

Refined Traffic Flow Model Based on Cellular Automaton Under Cooperative Vehicle Infrastructure System
-
摘要:
针对经典元胞自动机交通流模型中元胞尺寸难以准确表达车辆间位置关系的问题,提出通过细化元胞尺寸对基于元胞自动机的双车道模型(symmetric two-lane cellular automaton,STCA)进行改进的方案. 首先,分析城市道路双车道环境下的位置、速度、加速度以及车辆间的相互影响,并基于元胞自动机搭建相应数值模型,特别地,针对现有基于元胞自动机的交通流模型与实际车辆行驶现象不符的问题,改进其道路尺寸和元胞表征形式,建立精细化元胞自动机车道模型;其次,结合实际车路环境,对STCA模型中的道路堵塞、换道等行为重新定义,并将车道规则与精细化车道模型相结合,建立新的交通流模型STCA-CH;最后,与STCA、STCA-I、STCA-S、STCA-M模型相对比,通过分析在不同车辆密度下的平均速度、平均流量、换道频率及时空图,验证STCA-CH模型有效性. 结果表明,STCA-CH模型的换道频率相较于STCA-M模型提高约21.14%,最大平均流量较STCA-I、STCA-S和STCA-M模型分别提升约25.76%、11.30%和3.75%.
Abstract:The cell size in the classical cellular automaton-based traffic flow model makes it difficult to express the position relationship of vehicles accurately. Therefore, a scheme to improve the symmetric two-lane cellular automaton (STCA) model by refining the cell size was presented. Firstly, the position, speed, acceleration, and interaction of vehicles in the urban road two-lane environment were analyzed, and the numerical model of these characteristics was built based on the cellular automaton. Especially, the road size and the cellular representation form in the model were improved to solve the problem that the existing traffic flow model based on cellular automaton does not conform to the vehicle driving phenomenon on the actual road. Secondly, according to the real vehicle infrastructure environment, road congestion, lane changing, and other behaviors in the STCA model were redefined, and the lane rules were combined with the refined lane model. A new traffic flow model, namely STCA-CH, was established. Finally, the model was compared with STCA, STCA-I, STCA-S, and STCA-M models, and the validity of the STCA-CH model was verified by analyzing the average speed, average flow, lane changing frequency, and space-time diagram under different vehicle densities. The results show that the lane changing frequency of the STCA-CH model is about 21.14% higher than that of the STCA-M model, and the maximum average flow is about 25.76%, 11.30%, and 3.75% higher than that of the STCA-I, STCA-S, and STCA-M models respectively.
-
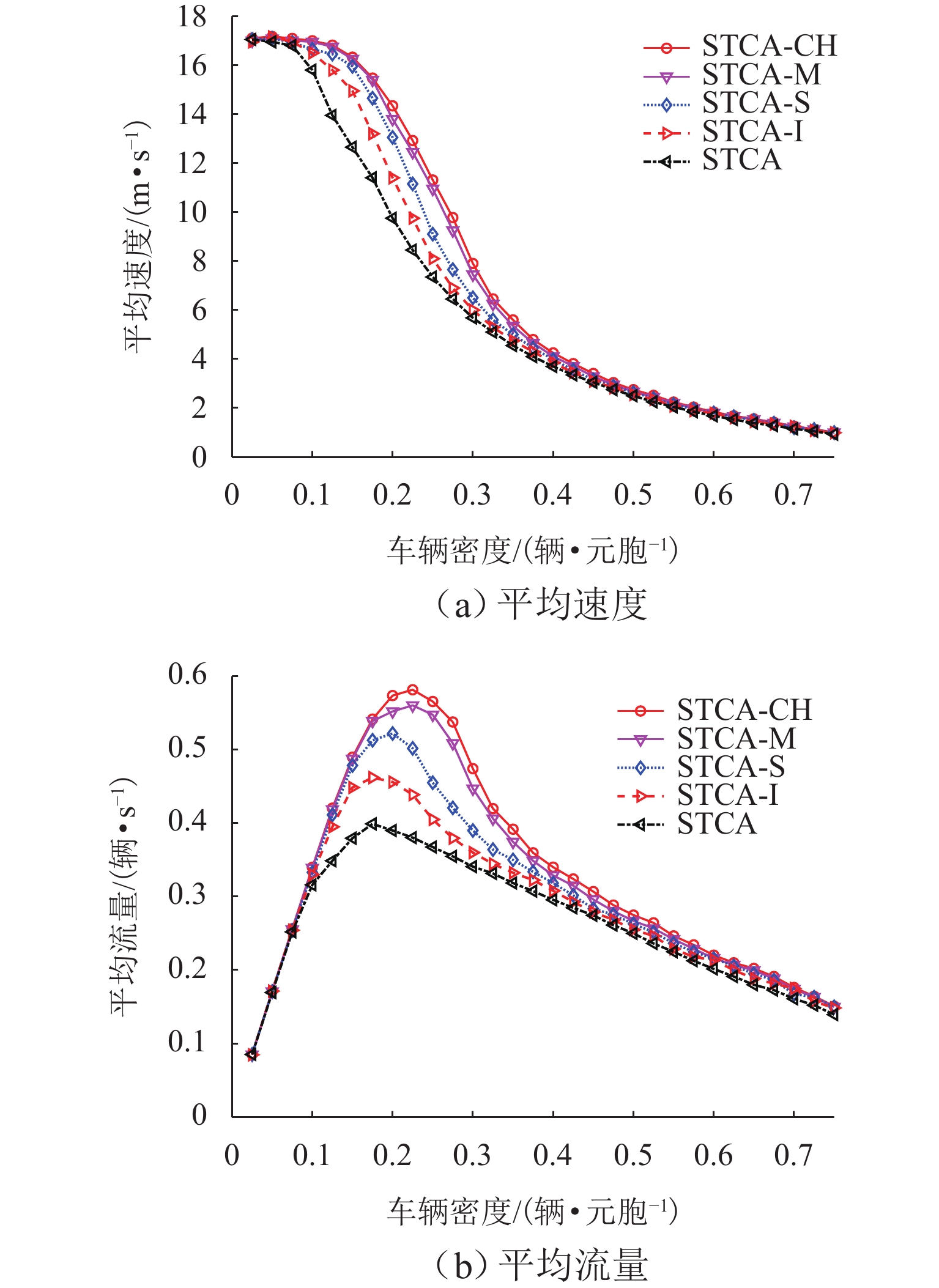
图 4 5种模型在不同车辆密度下的平均速度、平均流量对比
Figure 4. Comparison of average speed and average flow of five models under different vehicle densities
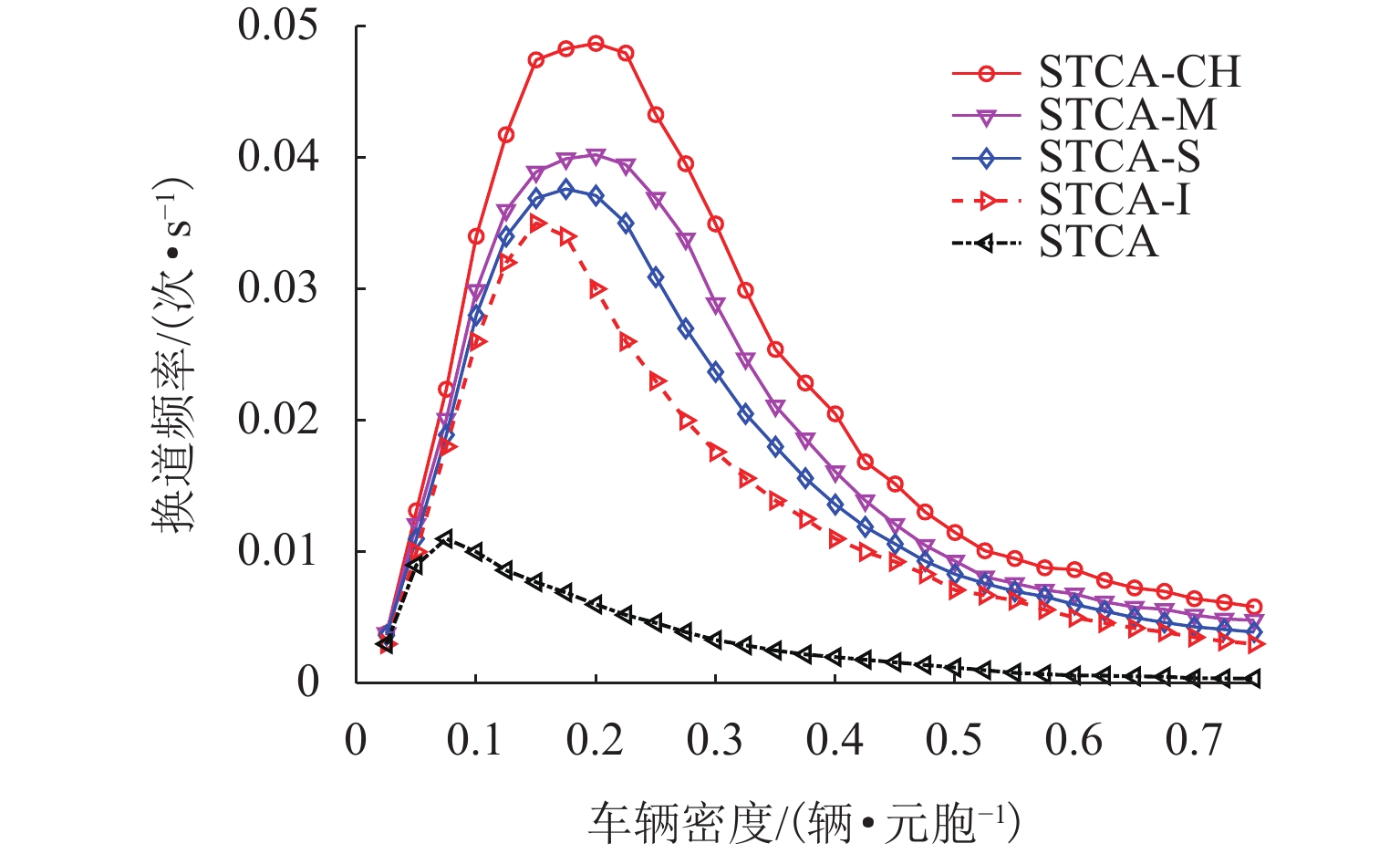
图 5 5种模型在不同车辆密度下的换道频率对比
Figure 5. Comparison of lane changing frequencies of five models under different vehicle densities
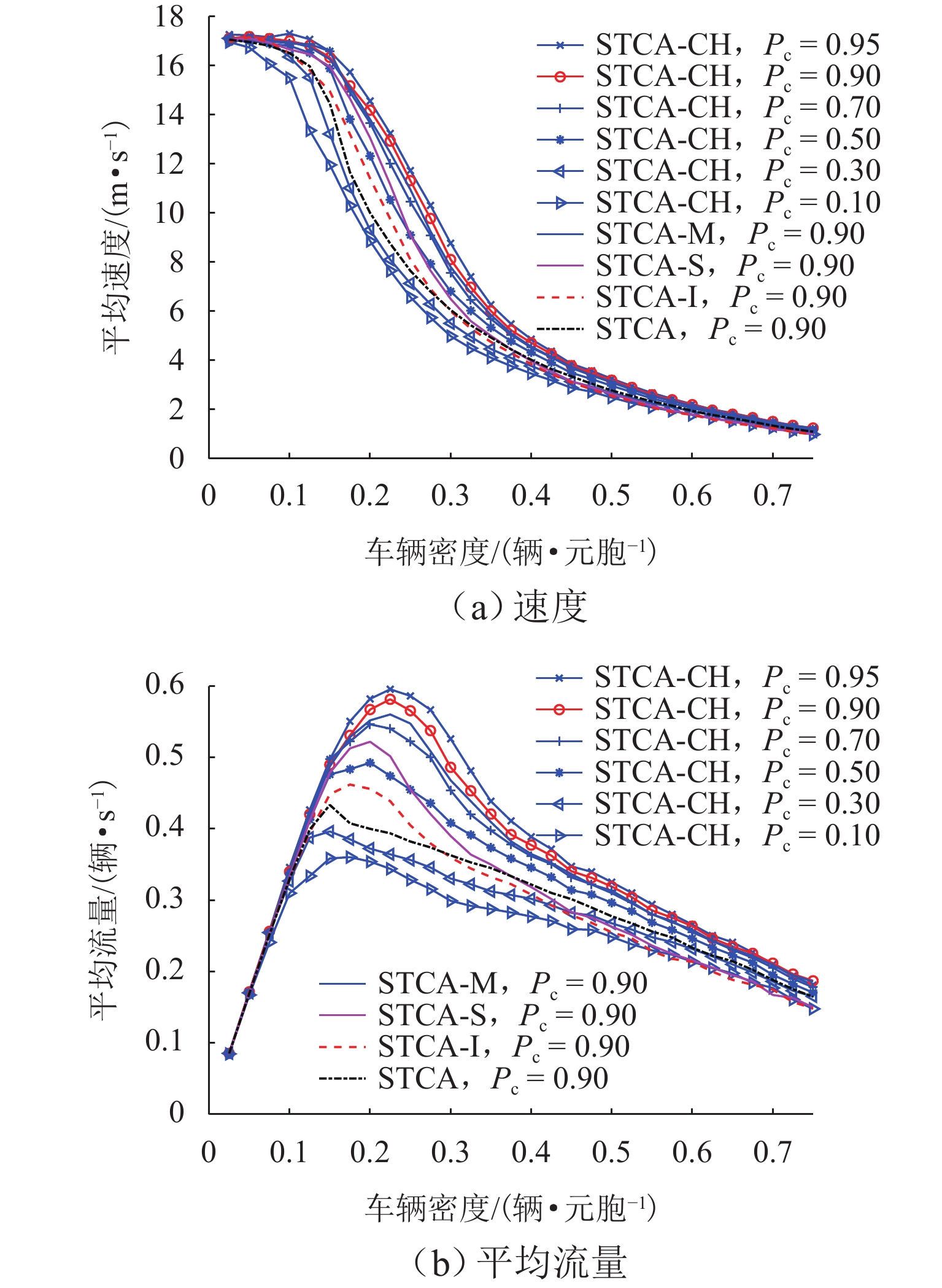
图 6 不同遵守率下双车道模型的平均速度、平均流量对比
Figure 6. Comparison of average speed and average flow for two-lane model under different compliance rates
表 1 5种元胞自动机交通流模型的时空图对比
Table 1. Comparison of space-time diagrams of five kinds of cellular automaton-based traffic flow models
车道 SCTA STCA-I STCA-S STCA-M STCA-CH 左车道 




右车道 




 下载: 导出CSV
下载: 导出CSV
-
[1] 郭洁. 智慧城市建设对城市交通拥堵改善的影响研究[D]. 成都:电子科技大学,2020. [2] 崔雪薇. 车路协同创未来:智慧公路技术在车路协同中的应用探讨[J]. 中国交通信息化,2018(12): 22-26. [3] 刘睿健. “ 协同” 有道,“ 无人” 驾成!——车路协同自动驾驶系统发展漫谈[J]. 中国交通信息化,2020(10): 18-25. [4] 《中国公路学报》编辑部. 中国交通工程学术研究综述 • 2016[J]. 中国公路学报,2016,29(6): 1-161.Editorial Department of China Journal of Highway and Transporl. Review on China’s traffic engineering research progress: 2016[J]. China Journal of Highway and Transport, 2016, 29(6): 1-161. [5] 杨涛,马玉琴,刘梦,等. 智能网联环境下信号交叉口车辆轨迹重构模型[J]. 西南交通大学学报,2024,59(5): 1148-1157.YANG Tao, MA Yugin, LIU Meng, et al. Vehicle trajectory reconstruction model of signalized intersection in connected automated environments[J]. Joural of Southwest Jiaotong University, 2024, 59(5): 1148-1157. [6] LI L H, GAN J, ZHOU K, et al. A novel lane-changing model of connected and automated vehicles: using the safety potential field theory[J]. Physica A: Statistical Mechanics and Its Applications, 2020, 559: 125039.1-125039.14. [7] WOLFRAM S. Theory and applications of cellular automata[M]. Singapore: World Scientific, 1986. [8] NAGEL K, SCHRECKENBERG M. A cellular automaton model for freeway traffic[J]. Journal De Physique Ⅰ, 1992, 2(12): 2221-2229. doi: 10.1051/jp2:1992262 [9] CHOWDHURY D, WOLF D E, SCHRECKENBERG M. Particle hopping models for two-lane traffic with two kinds of vehicles: effects of lane-changing rules[J]. Physica A: Statistical Mechanics and Its Applications, 1997, 235(3): 417-439. [10] 王永明,周磊山,吕永波. 基于元胞自动机交通流模型的车辆换道规则[J]. 中国公路学报,2008,21(1): 89-93.WANG Yongming, ZHOU Leishan, LYU Yongbo. Lane changing rules based on cellular automaton traffic flow model[J]. China Journal of Highway and Transport, 2008, 21(1): 89-93. [11] 李珣,曲仕茹,夏余. 车路协同环境下多车道车辆的协同换道规则[J]. 中国公路学报,2014,27(8): 97-104.LI Xun, QU Shiru, XIA Yu. Cooperative lane-changing rules on multilane under condition of cooperative vehicle and infrastructure system[J]. China Journal of Highway and Transport, 2014, 27(8): 97-104. [12] 李珣,马文哲,赵征凡,等. 车路协同下基于行车指引的改进STCA双车道换道模型[J]. 东南大学学报(自然科学版),2020,50(6): 1134-1142.LI Xun, MA Wenzhe, ZHAO Zhengfan, et al. Improved STCA lane changing model for two-lane road based on driving guidance under CVIS[J]. Journal of Southeast University (Natural Science Edition), 2020, 50(6): 1134-1142. [13] WU W J, SUN R C, NI A N, et al. Simulation and evaluation of speed and lane-changing advisory of CAVS at work zones in heterogeneous traffic flow[J]. International Journal of Modern Physics B, 2020, 34(21): 2050201.1-2050201.21. [14] JIAN M Y, LI X J, CAO J X. Investigating model and impacts of lane-changing execution process based on CA model[J]. International Journal of Modern Physics C, 2020, 31(12): 2050171.1-2050171.18. [15] 李珣,赵征凡,刘瑶,等. 车路协同下带诱导车速的单车道改进NS模型[J]. 公路交通科技,2018,35(2): 101-108. -

 下载:
下载:
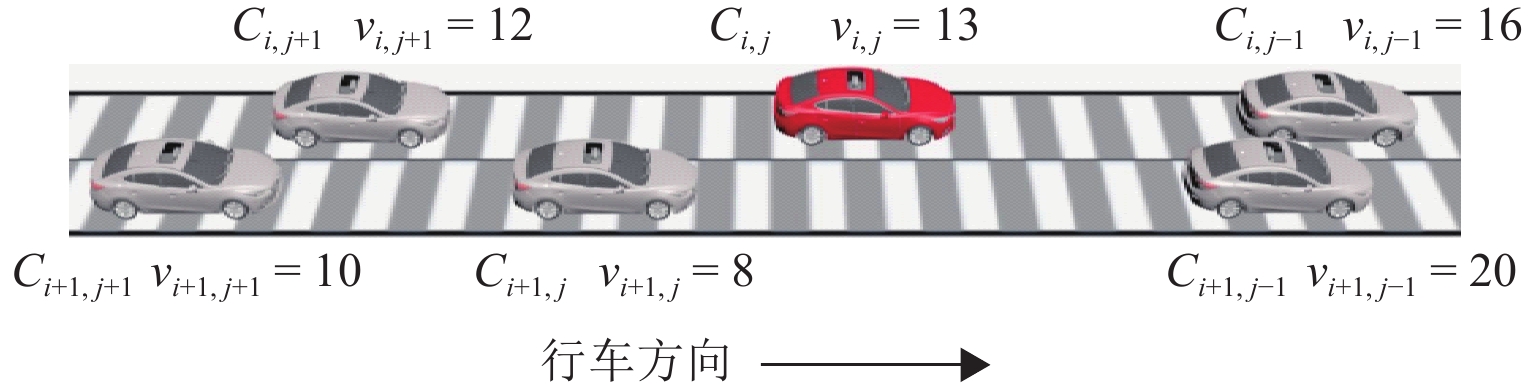
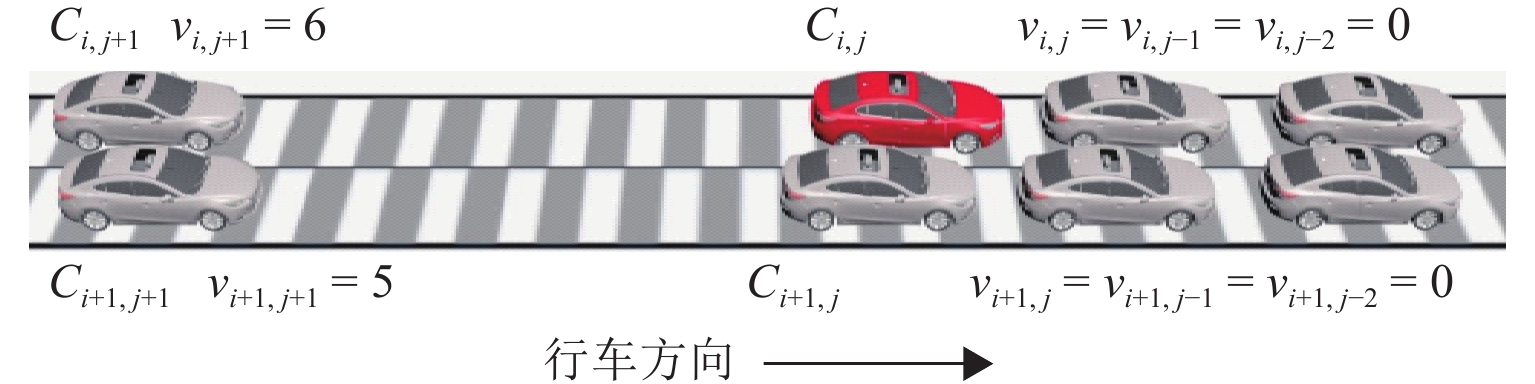

 点击查看大图
点击查看大图
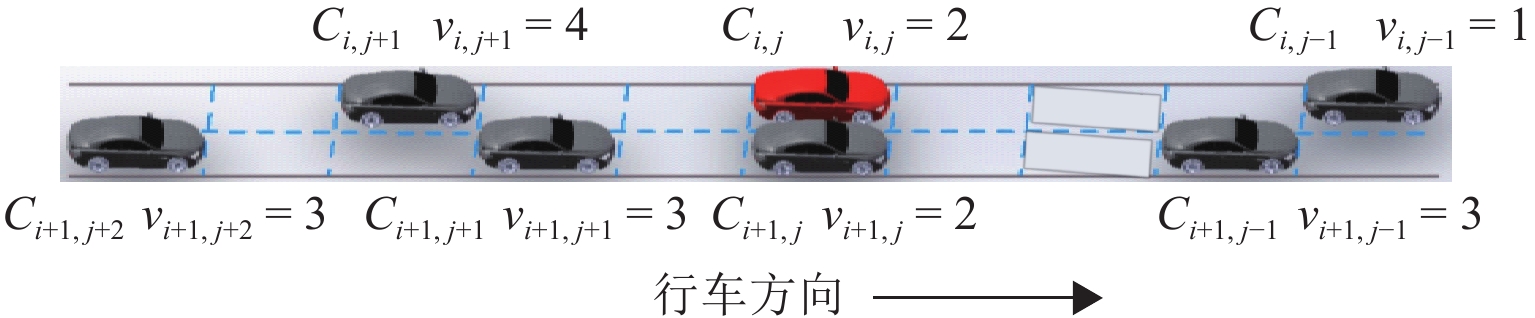
计量
- 文章访问数: 494
- HTML全文浏览量: 266
- PDF下载量: 74
- 被引次数: 0