

Analysis of Generation and Evolution Characteristics of Wheel High-Order Polygonal Wear
-
摘要:
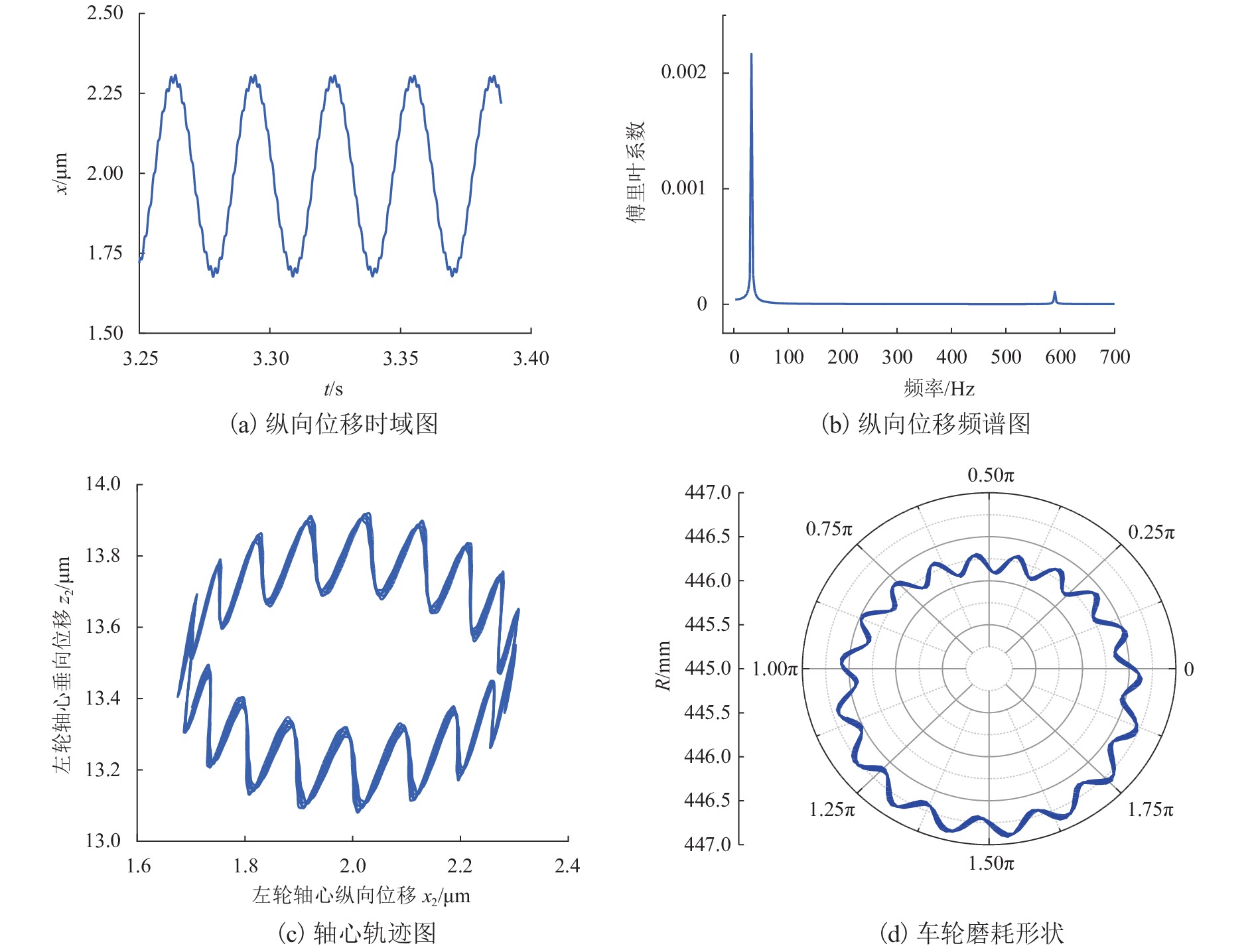
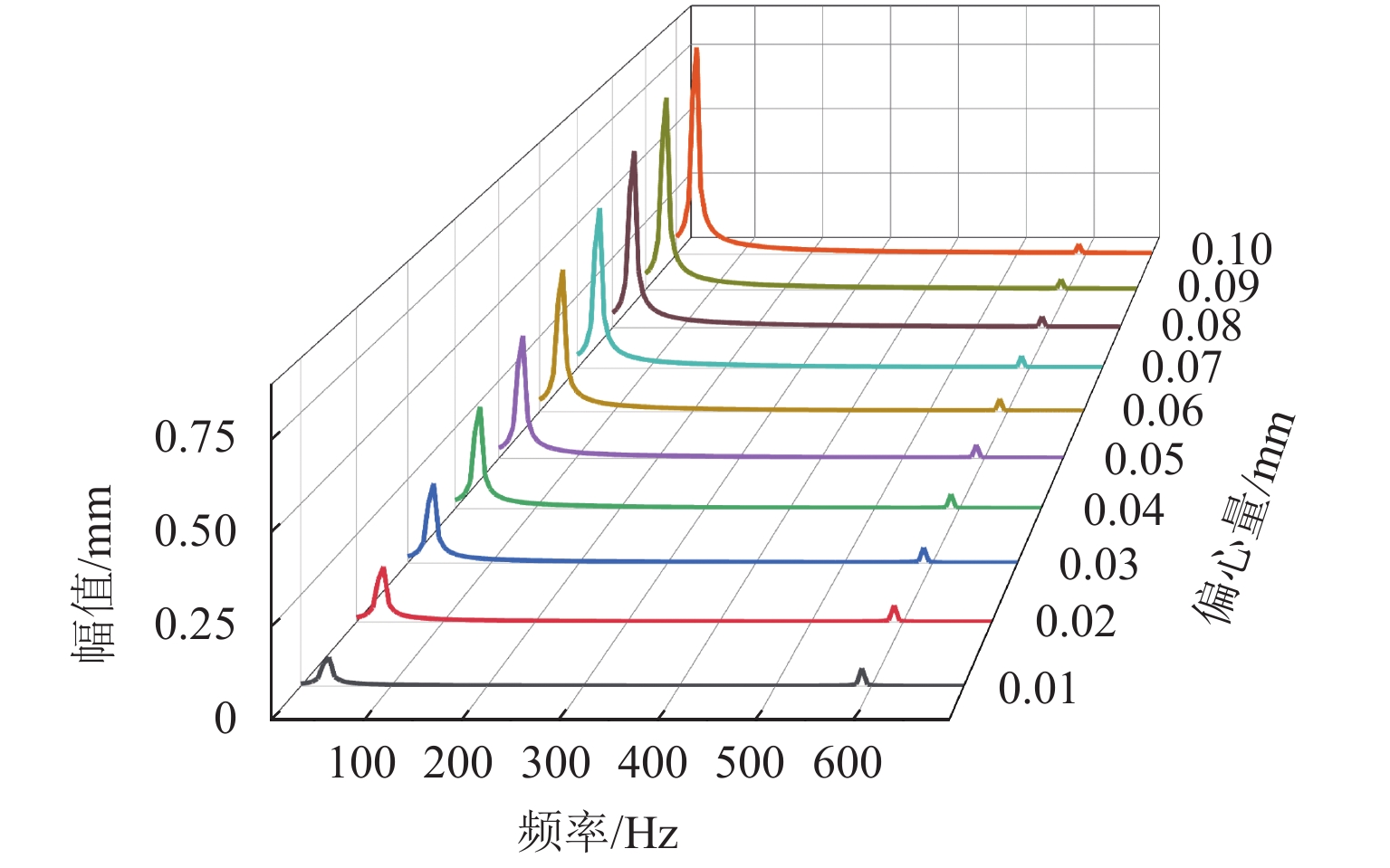
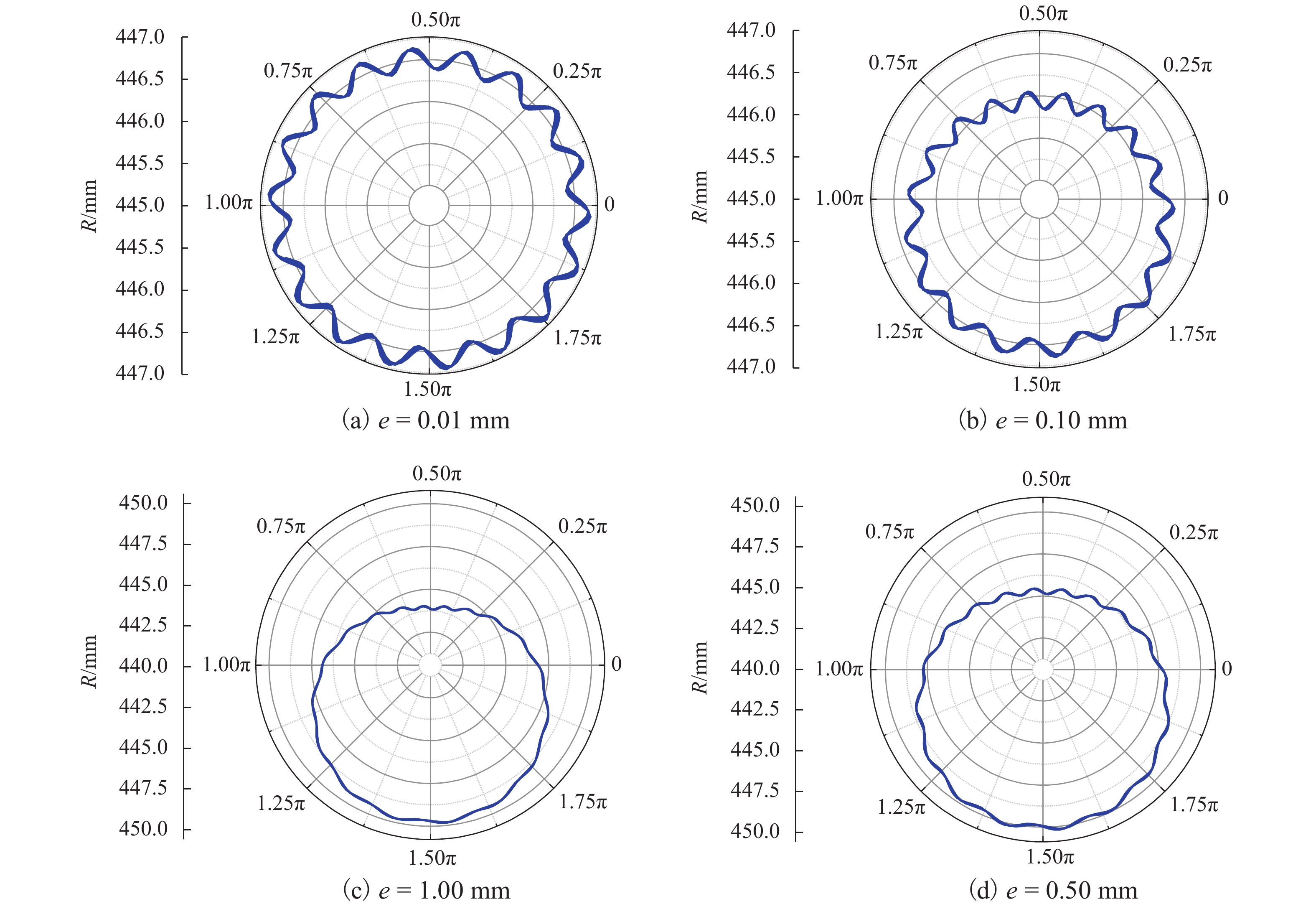
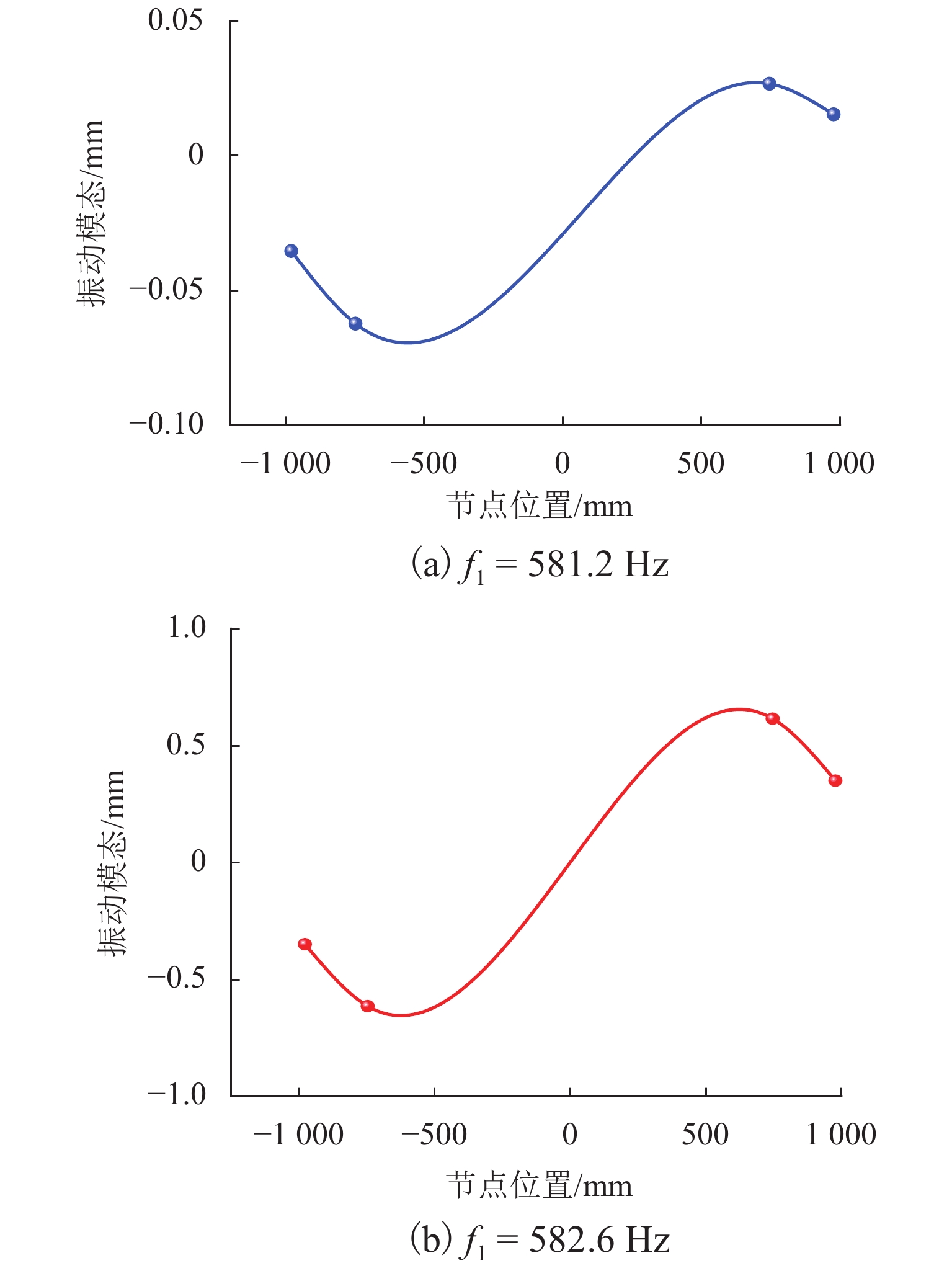
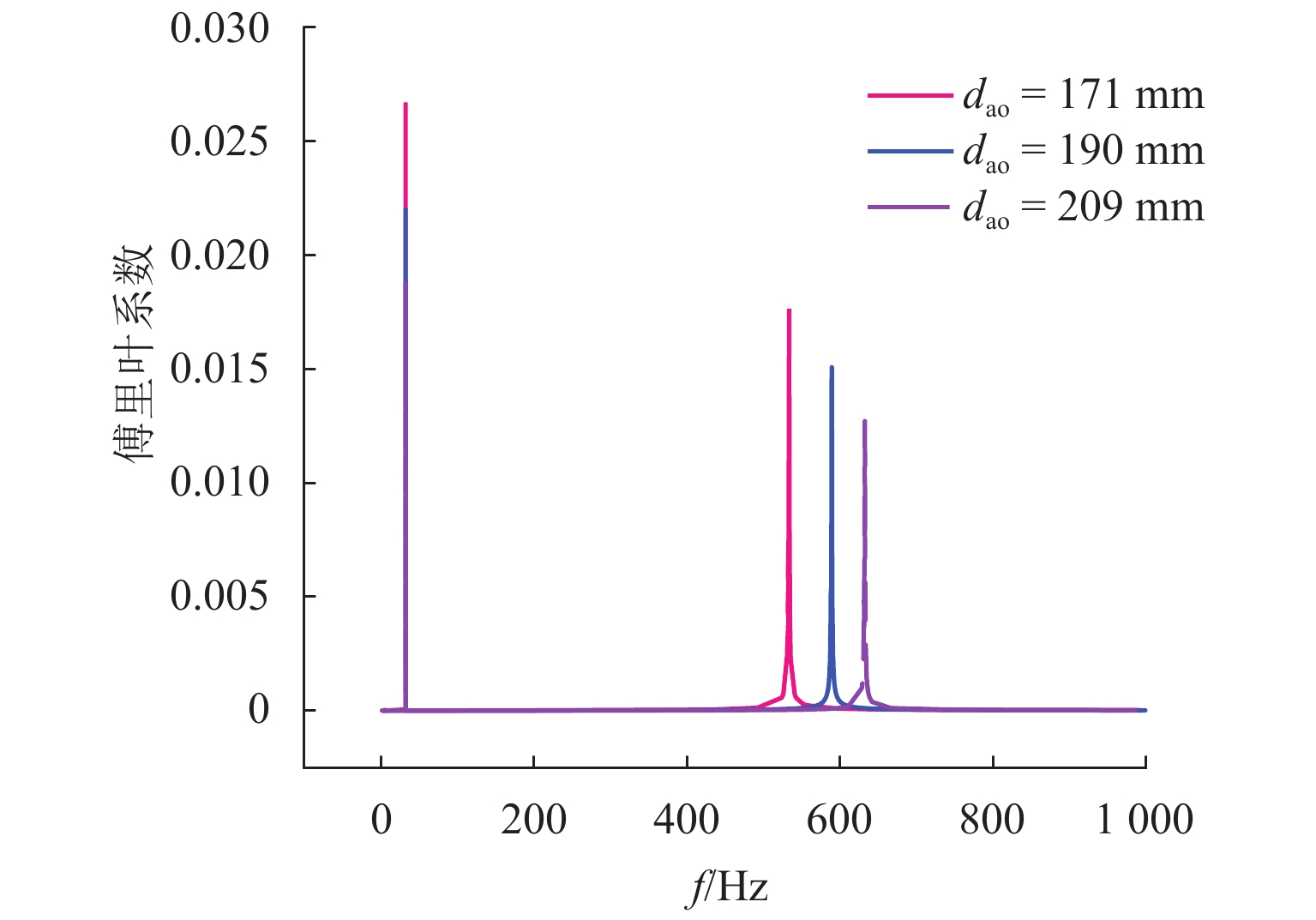
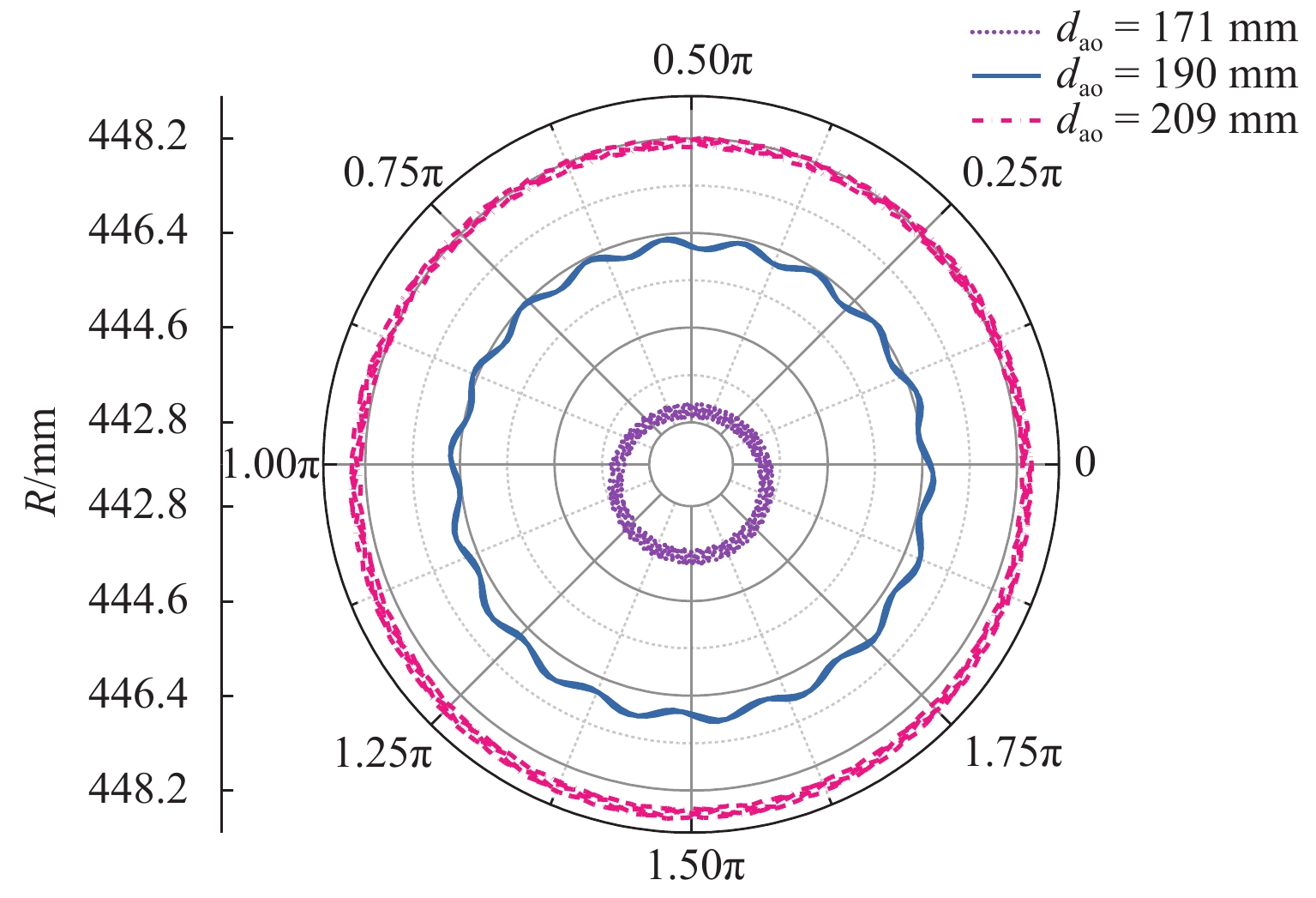
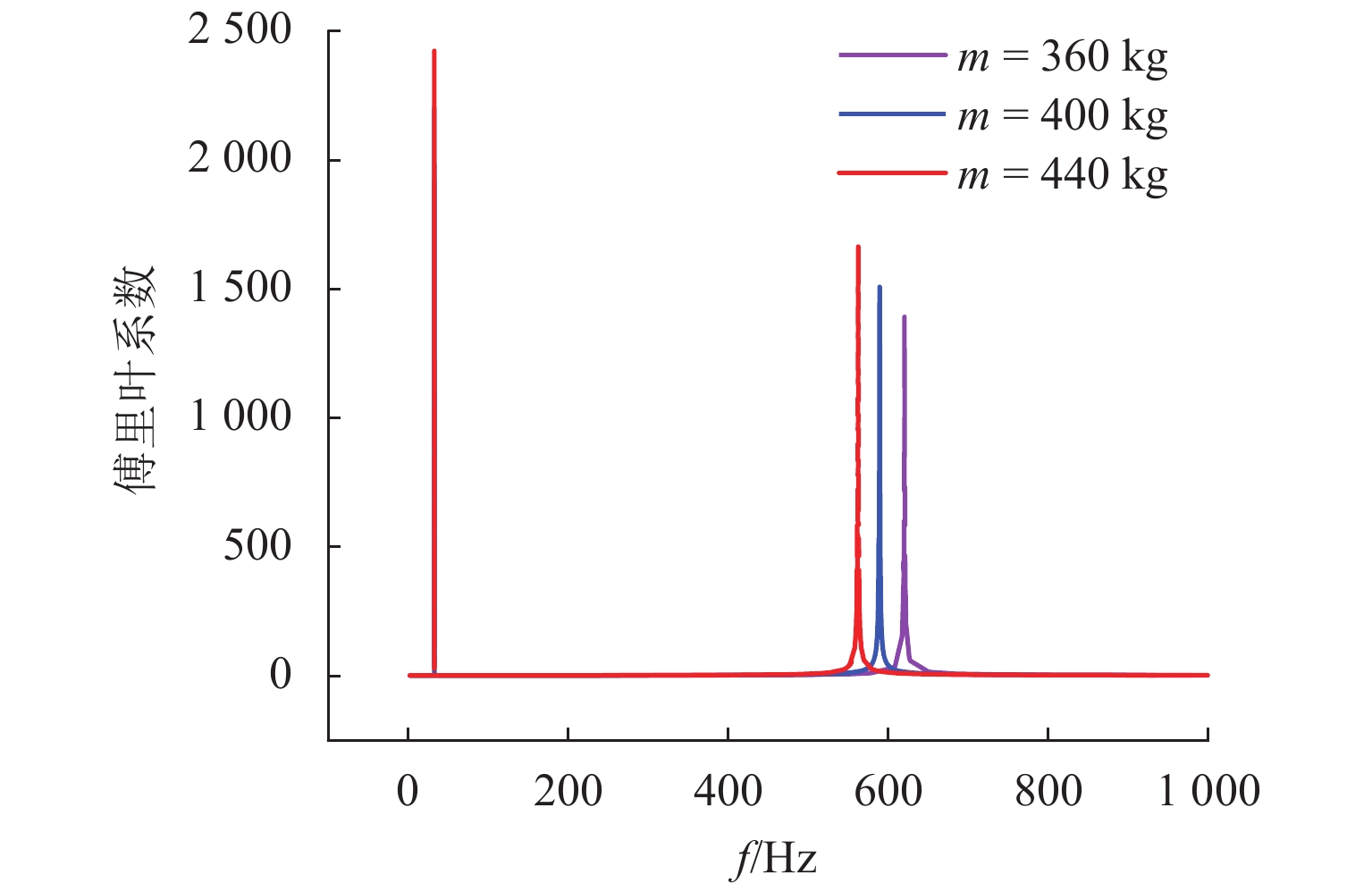
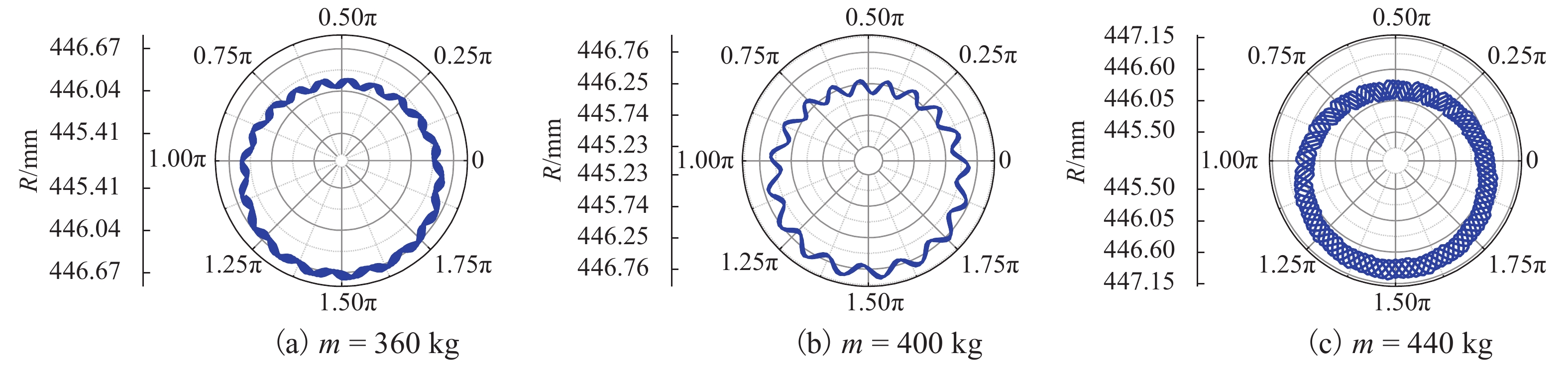
针对日益突出的车轮高阶多边形磨耗问题,基于轮轨系统转子动力学模型、轮轨接触模型和车轮圆周磨耗深度模型,建立车轮多边形磨耗发生与演化模型;分析列车运行速度和车轮质量偏心的变化,揭示车轮多边形磨耗发生与演化的规律,并进行现场跟踪实测数据验证;通过模态和灵敏度分析研究系统参数对多边形磨耗的影响. 研究结果表明:车轮高阶多边形磨耗的产生和演化遵循“定频整分”规律,即580 Hz左右的固定频率整分轮对转频时,车轮磨耗会演化成19阶左右的多边形,否则车轮磨耗将趋于均匀;该固定频率主要来源于轮对的2阶弯曲模态,且对车轴直径的灵敏度最大,通过定转速运行、增大车轴直径等措施改变固定频率可有效抑制车轮多边形磨耗.
Abstract:Aiming at the increasingly serious problem of high-order wheel polygonal wear, based on the wheel-rail system rotor dynamics model, wheel-rail contact model and wear depth model, the generation and evolution model of wheel polygonal wear is established. By analyzing the variation of speed and wheel mass eccentricity, the regularity of generation and evolution of wheel polygonal wear are revealed, and the field tracking data are verified. The influence of system parameters on polygonal wear is studied by modal analysis and sensitivity analysis. The results show that the generation and evolution of high order wheel polygonal wear follows the law of “fixed frequency and divisible”. When the fixed frequency of 580 Hz divides wheelset rotation frequency, the wheel wear will evolve into 19th order polygonal, otherwise it will tend to be uniform. This fixed frequency is mainly derived from the 2nd-order bending mode of the wheelset and has the greatest sensitivity to the axle diameter. The fixed frequency of the wheel can be changed by running at constant rotating speed and increasing the axle diameter, which can effectively suppress the polygonal wear of the wheel.
-
Key words:
- high-order polygonal /
- wear /
- fixed frequency and divisible /
- sensitivity
-
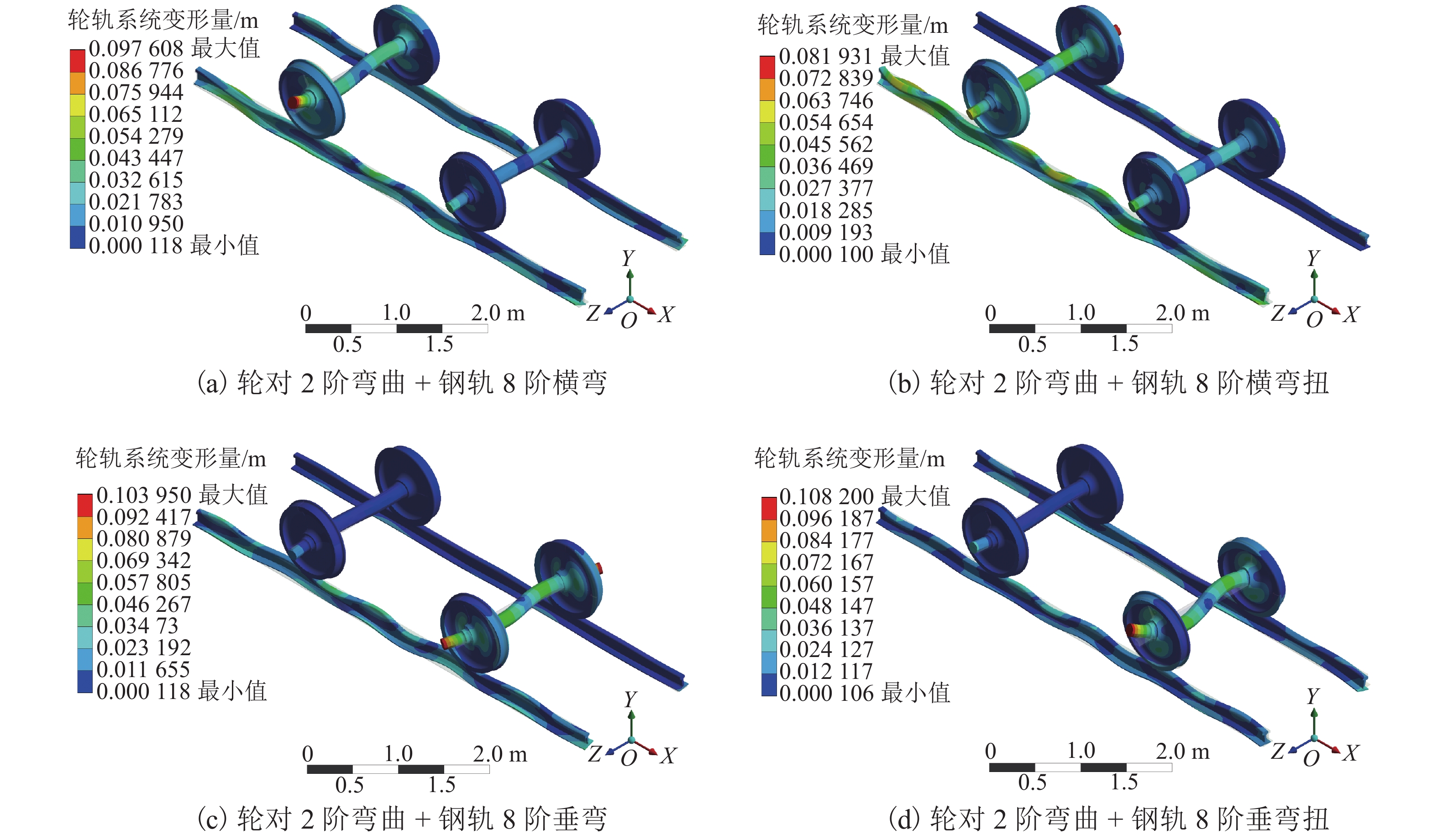
图 9 考虑转动效应下轮轨耦合系统振动模态
Figure 9. Vibration modes of wheel-rail coupling system considering rotation effect
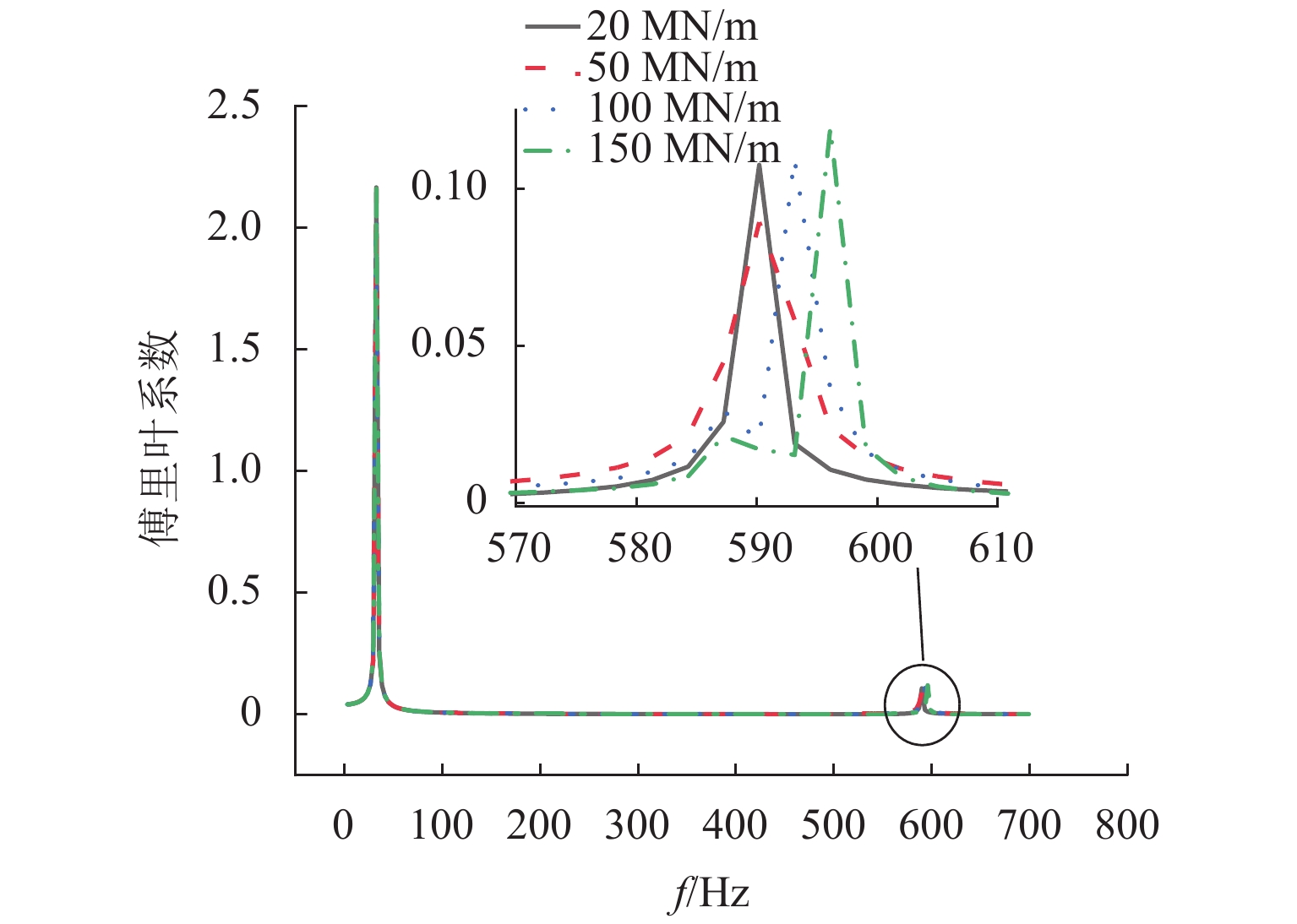
图 10 不同扣件刚度幅频图
Figure 10. Amplitude-frequency diagram under different fastener stiffnesses
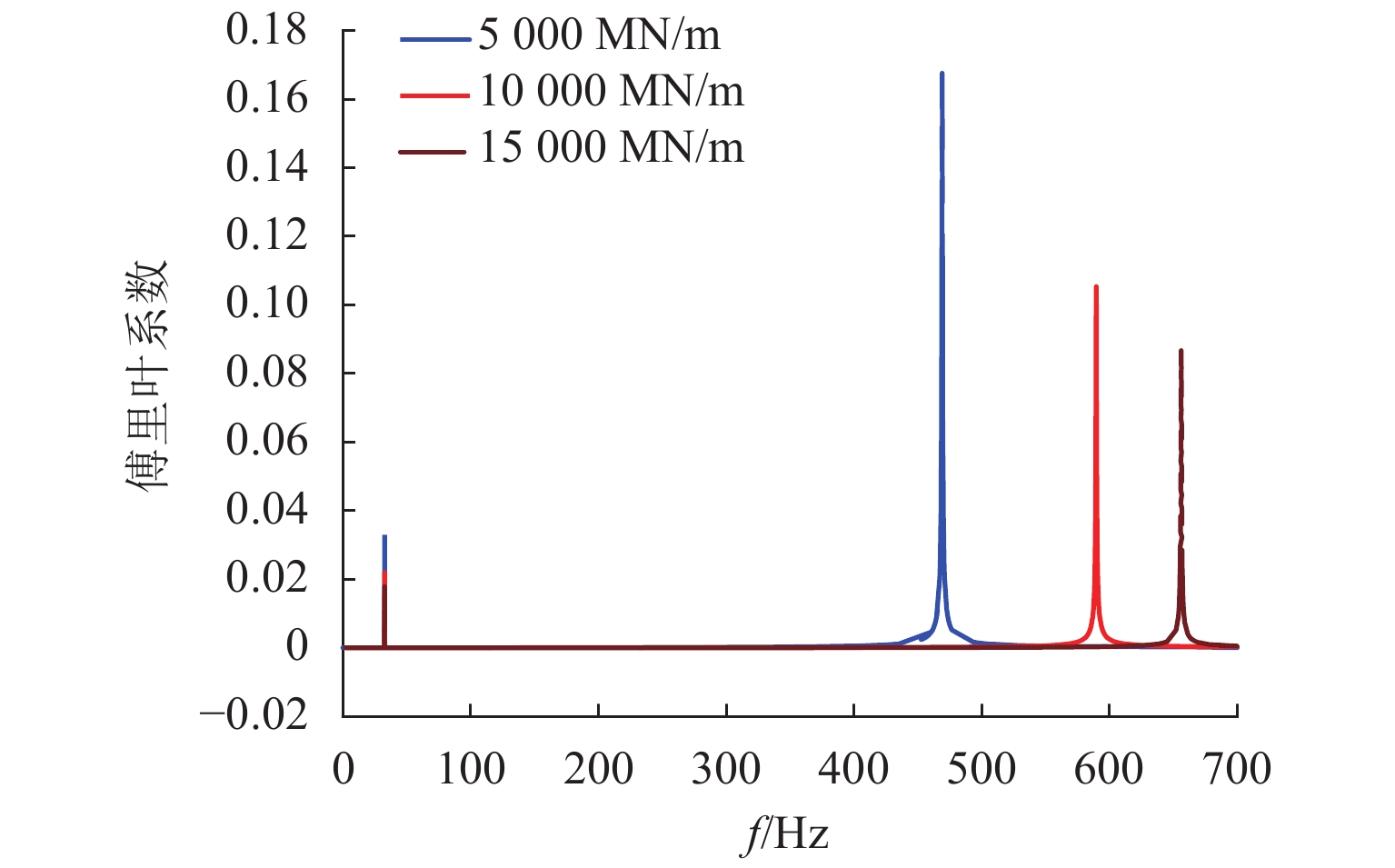
图 16 不同支承刚度的幅频图
Figure 16. Amplitude-frequency diagram under different support stiffnesses
表 1 车轮多边形磨耗参数分析
Table 1. Analysis of wheel polygonal wear parameters
n D/mm ω/(rad·s−1) f2/Hz fx/Hz 20 915 182.1 29.0 580.1 19 875 190.5 30.3 576.3 18 830 200.8 32.0 575.6  下载: 导出CSV
下载: 导出CSV
表 2 轮轨耦合系统的固有频率
Table 2. Natural frequency of rotor system of wheel set
Hz 不考虑转动效应 考虑转动效应 刚轮柔轨 柔轮刚轨 柔轮柔轨 柔轮柔轨 519.40 567.16 565.42 565.42 559.49 567.19 580.73 580.61 574.77 577.74 583.07 582.97 593.11 578.03 584.48 584.37 605.90 585.43 585.47 585.65 608.93 585.45 586.78 586.94 622.27 748.22 591.33 591.35 648.97 769.92 621.80 621.81
下载: 导出CSV
-
[1] 金学松,吴越,梁树林,等. 高速列车车轮多边形磨耗、机理、影响和对策分析[J]. 机械工程学报,2020,56(16): 118-136. doi: 10.3901/JME.2020.16.118JIN Xuesong, WU Yue, LIANG Shulin, et al. Characteristics, mechanism, influences and countermeasures of polygonal wear of high-speed train wheels[J]. Journal of Mechanical Engineering, 2020, 56(16): 118-136. doi: 10.3901/JME.2020.16.118 [2] 陶功权,温泽峰,金学松. 铁道车辆车轮非圆化磨耗形成机理及控制措施研究进展[J]. 机械工程学报,2021,57(6): 106-120. doi: 10.3901/JME.2021.06.106TAO Gongquan, WEN Zefeng, JIN Xuesong. Advances in formation mechanism and mitigation measures of out-of-round railway vehicle wheels[J]. Journal of Mechanical Engineering, 2021, 57(6): 106-120. doi: 10.3901/JME.2021.06.106 [3] TAO G Q, WEN Z F, JIN X S, et al. Polygonisation of railway wheels: a critical review[J]. Railway Engineering Science, 2020, 28(4): 317-345. doi: 10.1007/s40534-020-00222-x [4] MORYS B. Enlargement of out-of-round wheel profiles on high speed trains[J]. Journal of Sound and Vibration, 1999, 227(5): 965-978. doi: 10.1006/jsvi.1999.2055 [5] MEYWERK M. Polygonalization of railway wheels[J]. Archive of Applied Mechanics, 1999, 69(2): 105-120. doi: 10.1007/s004190050208 [6] JOHANSSON A, ANDERSSON C. Out-of-round railway wheels—a study of wheel polygonalization through simulation of three-dimensional wheel-rail interaction and wear[J]. Vehicle System Dynamics, 2005, 43(8): 539-559. doi: 10.1080/00423110500184649 [7] WU X W, RAKHEJA S, CAI W B, et al. A study of formation of high order wheel polygonalization[J]. Wear, 2019, 424/425: 1-14. doi: 10.1016/j.wear.2019.01.099 [8] CAI W B, CHI M R, WU X W, et al. Experimental and numerical analysis of the polygonal wear of high-speed trains[J]. Wear, 2019, 440/441: 203079.1-203079.12. [9] MEINKE P, MEINKE S. Polygonalization of wheel treads caused by static and dynamic imbalances[J]. Journal of Sound and Vibration, 1999, 227(5): 979-986. doi: 10.1006/jsvi.1999.2590 [10] 胡晓依,任海星,成棣,等. 动车组车轮多边形磨耗形成与发展过程仿真研究[J]. 中国铁道科学,2021,42(2): 107-115.HU Xiaoyi, REN Haixing, CHENG Di, et al. Numerical simulation on the formation and development of polygonal wear of EMU wheels[J]. China Railway Science, 2021, 42(2): 107-115. [11] 宋志坤,任海星,胡晓依,等. 动车组车轮多边形磨耗发展历程模拟及车轮粗糙度的影响[J]. 铁道学报,2021,43(6): 23-28. doi: 10.3969/j.issn.1001-8360.2021.06.004SONG Zhikun, REN Haixing, HU Xiaoyi, et al. Research on development process simulation and influencing factors of polygonal wear of high-speed train wheels[J]. Journal of the China Railway Society, 2021, 43(6): 23-28. doi: 10.3969/j.issn.1001-8360.2021.06.004 [12] ZHAO X N, CHEN G X, LV J Z, et al. Study on the mechanism for the wheel polygonal wear of high-speed trains in terms of the frictional self-excited vibration theory[J]. Wear, 2019, 426/427: 1820-1827. doi: 10.1016/j.wear.2019.01.020 [13] 关庆华,赵鑫,温泽峰,等. 基于Hertz接触理论的法向接触刚度计算方法[J]. 西南交通大学学报,2021,56(4): 883-888.GUAN Qinghua, ZHAO Xin, WEN Zefeng, et al. Calculation method of Hertz normal contact stiffness[J]. Journal of Southwest Jiaotong University, 2021, 56(4): 883-888. [14] 王玉丰,沈钢. 几种铁路轮轨蠕滑力计算方法的比较[J]. 上海铁道大学学报(理工辑),1999(10): 27-32.WANG Yufeng, SHEN Gang. Comparison of several calculation methods of wheel/rail creep force[J]. Journal of Shanghai Tiedao University (Science and Technology), 1999(10): 27-32. [15] 张卫华,金学松,薛弼一. 单轮对试验台试验及轮轨蠕滑力计算模型的验证[J]. 铁道车辆,1997,35(5): 3-6,11.ZHANG Weihua, JIN Xuesong, XUE Biyi. Single wheelset test and verification of wheel-rail creep force calculation model[J]. Journal of Railway Vehicle, 1997, 35(5): 3-6,11. [16] 曹树谦,陈予恕. 多跨不平衡轴系的非线性动力学建模[J]. 非线性动力学学报,2002,9(1): 26-32.CAO Shuqian, CHEN Yushu. Nonlinear dynamics modeling of multi-span unbalanced shafting[J]. Journal of Nonlinear Dynamics, 2002, 9(1): 26-32. [17] 丁军君,杨九河,胡静涛,等. 高速列车车轮多边形磨耗演变行为[J]. 机械工程学报,2020,56(22): 184-189. doi: 10.3901/JME.2020.22.184DING Junjun, YANG Jiuhe, HU Jingtao, et al. Evolution of the polygonal wear of high-speed train wheels[J]. Journal of Mechanical Engineering, 2020, 56(22): 184-189. doi: 10.3901/JME.2020.22.184 [18] WU Y, JIN X S, CAI W B, et al. Key factors of the initiation and development of polygonal wear in the wheels of a high-speed train[J]. Applied Sciences, 2020, 10(17): 10175880.1-10175880.22. doi: 10.3390/app10175880 [19] 金学松,吴越,梁树林,等. 车轮非圆化磨耗问题研究进展[J]. 西南交通大学学报,2018,53(1): 1-14. doi: 10.3969/j.issn.0258-2724.2018.01.001JIN Xuesong, WU Yue, LIANG Shulin, et al. Mechanisms and countermeasures of out-of-roundness wear on railway vehicle wheels[J]. Journal of Southwest Jiaotong University, 2018, 53(1): 1-14. doi: 10.3969/j.issn.0258-2724.2018.01.001 -

 下载:
下载:



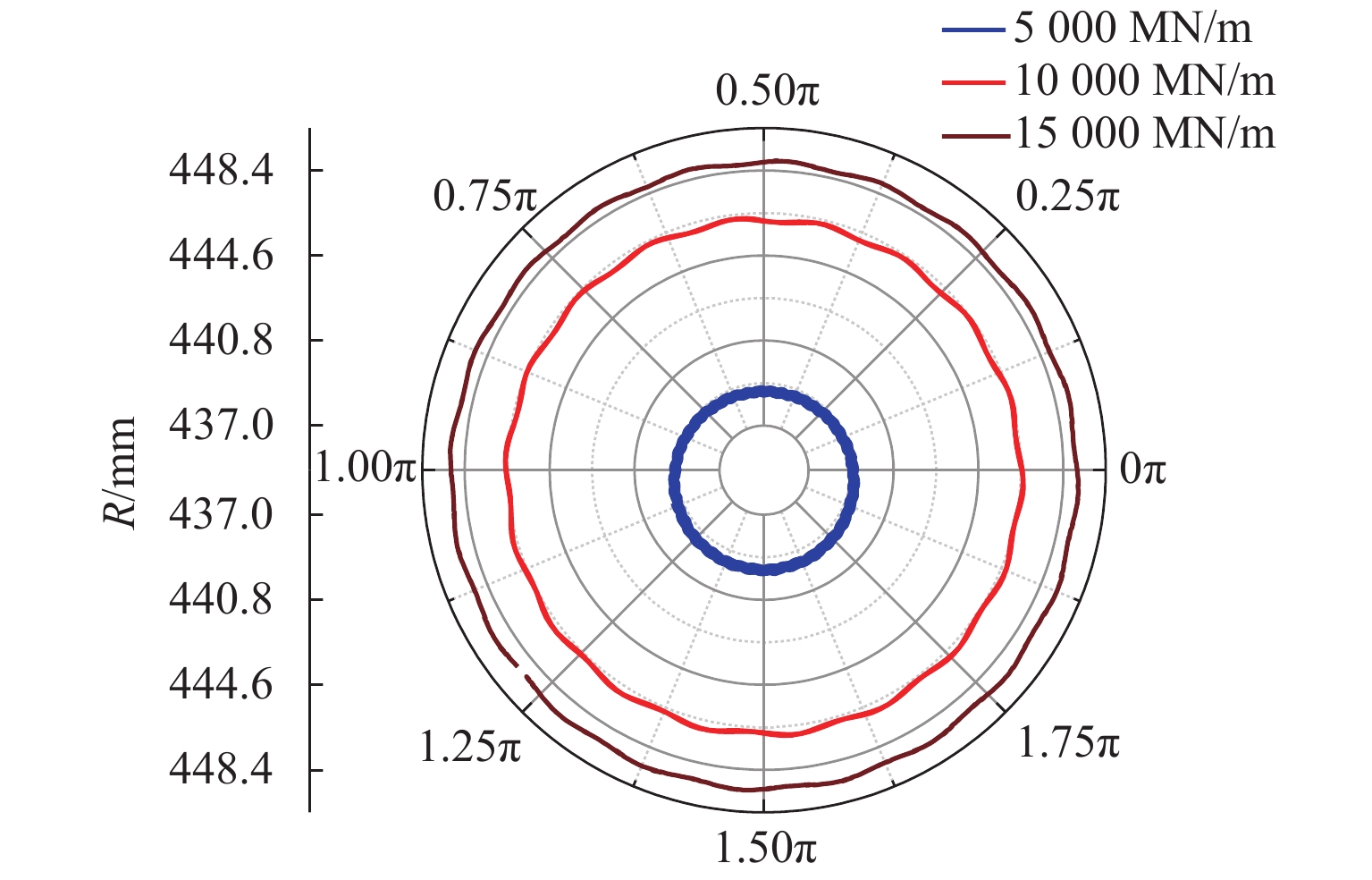
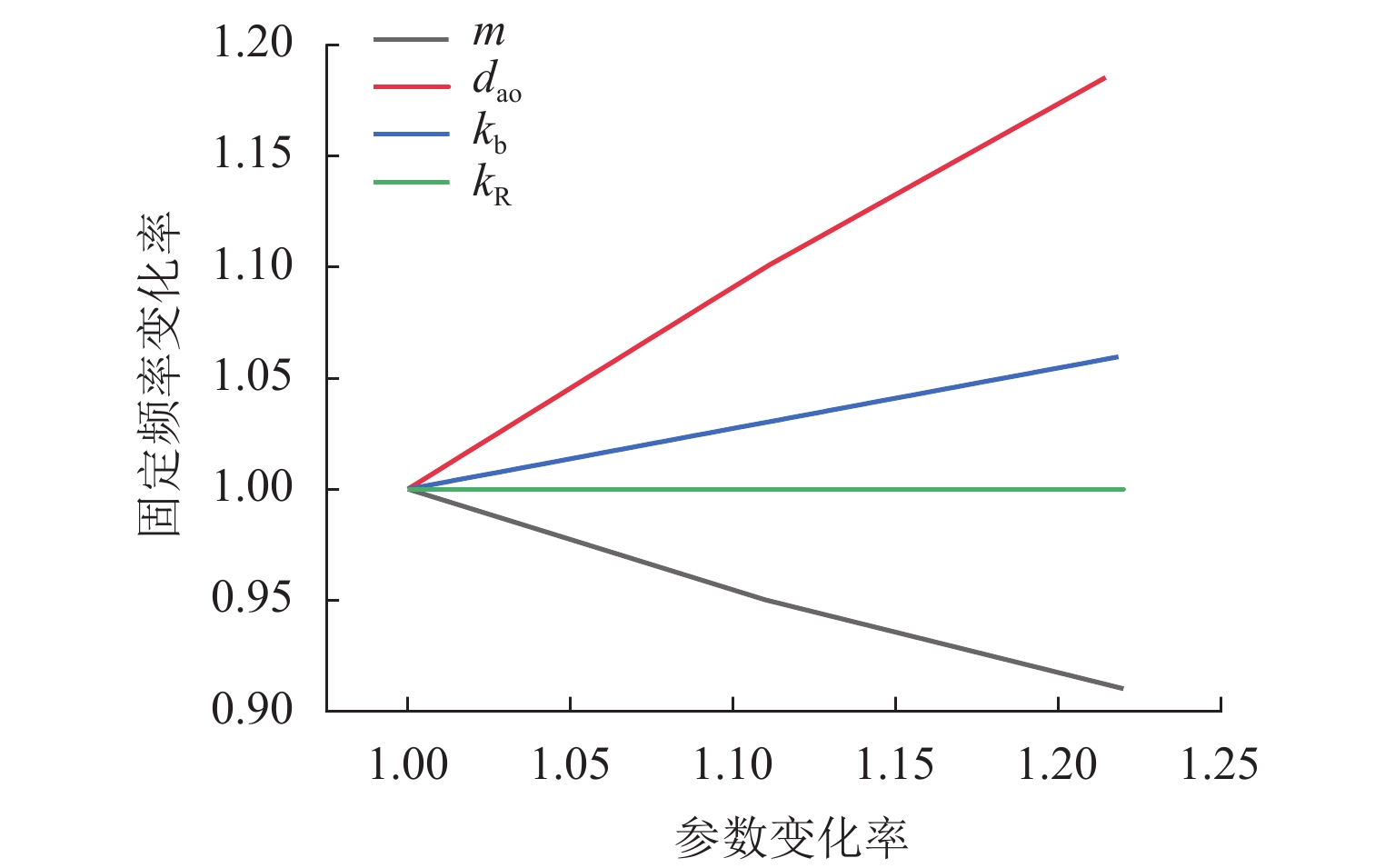

 点击查看大图
点击查看大图
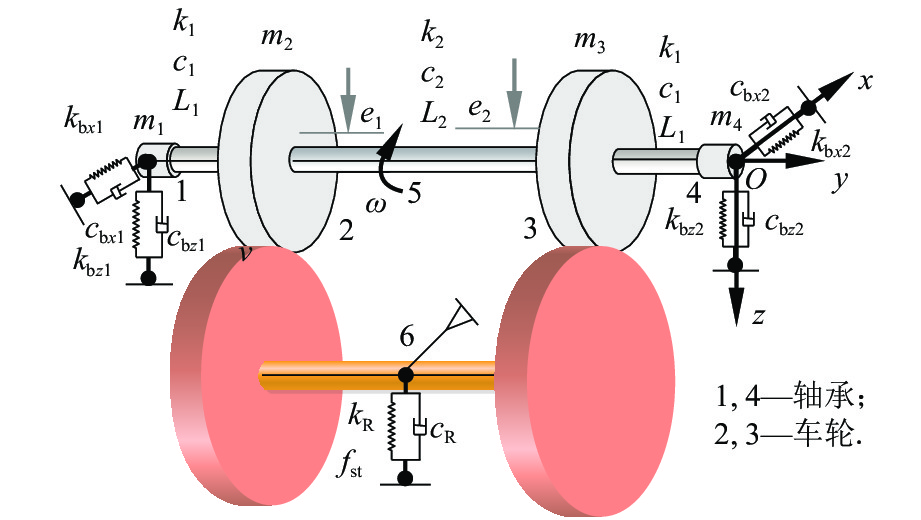
计量
- 文章访问数: 1200
- HTML全文浏览量: 380
- PDF下载量: 107
- 被引次数: 0