/j.aei.2015.05.005 [13] LI Z, ZHANG T, MIAO Y, et al. Automated quantification of crack length and width in asphalt pavements[J]. Computer-Aided Civil and Infrastructure Engineering, 2024, 39(21): 3317-3336. doi: 10.1111/mice.13344 [14] 周颖, 刘彤. 基于计算机视觉的混凝土裂缝识别[J]. 同济大学学报(自然科学版), 2019, 47(9): 1277-1285.ZHOU Ying, LIU Tong. Computer vision-based crack detection and measurement on concrete structure[J]. Journal of Tongji University (Natural Science), 2019, 47(9): 1277-1285. [15] 陈善继, 刘天禹, 刘鹏宇, 等. 基于计算机视觉的公路边坡裂缝监测方法[J]. 北京工业大学学报, 2024, 50(6): 702-710.CHEN Shanji, LIU Tianyu, LIU Pengyu, et al. Computer vision-based method for monitoring road slope cracks[J]. Journal of Beijing University of Technology, 2024, 50(6): 702-710. [16] 王卫东, 吴铮, 邱实, 等. 基于多目标级联深度学习的无砟轨道板表面裂缝测量[J]. 铁道科学与工程学报, 2023, 20(9): 3592-3603.WANG Weidong, WU Zheng, QIU Shi, et al. Multi-objective cascade deep learning based crack measurement for ballastless track slab[J]. Journal of Railway Science and Engineering, 2023, 20(9): 3592-3603. [17] KHANAM R, HUSSAIN M. Yolov11: an overview of the key architectural enhancements[EB/OL]. (2023-10-23)[2025-07-12]. https://arxiv.org/abs/2410.17725. [18] VARGHESE R, M S. YOLOv8: a novel object detection algorithm with enhanced performance and robustness[C]//2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS). Chennai: IEEE, 2024. [19] CHILD R, GRAY S, RADFORD A, et al. Generating long sequences with sparse transformers[EB/OL]. (2019-02-23)[2025-07-12]. https://arxiv.org/abs/1904.10509. [20] XIE E, WANG W, YU Z, et al. Segformer: simple and efficient design for semantic segmentation with transformers[J]. Advances in neural information processing systems, 2021, 34: 12077-12090. [21] MA X, DAI X Y, BAI Y, et al. Rewrite the stars[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle: IEEE, 2024: 5694-5703. [22] TIAN Z, SHEN C H, CHEN H, et al. FCOS: a simple and strong anchor-free object detector[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(4): 1922-1933. [23] ZHANG J M, ZENG Z G, SHARMA P K, et al. A dual encoder crack segmentation network with Haar wavelet—based high–low frequency attention[J]. Expert Systems with Applications, 2024, 256: 124950. doi: 10.1016/j.eswa.2024.124950 [24] CHEN G G, DAI K X, YANG K Z, et al. Bracketing image restoration and enhancement with high—low frequency decomposition[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Seattle: IEEE, 2024: 6097-6107. [25] DONG J X, PAN J S, YANG Z B, et al. Multi-scale residual low-pass filter network for image deblurring[C]//2023 IEEE/CVF International Conference on Computer Vision (ICCV). Paris: IEEE, 2023: 12311-12320. [26] AI D H, JIANG G Y, KEI L S, et al. Automatic pixel-level pavement crack detection using information of multi-scale neighborhoods[J]. IEEE Access, 2018, 6: 24452-24463. doi: 10.1109/ACCESS.2018.2829347 [27] ZHANG L, YANG F, ZHANG Y D, et al. Road crack detection using deep convolutional neural network[C]//2016 IEEE International Conference on Image Processing (ICIP). Phoenix: IEEE, 2016: 3708-3712. [28] 李林超, 钟良剑, 苏庆, 等. 基于多源数据融合的城市土地利用精细识别方法[J]. 西南交通大学学报, 2025, 60(2): 326-335.LI Linchao, ZHONG Liangjian, SU Qing, et al. Fine urban land use identification based on fusion of multi-source data[J]. Journal of Southwest Jiaotong University, 2025, 60(2): 326-335. [29] 李恒超, 刘香莲, 刘鹏, 等. 基于多尺度感知的密集人群计数网络[J]. 西南交通大学学报, 2024, 59(5): 1176-1183, 1214.LI Hengchao, LIU Xianglian, LIU Peng, et al. Dense crowd counting network based on multi-scale perception[J]. Journal of Southwest Jiaotong University, 2024, 59(5): 1176-1183, 1214. -

 下载:
下载:





 点击查看大图
点击查看大图
计量
- 文章访问数: 389
- HTML全文浏览量: 428
- PDF下载量: 89
- 被引次数: 0