Infrared and Visible Image Fusion Based on Attention Mechanism and Illumination-Aware Network
-
摘要:
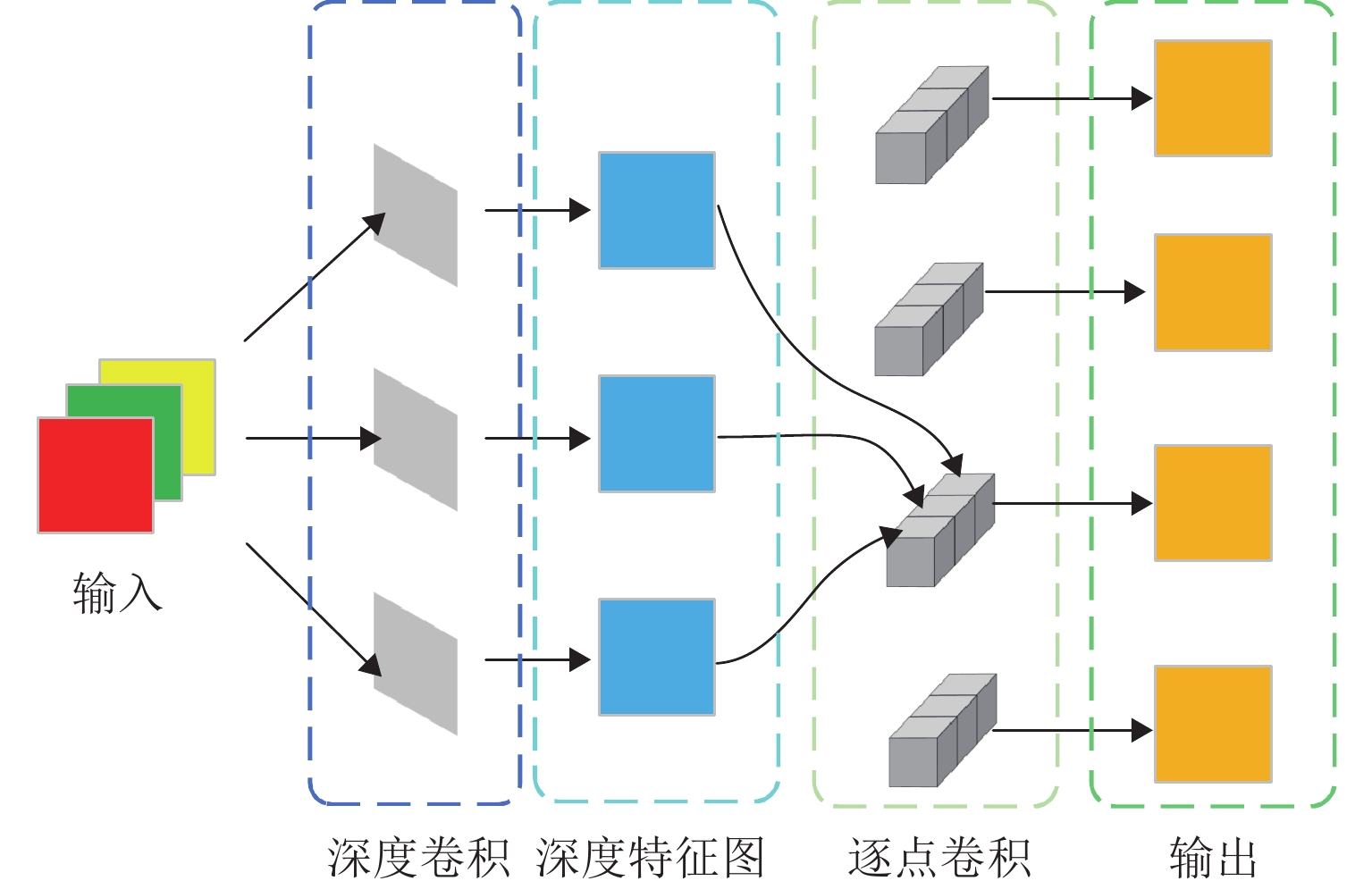
部分图像融合方法未充分考虑图像环境的光照状况,导致融合图像中出现红外目标亮度不足以及整体画面亮度较低,从而影响纹理细节的清晰度. 为解决上述问题,提出一种基于注意力机制与光照感知网络相结合的红外与可见光图像融合算法. 首先,在训练融合网络之前利用光照感知网络计算当前场景是日间或夜间的概率,将其运用至融合网络损失函数中,用以指导融合网络训练;然后,在网络的特征提取部分采用空间注意力机制和深度可分离卷积对源图像进行特征提取,得到空间显著信息后,输入卷积神经网络(CNN)以提取深度特征;最后,将深度特征信息进行拼接用于图像重建,进而得到最终的融合图像. 实验结果表明:本文方法的互信息(MI)、视觉保真度(VIF)、平均梯度(AG)、融合质量(Qabf)与空间频率(SF)较对比方法分别平均提高39.33%、11.29%、26.27%、47.11%和39.01%;融合后的图像能够有效保留红外目标亮度,且包含丰富的纹理细节信息.
Abstract:Some image fusion methods do not fully consider the illumination conditions in the image environment, resulting in insufficient brightness of infrared targets and overall low brightness of the image in the fused image, thereby affecting the clarity of texture details. To address these issues, an infrared and visible image fusion algorithm based on attention mechanism and illumination-aware network was proposed. Firstly, before training the fusion network, the illumination-aware network was used to calculate the probability that the current scene was daytime or nighttime and apply it to the loss function of the fusion network, so as to guide the training of the fusion network. Then, in the feature extraction part of the network, spatial attention mechanism and depthwise separable convolution were used to extract features from the source image. After obtaining spatial salient information, it was input into a convolutional neural network (CNN) to extract deep features. Finally, the deep feature information was concatenated for image reconstruction to obtain the final fused image. The experimental results show that the method proposed in this paper improves mutual information (MI), visual fidelity (VIF), average gradient (AG), fusion quality (Qabf), and spatial frequency (SF) by an average of 39.33%, 11.29%, 26.27%, 47.11%, and 39.01%, respectively. At the same time, it can effectively preserve the brightness of infrared targets in the fused images, including rich texture detail information.
-
表 1 特征提取部分卷积核大小与输出通道数
Table 1. Convolution kernel size and output channels in feature extraction part
卷积层 卷积核大小 输出通道数/个 Conv1-1 1 × 1 16 Conv1-2 3 × 3 16 Conv1-3 3 × 3 32 Conv1-4 3 × 3 64 Conv1-5 3 × 3 128  下载: 导出CSV
下载: 导出CSV
表 2 图像重建部分卷积核大小与输出通道数
Table 2. Convolution kernel size and output channels in image reconstruction part
卷积层 卷积核大小 输出通道数/个 Conv2-1 3 × 3 256 Conv2-2 3 × 3 128 Conv2-3 3 × 3 64 Conv2-4 3 × 3 32 Conv2-5 1 × 1 1
下载: 导出CSV
表 4 红外目标分析
Table 4. Infrared target analysis
 下载: 导出CSV
下载: 导出CSV
表 5 客观评价指标对比
Table 5. Comparison of objective evaluation indicators
融合方法 MI VIF AG Qabf EN SF DenseFuse 2.3019 0.8175 3.5600 0.4457 6.8912 0.0352 FusionGAN 2.3352 0.6541 2.4211 0.2341 6.5580 0.0246 PMGI 2.3521 0.8692 3.5981 0.4117 7.0180 0.0344 RFN-Nest 2.1184 0.8183 2.6693 0.3341 6.9632 0.0230 SDNet 2.2606 0.7592 4.6117 0.4294 6.6948 0.0457 U2Fusion 2.0102 0.8197 5.0233 0.4263 6.9967 0.0465 DIVFusion 2.2226 0.9005 5.5595 0.3117 7.5932 0.0465 PSFusion 2.3082 0.9000 5.5979 0.5223 7.2529 0.0478 本文方法 3.1231 0.9008 4.7888 0.5578 6.8794 0.0489
下载: 导出CSV
[1] LIU X W, WANG R H, HUO H T, et al. An attention-guided and wavelet-constrained generative adversarial network for infrared and visible image fusion[J]. Infrared Physics and Technology, 2023, 129: 104570.1-104570.16. [2] 唐霖峰,张浩,徐涵,等. 基于深度学习的图像融合方法综述[J]. 中国图象图形学报,2023,28(1): 3-36. doi: 10.11834/jig.220422TANG Linfeng, ZHANG Hao, XU Han, et al. Deep learning-based image fusion: a survey[J]. Journal of Image and Graphics, 2023, 28(1): 3-36. doi: 10.11834/jig.220422 [3] 程博阳,李婷,王喻林. 基于视觉显著性加权与梯度奇异值最大的红外与可见光图像融合[J]. 中国光学(中英文),2022,15(4): 675-688. doi: 10.37188/CO.2022-0124CHENG Boyang, LI Ting, WANG Yulin. Fusion of infrared and visible light images based on visual saliency weighting and maximum gradient singular value[J]. Chinese Optics, 2022, 15(4): 675-688. doi: 10.37188/CO.2022-0124 [4] 杨莘,田立凡,梁佳明,等. 改进双路径生成对抗网络的红外与可见光图像融合[J]. 电子与信息学报,2023,45(8): 3012-3021. doi: 10.11999/JEIT220819YANG Shen, TIAN Lifan, LIANG Jiaming, et al. Infrared and visible image fusion based on improved dual path generation adversarial network[J]. Journal of Electronics & Information Technology, 2023, 45(8): 3012-3021. doi: 10.11999/JEIT220819 [5] 沈英,黄春红,黄峰,等. 红外与可见光图像融合技术的研究进展[J]. 红外与激光工程,2021,50(9): 152-169.SHEN Ying, HUANG Chunhong, HUANG Feng, et al. Research progress of infrared and visible image fusion technology[J]. Infrared and Laser Engineering, 2021, 50(9): 152-169. [6] 胡建平,郝梦云,杜影,等. 结构和纹理感知的Retinex融合红外与可见光图像[J]. 光学 精密工程,2022,30(24): 3225-3238. doi: 10.37188/OPE.20223024.3225HU Jianping, HAO Mengyun, DU Ying, et al. Fusion of infrared and visible images via structure and texture-aware retinex[J]. Optics and Precision Engineering, 2022, 30(24): 3225-3238. doi: 10.37188/OPE.20223024.3225 [7] 李霖,王红梅,李辰凯. 红外与可见光图像深度学习融合方法综述[J]. 红外与激光工程,2022,51(12): 337-356.LI Lin, WANG Hongmei, LI Chenkai. A review of deep learning fusion methods for infrared and visible images[J]. Infrared and Laser Engineering, 2022, 51(12): 337-356. [8] 王银,王立德,邱霁. 基于DenseNet结构的轨道暗光环境实时增强算法[J]. 西南交通大学学报,2022,57(6): 1349-1357. doi: 10.3969/j.issn.0258-2724.20210199WANG Yin, WANG Lide, QIU Ji. Real-time enhancement algorithm based on DenseNet structure for railroad low-light environment[J]. Journal of Southwest Jiaotong University, 2022, 57(6): 1349-1357. doi: 10.3969/j.issn.0258-2724.20210199 [9] 朱雯青,汤心溢,张瑞,等. 基于边缘保持和注意力生成对抗网络的红外与可见光图像融合[J]. 红外与毫米波学报,2021,40(5): 696-708. doi: 10.11972/j.issn.1001-9014.2021.05.017ZHU Wenqing, TANG Xinyi, ZHANG Rui, et al. Infrared and visible image fusion based on edge-preserving and attention generative adversarial network[J]. Journal of Infrared and Millimeter Waves, 2021, 40(5): 696-708. doi: 10.11972/j.issn.1001-9014.2021.05.017 [10] TANG L F, XIANG X Y, ZHANG H, et al. DIVFusion: darkness-free infrared and visible image fusion[J]. Information Fusion, 2023, 91: 477-493. doi: 10.1016/j.inffus.2022.10.034 [11] 李泽琛,李恒超,胡文帅,等. 多尺度注意力学习的Faster R-CNN口罩人脸检测模型[J]. 西南交通大学学报,2021,56(5): 1002-1010. doi: 10.3969/j.issn.0258-2724.20210017LI Zechen, LI Hengchao, HU Wenshuai, et al. Masked face detection model based on multi-scale attention-driven faster R-CNN[J]. Journal of Southwest Jiaotong University, 2021, 56(5): 1002-1010. doi: 10.3969/j.issn.0258-2724.20210017 [12] 王满利,王晓龙,张长森. 基于动态范围压缩增强和NSST的红外与可见光图像融合算法[J]. 光子学报,2022,51(9): 277-291.WANG Manli, WANG Xiaolong, ZHANG Changsen. Infrared and visible image fusion algorithm based on dynamic range compression enhancement and NSST[J]. Acta Photonica Sinica, 2022, 51(9): 277-291. [13] 朱文鹏,陈莉,张永新. 基于引导滤波和快速共现滤波的红外和可见光图像融合[J]. 计算机应用研究,2021,38(2): 600-604,610.ZHU Wenpeng, CHEN Li, ZHANG Yongxin. Infrared and visible image fusion based on guided filter and fast co-occurrence filter[J]. Application Research of Computers, 2021, 38(2): 600-604,610. [14] MA J L, ZHOU Z Q, WANG B, et al. Infrared and visible image fusion based on visual saliency map and weighted least square optimization[J]. Infrared Physics and Technology, 2017, 82: 8-17. doi: 10.1016/j.infrared.2017.02.005 [15] MA J Y, YU W, LIANG P W, et al. FusionGAN: a generative adversarial network for infrared and visible image fusion[J]. Information Fusion, 2019, 48: 11-26. doi: 10.1016/j.inffus.2018.09.004 [16] ZHANG H, MA J Y. SDNet: a versatile squeeze-and-decomposition network for real-time image fusion[J]. International Journal of Computer Vision, 2021, 129(10): 2761-2785. doi: 10.1007/s11263-021-01501-8 [17] LI H, WU X J, KITTLER J. RFN-Nest: an end-to-end residual fusion network for infrared and visible images[J]. Information Fusion, 2021, 73(10): 72-86. [18] XU H, MA J Y, JIANG J J, et al. U2Fusion: a unified unsupervised image fusion network[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(1): 502-518. doi: 10.1109/TPAMI.2020.3012548 [19] LI H, WU X J. DenseFuse: a fusion approach to infrared and visible images[J]. IEEE Transactions on Image Processing, 2019, 28(5): 2614-2623. doi: 10.1109/TIP.2018.2887342 [20] JIAN L H, YANG X M, LIU Z, et al. SEDRFuse: a symmetric encoder–decoder with residual block network for infrared and visible image fusion[J]. IEEE Transactions on Instrumentation and Measurement, 2021, 70: 5002215.1-5002215.15. [21] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]//European Conference on Computer Vision. Cham: Springer, 2018: 3-19. [22] CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu: IEEE, 2017: 1800-1807. [23] TANG L F, YUAN J T, ZHANG H, et al. PIAFusion: a progressive infrared and visible image fusion network based on illumination aware[J]. Information Fusion, 2022, 83/84: 79-92. doi: 10.1016/j.inffus.2022.03.007 [24] ZHANG H, XU H, XIAO Y, et al. Rethinking the image fusion: a fast unified image fusion network based on proportional maintenance of gradient and intensity[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 12797-12804. doi: 10.1609/aaai.v34i07.6975 [25] TANG L F, ZHANG H, XU H, et al. Rethinking the necessity of image fusion in high-level vision tasks: a practical infrared and visible image fusion network based on progressive semantic injection and scene fidelity[J]. Information Fusion, 2023, 99: 101870.1-101870.16. 
 点击查看大图
点击查看大图
 图(5) / 表(6)
图(5) / 表(6)计量
- 文章访问数: 571
- HTML全文浏览量: 306
- PDF下载量: 66
- 被引次数: 0
 下载:
下载: