

Knowledge Fusion Method of High-Speed Train Based on Knowledge Graph
-
摘要:
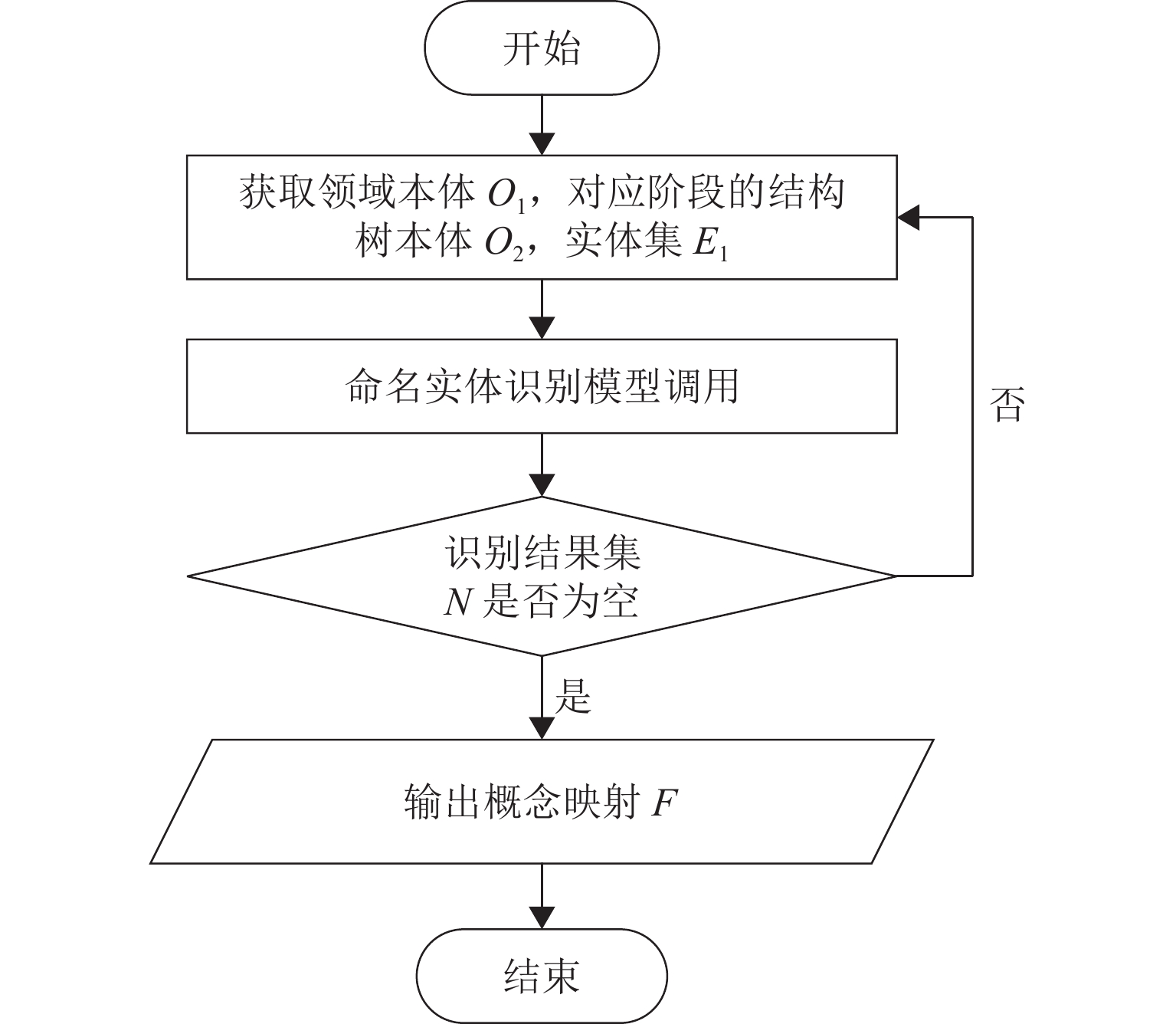
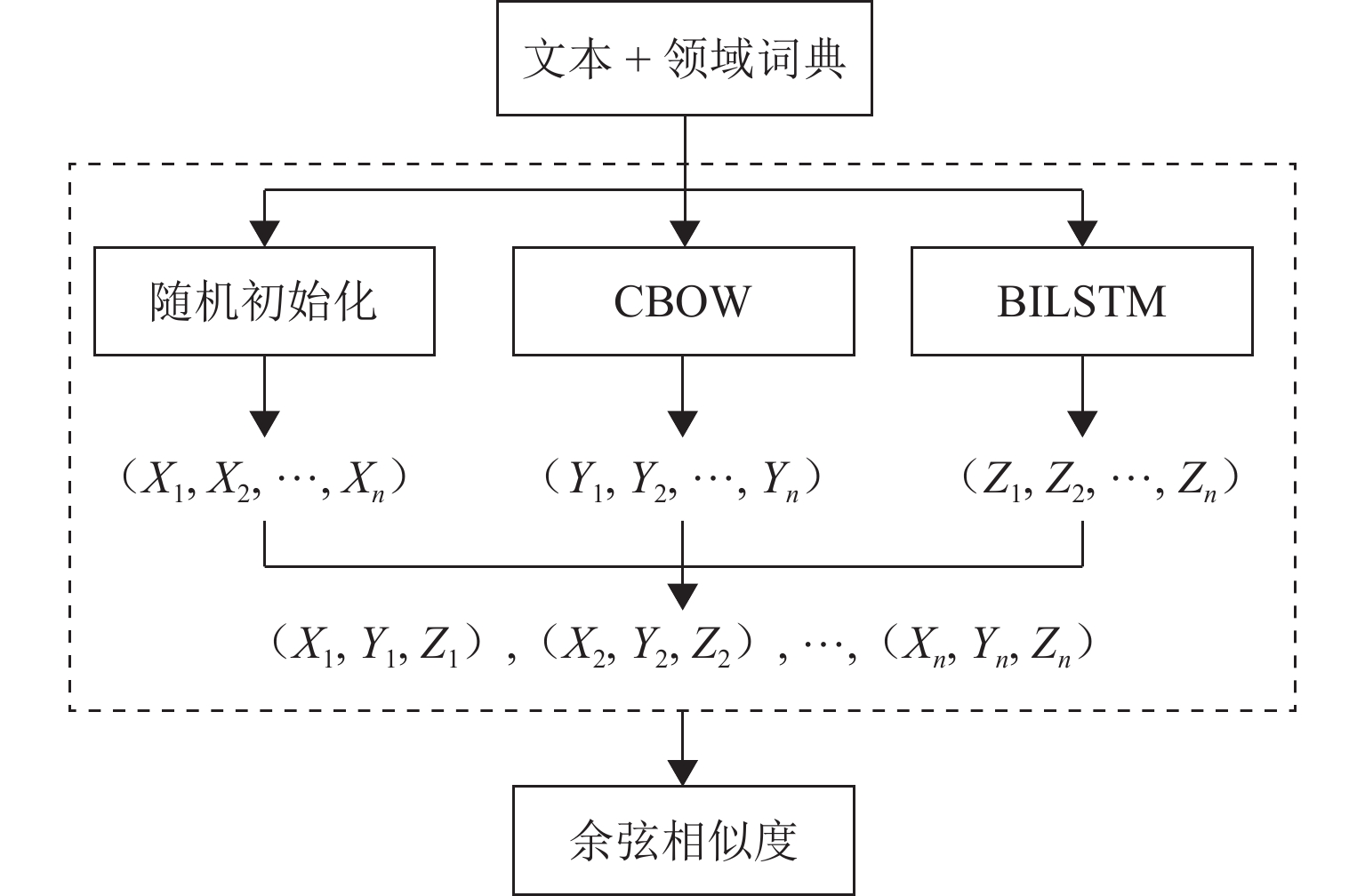
为解决高速列车各领域知识之间关联不明、难以检索和应用等问题,首先分析高速列车多源异构知识的组织形式,并结合高速列车产品结构树和阶段领域,构建高速列车领域知识图谱模式层和知识图谱;其次,通过双向编码变换器-双向长短期记忆网络-条件随机场(BERT-BILSTM-CRF)模型进行实体识别,得到阶段领域本体的映射;然后,将高速列车实体属性分为结构化和非结构化2类,并分别使用Levenshtein距离和连续词袋模型-双向长短期记忆网络(CBOW-BILSTM)模型计算相应属性的相似度,得到对齐实体对;最后,结合高速列车产品编码结构树进行映射融合,构建高速列车领域融合知识图谱. 应用本文方法对高速列车转向架进行实例验证的结果表明:在命名实体识别方面,基于BERT-BILSTM-CRF模型得到的实体识别准确率为91%;在实体对齐方面,采用Levenshtein 距离、CBOW-BILSTM模型计算实体相似度的准确率和召回率的调和平均数(F1值)分别为82%、83%.
Abstract:To address challenges of unclear correlation, intricate knowledge retrieval, and difficult knowledge application across diverse domains of high-speed trains, the organizational structure involving multi-source heterogeneous knowledge pertaining to high-speed trains was first analyzed, and a knowledge graph pattern layer and knowledge graph of the high-speed train domain was developed based on the product structure tree and stage domain of high-speed trains. Subsequently, the bidirectional encoder transformer-bidirectional long short-term memory network-conditional random field (BERT-BILSTM-CRF) model was employed for entity recognition, so as to establish the mapping of stage domain ontology. Then, the entity attributes of high-speed trains were categorized into structured and unstructured attributes. The Levenshtein distance and the continuous bag of words-bidirectional long short-term memory network (CBOW-BILSTM) model were utilized to calculate the similarity of corresponding attributes, resulting in aligned entity pairs. Ultimately, the knowledge fusion graph of high-speed train domain fusion was constructed by using the coding structure tree of high-speed train products for mapping and fusion. The proposed method was applied to high-speed train bogies for verification. The results reveal that in terms of named entity recognition, the entity recognition accuracy of the BERT-BILSTM-CRF model reaches 91%. In terms of entity alignment, the F1 values (the harmonic mean of accuracy and recall) of entity similarity calculated by the Levenshtein distance and the CBOW-BILSTM model are 82% and 83%, respectively.
-
Key words:
- high-speed train /
- knowledge graph /
- knowledge fusion /
- ontology mapping /
- entity alignment
-
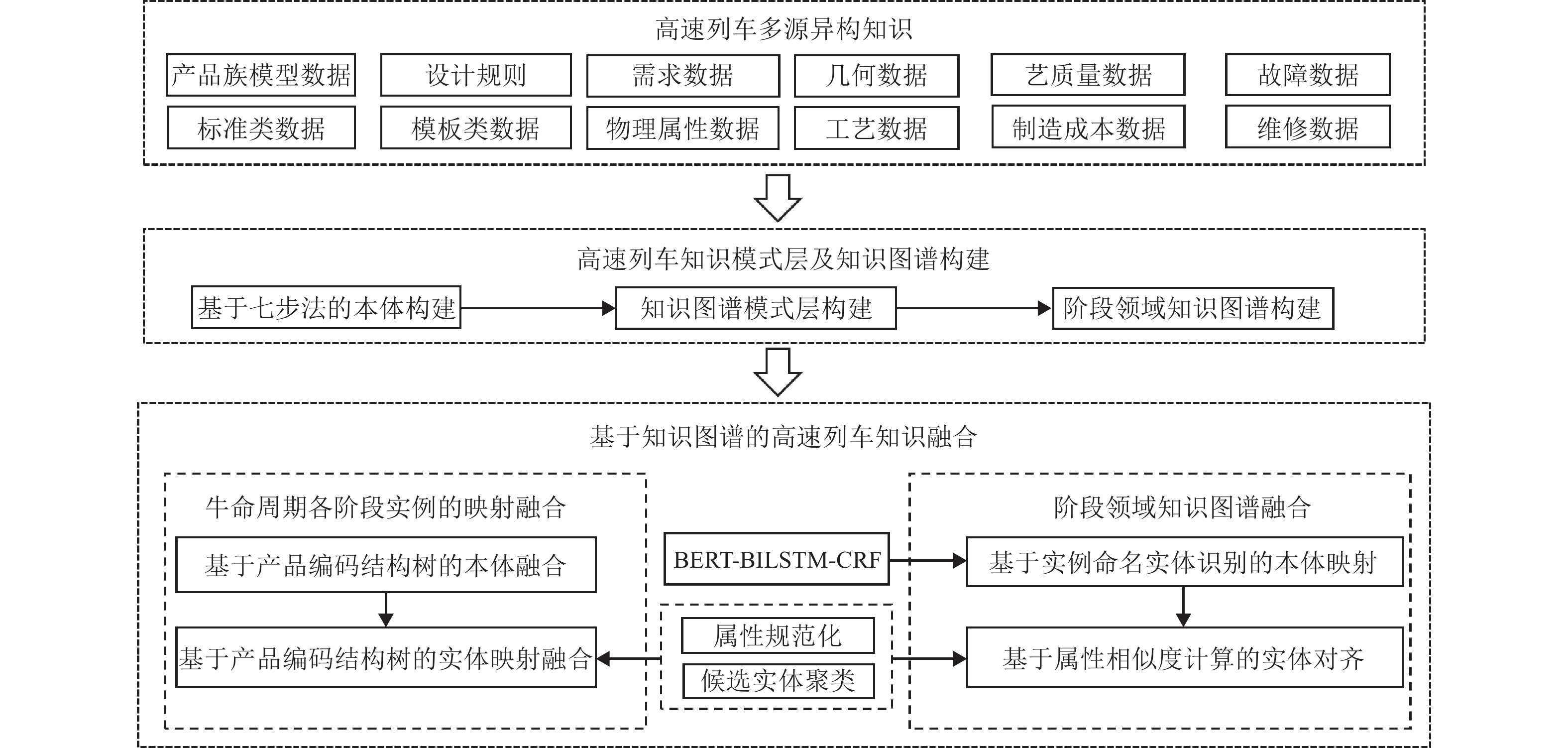
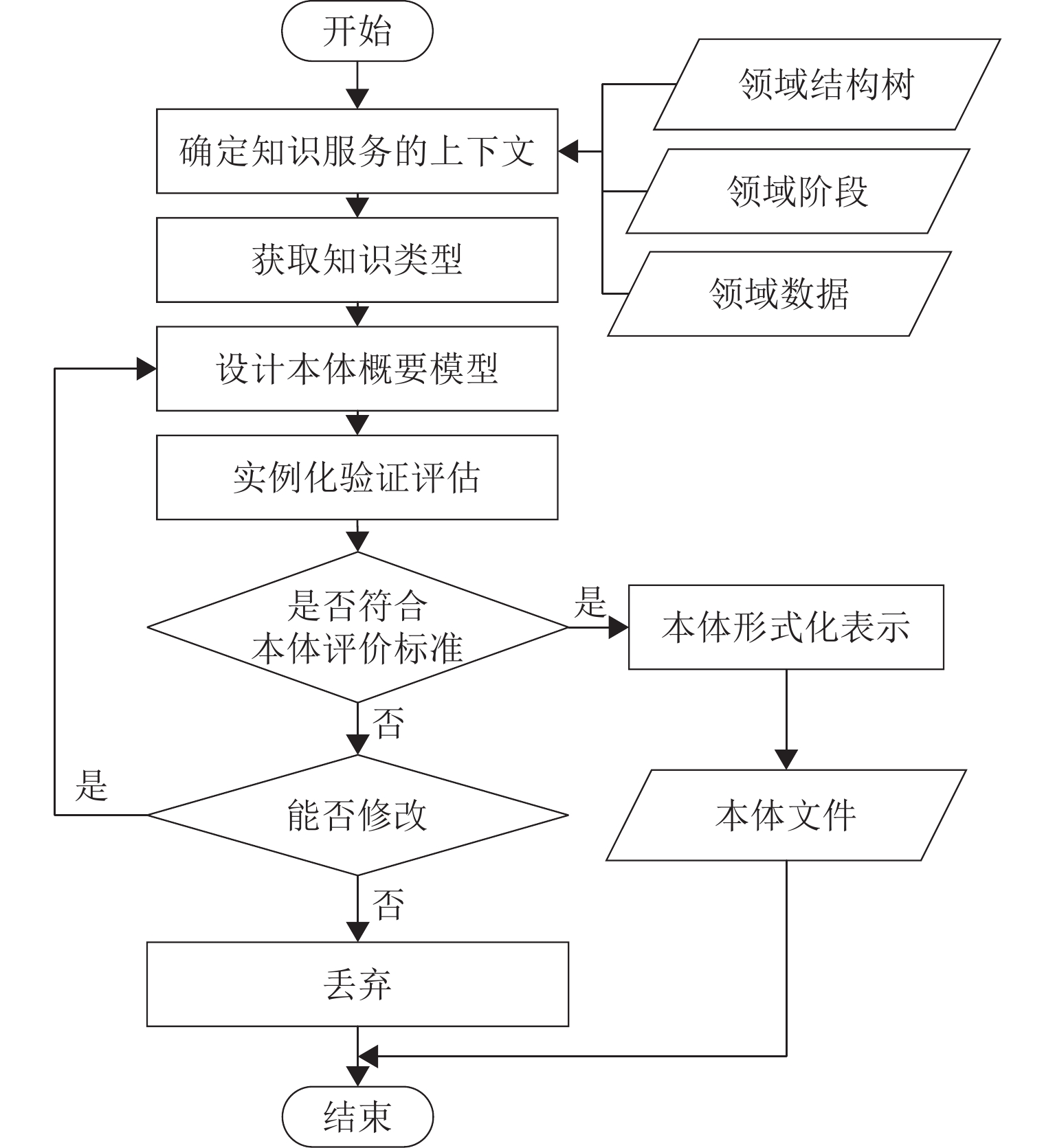
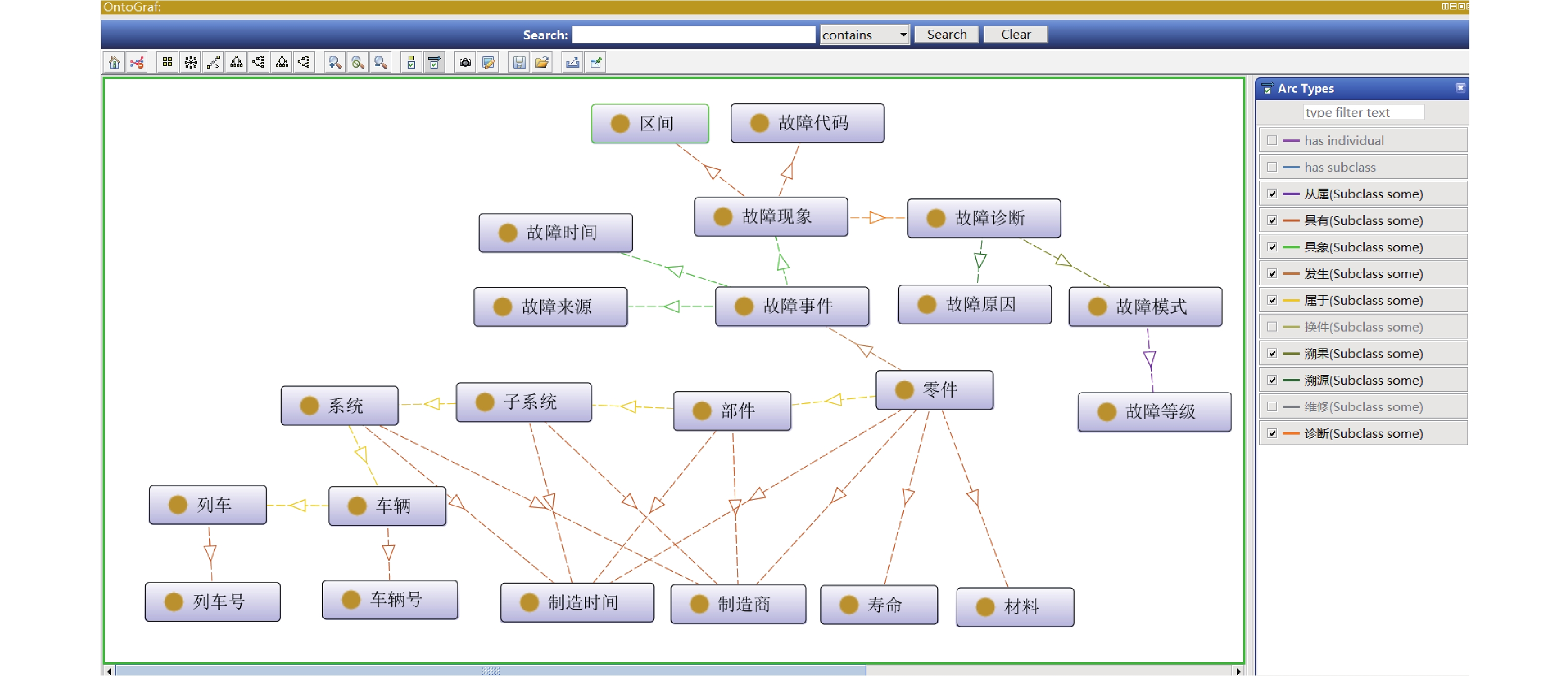
图 1 基于知识图谱的高速列车知识融合
Figure 1. Knowledge fusion of high-speed train based on knowledge graph
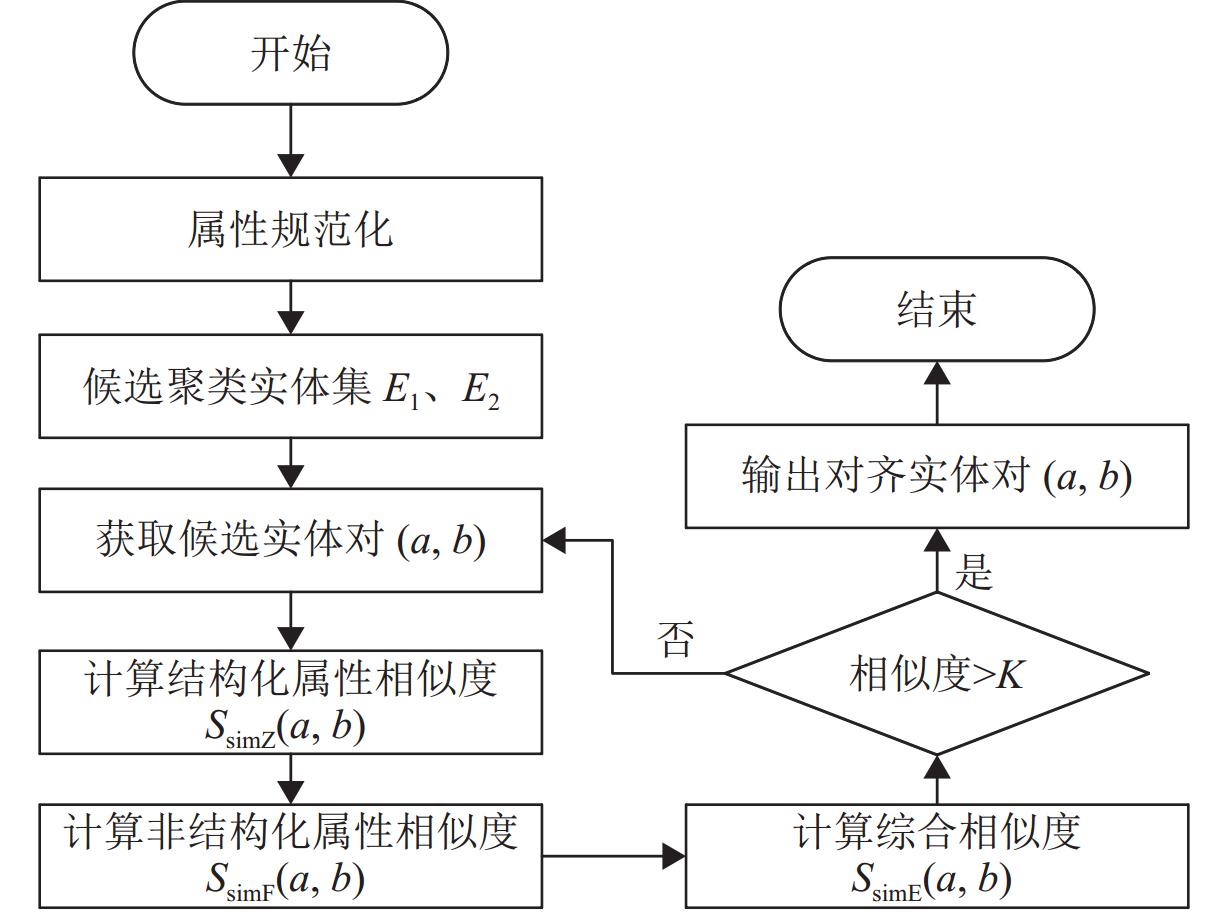
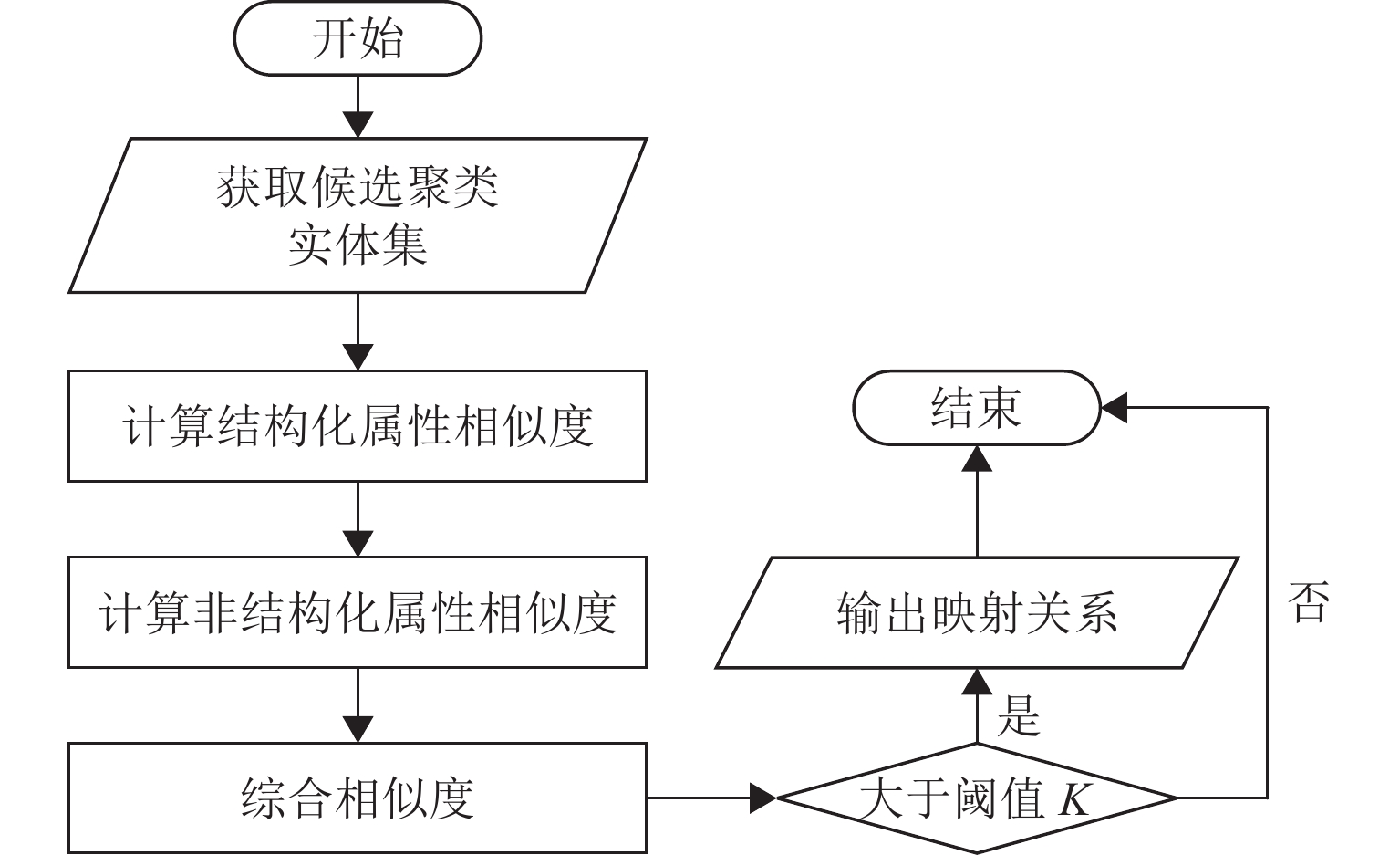
图 5 基于属性相似度的实体对齐算法流程
Figure 5. Entity alignment algorithm based on attribute similarity
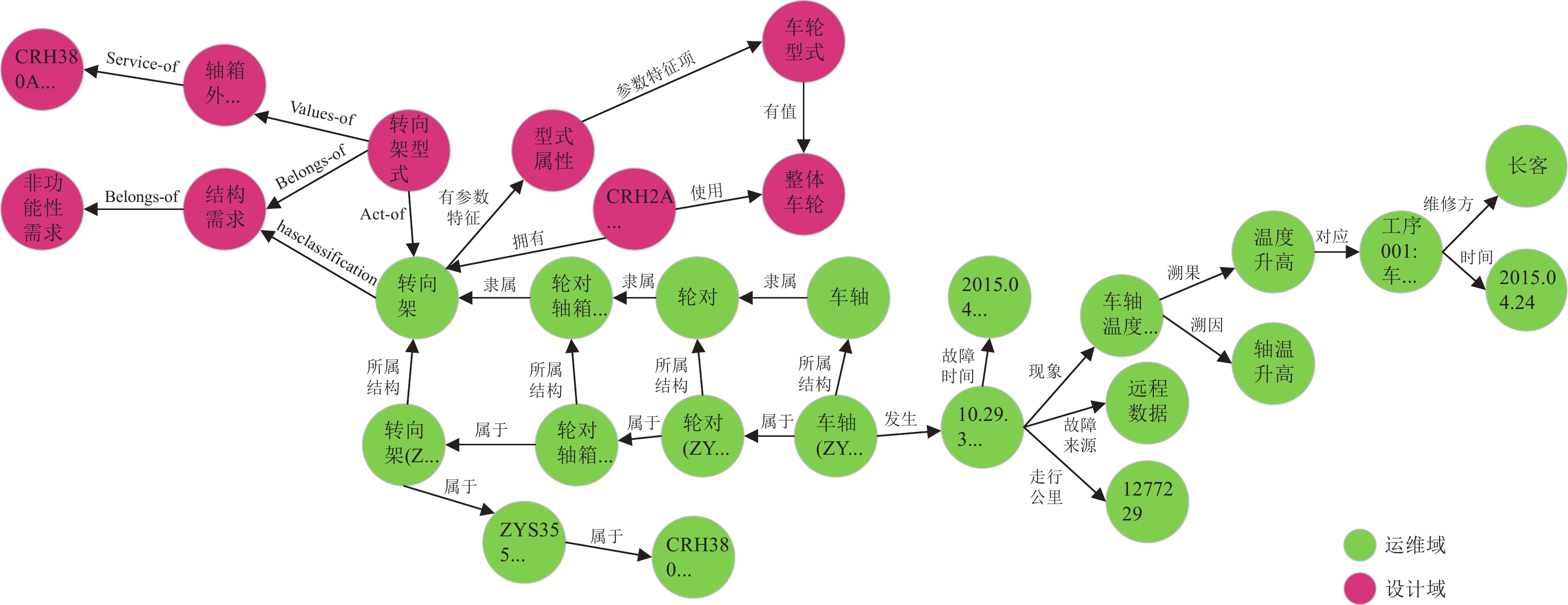
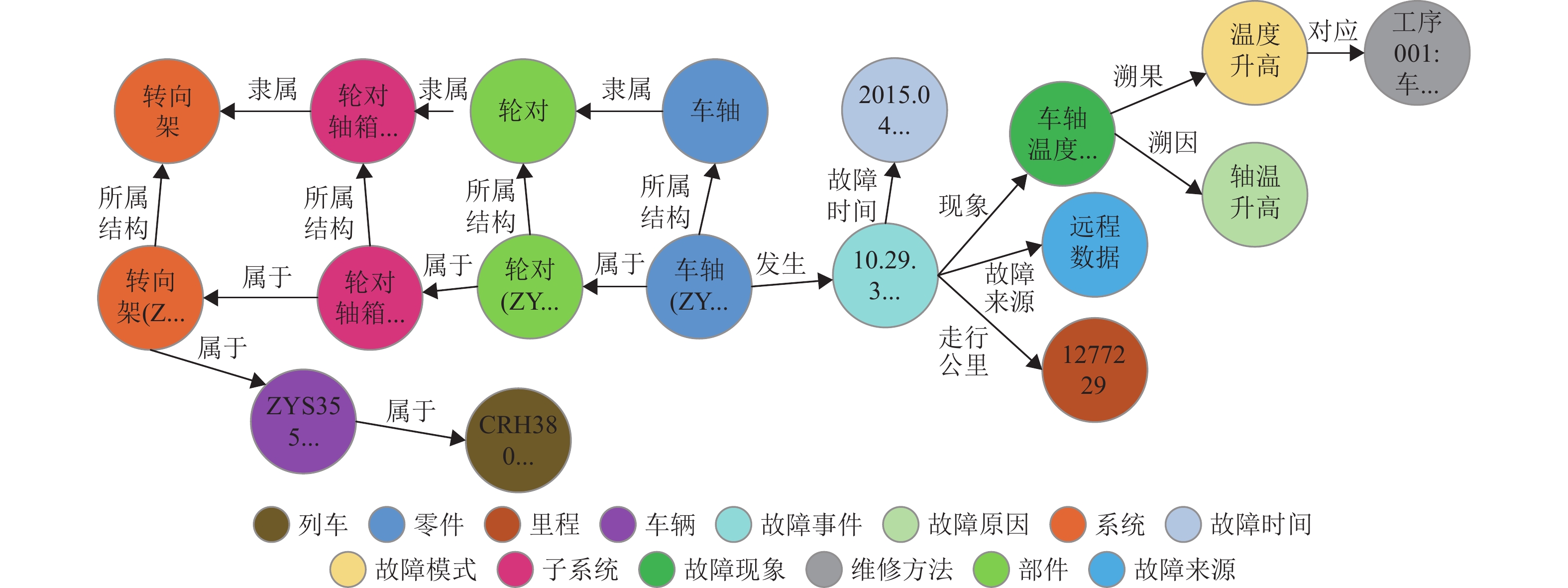
图 13 设计域和运维域融合知识图谱
Figure 13. Fusion knowledge graph of design domain and maintenance domain
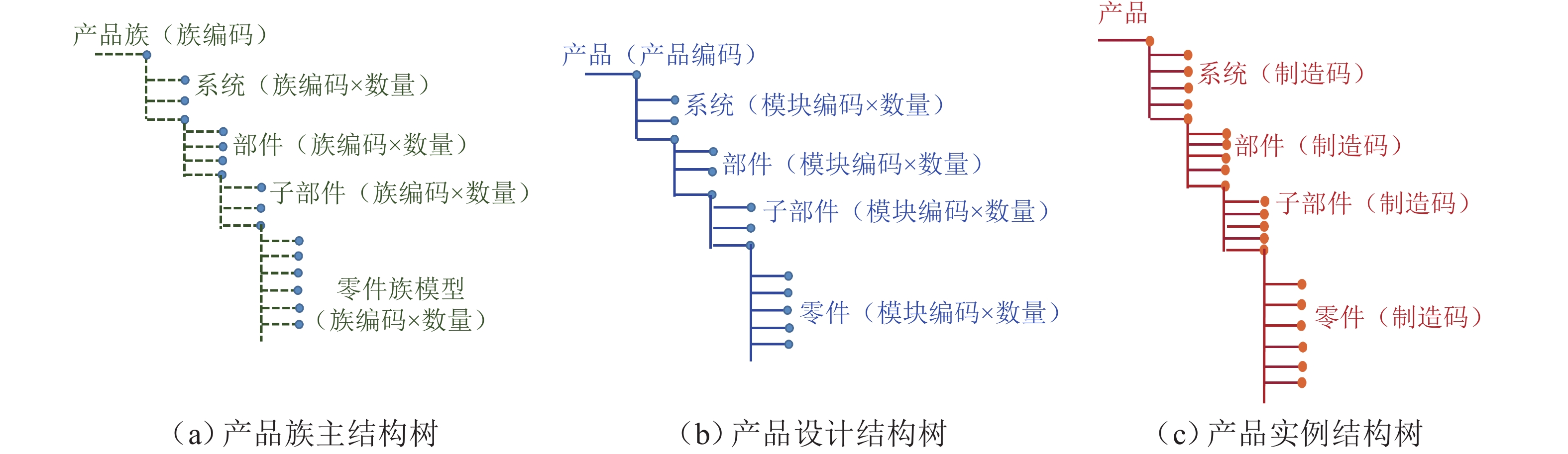
表 1 结构树划分
Table 1. Partition of structure trees
结构树 知识来源 特点分析 产品族主结构树 产品族模型数据、标准类数据、模板类数据 具有快速重用的特点,不涉及具体的参数值,是设计实例的模板结构,具有元节点编码作为唯一标识 产品设计结构树 需求数据、几何数据、设计规则、物理属性数据、工艺数据 与设计产出相对应,是按需求设计实例化的结果,具有模块编码作为唯一标识 产品实例结构树 工艺质量数据、故障数据、制造成本数据 设计实例实物化的结果,与设计实例具有多对一的关系,制造码为唯一标识  下载: 导出CSV
下载: 导出CSV
表 2 高速列车实体属性
Table 2. Entity attributes of high-speed train
数值型(结构化属性) 文本型(非结构化属性) 运营速度、转向架最大宽度、转向架最大高度、车轮直径(新轮)、车轮直径(半磨耗)、齿轮中心距、轴重 转向架型式、车轮型式、车轮踏面型式、车轴型式、牵引电机型式、牵引拉杆材料、齿轮箱材料
下载: 导出CSV
表 4 数据集构成
Table 4. Composition of dataset
数据集 实体数 关系数 实体数 可对齐 不可对齐 故障数据 13258 41152 8925 4333 维修数据 10506 35282 8925 1581
下载: 导出CSV
表 5 BERT-BILSTM-CRF模型参数
Table 5. Parameters of BERT-BILSTM-CRF model
参数名 参数值 批大小/批 4 学习率 0.001 丢失率 0.5 训练轮次/轮 10 字向量维度/维 768 序列长度/个 128
下载: 导出CSV
表 6 实体识别对比实验
Table 6. Comparative experiment of entity recognition
% 实验方法 准确率 召回率 F1 值 Word2vec-BILSTM 86 83 84 Word2vec-BILSTM-CRF 90 87 88 BERT-BILSTM 89 86 87 BERT-BILSTM-CRF 91 88 89
下载: 导出CSV
表 7 相似度计算对比实验
Table 7. Comparative experiment of similarity calculation
相似度计算方法 F1 值/% Levenshtein 距离 82 Jaro-Winkler 距离 79 语义相似度(CBOW) 77 语义相似度(BILSTM) 81 语义相似度(CBOW-BILSTM) 83
下载: 导出CSV
-
[1] 丁国富,姜杰,张海柱,等. 我国高速列车数字化研发的进展及挑战[J]. 西南交通大学学报,2016,51(2): 251-263. doi: 10.3969/j.issn.0258-2724.2016.02.005DING Guofu, JIANG Jie, ZHANG Haizhu, et al. Development and challenge of digital design of high-speed trains in China[J]. Journal of Southwest Jiaotong University, 2016, 51(2): 251-263. doi: 10.3969/j.issn.0258-2724.2016.02.005 [2] 刘峤,李杨,段宏,等. 知识图谱构建技术综述[J]. 计算机研究与发展,2016,53(3): 582-600.LIU Qiao, LI Yang, DUAN Hong, et al. Knowledge graph construction techniques[J]. Journal of Computer Research and Development, 2016, 53(3): 582-600. [3] RUTA M, SCIOSCIA F, GRAMEGNA F, et al. A knowledge fusion approach for context awareness in vehicular networks[J]. IEEE Internet of Things Journal, 2018, 5(4): 2407-2419. doi: 10.1109/JIOT.2018.2815009 [4] ZHAO X J, JIA Y, LI A P, et al. Multi-source knowledge fusion: a survey[C]//2019 IEEE Fourth International Conference on Data Science in Cyberspace (DSC). Hangzhou: IEEE, 2019: 119-127. [5] ABDELLATIF M, FARHAN M S, SHEHATA N S. Overcoming business process reengineering obstacles using ontology-based knowledge map methodology[J]. Future Computing and Informatics Journal, 2018, 3(1): 7-28. doi: 10.1016/j.fcij.2017.10.006 [6] KAUSHIK N, CHATTERJEE N. Automatic relationship extraction from agricultural text for ontology construction[J]. Information Processing in Agriculture, 2018, 5(1): 60-73. doi: 10.1016/j.inpa.2017.11.003 [7] DAI Z J, WANG X T, NI P, et al. Named entity recognition using BERT BiLSTM CRF for Chinese electronic health records[C]//2019 12th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI). Suzhou: IEEE, 2019: 1-5. [8] JIANG L, SHI J Y, WANG C Y. Multi-ontology fusion and rule development to facilitate automated code compliance checking using BIM and rule-based reasoning[J]. Advanced Engineering Informatics, 2022, 51: 101449.1-101449.15. [9] 王雪鹏,刘康,何世柱,等. 基于网络语义标签的多源知识库实体对齐算法[J]. 计算机学报,2017,40(3): 701-711. doi: 10.11897/SP.J.1016.2017.00701WANG Xuepeng, LIU Kang, HE Shizhu, et al. Multi-source knowledge bases entity alignment by leveraging semantic tags[J]. Chinese Journal of Computers, 2017, 40(3): 701-711. doi: 10.11897/SP.J.1016.2017.00701 [10] TRISEDYA B D, QI J Z, ZHANG R. Entity alignment between knowledge graphs using attribute embeddings[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 297-304. doi: 10.1609/aaai.v33i01.3301297 [11] ZHU Q, WEI H, SISMAN B, et al. Collective multi-type entity alignment between knowledge graphs[C]//Proceedings of the Web Conference 2020. Taipei: ACM, 2020: 2241–2252. [12] ZAD S, HEIDARI M, HAJIBABAEE P, et al. A survey of deep learning methods on semantic similarity and sentence modeling[C]//2021 IEEE 12th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON). Vancouver: IEEE, 2021: 466-472. [13] TSENG C W, CHOU J J, TSAI Y C. Text mining analysis of teaching evaluation questionnaires for the selection of outstanding teaching faculty members[J]. IEEE Access, 2018, 6: 72870-72879. doi: 10.1109/ACCESS.2018.2878478 [14] ZHANG W T, JIANG S H, ZHAO S, et al. A BERT-BiLSTM-CRF model for Chinese electronic medical records named entity recognition[C]//2019 12th International Conference on Intelligent Computation Technology and Automation (ICICTA). Xiangtan: IEEE, 2019: 166-169. [15] ZHANG M Y, WANG J, ZHANG X J. Using a pre-trained language model for medical named entity extraction in Chinese clinic text[C]//2020 IEEE 10th International Conference on Electronics Information and Emergency Communication (ICEIEC). Beijing: IEEE, 2020: 312-317. [16] NGUYEN H T, DUONG P H, CAMBRIA E. Learning short-text semantic similarity with word embeddings and external knowledge sources[J]. Knowledge-Based Systems, 2019, 182: 104842.1-104842.9. [17] PUTERA UTAMA SIAHAAN A, ARYZA S, HARIYANTO E, et al. Combination of Levenshtein distance and Rabin-Karp to improve the accuracy of document equivalence level[J]. International Journal of Engineering & Technology, 2018, 7: 17-21. [18] MANAF K, PITARA S, SUBAEKI B, et al. Comparison of carp Rabin algorithm and jaro-winkler distance to determine the equality of sunda languages[C]//2019 IEEE 13th International Conference on Telecommunication Systems, Services, and Applications (TSSA). Bali: IEEE, 2019: 77-81. -

 下载:
下载:



 点击查看大图
点击查看大图
计量
- 文章访问数: 703
- HTML全文浏览量: 341
- PDF下载量: 102
- 被引次数: 0