

Susceptibility Assessment of Collapses and Landslides Based on Cluster and Random Forest Coupled Model
-
摘要:
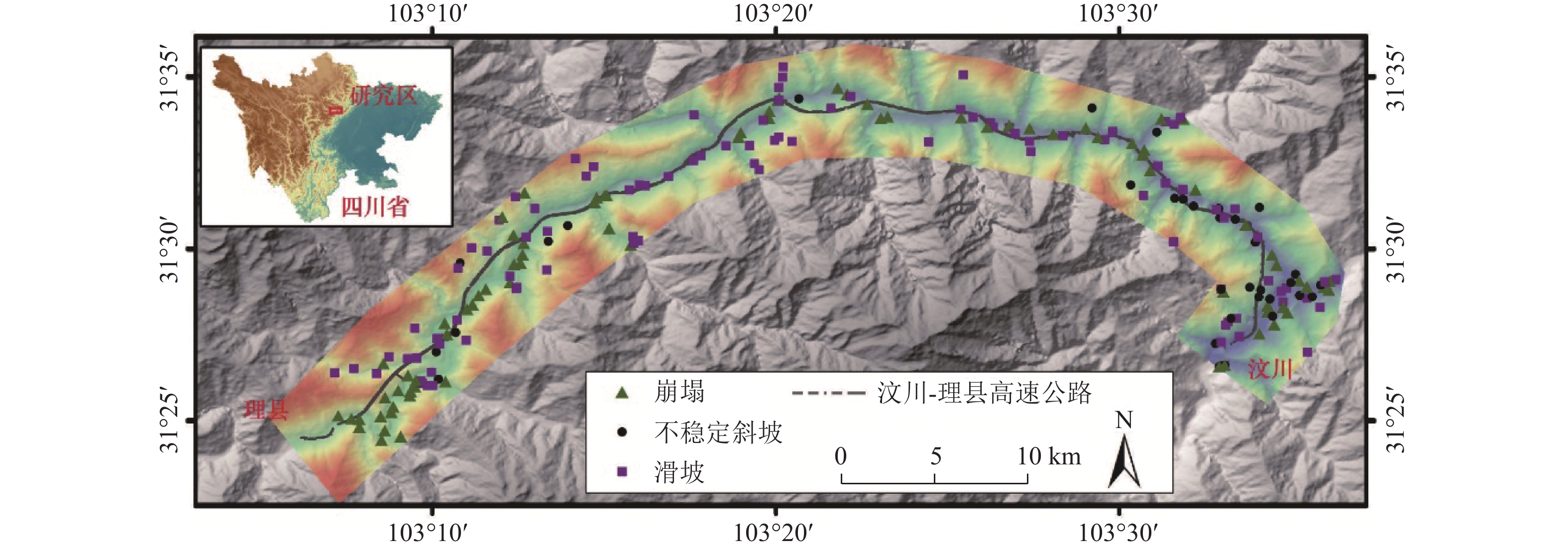
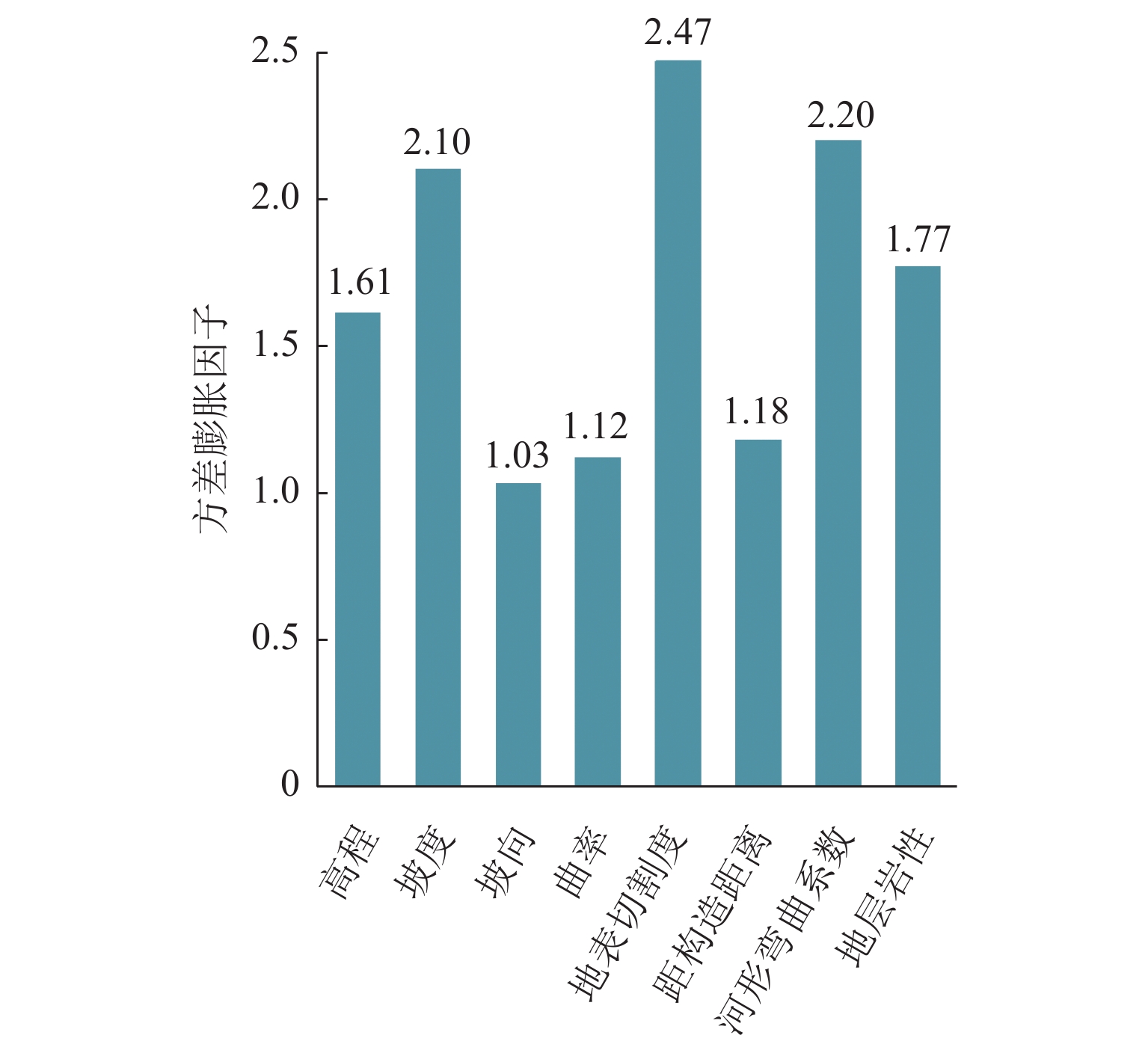
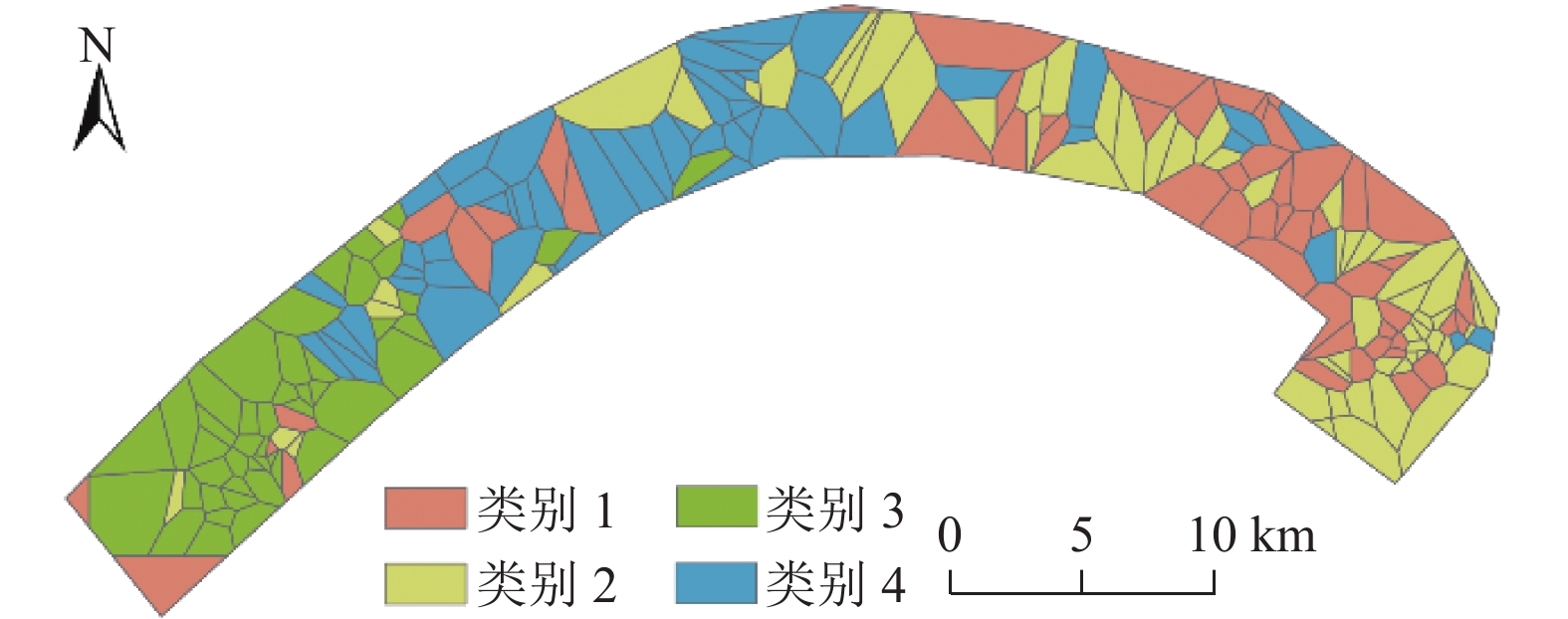
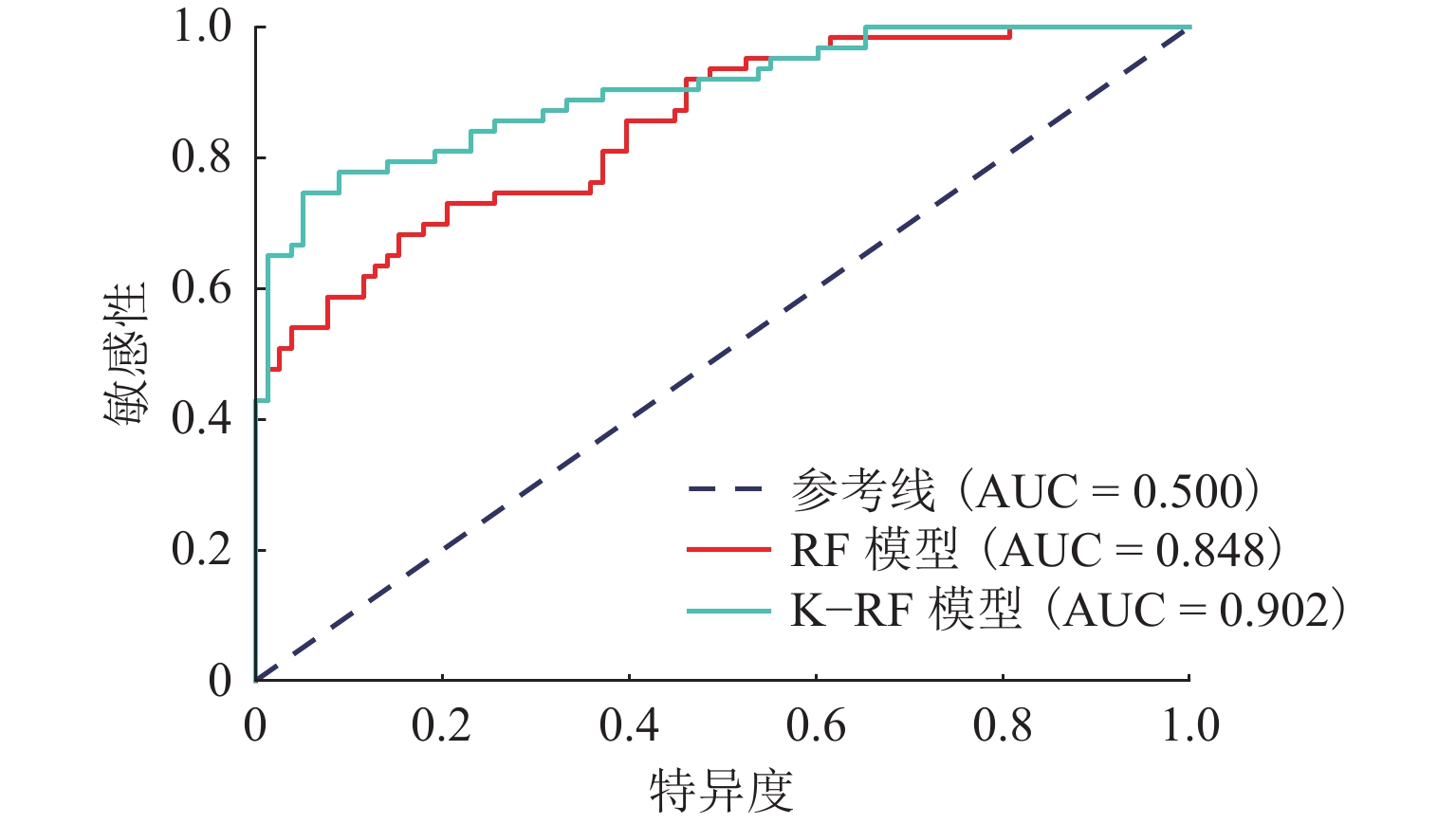
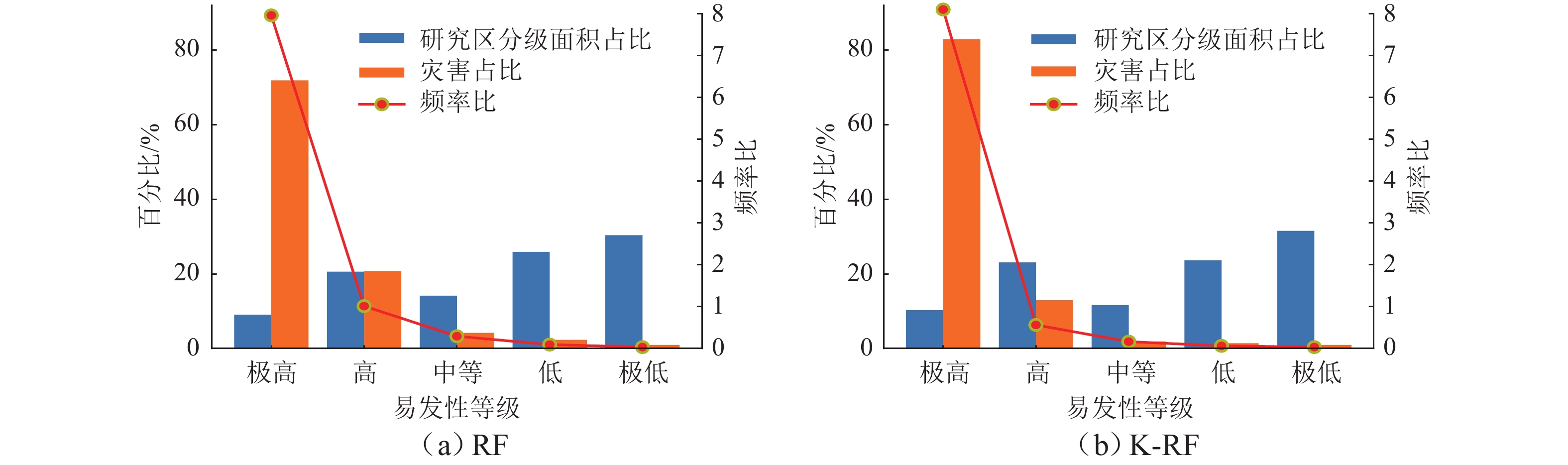
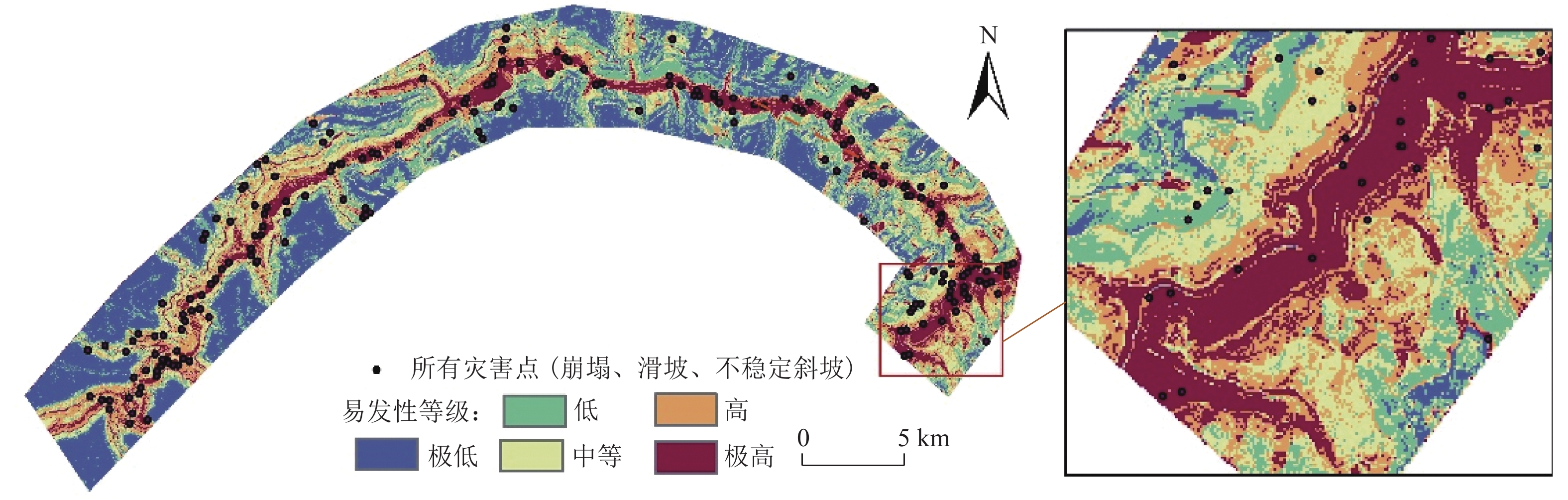
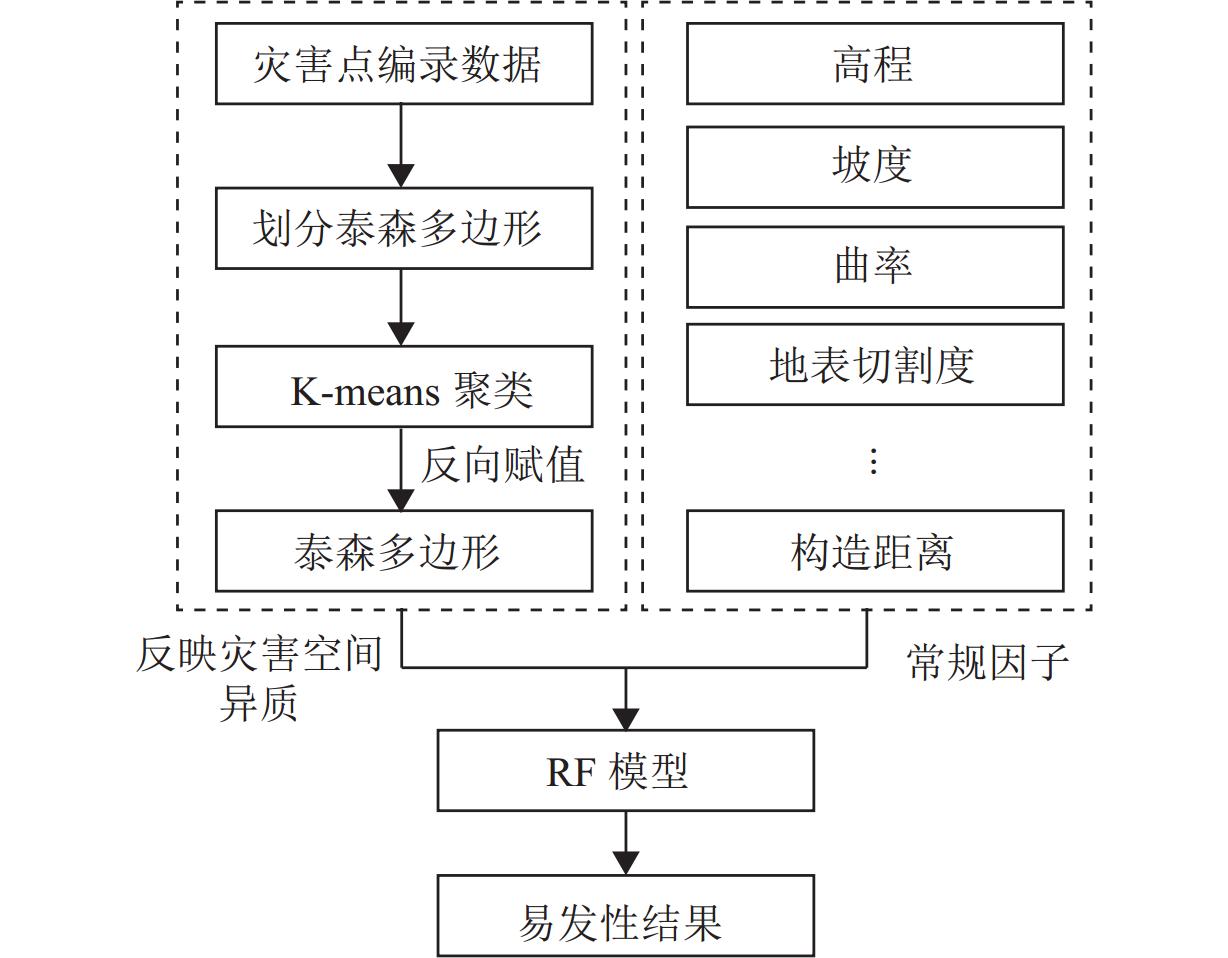
灾害易发性评估通常是基于灾害空间分布特征进行概率建模,然而灾害本身存在空间异质性. 本文以汶马高速汶川至理县段沿线崩滑灾害为例,为解决灾害的空间异质性问题,利用K-means算法将研究区灾害威胁对象(人员、财产)及危险程度(损毁房屋面积、损毁道路长度)进行空间聚类并赋予研究区不同聚类属性;从水文、地质、地貌条件等方面综合选取坡度、高程、坡向、曲率、地表切割度、河型弯曲系数、距构造带距离、岸坡坡体结构和地层岩性9个因子,将样本划分为70%的训练数据、30%的测试数据,对比K-RF模型与传统RF模型在易发性评估中的性能,以期为高速公路的运营安全及灾害防治提供理论支撑. 结果表明:K-RF模型极高易发区共包含82.95%灾害点,相较于单一RF模型取得了更好的评价结果(AUC值提高5.4%);采用聚类的方法解决灾害空间异质性是可行的,但本文局限性在于未能从灾害本身反映灾害空间异质性,耦合模型结果本质上是易发性和易损性的综合反映.
Abstract:Hazard susceptibility assessment is generally a probabilistic modeling based on the spatial distribution characteristics of hazards, but the hazards have spatial heterogeneity. In order to solve the spatial heterogeneity of hazards, the collapses and landslides along the Wenchuan−Lixian section in the Wenchuan−Maerkang Expressway were studied. By using the K-means algorithm, the hazard-threaten objects (people and property) and risk degree (damaged house area and damaged road length) in the study area were spatially clustered, and different clustering attributes were assigned to the study area. Then, nine factors including slope angle, elevation, slope aspect, curvature, surface cutting degree, river curvature coefficient, distance from the tectonic zone, bank slope structure, and formation lithology were selected in terms of hydrology, geology, and geomorphic conditions. The samples were divided into 70% training data and 30% test data. The performance of the K-RF model and the traditional random forest (RF) model in susceptibility assessment was compared to provide theoretical support for operation safety and hazard prevention of expressways. The results show that the K-RF model contains a total of 82.95% of the hazard points in the areas with extremely high susceptibility, which has better assessment results than the single RF model (with AUC value increased by 5.4%). Therefore, it is feasible to use clustering to solve the spatial heterogeneity of hazards. However, the research limitation is that it fails to reflect the spatial heterogeneity of hazards from the hazard itself. The coupled model is a comprehensive reflection of susceptibility and vulnerability in essence.
-
Key words:
- hazard /
- machine learning /
- susceptibility /
- spatial heterogeneity
-
表 1 聚类结果
Table 1. Clustering results
类别 灾害数量/处 平均威
胁人员
数量/人平均威胁财产/万元 平均损
毁房屋
面积/m2平均损
毁道路
长度/m1 53 95 337.2 8.90 0 2 65 50 164.6 1.80 0 3 46 36 113.5 0.43 0 4 53 59 80.4 1.38 10.2  下载: 导出CSV
下载: 导出CSV
表 2 验证指标计算结果
Table 2. Calculation results of validation indicators
模型 Pre Acc R AUC RF 0.681 0.730 0.746 0.848 K-RF 0.726 0.787 0.841 0.902
下载: 导出CSV
表 3 易发性分级统计结果
Table 3. Statistical results of susceptibility levels
模型 易发性等级 分区面积/km2 灾害点个数/个 研究区分级面积占比/% 灾害占比/% 频率比 K-RF 极高 35.70 180 10.24 82.95 8.10 高 80.37 28 23.05 12.90 0.56 中等 40.27 4 11.55 1.84 0.16 低 82.50 3 23.66 1.38 0.06 极低 109.90 2 31.52 0.92 0.03 RF 极高 31.50 156 9.03 71.89 7.96 高 71.74 45 20.57 20.74 1.01 中等 49.27 9 14.13 4.15 0.29 低 90.30 5 25.90 2.30 0.09 极低 105.90 2 30.37 0.92 0.03
下载: 导出CSV
-
[1] FELL R, COROMINAS J, BONNARD C, et al. Guidelines for landslide susceptibility, hazard and risk zoning for land use planning[J]. Engineering Geology, 2008, 102(3/4): 85-98. [2] NHU V H, HOANG N D, NGUYEN H, et al. Effectiveness assessment of Keras based deep learning with different robust optimization algorithms for shallow landslide susceptibility mapping at tropical area[J]. Catena, 2020, 188: 104458.1-104458.13. [3] 李利峰,杨华,张娟,等. 基于人工神经网络的区域滑坡预测研究[J]. 气象与环境科学,2020,43(3): 65-70.LI Lifeng, YANG Hua, ZHANG Juan, et al. Research on regional landslide prediction based on artificial neural network[J]. Meteorological and Environmental Sciences, 2020, 43(3): 65-70. [4] 常晁瑜,薄景山,李孝波,等. 地震黄土滑坡滑距预测的BP神经网络模型[J]. 地震工程学报,2020,42(6): 1609-1614. doi: 10.3969/j.issn.1000-0844.2020.06.1609CHANG Chaoyu, BO Jingshan, LI Xiaobo, et al. A BP neural network model for forecasting sliding distance of seismic loess landslides[J]. China Earthquake Engineering Journal, 2020, 42(6): 1609-1614. doi: 10.3969/j.issn.1000-0844.2020.06.1609 [5] 许冲,徐锡伟. 逻辑回归模型在玉树地震滑坡危险性评价中的应用与检验[J]. 工程地质学报,2012,20(3): 326-333. doi: 10.3969/j.issn.1004-9665.2012.03.004XU Chong, XU Xiwei. Logistic regression model and its validation for hazard mapping of landslides triggered by Yushu earthquake[J]. Journal of Engineering Geology, 2012, 20(3): 326-333. doi: 10.3969/j.issn.1004-9665.2012.03.004 [6] 吴博,赵法锁,贺子光,等. 基于BA-LSSVM模型的黄土滑坡致灾范围预测[J]. 中国地质灾害与防治学报,2020,31(5): 1-6.WU Bo, ZHAO Fasuo, HE Ziguang, et al. Prediction of the disaster area of loess landslide based on least square support vector machine optimized by bat algorithm[J]. The Chinese Journal of Geological Hazard and Control, 2020, 31(5): 1-6. [7] XI C J, HAN M, HU X W, et al. Effectiveness of Newmark-based sampling strategy for coseismic landslide susceptibility mapping using deep learning, support vector machine, and logistic regression[J]. Bulletin of Engineering Geology and the Environment, 2022, 81(5): 174-196. doi: 10.1007/s10064-022-02664-5 [8] 文海家,胡东萍,王桂林. 汶川县地震滑坡易发性LR与NN评价比较研究[J]. 土木工程学报,2014,47(增1): 17-23.WEN Haijia, HU Dongping, WANG Guilin. Comparative study on LR and NN evaluation of earthquake landslide susceptibility in Wenchuan County[J]. China Civil Engineering Journal, 2014, 47(S1): 17-23. [9] YAO X, THAM L G, DAI F C. Landslide susceptibility mapping based on Support Vector Machine: a case study on natural slopes of Hong Kong, China[J]. Geomorphology, 2008, 101(4): 572-582. doi: 10.1016/j.geomorph.2008.02.011 [10] 许冲,徐锡伟. 基于不同核函数的2010年玉树地震滑坡空间预测模型研究[J]. 地球物理学报,2012,55(9): 2994-3005. doi: 10.6038/j.issn.0001-5733.2012.09.018XU Chong, XU Xiwei. The 2010 Yushu earthquake triggered landslides spatial prediction models based on several kernel function types[J]. Chinese Journal of Geophysics, 2012, 55(9): 2994-3005. doi: 10.6038/j.issn.0001-5733.2012.09.018 [11] TRUONG X, MITAMURA M, KONO Y, et al. Enhancing prediction performance of landslide susceptibility model using hybrid machine learning approach of bagging ensemble and logistic model tree[J]. Applied Sciences, 2018, 8(7): 1046.1-1046.22. [12] BREIMAN L. Random forests[J]. Machine Learning, 2001, 45: 5-32. doi: 10.1023/A:1010933404324 [13] FREUND Y, SCHAPIRE R E. A decision-theoretic generalization of on-line learning and an application to boosting[J]. Journal of Computer and System Sciences, 1997, 55(1): 119-139. doi: 10.1006/jcss.1997.1504 [14] FRIEDMAN J H. Greedy function approximation: a gradient boosting machine[J]. The Annals of Statistics, 2001, 29(5): 1189-1232. doi: 10.1214/aos/1013203450 [15] WANG Y M, FENG L W, LI S J, et al. A hybrid model considering spatial heterogeneity for landslide susceptibility mapping in Zhejiang Province, China[J]. Catena, 2020, 188: 104425.1-104425.13. [16] DENG M, YANG W T, LIU Q L, et al. Heterogeneous space–time artificial neural networks for space–time series prediction[J]. Transactions in GIS, 2018, 22(1): 183-201. doi: 10.1111/tgis.12302 [17] 黄发明,殷坤龙,蒋水华,等. 基于聚类分析和支持向量机的滑坡易发性评价[J]. 岩石力学与工程学报,2018,37(1): 156-167.HUANG Faming, YIN Kunlong, JIANG Shuihua, et al. Landslide susceptibility assessment based on clustering analysis and support vector machine[J]. Chinese Journal of Rock Mechanics and Engineering, 2018, 37(1): 156-167. [18] 兰恒星,伍法权,王思敬. 基于GIS的滑坡CF多元回归模型及其应用[J]. 山地学报,2002,20(6): 732-737. doi: 10.3969/j.issn.1008-2786.2002.06.015LAN Hengxing, WU Faquan, WANG Sijing. GIS based landslide CF multi-variable regression model and its application[J]. Journal of Mountain Research, 2002, 20(6): 732-737. doi: 10.3969/j.issn.1008-2786.2002.06.015 [19] 陈晓利,冉洪流,祁生文. 1976年龙陵地震诱发滑坡的影响因子敏感性分析[J]. 北京大学学报(自然科学版),2009,45(1): 104-110. doi: 10.3321/j.issn:0479-8023.2009.01.016CHEN Xiaoli, RAN Hongliu, QI Shengwen. Triggering factors susceptibility of earthquake-induced landslides in 1976 Longling earthquake[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2009, 45(1): 104-110. doi: 10.3321/j.issn:0479-8023.2009.01.016 [20] 许冲,戴福初,姚鑫,等. 基于GIS的汶川地震滑坡灾害影响因子确定性系数分析[J]. 岩石力学与工程学报,2010,29(增1): 2972-2981.XU Chong, DAI Fuchu, YAO Xin, et al. Analysis of deterministic coefficient of influencing factors of Wenchuan earthquake landslide disaster based on GIS[J]. Chinese Journal of Rock Mechanics and Engineering, 2010, 29(S1): 2972-2981. [21] 陈绪坚,陈清扬. 黄河下游河型转换及弯曲变化机理[J]. 泥沙研究,2013(1): 1-6. doi: 10.3969/j.issn.0468-155X.2013.01.001CHEN Xujian, CHEN Qingyang. Theory of river pattern transformation and change of channel sinuosity ratio in Lower Yellow River[J]. Journal of Sediment Research, 2013(1): 1-6. doi: 10.3969/j.issn.0468-155X.2013.01.001 [22] CHEN Z, LIANG S Y, KE Y T, et al. Landslide susceptibility assessment using different slope units based on the evidential belief function model[J]. Geocarto International, 2020, 35(15): 1641-1664. doi: 10.1080/10106049.2019.1582716 [23] WEN H, WU X Y, LIAO X, et al. Application of machine learning methods for snow avalanche susceptibility mapping in the Parlung Tsangpo Catchment, southeastern Qinghai−Tibet Plateau[J]. Cold Regions Science and Technology, 2022, 198: 103535.1-103535.12. -

 下载:
下载:



 点击查看大图
点击查看大图
计量
- 文章访问数: 546
- HTML全文浏览量: 279
- PDF下载量: 98
- 被引次数: 0