

Influence Analysis of Vibration Control Parameters for High-Speed Maglev Train-Bridge Coupling
-
摘要:
磁浮列车悬浮系统控制参数取值不当可能导致车-桥系统异常振动. 因此,明确悬浮系统控制参数与磁浮车-桥系统动力响应之间的关系十分重要. 首先,建立包含比例-微分控制的5节编组磁浮列车动力学模型和20跨简支梁桥有限元模型;其次,与实测结果进行对比验证所建立模型的正确性;最后,计算车速430 km/h时不同控制参数下列车和桥梁的动力响应. 结果表明:增大比例系数会使悬浮和导向系统刚度增大,增大微分系数会使悬浮和导向系统阻尼增大;车体竖向加速度随比例和微分系数的增大而增大,车体横向加速度随比例系数的增大而增大;悬浮间隙和桥梁竖向加速度均随比例系数的增大而减小,随微分系数的增大而增大;导向间隙随微分系数的增大而减小,比例系数对导向间隙的影响较小;桥梁横向加速度随比例系数的增大而减小,随微分系数的增大而增大;桥梁竖向加速度主要受电磁力中悬浮电磁铁长度特征频率1倍~12倍频的影响,桥梁横向加速度主要受导向磁极长度特征频率及其2倍频和导向电磁铁长度特征频率2倍频及4倍频的影响;为减小车-桥系统动力响应,综合建议竖向比例和微分系数的取值范围分别为3000~4000和10~25,横向比例和微分系数的取值范围分别为4000~5000和10~25.
Abstract:Improper control parameters of the suspension system of maglev trains may lead to abnormal vibration of the train-bridge system. Therefore, it is important to clarify the relationship between the control parameters of the suspension system and the dynamic response of the maglev train-bridge system. Firstly, the dynamic model of a 5-car maglev train with proportional-differential control, as well as the finite element model of a 20-span simply supported beam bridge was established. Secondly, the correctness of the models was verified by comparing them with the measured results. Finally, the dynamic responses of the train and bridge under different control parameters at 430 km/h were calculated. The results show that increasing the proportional coefficient will increase the stiffness of the suspension and guidance system, and increasing the differential coefficient will increase the damping of the suspension and guidance system. The vertical acceleration of the car body increases with the increase in the proportional and differential coefficients, and the lateral acceleration of the car body increases with the increase in the proportional coefficient. The suspension gap and the vertical acceleration of the bridge decrease with the increase in the proportional coefficient, and they increase with the increase in the differential coefficient. The guidance gap decreases with the increase in the differential coefficient, and the proportional coefficient has little effect on the guidance gap. The lateral acceleration of the bridge decreases with the increase in the proportional coefficient and increases with the increase in the differential coefficient. The vertical acceleration of the bridge is mainly affected by a characteristic frequency of 1–12 times of the length of the suspended electromagnet in the electromagnetic force, and the lateral acceleration of the bridge is mainly affected by the characteristic frequency and frequency of 2 times of the length of the guidance pole, as well as the characteristic frequency of 2 times and 4 times of the length of the guidance electromagnet. In order to reduce the dynamic response of the train-bridge system, it is suggested that the values of vertical proportional and differential coefficients should be 3 000–4 000 and 10–25, respectively, and the values of lateral proportional and differential coefficients should be 4 000–5 000 and 10–25, respectively.
-

图 5 不同控制参数下车体竖向加速度最大值
Figure 5. Maximum values of vertical acceleration of car body under different control parameters
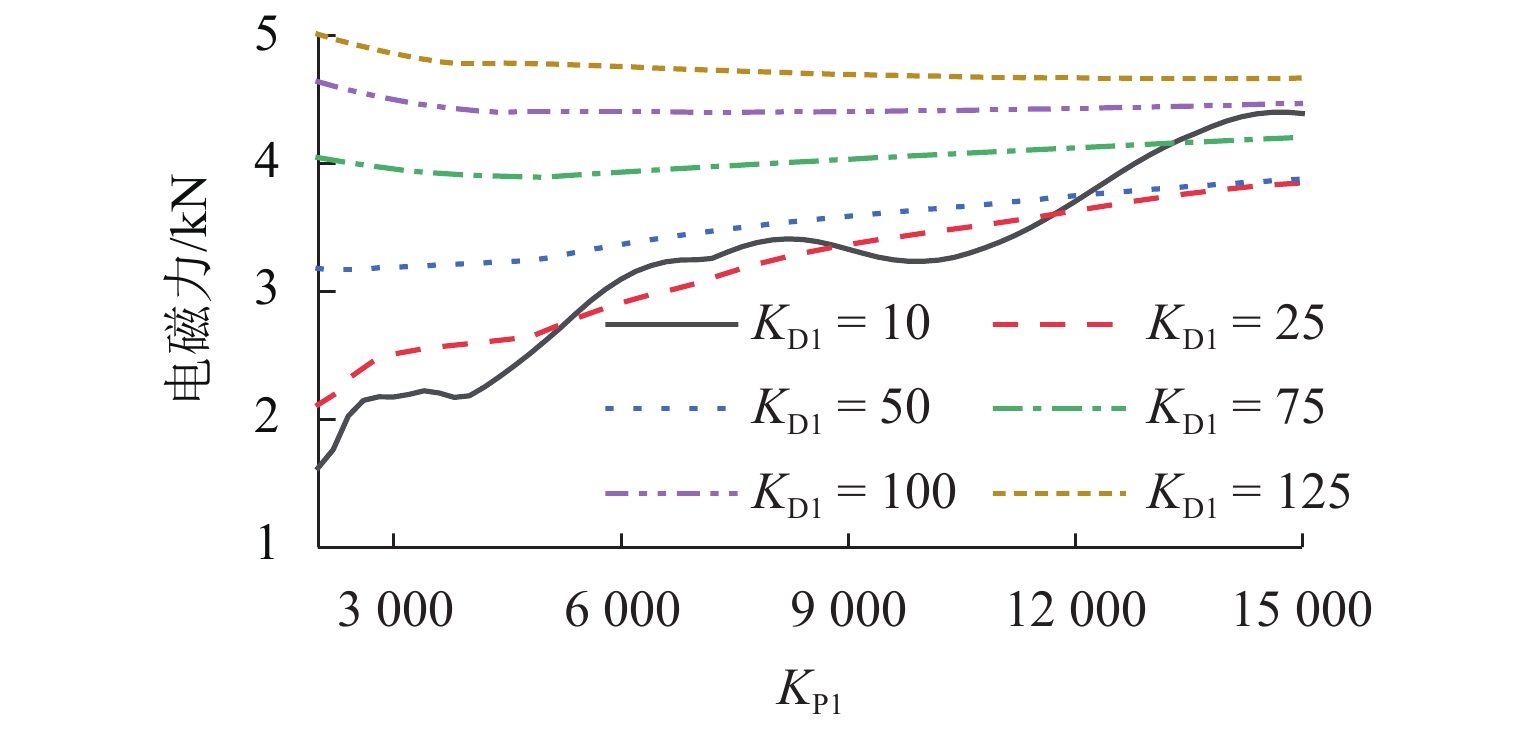
图 6 不同控制参数下悬浮电磁力最大值
Figure 6. Maximum values of suspended electromagnetic force under different control parameters
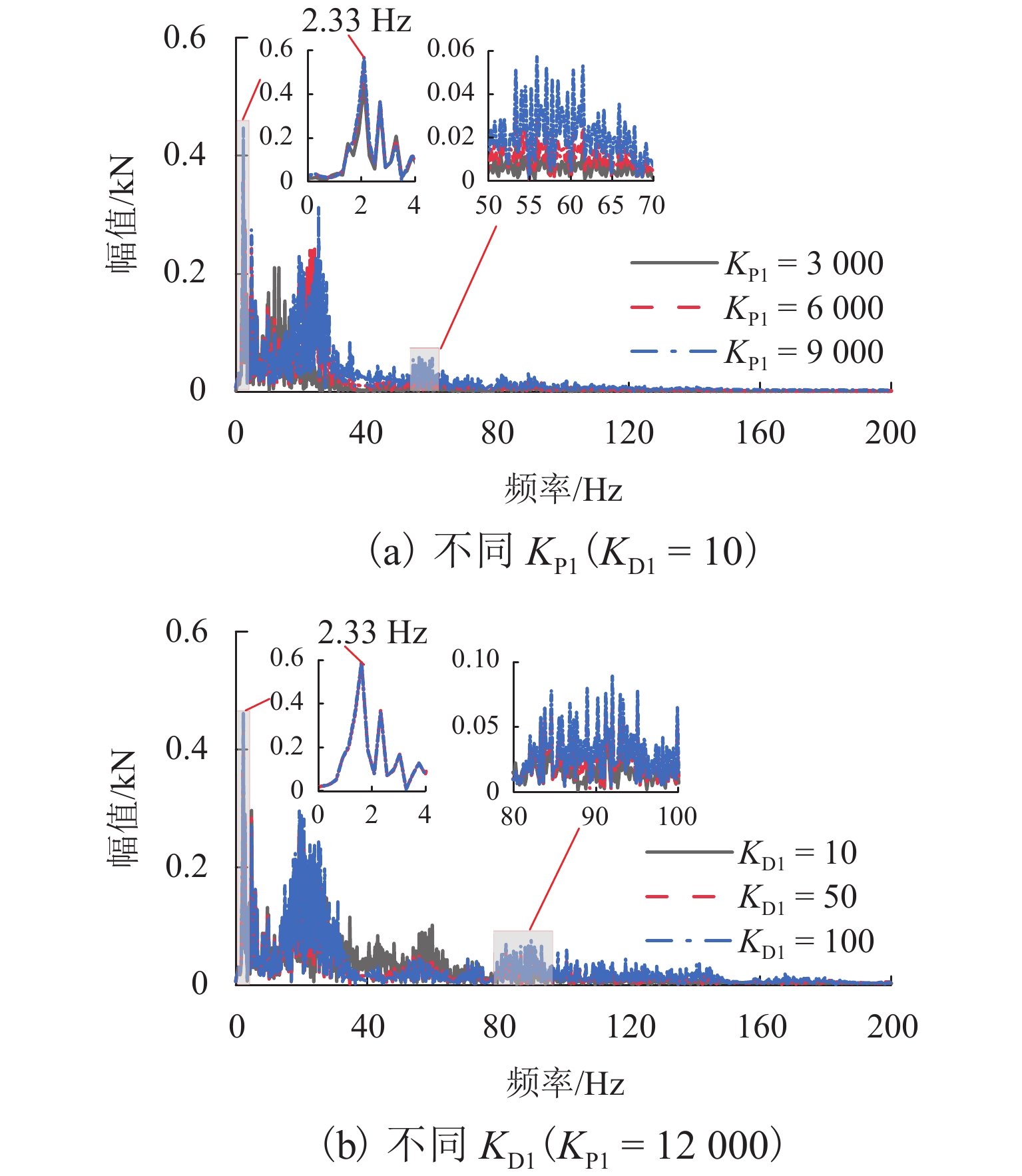
图 7 不同控制参数下悬浮电磁力幅值谱
Figure 7. Amplitude spectrum of suspended electromagnetic force under different control parameters
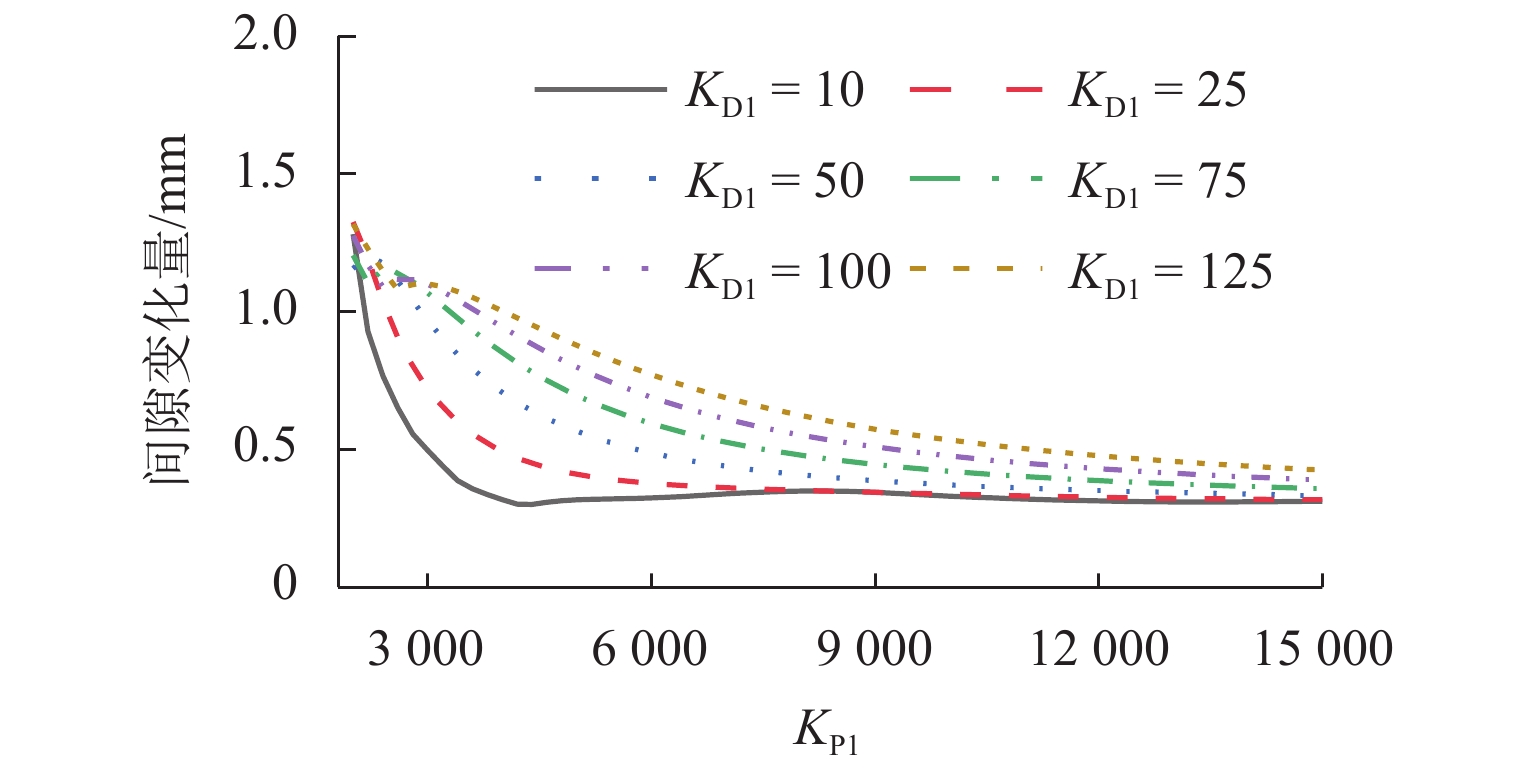
图 8 不同控制参数下中间悬浮磁极间隙变化量
Figure 8. Variation of intermediate suspended pole gap under different control parameters
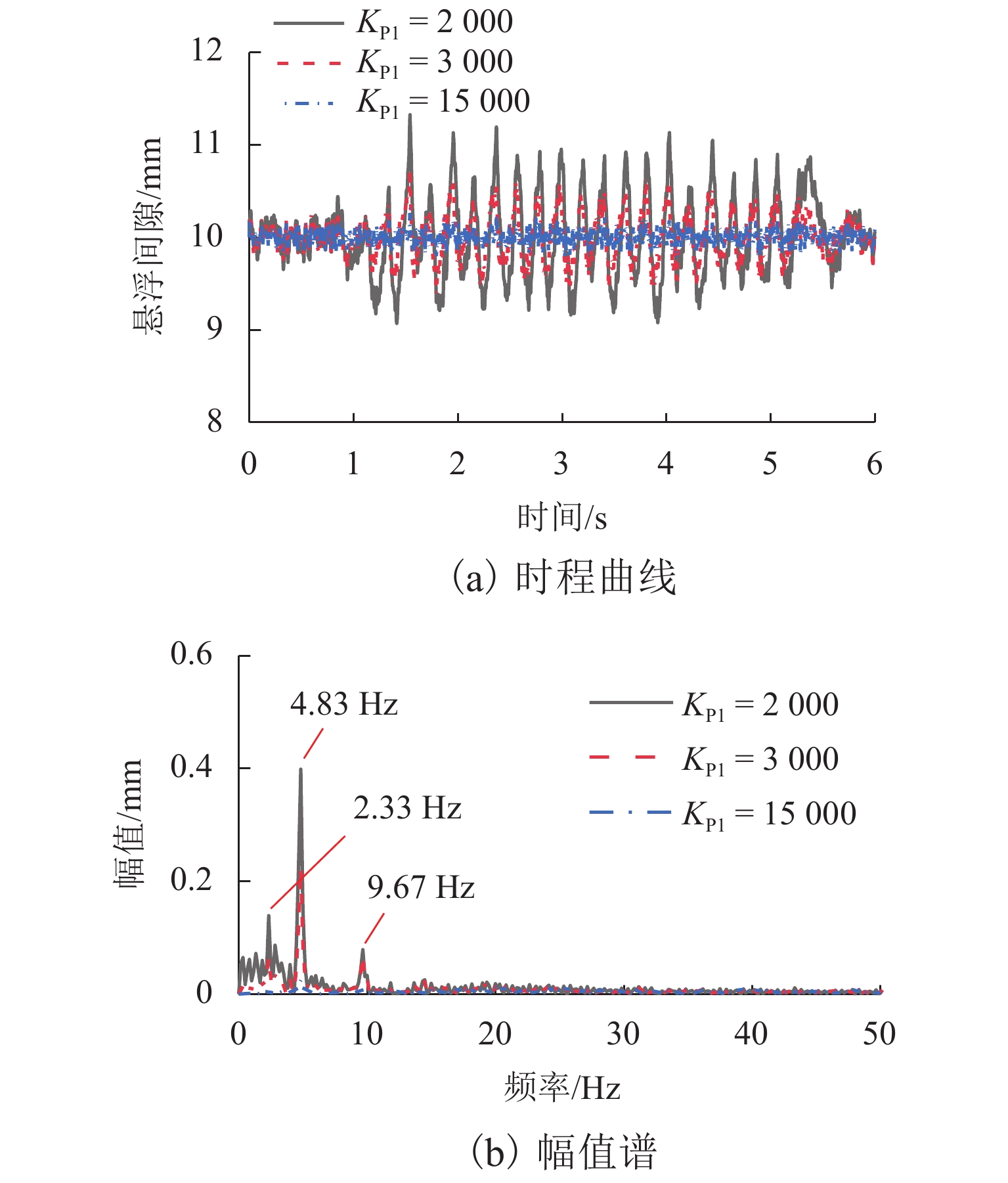
图 9 不同控制参数下悬浮间隙时程曲线及其幅值谱(KD1=25)
Figure 9. Suspension gap time history curve and amplitude spectrum under different control parameters (KD1 = 25)
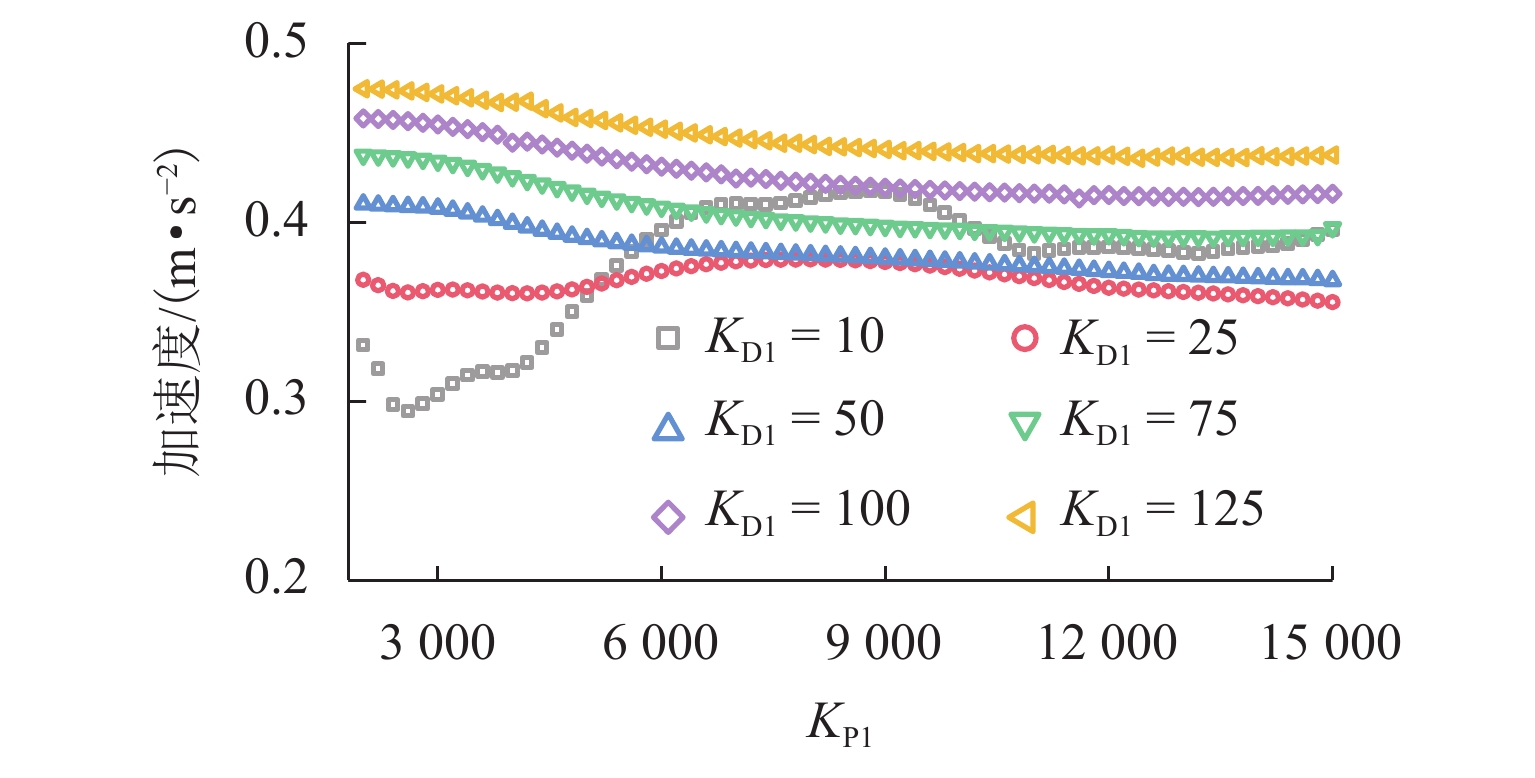
图 10 不同控制参数下主梁跨中竖向加速度最大值
Figure 10. Maximum values of vertical acceleration at midspan of girder under different control parameters
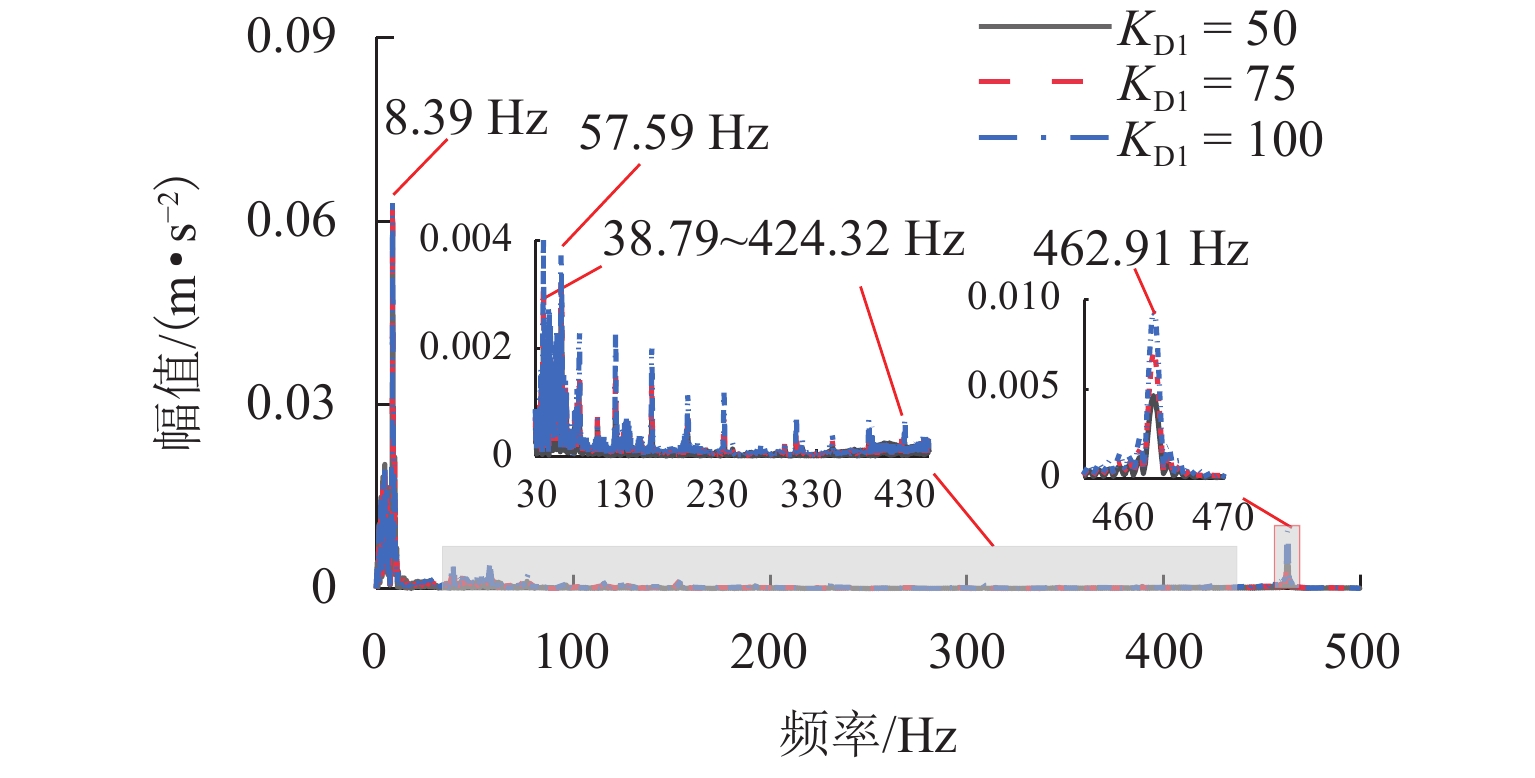
图 11 不同KD1下主梁跨中竖向加速度幅值谱(KP1=6000)
Figure 11. Amplitude spectrum of vertical acceleration at midspan of girder under different KD1 (KP1 = 6 000)
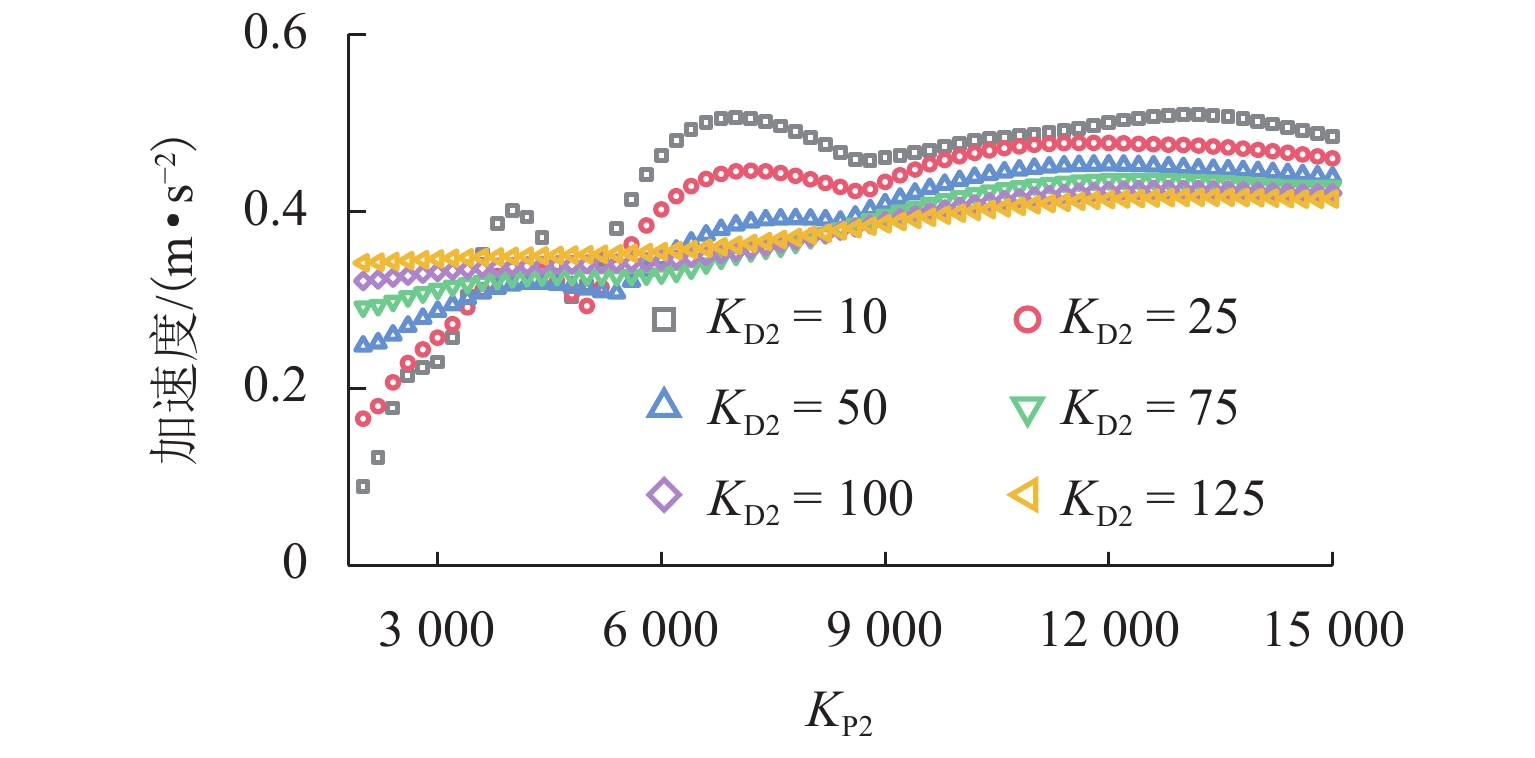
图 12 不同控制参数下车体横向加速度最大值
Figure 12. Maximum values of lateral acceleration of car body under different control parameters
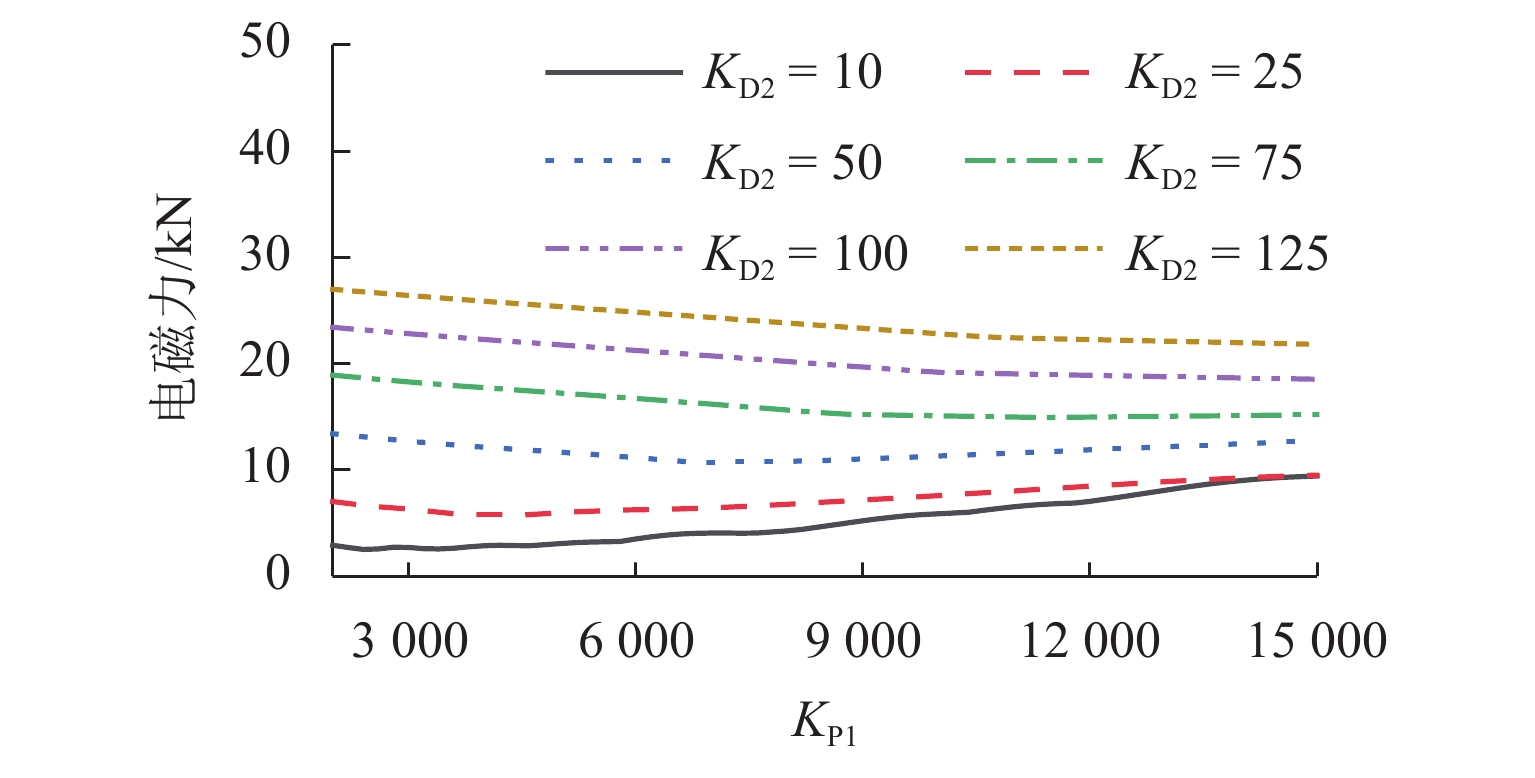
图 13 不同控制参数下导向电磁力最大值
Figure 13. Maximum values of guidance electromagnetic force under different control parameters
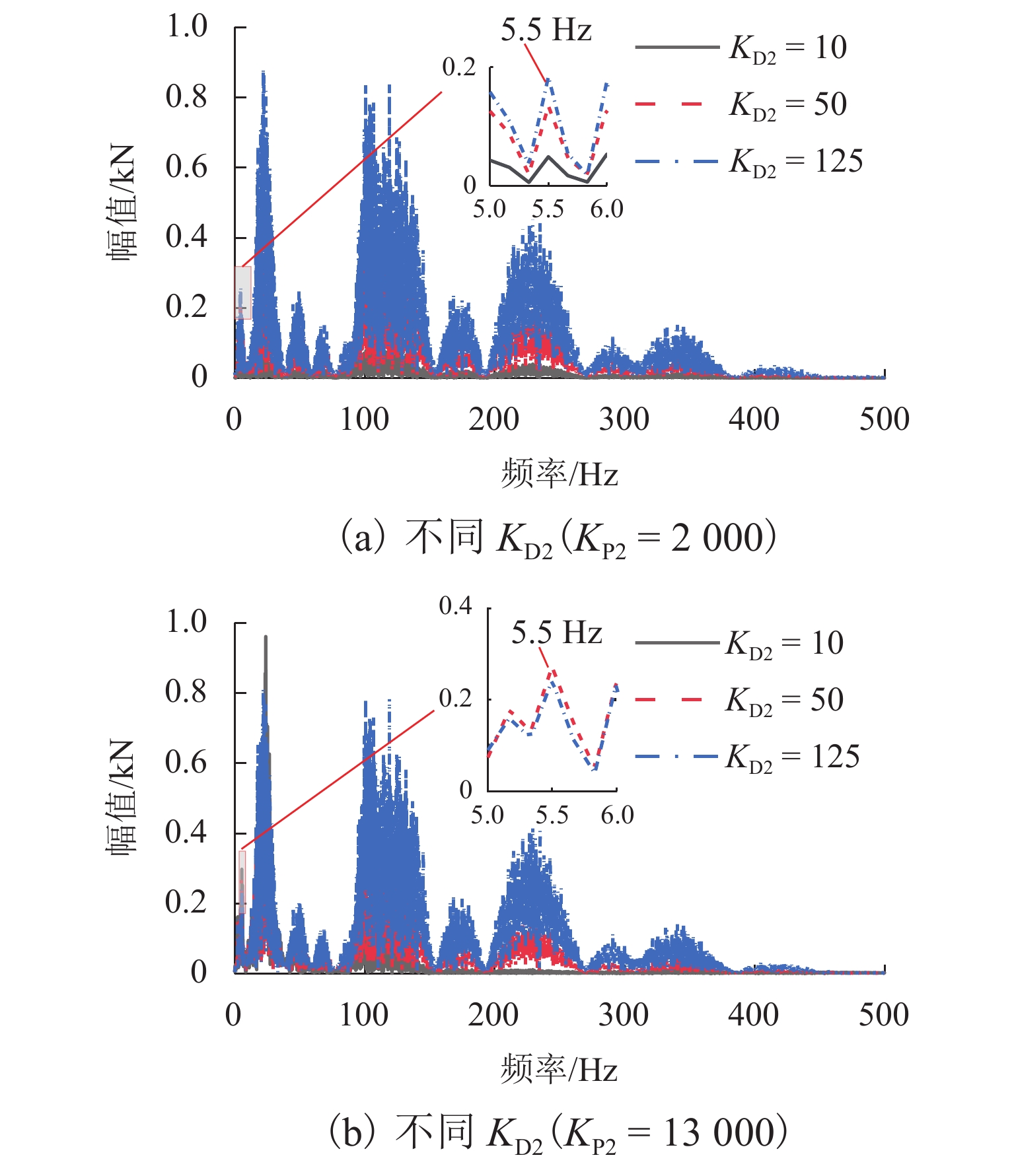
图 14 不同控制参数下导向电磁力幅值谱
Figure 14. Amplitude spectrum of guidance electromagnetic force under control parameters
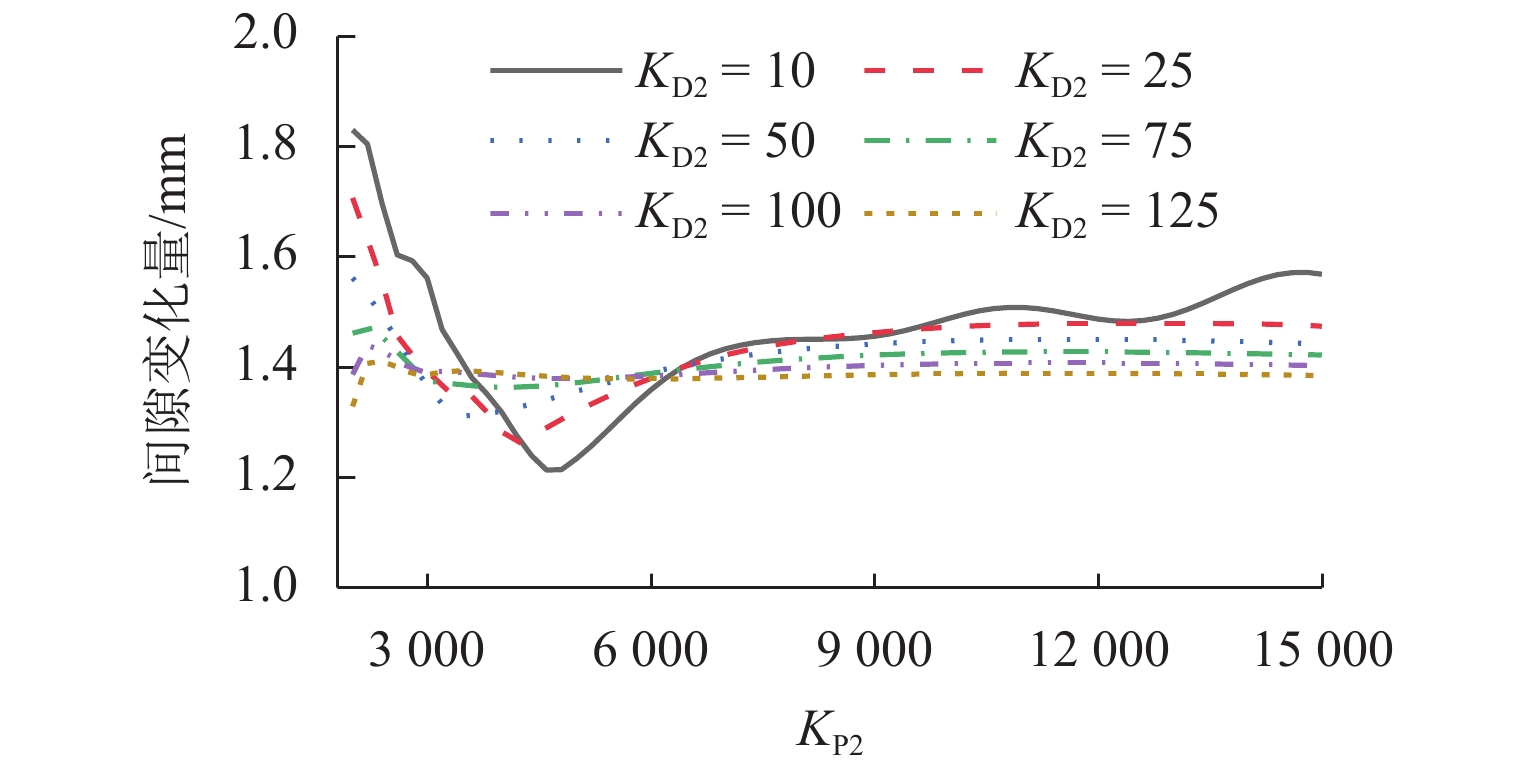
图 15 不同控制参数下中间导向磁极间隙变化量
Figure 15. Variation of intermediate guidance pole gap under different control parameters
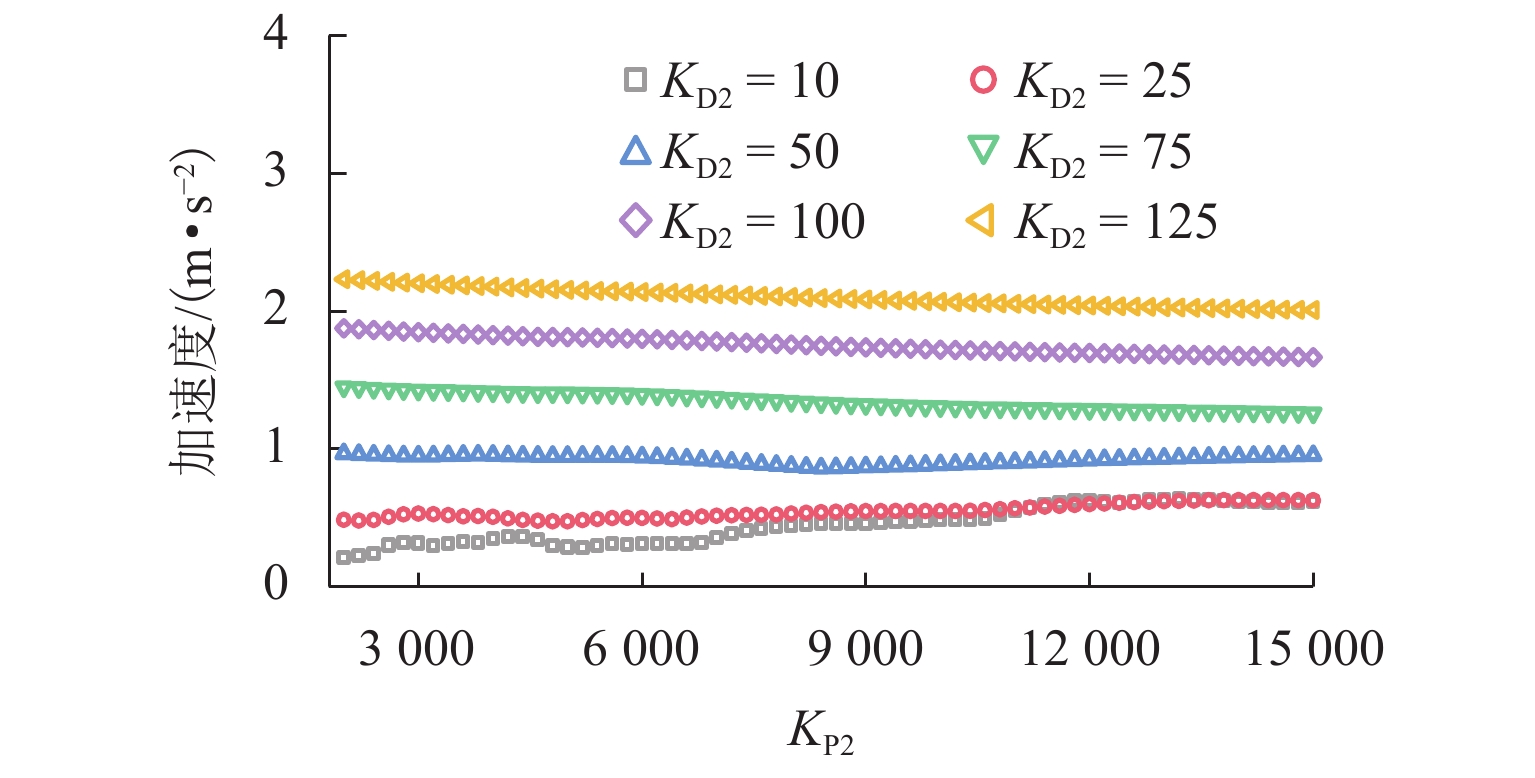
图 16 不同控制参数下主梁跨中横向加速度最大值
Figure 16. Maximum values of lateral acceleration at midspan of girder under different control parameters
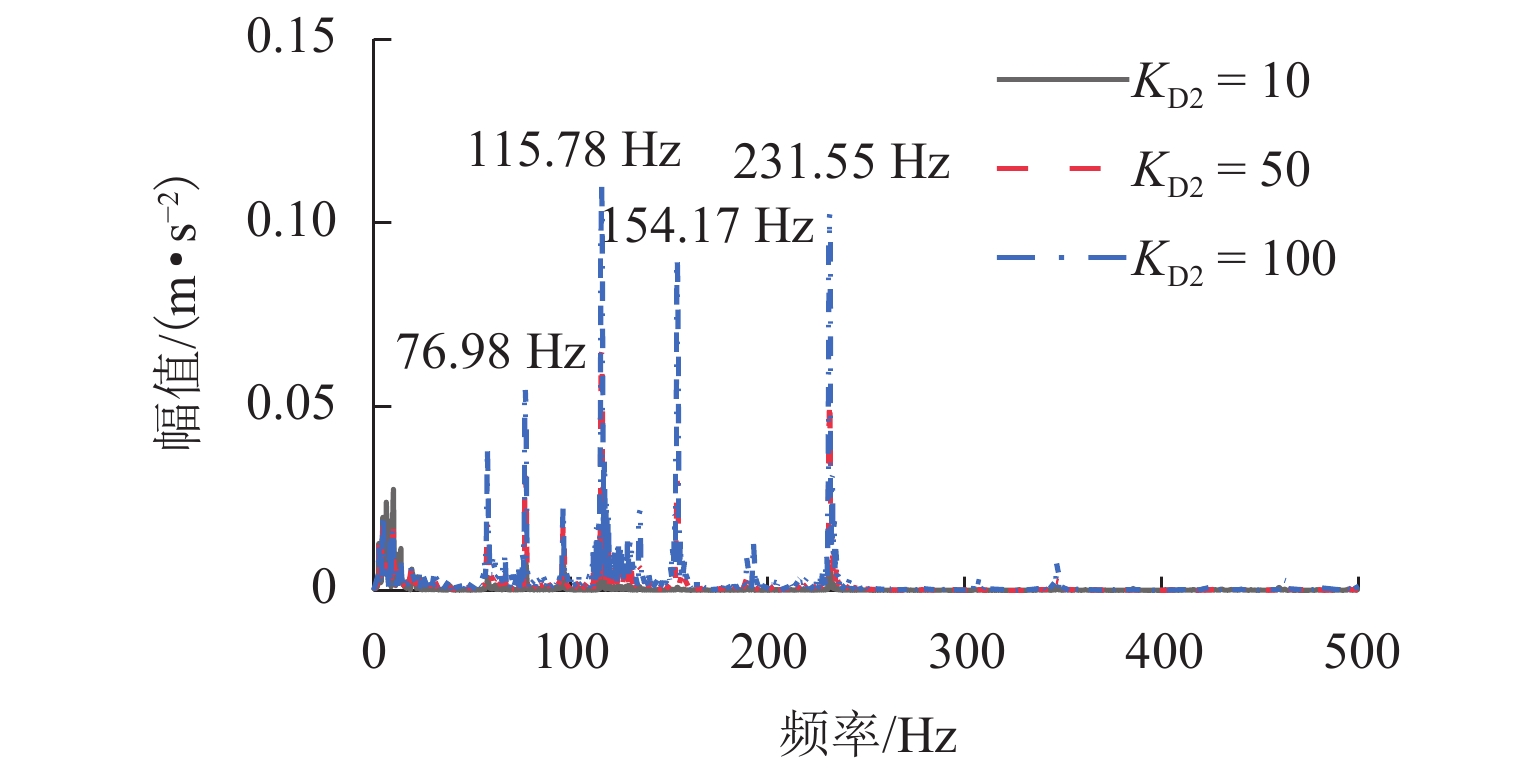
图 17 不同KD2下主梁跨中横向加速度幅值谱(KP2=6000)
Figure 17. Amplitude spectrum of lateral acceleration at midspan of girder under different KD2 (KP2 = 6 000)
表 1 车辆模型参数
Table 1. Parameters of train model
参数 数值 车体质量/(× 104 kg) 3.90 车体侧滚质量惯性矩/(× 104 kg•m2) 6.46 车体摇头质量惯性矩/(× 104 kg•m2) 1.75 车体点头质量惯性矩/(× 104 kg•m2) 1.76 一系/二系弹簧竖向刚度/(×106 N•m−1) 20/2 一系/二系弹簧竖向阻尼/(×103 N•s•m−1) 5/5 一系/二系弹簧横向刚度/(×106 N•m−1) 28/2 一系/二系弹簧横向阻尼/(×102 N•s•m−1) 5/20 空气弹簧刚度竖向/(× 106 N•m−1) 1.90  下载: 导出CSV
下载: 导出CSV
表 2 桥梁模型参数
Table 2. Parameters of bridge model
参数 数值 主梁/钢轨/桥墩密度/(kg•m−3) 2551/7850/2500 主梁/钢轨/桥墩弹性模量/GPa 44.5/206.0/30.0 主梁/钢轨/桥墩泊松比 0.2/0.3/0.2
下载: 导出CSV
-
[1] SU X Y, XU Y L, YANG X F. Neural network adaptive sliding mode control without overestimation for a maglev system[J]. Mechanical Systems and Signal Processing, 2022, 168: 108661.1-108661.12. [2] 马卫华,胡俊雄,李铁,等. EMS型中低速磁浮列车悬浮架技术研究综述[J]. 西南交通大学学报,2023,58(4): 720-733.MA Weihua, HU Junxiong, LI Tie, et al. Technologies research review of electro-magnetic suspension medium-low-speed maglev train levitation frame[J]. Journal of Southwest Jiaotong University, 2023, 58(4): 720-733. [3] 熊嘉阳,邓自刚. 高速磁悬浮轨道交通研究进展[J]. 交通运输工程学报,2021,21(1): 177-198.XIONG Jiayang, DENG Zigang. Research progress of high-speed maglev rail transit[J]. Journal of Traffic and Transportation Engineering, 2021, 21(1): 177-198. [4] WANG L D, BU X M, HU P, et al. Dynamic reliability analysis of running safety and stability of a high-speed maglev train on a guideway bridge[J]. International Journal of Structural Stability and Dynamics, 2023: 1-41. [5] 翟明达,朱朋博,李晓龙,等. 常导电磁型高速磁浮列车主动导向能力的评估与验证[J]. 西南交通大学学报,2022,57(3): 514-521.ZHAI Mingda, ZHU Pengbo, LI Xiaolong, et al. Evaluation and verification for active guidance ability of EMS maglev train[J]. Journal of Southwest Jiaotong University, 2022, 57(3): 514-521. [6] 陆海英,韩霄翰,李忠继,等. 中低速磁浮系统起浮阶段的振动特性分析[J]. 中国机械工程,2019,30(3): 318-324.LU Haiying, HAN Xiaohan, LI Zhongji, et al. Analysis of vibration characteristics of low-medium speed maglev levitation systems in lifting stages[J]. China Mechanical Engineering, 2019, 30(3): 318-324. [7] 翟婉明,赵春发. 现代轨道交通工程科技前沿与挑战[J]. 西南交通大学学报,2016,51(2): 209-226.ZHAI Wanming, ZHAO Chunfa. Frontiers and challenges of sciences and technologies in modern railway engineering[J]. Journal of Southwest Jiaotong University, 2016, 51(2): 209-226. [8] 韩霄翰,李忠继,池茂儒. 轨道梁结构对中低速磁浮车轨耦合振动的影响[J]. 铁道机车车辆,2019,39(5): 36-42.HAN Xiaohan, LI Zhongji, CHI Maoru. Influence of track beam structure on the mid-low maglev vehicle-rail coupling vibration[J]. Railway Locomotive & Car, 2019, 39(5): 36-42. [9] FENG Y, ZHAO C F, WU D H, et al. Effect of levitation gap feedback time delay on the EMS maglev vehicle system dynamic response[J]. Nonlinear Dynamics, 2023, 111(8): 7137-7156. doi: 10.1007/s11071-022-08225-5 [10] 赵春发,翟婉明. 常导电磁悬浮动态特性研究[J]. 西南交通大学学报,2004,39(4): 464-468.ZHAO Chunfa, ZHAI Wanming. Dynamic characteristics of electromagnetic levitation systems[J]. Journal of Southwest Jiaotong University, 2004, 39(4): 464-468. [11] 蔡文涛,王春江,滕念管,等. 高速磁浮双向主动控制系统模型参数分析[J]. 力学季刊,2020,41(3): 477-485.CAI Wentao, WANG Chunjiang, TENG Nianguan, et al. Study on the parameters of bi-directional active control system for high speed maglev[J]. Chinese Quarterly of Mechanics, 2020, 41(3): 477-485. [12] 梁鑫,罗世辉,马卫华. 单磁铁悬浮控制系统反馈参数动力学特性分析[J]. 噪声与振动控制,2012,32(5): 62-66,135.LIANG Xin, LUO Shihui, MA Weihua. Dynamic characteristics of feedback coefficient of single magnet suspension control system[J]. Noise and Vibration Control, 2012, 32(5): 62-66,135. [13] 汤港归,汪斌,夏翠鹏,等. 磁浮车辆起浮参数控制及其动力性能研究[J]. 铁道科学与工程学报,2023,20(3): 790-801.TANG Ganggui, WANG Bin, XIA Cuipeng, et al. Control of levitation parameters and dynamic performance of maglev vehicle[J]. Journal of Railway Science and Engineering, 2023, 20(3): 790-801. [14] SUN Y G, HE Z Y, XU J Q, et al. Dynamic analysis and vibration control for a maglev vehicle-guideway coupling system with experimental verification[J]. Mechanical Systems and Signal Processing, 2023, 188: 109954.1-109954.18. [15] 杨志南,冯洋,刘东生,等. 悬浮控制参数对磁浮车辆与道岔梁耦合振动的影响分析[J]. 机械,2022,49(2): 38-46.YANG Zhinan, FENG Yang, LIU Dongsheng, et al. Influence of levitation control parameters on coupled vibration between maglev vehicles and switch girder[J]. Machinery, 2022, 49(2): 38-46. [16] XIANG H Y, TIAN X F, LI Y L, et al. Dynamic interaction analysis of high-speed maglev train and guideway with a control loop failure[J]. International Journal of Structural Stability and Dynamics, 2022, 22(10): 2241012.1-224101228. [17] GUO W, CHEN X Y, YE Y T, et al. Coupling vibration analysis of high-speed maglev train-viaduct systems with control loop failure[J]. Journal of Central South University, 2022, 29(8): 2771-2790. doi: 10.1007/s11771-022-5119-1 [18] 谢云德,常文森. 电磁型(EMS)磁悬浮列车系统铅垂方向的建模与仿真[J]. 铁道学报,1996,18(4): 47-54.XIE Yunde, CHANG Wensen. Modeling and simulation of electromagnetic (EMS) maglev train system in vertical direction[J]. Journal of the China Railway Society, 1996, 18(4): 47-54. [19] ZHANG L, HUANG J Y. Dynamic interaction analysis of the high-speed maglev vehicle/guideway system based on a field measurement and model updating method[J]. Engineering Structures, 2019, 180: 1-17. doi: 10.1016/j.engstruct.2018.11.031 [20] 张宝安,虞大联,李海涛,等. 高速磁浮悬浮架柔性特征对曲线通过性能的影响[J]. 西南交通大学学报,2022,57(3): 475-482.ZHANG Baoan, YU Dalian, LI Haitao, et al. Influence of flexibility characteristics of levitation chassis on curve negotiation performance of high-speed maglev vehicle[J]. Journal of Southwest Jiaotong University, 2022, 57(3): 475-482. [21] ZHAO C F, ZHAI W M. Maglev vehicle/guideway vertical random response and ride quality[J]. Vehicle System Dynamics, 2002, 38(3): 185-210. doi: 10.1076/vesd.38.3.185.8289 [22] SHI J, FANG W S, WANG Y J, et al. Measurements and analysis of track irregularities on high speed maglev lines[J]. Journal of Zhejiang University-Science A, 2014, 15(6): 385-394. doi: 10.1631/jzus.A1300163 [23] WANG Z L, XU Y L, LI G Q, et al. Modelling and validation of coupled high-speed maglev train-and-viaduct systems considering support flexibility[J]. Vehicle System Dynamics, 2019, 57(2): 161-191. doi: 10.1080/00423114.2018.1450517 [24] SHI J, WANG Y J. Dynamic response analysis of single-span guideway caused by high speed maglev train[J]. Latin American Journal of Solids and Structures, 2011, 8(3): 213-228. doi: 10.1590/S1679-78252011000300001 [25] XU Y L, WANG Z L, LI G Q, et al. High-speed running maglev trains interacting with elastic transitional viaducts[J]. Engineering Structures, 2019, 183: 562-578. doi: 10.1016/j.engstruct.2019.01.012 [26] 徐金辉,王平,汪力,等. 基于频域分析方法的轨道高低不平顺敏感波长的研究[J]. 中南大学学报(自然科学版),2016,47(2): 683-689.XU Jinhui, WANG Ping, WANG Li, et al. Sensitive wavelengths of vertical track irregularities by frequency-domain method[J]. Journal of Central South University (Science and Technology), 2016, 47(2): 683-689. -

 下载:
下载:
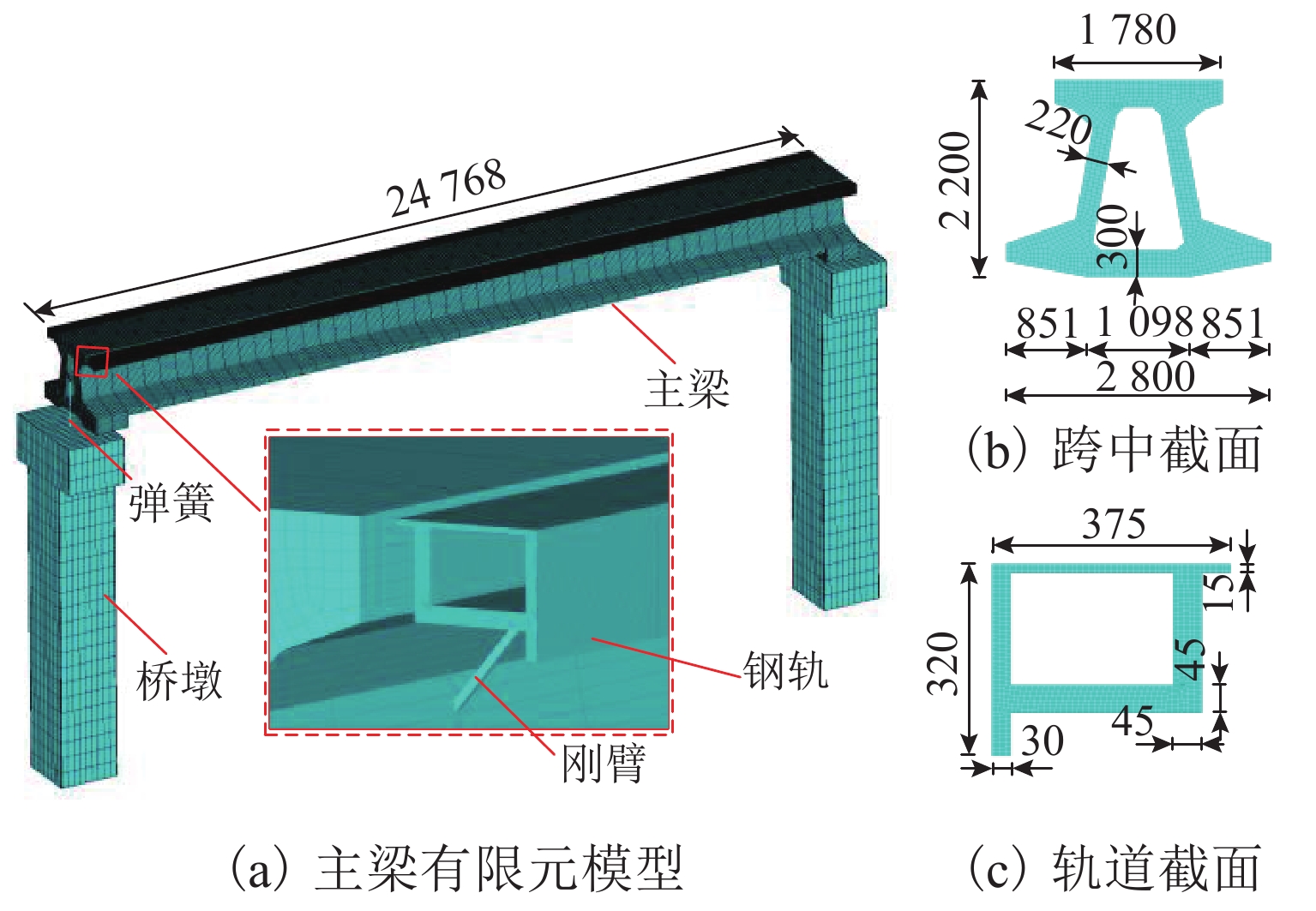

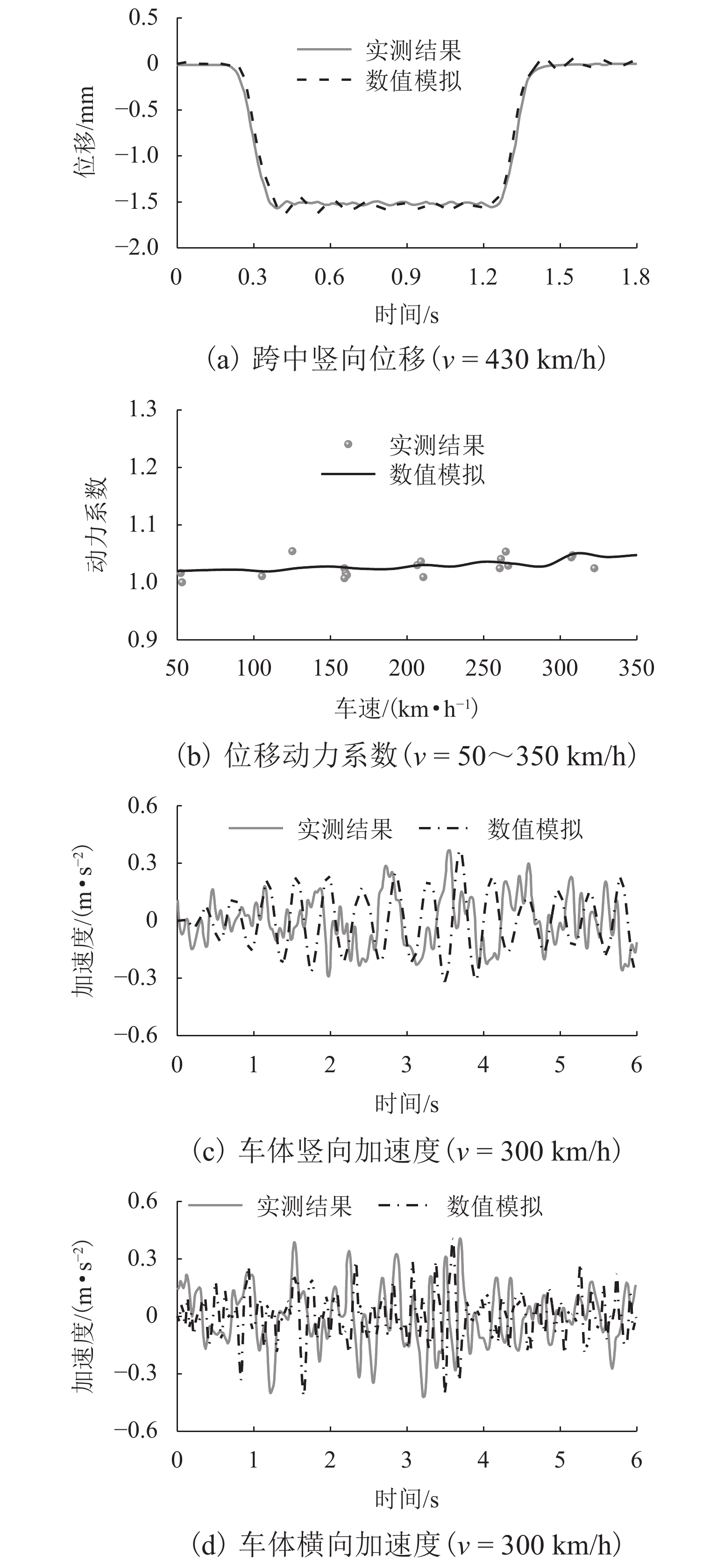

 点击查看大图
点击查看大图
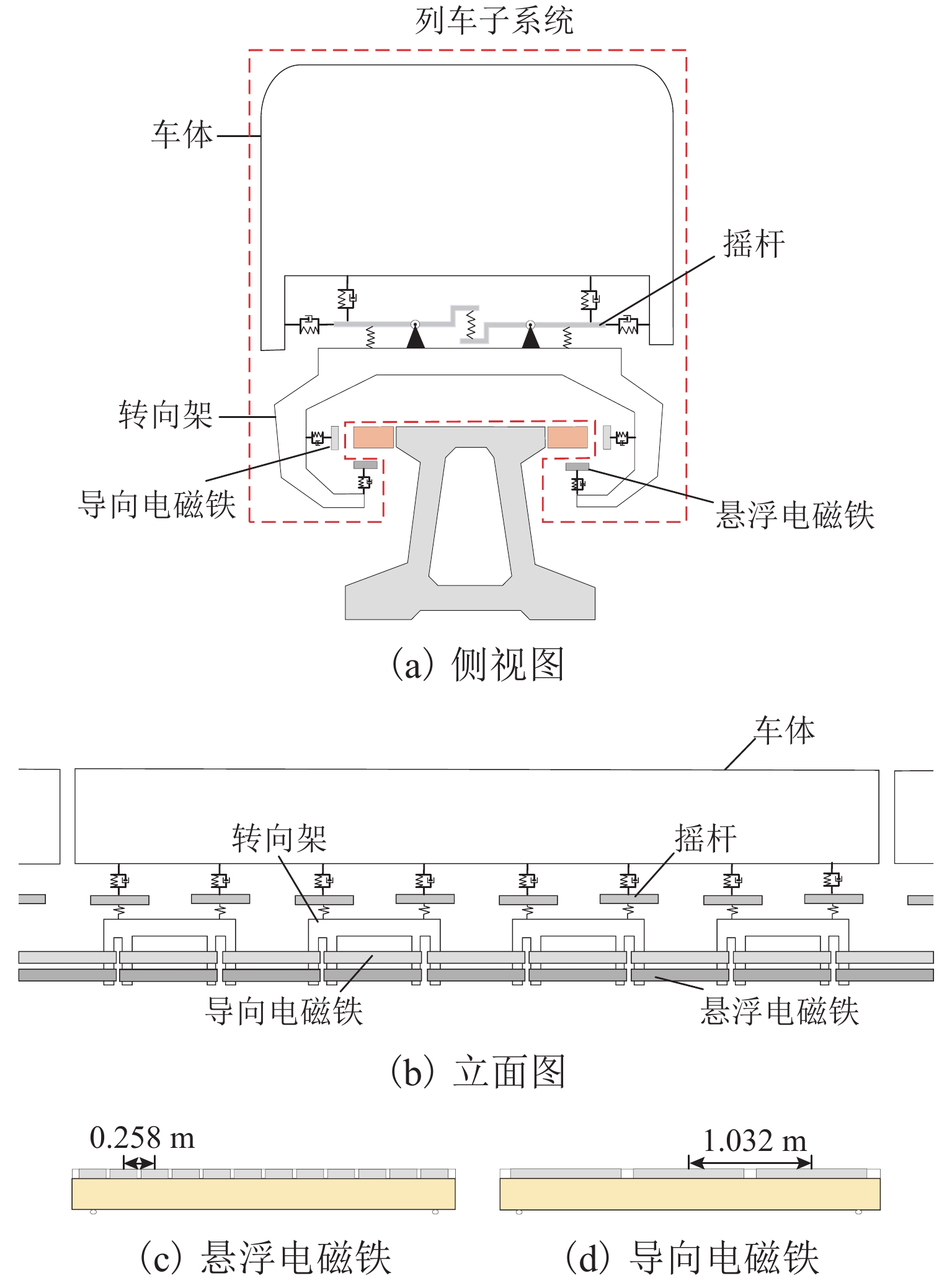
计量
- 文章访问数: 846
- HTML全文浏览量: 475
- PDF下载量: 97
- 被引次数: 0