

Location Information Perception of Onsite Construction Crew Based on Person Re-identification
-
摘要:
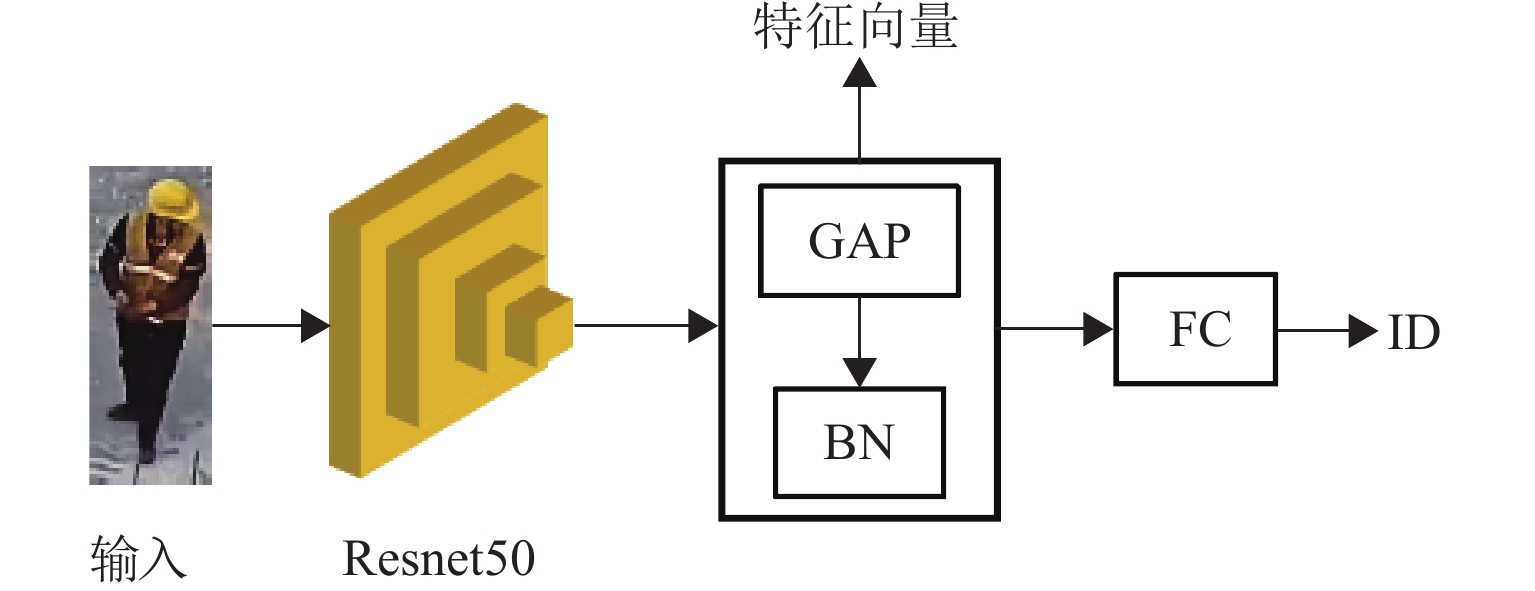
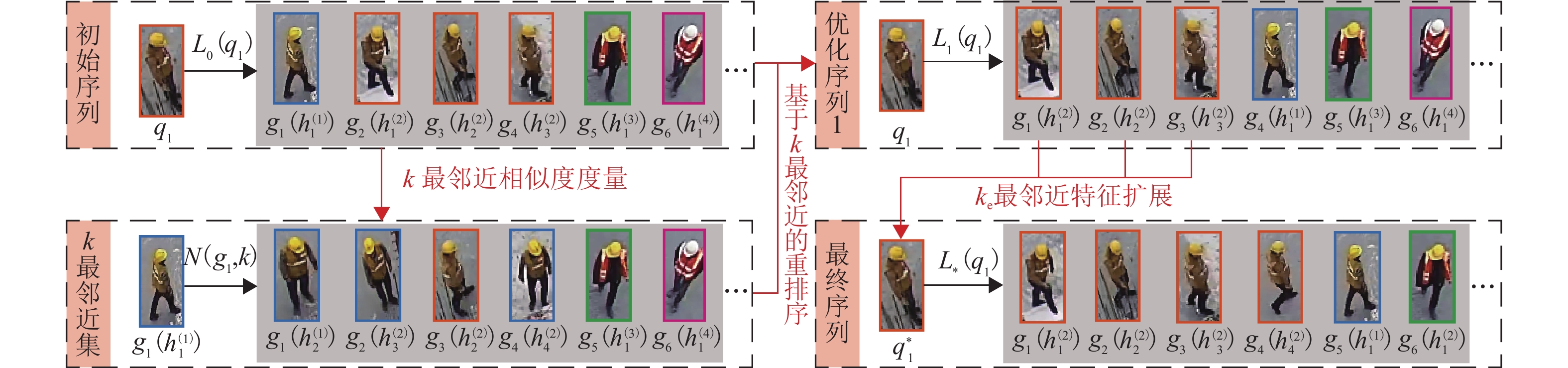
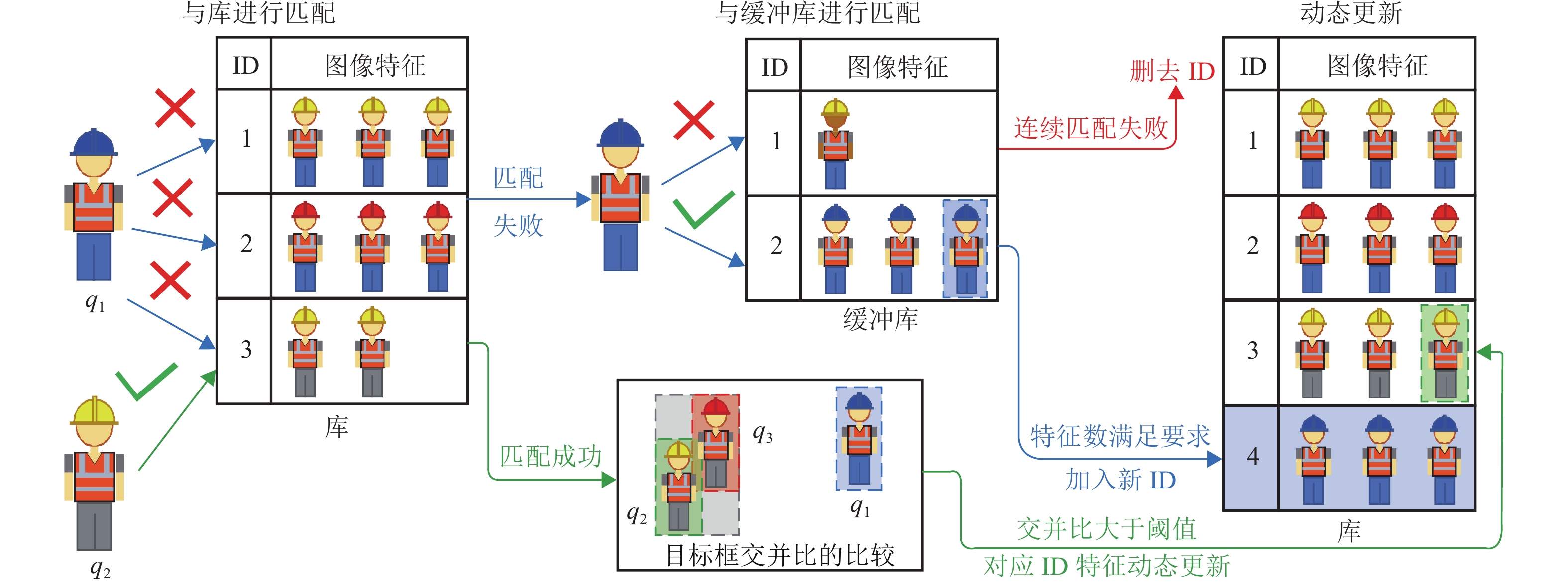
为结合施工场景动态性强、遮挡严重、人员衣着相似等特点,实现对施工现场人员持续的位置信息感知,提出一种基于计算机视觉的施工现场人员信息智能感知算法. 首先,利用基于深度学习的目标检测算法实现人员的初步感知;其次,以行人重识别的视角提出一种数据关联方法,通过深度特征匹配实现目标ID分配,采用基于重排序的距离度量优化相似度度量结果,再利用缓冲机制和特征动态更新机制对匹配结果进行后处理,减少施工场景难点带来的错误匹配;然后,利用图像透视变换获取与ID对应的2D坐标信息及运动信息,为生产力分析提供基础数据;最后,利用所采集的包含不同施工阶段的图像构建标准测试视频,并对方法进行测试. 研究表明:在不同场景下,算法平均IDF1(ID的F1得分)和多目标追踪准确度(multiple object tracking accuracy,MOTA)分别为85.4%和75.4%,所提出的重排序方法、匹配后处理机制有效提升追踪精度,相比去除这些优化机制后的算法,IDF1和MOTA平均分别提升了52.8%和3.8%.
Abstract:To obtain location information of onsite construction crew continuously with the consideration of dynamical changing, occluding, and high appearance similarity in construction scenes, a computer vision-based location information perception method for onsite construction crew was proposed. Firstly, a deep learning-based object detection method was utilized to percept targets preliminarily. Then, a data association method based on person re-identification was used, where ID assignment was completed by matching the deep learning-based feature. A distance metric method based on re-ranking was utilized to optimize the similarity measurement results, and the matching result was processed by using a buffering mechanism and a dynamical feature updating mechanism, so as to mitigate mismatch due to difficulties in construction scenes. 2D coordinates and movement information corresponding to ID were obtained using perspective transformation of images to provide basic data for productivity analysis. Finally, standard test videos were created from images collected at different construction stages to test the proposed method. The test results show that in different scenes, the average F1 score of ID (IDF1) and multiple object tracking accuracy (MOTA) of the algorithm are 85.4% and 75.4%, respectively. The proposed re-ranking method and post-processing mechanism for matching effectively improve the tracking accuracy. Compared with the algorithm after removing these optimization mechanisms, the average improvement of IDF1 and MOTA is 52.8% and 3.8%, respectively.
-
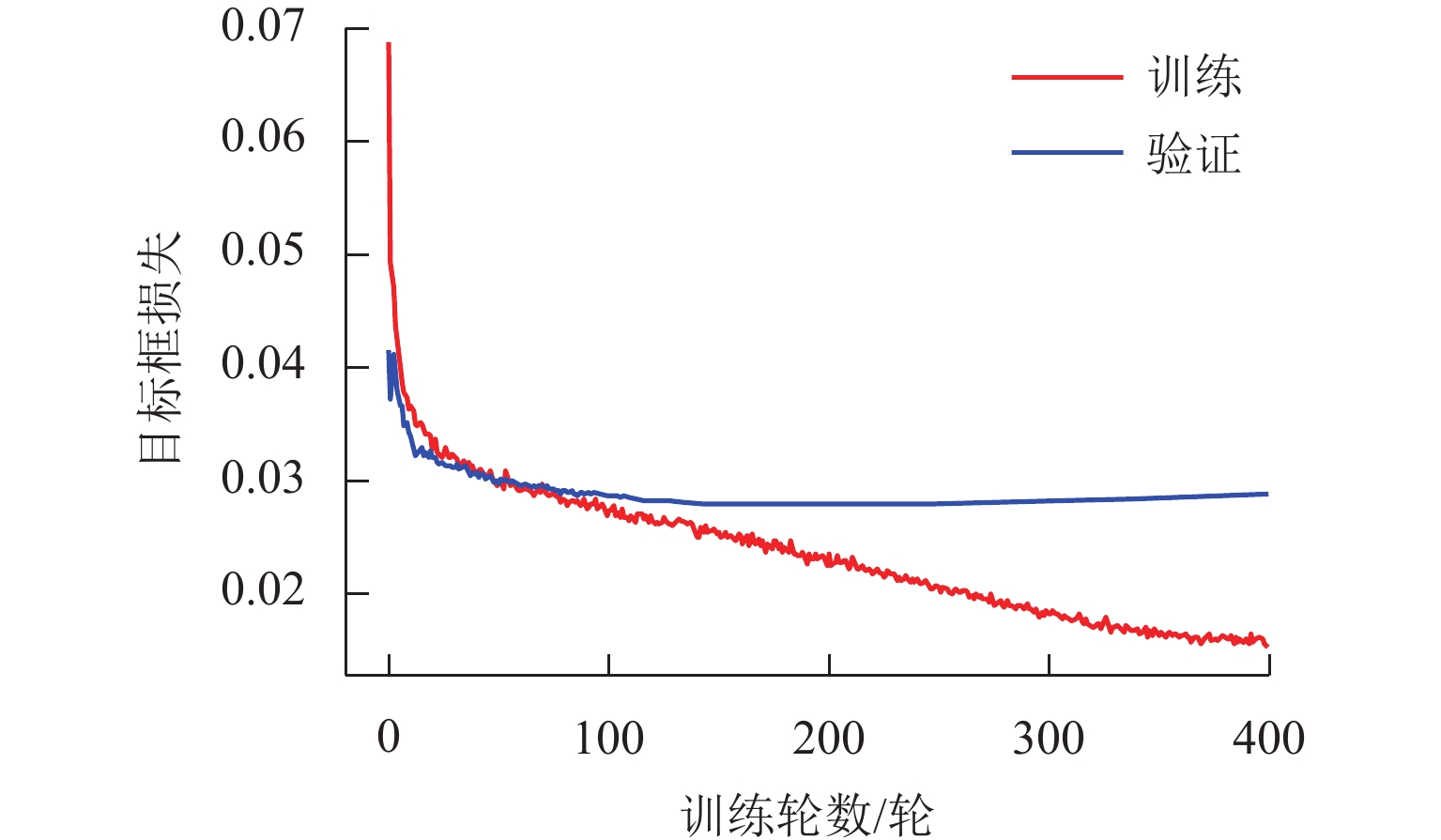
图 2 目标检测网络目标框损失变化曲线
Figure 2. Loss curves of target boxes for target detection network
表 1 标准测试视频详细信息
Table 1. Details of standard test videos
编号 主要施工活动 视角 帧数/帧 目标数/个 难点 1 混凝土浇筑 平视 1479 10136 尺寸差异、遮挡 2 结构测设 平视 769 4606 尺寸差异、遮挡 3 混凝土浇筑 俯视 754 9803 夜间、遮挡 4 结构测设 俯视 616 8101 小目标、遮挡 5 钢筋绑扎 俯视 1230 26922 小目标、遮挡 6 混凝土浇筑 俯视 704 8427 夜间、小目标 7 混凝土模板搭设 俯视 1131 5656 姿态改变、背景复杂 8 预制柱吊装 俯视 1374 11220 动态性强、遮挡 9 预制板吊装 俯视 866 4221 动态性强、遮挡 10 脚手架搭建 俯视 497 6853 背景复杂 11 钢筋加工 俯视 632 3265 人员离开又重进入  下载: 导出CSV
下载: 导出CSV
表 2 软硬件配置详情
Table 2. Software and hardware configuration
项目 详情 监控设备 6 寸球机 型号:DS-2DC6423IW-AE CPU Intel(R) Core(TM) i9-10900X @3.70 GHz GPU NVIDIA GeForce GTX 2080 Ti 操作系统 Ubuntu 20.04.3 编程环境 Python 3.8.8 深度学习框架 Pytorch 1.9.1 + cu102
下载: 导出CSV
表 3 不同算法在标准测试视频中的结果
Table 3. Performance of different algorithms on standard test videos
% 算法 场景 1 场景 2 场景 3 场景 4 场景 5 场景 6 场景 7 场景 8 场景 9 场景 10 场景 11 DAN*[20] 61.5/65.8 44.2/55.4 66.8/67.8 79.2/77.9 73.1/61.5 78.9/81.3 95.3/86.4 76.7/84.2 78.6/81.3 65.5/59.0 93.5/96.2 TraDeS[21] 43.4/27.0 32.2/21.2 8.2/5.3 10.4/−10.8 8.8/−6.8 40.3/28.8 4.2/2.6 30.2/36.2 5.4/−0.7 10.5/2.8 40.4/16.6 FairMOT[22] 48.7/47.0 51.4/54.0 18.4/13.5 47.9/40.5 12.0/0 61.9/45.0 10.1/9.6 29.1/33.6 28.2/18.2 11.6/5.7 49.8/43.5 Trackformer*[23] 61.7/55.3 49.8/44.4 29.5/23.0 58.0/54.5 37.2/22.7 68.7/58.9 40.6/24.1 36.7/52.3 32.8/30.6 37.5/38.1 83.8/95.7 Unicorn[24] 61.4/57.5 70.5/64.0 13.2/4.6 62.6/46.9 20.1/16.4 72.5/66.3 3.2/3.4 54.6/58.7 34.3/29.2 40.4/34.2 81.7/79.9 ByteTrack[25] 73.4/63.7 67.3/62.4 64.6/58.2 82.1/73.5 38.5/29.6 77.6/71.2 33.4/31.1 61.8/67.1 52.6/54.1 47.0/34.4 83.0/75.8 本文算法* 78.0/66.0 73.3/57.1 82.4/67.8 87.2/77.7 78.0/63.1 89.1/81.6 97.8/95.6 91.8/84.8 90.5/81.5 73.8/58.3 97.5/96.4 注:带 * 的方法使用了相同的目标检测结果,最优结果加粗表示.
下载: 导出CSV
表 4 不同架构下追踪结果详情
Table 4. Tracking results with different architectures
% 架构 场景 1 场景 2 场景 3 场景 4 场景 5 场景 6 场景 7 场景 8 场景 9 场景 10 场景 11 完整 78.0/66.0 73.3/57.1 82.4/67.8 87.2/77.7 78.0/63.1 89.1/81.6 97.8/95.6 91.8/84.8 90.5/81.5 73.8/58.3 97.5/96.4 无重排序 77.3/66.0 60.1/56.6 81.6/67.6 77.8/77.5 74.8/61.9 88.1/81.4 97.8/95.6 80.6/84.2 90.4/81.3 66.8/58.3 95.9/92.6 无缓冲 76.9/66.0 56.8/55.6 79.3/68.0 81.5/77.9 76.0/61.5 87.1/81.6 97.8/95.6 91.3/84.2 89.5/81.0 72.8/59.1 96.0/96.4 无动态更新 67.0/62.9 47.1/53.5 46.7/60.5 56.1/66.4 45.0/54.7 69.2/77.8 68.4/91.9 60.4/79.4 69.1/78.5 51.3/51.2 92.3/93.7 仅动态更新 70.0/65.9 55.5/55.5 76.4/67.9 74.0/77.7 64.7/61.5 84.5/81.5 93.9/95.6 78.0/84.1 81.4/81.1 63.3/58.9 88.0/96.2 仅缓冲 60.6/63.6 31.0/53.0 30.1/59.3 36.2/68.9 28.3/53.9 60.3/77.2 40.2/87.3 37.5/78.8 45.1/77.0 27.0/52.3 44.7/90.2 仅重排序 63.0/63.9 45.0/54.6 38.8/64.4 41.5/72.6 36.8/56.6 64.0/79.9 58.3/92.4 52.8/80.3 69.5/77.8 38.3/55.8 63.2/94.0 无优化方法 47.8/63.4 27.8/53.4 22.9/62.5 29.6/73.3 21.7/56.2 49.2/79.0 31.6/91.3 29.1/80.4 37.7/77.9 24.5/56.4 36.7/94.1
下载: 导出CSV
表 5 运动数据获取结果
Table 5. Attained movement data
ID 移动距离/m 在场总时间/s 移动时间/s 平均速度/
(m•s−1)0 52.2 78.0 37.8 1.4 1 12.3 78.0 9.0 1.4 2 0.5 78.0 0.6 0.8 3 7.0 77.8 7.0 1.0 4 28.0 76.1 25.6 1.1 5 17.4 33.5 16.6 1.0
下载: 导出CSV
-
[1] PARK M W, BRILAKIS I. Continuous localization of construction workers via integration of detection and tracking[J]. Automation in Construction, 2016, 72: 129-142. doi: 10.1016/j.autcon.2016.08.039 [2] LEE Y J, PARK M W. 3D tracking of multiple onsite workers based on stereo vision[J]. Automation in Construction, 2019, 98: 146-159. doi: 10.1016/j.autcon.2018.11.017 [3] SON H, KIM C. Integrated worker detection and tracking for the safe operation of construction machinery[J]. Automation in Construction, 2021, 126: 103670.1-103670.11. [4] KONSTANTINOU E, LASENBY J, BRILAKIS I. Adaptive computer vision-based 2D tracking of workers in complex environments[J]. Automation in Construction, 2019, 103: 168-184. doi: 10.1016/j.autcon.2019.01.018 [5] SON H, CHOI H, SEONG H, et al. Detection of construction workers under varying poses and changing background in image sequences via very deep residual networks[J]. Automation in Construction, 2019, 99: 27-38. doi: 10.1016/j.autcon.2018.11.033 [6] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. (2020-04-23)[2023-02-23]. http://arxiv.org/abs/2004.10934. [7] ANGAH O, CHEN A Y. Tracking multiple construction workers through deep learning and the gradient based method with re-matching based on multi-object tracking accuracy[J]. Automation in Construction, 2020, 119: 103308.1-103308.9. [8] HE K M, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//2017 IEEE International Conference on Computer Vision (ICCV). Venice: IEEE, 2017: 2980-2988. [9] ZHANG Q L, WANG Z C, YANG B, et al. Reidentification-based automated matching for 3D localization of workers in construction sites[J]. Journal of Computing in Civil Engineering, 2021, 35(6): 04021019.1-04021019.18. [10] 罗浩,姜伟,范星,等. 基于深度学习的行人重识别研究进展[J]. 自动化学报,2019,45(11): 2032-2049.LUO Hao, JIANG Wei, FAN Xing, et al. A survey on deep learning based person re-identification[J]. Acta Automatica Sinica, 2019, 45(11): 2032-2049. [11] YE M, SHEN J B, LIN G J, et al. Deep learning for person re-identification: a survey and outlook[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(6): 2872-2893. doi: 10.1109/TPAMI.2021.3054775 [12] JOCHER G. YOLOv5 by ultralytics[CP/OL]. (2020-05)[2023-02-23]. https://github.com/ultralytics/yolov5. [13] AN X H, ZHOU L, LIU Z G, et al. Dataset and benchmark for detecting moving objects in construction sites[J]. Automation in Construction, 2021, 122: 103482.1-103482.18. [14] LUO H, GU Y Z, LIAO X Y, et al. Bag of tricks and a strong baseline for deep person re-identification [C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Long Beach: IEEE, 2019: 1487-1495. [15] ZHENG L, SHEN L Y, TIAN L, et al. Scalable person re-identification: a benchmark[C]//2015 IEEE International Conference on Computer Vision (ICCV). Santiago: IEEE, 2015: 1116-1124. [16] JIA J R, RUAN Q Q, JIN Y, et al. View-specific subspace learning and re-ranking for semi-supervised person re-identification[J]. Pattern Recognition, 2020, 108: 107568.1-107568.12. [17] GARCIA J, MARTINEL N, GARDEL A, et al. Discriminant context information analysis for post-ranking person re-identification[J]. IEEE Transactions on Image Processing, 2017, 26(4): 1650-1665. doi: 10.1109/TIP.2017.2652725 [18] CROUSE D F. On implementing 2D rectangular assignment algorithms[J]. IEEE Transactions on Aerospace and Electronic Systems, 2016, 52(4): 1679-1696. doi: 10.1109/TAES.2016.140952 [19] KIM D, LIU M Y, LEE S, et al. Remote proximity monitoring between mobile construction resources using camera-mounted UAVs[J]. Automation in Construction, 2019, 99: 168-182. doi: 10.1016/j.autcon.2018.12.014 [20] SUN S J, AKHTAR N, SONG H S, et al. Deep affinity network for multiple object tracking[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(1): 104-119. [21] WU J L, CAO J L, SONG L C, et al. Track to detect and segment: an online multi-object tracker[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville: IEEE, 2021: 12347-12356. [22] ZHANG Y F, WANG C Y, WANG X G, et al. FairMOT: on the fairness of detection and re-identification in multiple object tracking[J]. International Journal of Computer Vision, 2021, 129(11): 3069-3087. doi: 10.1007/s11263-021-01513-4 [23] MEINHARDT T, KIRILLOV A, LEAL-TAIXÉ L, et al. TrackFormer: multi-object tracking with transformers[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans: IEEE, 2022: 8834-8844. [24] YAN B, JIANG Y, SUN P Z, et al. Towards grand unification of object tracking[C]//European Conference on Computer Vision. Cham: Springer, 2022: 733-751. [25] ZHANG Y F, SUN P Z, JIANG Y, et al. ByteTrack: multi-object tracking by associating every detection box[C]//European Conference on Computer Vision. Cham: Springer, 2022: 1-21. [26] 朱军,张天奕,谢亚坤,等. 顾及小目标特征的视频人流量智能统计方法[J]. 西南交通大学学报,2022,57(4): 705-712,736. doi: 10.3969/j.issn.0258-2724.20200425ZHU Jun, ZHANG Tianyi, XIE Yakun, et al. Intelligent statistic method for video pedestrian flow considering small object features[J]. Journal of Southwest Jiaotong University, 2022, 57(4): 705-712,736. doi: 10.3969/j.issn.0258-2724.20200425 -

 下载:
下载:
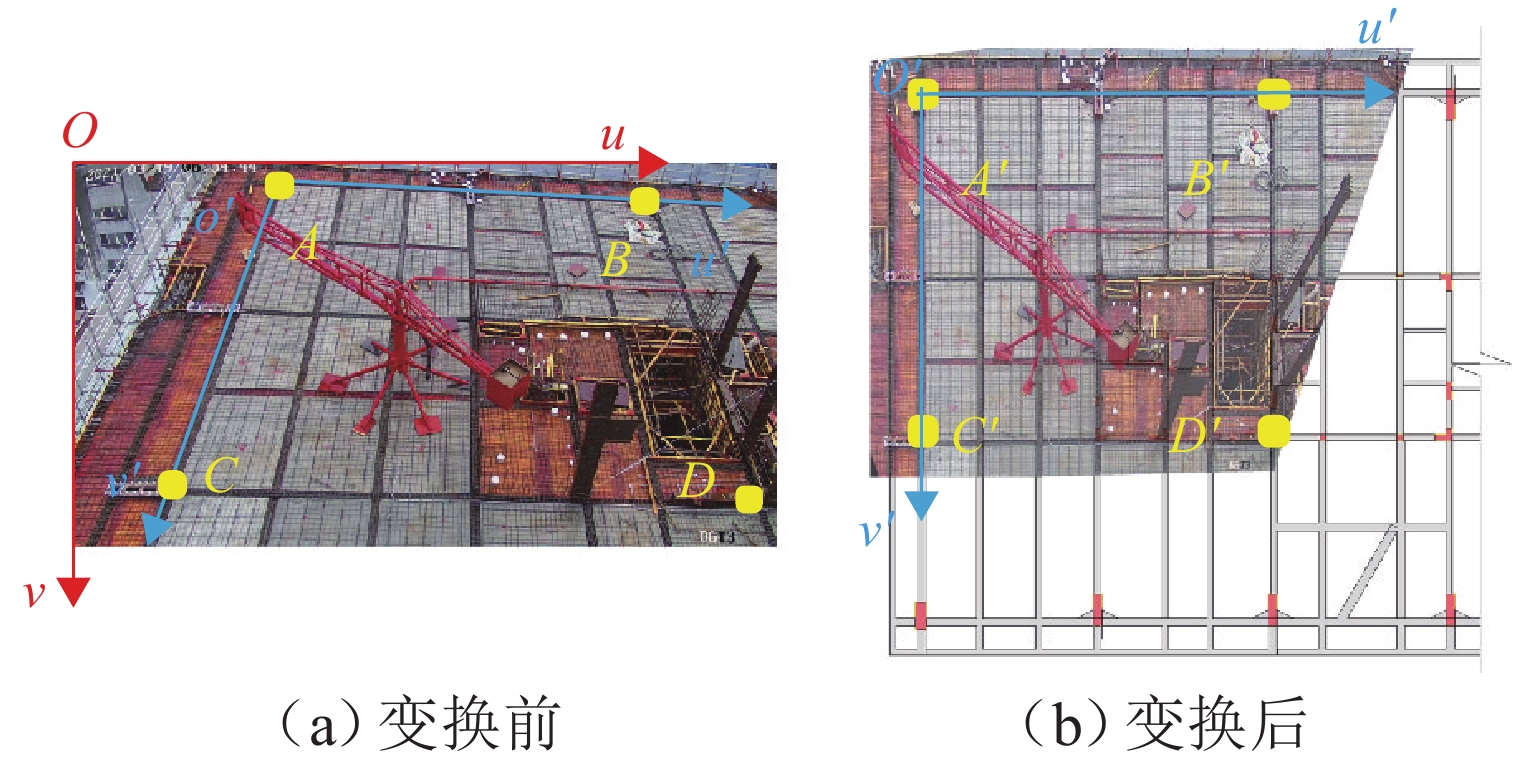

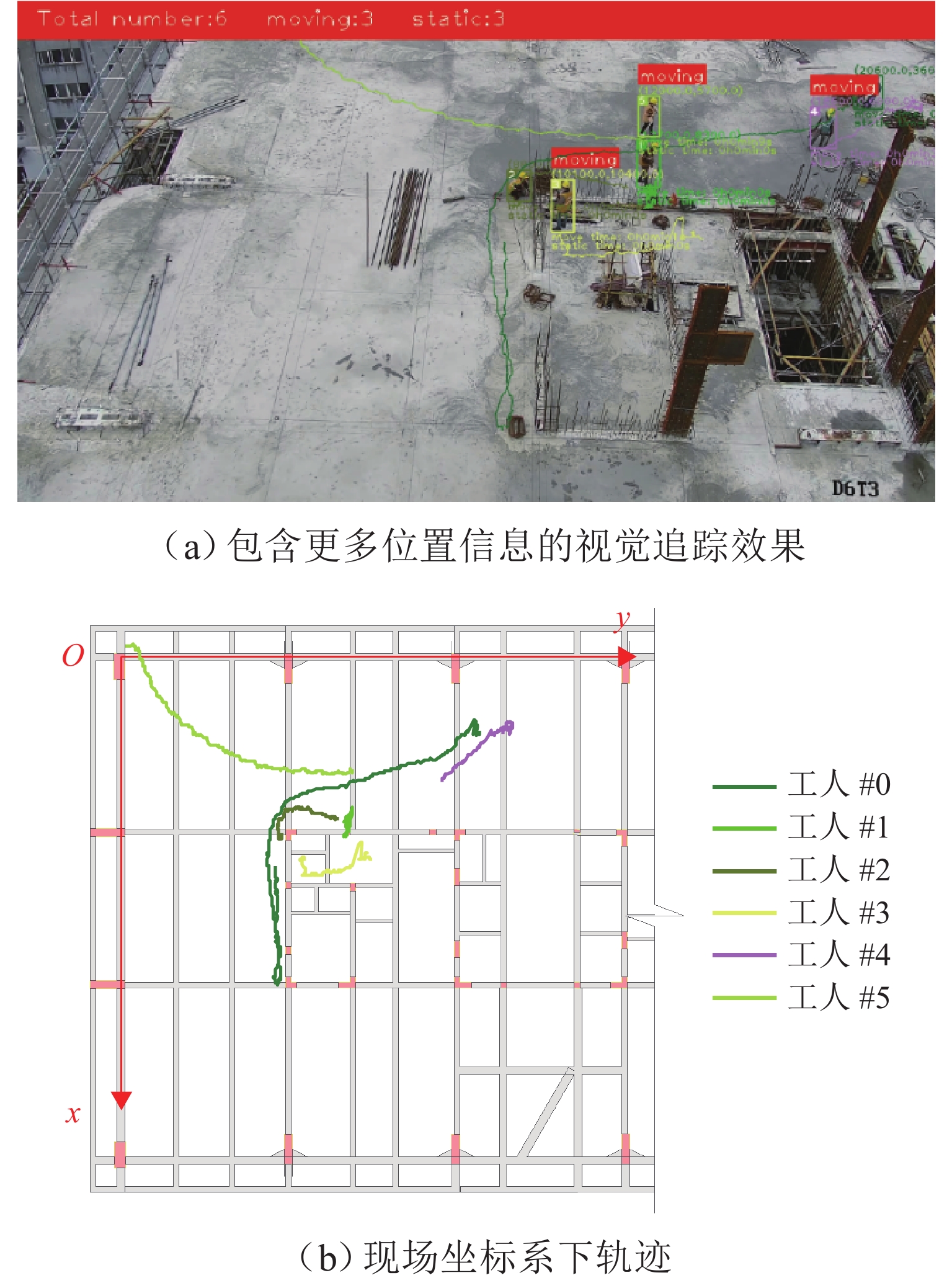


 点击查看大图
点击查看大图
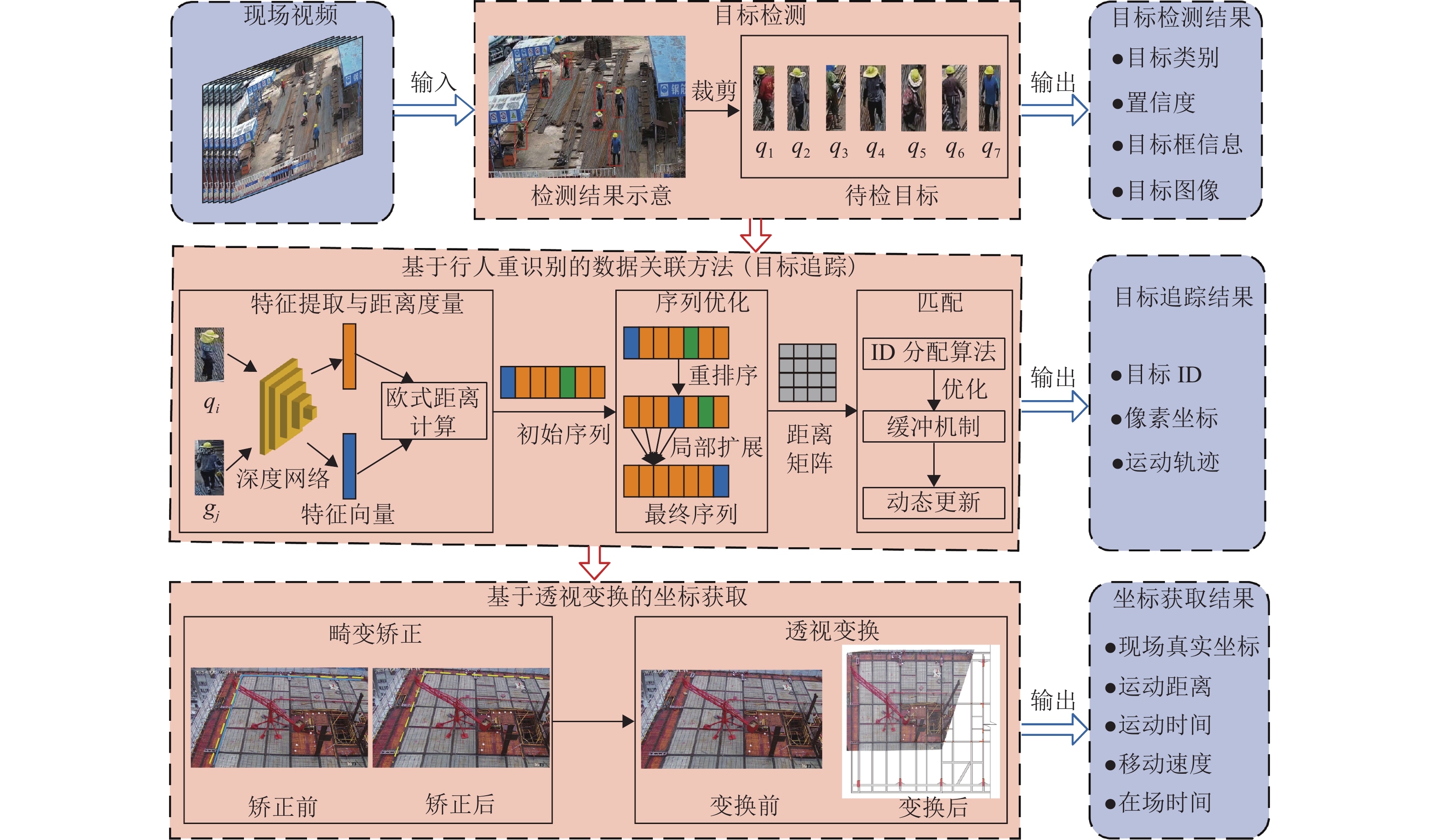
计量
- 文章访问数: 321
- HTML全文浏览量: 148
- PDF下载量: 41
- 被引次数: 0