

Micro-positioning Control of Magnetic Actuator for Electrical Discharge Machining
-
摘要:
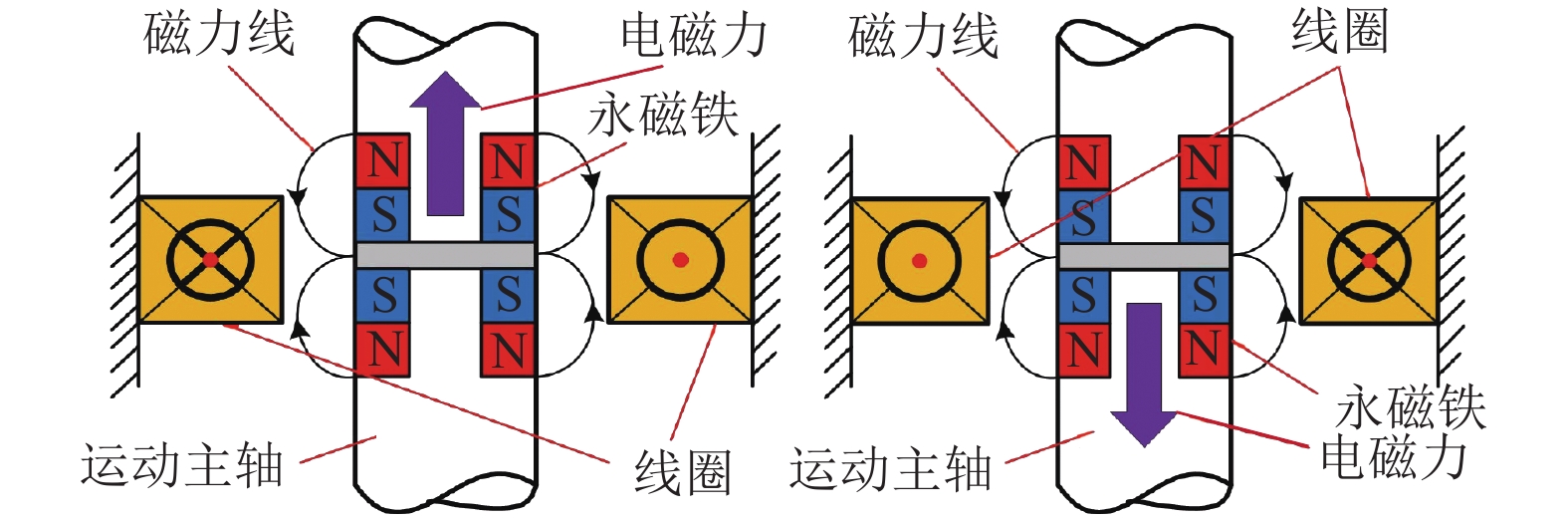
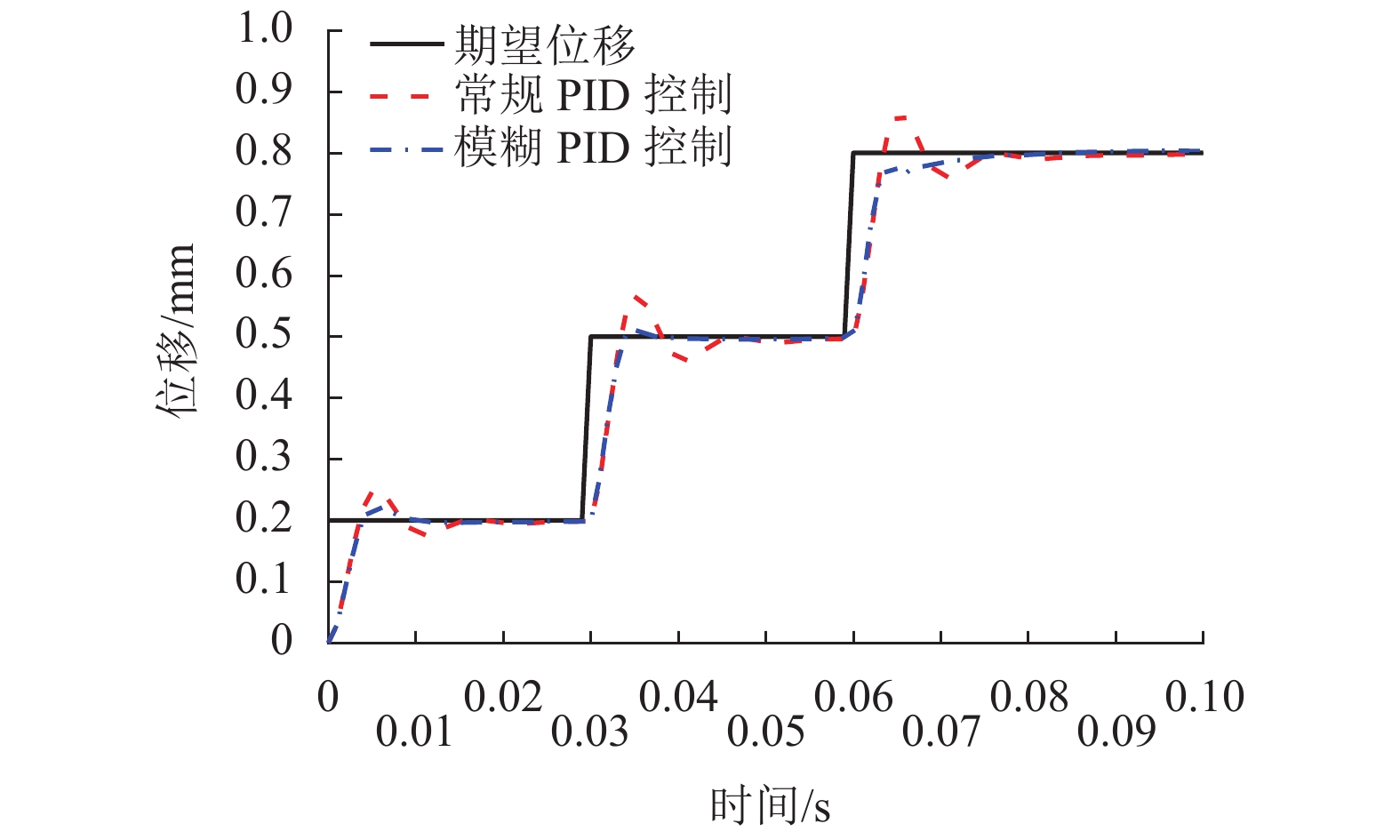
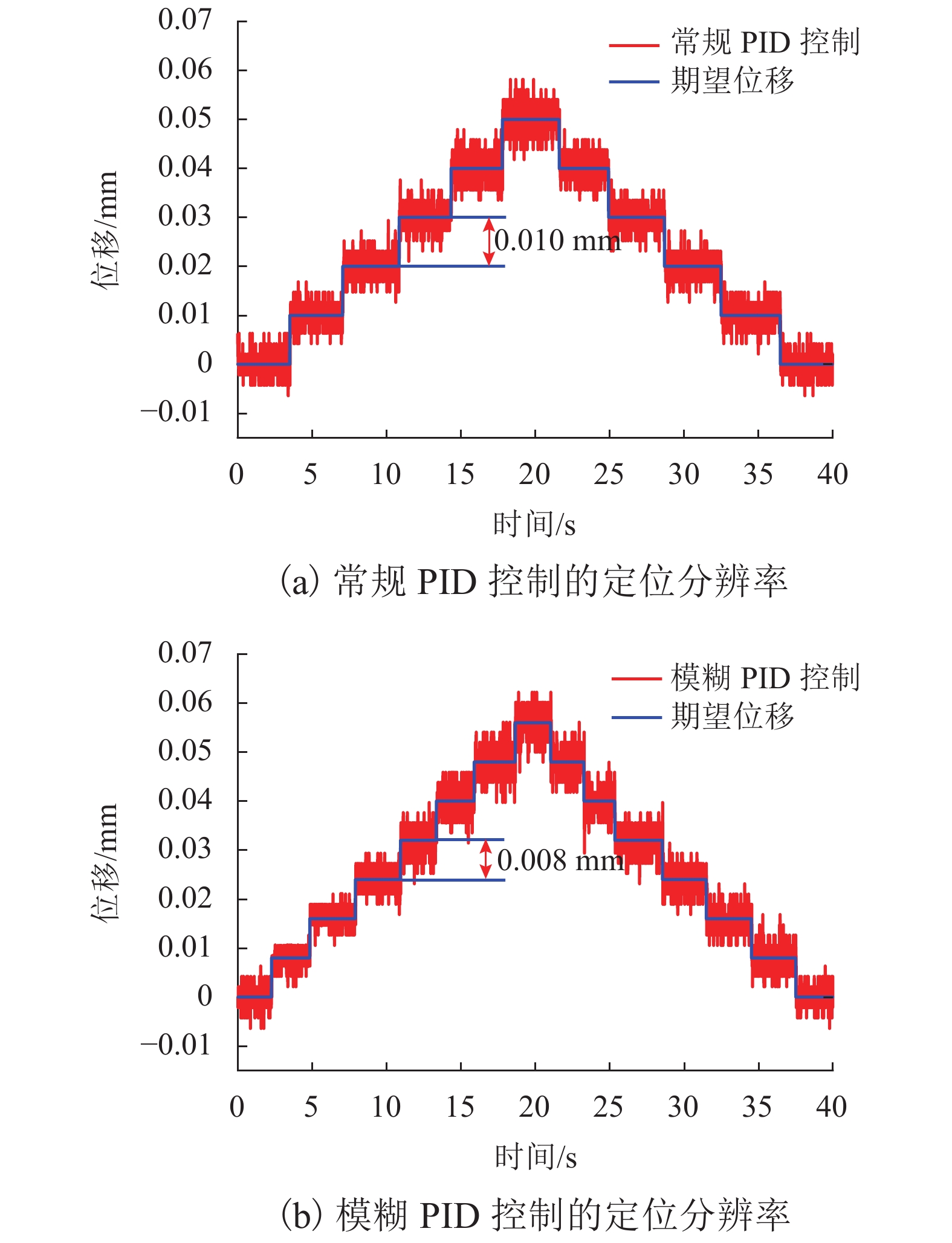
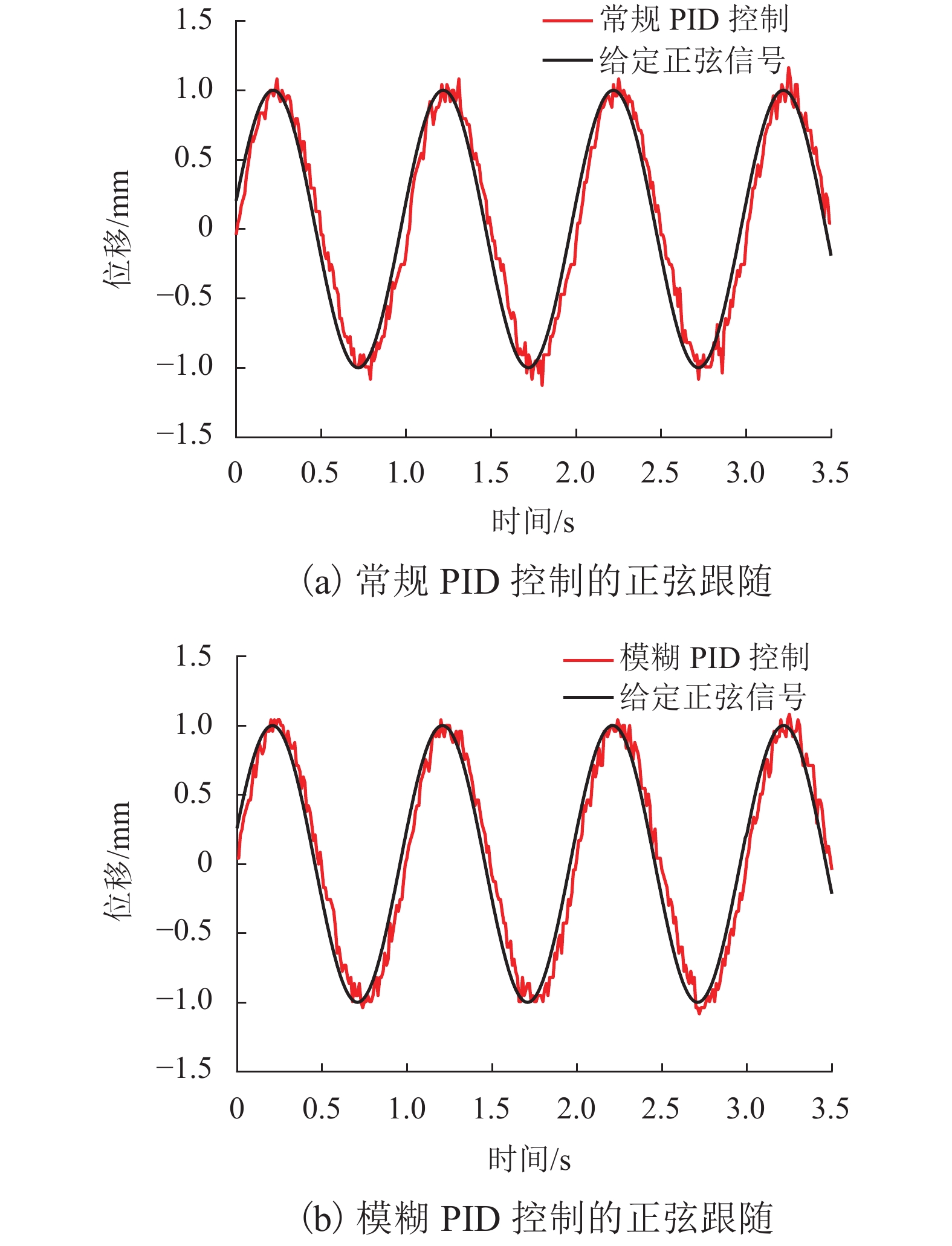
针对传统电火花加工中极间间隙的及时控制问题,提出一种具有高精度、响应快、宽频带、长行程的单自由度磁力驱动器,采用磁力驱动器作为电火花加工的局部执行机构,并设计了一种模糊PID控制方法在线实时修正PID控制参数,优化磁力驱动器控制系统. 首先, 分析了磁力驱动器装置的动力学模型,获得通入线圈电流与磁力驱动器动子位移之间的变换关系;其次, 根据磁力驱动器装置特点设计了常规PID控制器,并引入模糊控制对微定位控制性能进行优化;最后, 通过对磁力驱动器的微定位仿真和实验验证了控制器的控制效果. 仿真和实验结果表明:该磁力驱动器具有微米级的定位分辨率、大于50 Hz的宽频带和2 mm的定位行程,完全满足电火花加工微调要求.
Abstract:For timely controlling the gap between poles in electrical discharge machining (EDM), a single-degree-of-freedom magnetic actuator is designed with merits of high precision, fast response, wide frequency band and long stroke. As the local actuator in EDM, it is optimized by a fuzzy PID control method that modify the control parameters online and in real time. Firstly, the dynamic model of the magnetic actuator device is analyzed, and the transformation relationship is built between the coil current and the mover displacement in the magnetic actuator. Secondly, a conventional PID controller is designed according to the characteristics of the magnetic actuator device, and fuzzy control is introduced to optimize the performance of micro-positioning control. Finally, the controller performance is verified by the micro-positioning simulation and experiment on the magnetic actuator. Simulation and experimental results show that the magnetic actuator has a micron-level positioning resolution, a wide frequency band greater than 50 Hz, and a positioning stroke of 2 mm, which fully meets the fine-tuning requirements of EDM.
-

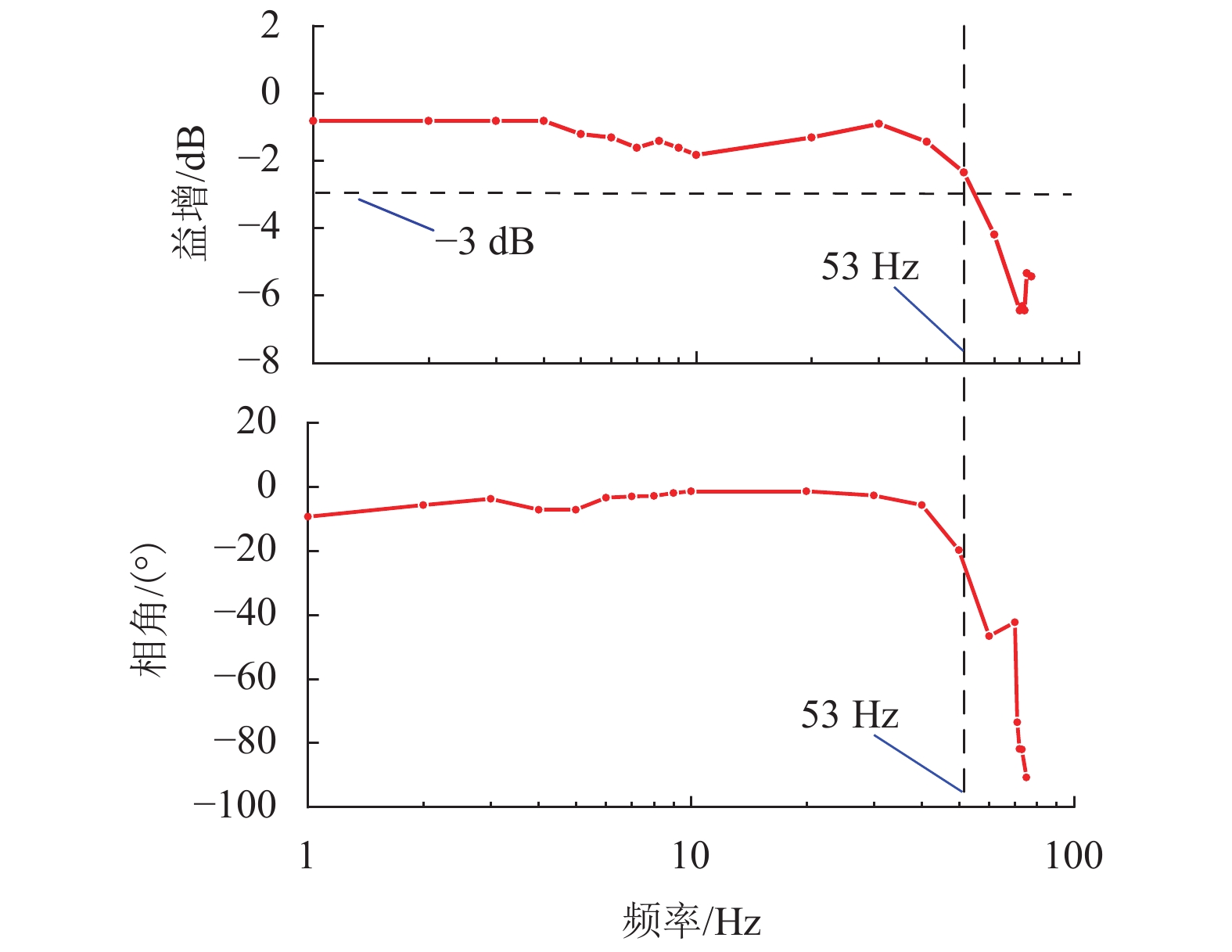
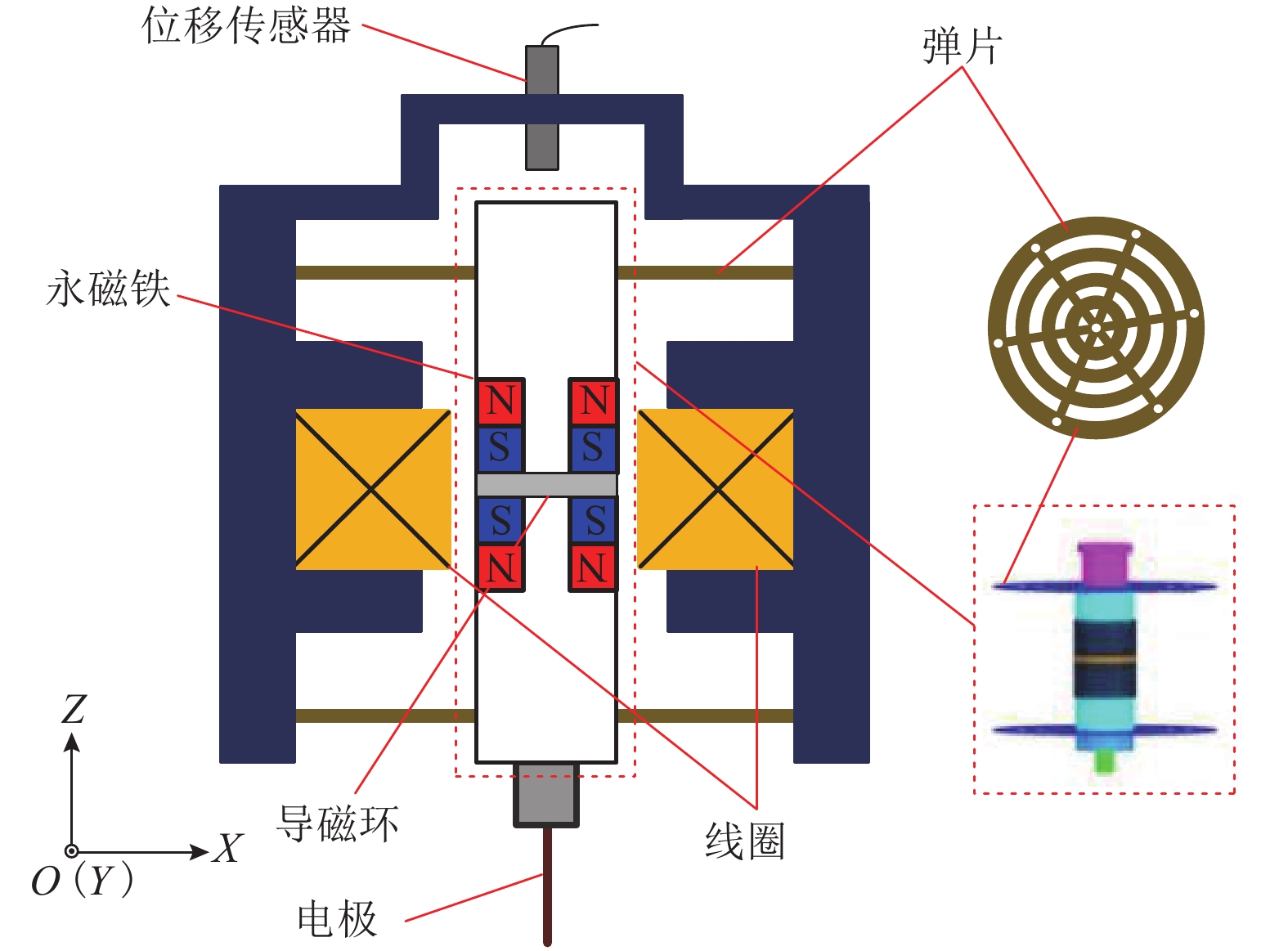
图 7 磁力驱动器位移控制实验平台
Figure 7. Experimental platform for displacement control of magnetic actuator
表 1 受力模型实验参数
Table 1. Test parameters of force model
M/kg c/(N•s•m−1) k/(×103 N•m−1) Ki(/N•A−1) Ff/N 0.27 0 5.425 5.66 0  下载: 导出CSV
下载: 导出CSV
表 2 ΔKP的模糊控制规则
Table 2. Fuzzy-control rules of ΔKP
输入 语言值 E NB NM NS ZO PS PM PB CE NB PB PB PM ZO ZO ZO NS NM PB PM PM ZO ZO NS NS NS PM PM PS NS NS NS PM ZO PM PS PS NS NS NM NM PS PM PS PS NS NM NM NB PM PS PS ZO NM NM NB NB PB ZO ZO ZO NM NB NB NB
下载: 导出CSV
表 3 ΔKI的模糊控制规则
Table 3. Fuzzy-control rules of ΔKI
输入 语言值 E NB NM NS ZO PS PM PB CE NB NB NB NM NM NS ZO ZO NM NB NM NM NS NS ZO ZO NS NM NM NS NS ZO PS PS ZO NM NS NS ZO PS PS PM PS NM NS ZO PS PM PM PB PM ZO ZO PS PM PM PB PB PB ZO ZO PS PM PB PB PB
下载: 导出CSV
表 4 ΔKD的模糊控制规则表
Table 4. Fuzzy-control rules of ΔKD
输入 语言值 E NB NM NS ZO PS PM PB CE NB PS NS NM NB NB NB PM NM ZO NS NM NB NM NS ZO NS ZO NS NM NM NM NS ZO ZO ZO NS NS NM NS NS ZO PS ZO ZO ZO ZO ZO ZO ZO PM PB PM PM PS PS PM PB PB PB PB PM PS PS PM PB
下载: 导出CSV
-
[1] LI H, DENG Z, HUANG H, et al. Experiments and simulations of the secondary suspension system to improve the dynamic characteristics of HTS maglev[J]. IEEE Transactions on Applied Superconductivity, 2021, 31(6): 1-8. [2] 蒋启龙,梁达,阎枫. 数字单周期电流控制在电磁悬浮系统中的应用[J]. 西南交通大学学报,2019,54(1): 1-8, 22.JIANG Qilong, LIANG Da, YAN Fang. Application of Digital One-Cycle Control for Current in Electromagnetic Suspension System[J]. Journal of Southwest Jiaotong University, 2019, 54(1): 1-8, 22. [3] 张伟煜,朱熀秋,袁野. 磁悬浮轴承应用发展及关键技术综述[J]. 电工技术学报,2015,30(12): 12-20. doi: 10.3969/j.issn.1000-6753.2015.12.002ZHANG Weiyu, ZHU Huangqiu, YUAN Ye. Study on key technologies and Applications of magnetic bearings[J]. Transactions of China Electrotechnical Society, 2015, 30(12): 12-20. doi: 10.3969/j.issn.1000-6753.2015.12.002 [4] 姚京京,郑德智,马康,等. 多轴悬浮式低频振动传感器的理论研究[J]. 北京航空航天大学学报,2018,44(7): 1481-1488.YAO Jingjing, ZHENG Dezhi, MA Kang, et al. Theoretical research on muti-axis maglev low-frequency vibration sensor[J]. Journal of Beijing University of Aeronautics and Astronautic, 2018, 44(7): 1481-1488. [5] 郜浩楠,徐俊,蒲晓晖,等. 面向新能源汽车的悬架振动能量回收在线控制方法[J]. 西安交通大学学报,2020,54(4): 19-26.GAO Haonan, XU Jun, PU Xiaohui, et al. An online control method for energy recovery of suspension vibration of new energy vehicles[J]. Journal of Xi’an Jiaotong University, 2020, 54(4): 19-26. [6] ZHU H Y, TEO D, PANG C K. Magnetically levitated parallel actuated dual-stage (Maglev-PAD) system for six-axis precision positioning[J]. Transactions on Mechatronics, 2019, 24(4): 1829-1838. doi: 10.1109/TMECH.2019.2928978 [7] 李红伟,范友鹏,张云鹏,等. 轴流式人工心脏泵混合磁悬浮系统的耦合特性[J]. 电机与控制学报,2014,18(5): 105-111. doi: 10.3969/j.issn.1007-449X.2014.05.017LI Hongwei, FAN Youpeng, ZHANG Yunpeng. Coupling in hybrid magnetic levitation system of axial-flow blood pump[J]. Electric Machines and Control, 2014, 18(5): 105-111. doi: 10.3969/j.issn.1007-449X.2014.05.017 [8] 佟玲,吴利平,金嘉琦,等. 激光焦点控制磁力驱动的控制特性实验对比分析[J]. 国防科技大学学报,2018,40(3): 120-126. doi: 10.11887/j.cn.201803019TONG Ling, WU Lingping, JIN Jiaqi, et al. Experimental comparative analysis of control characteristics of laser focus control magnetic force drive[J]. Journal of National University of Defense Technology, 2018, 40(3): 120-126. doi: 10.11887/j.cn.201803019 [9] FENG Y, GUO Y F, LING Z B, et al. Micro-holes EDM of superalloy Inconel 718 based on a magnetic suspension spindle system[J]. Journal of Advanced Manufacturing Technology, 2019, 101(5/6/7/8): 2015-2026. doi: 10.1007/s00170-018-3075-6 [10] FENG Y, GUO Y F, LING Z B, et al. Investigation on machining performance of micro-holes EDM in ZrB2-SiC ceramics using a magnetic suspension spindle system[J]. The International Journal of Advanced Manufacturing Technology, 2019, 101(5): 2083-2095. [11] ZHANG X Y, TADAHIKO S, AKIRA S. High-speed electrical discharge machining by using a 5-DOF controlled maglev local actuator[J]. Journal of Advanced Mechanical Design, Systems, and Manufacturing, 2008, 2(4): 493-503. doi: 10.1299/jamdsm.2.493 [12] REPINALDO J P, KOROISHI E H, LARA-MOLINA F A, et al. Neuro-fuzzy control applied on a 2DOF structure using electromagnetic actuators[J]. IEEE Latin America Transactions, 2021, 19(1): 75-82. doi: 10.1109/TLA.2021.9423849 [13] LI X H, WAN S K, YUAN J P, et al. Active suppression of milling chatter with LMI-based robust controller and electromagnetic actuator[J]. Journal of Materials Processing Technology, 2021, 297: 117238. doi: 10.1016/j.jmatprotec.2021.117238 [14] ZHENG T, XU X Z, LU X, et al. Learning adaptive sliding mode control for repetitive motion tasks in maglev rotary table[J]. Transactions on Industrial Electronics, 2021, 69(2): 1836-1846. [15] 朱熀秋, 顾志伟. 基于模糊神经网络逆系统的五自由度无轴承永磁同步电机自抗扰控制[J]. 电机与控制学报,2021,25(2): 72-81.ZHU Huangqiu, GU Zhiwei. Active disturbance rejection control for 5-degree-of-freedom bearingless permanent magnet synchronous motor based on inverse system using the fuzzy neural network[J]. Electric Machines and Control, 2021, 25(2): 72-81. [16] CHEN J W. Modeling and decoupling control of a linear permanent magnet actuator considering fringing effect for precision engineering[J]. IEEE Transactions on Magnetics, 2021, 57(3): 1965-2012. [17] 林超力,刘鸿飞,孙惠军,等. 模糊自适应PID算法在核磁共振谱仪样品旋转控制系统中的应用[J]. 分析化学,2011,39(4): 506-510.LIN Chaoli, LIU Hongfei, SUN Huijun, et al. Implementation of fuzzy self-tuning proportional integral derivative controller on sample-tube spin control system in nuclear magnetic resonance spectrometer[J]. Chinese Journal of Analytical Chemistry, 2011, 39(4): 506-510. [18] ZHANG X Y, UEYAMA Y, SHINSHI T, ec al. High-speed and high-accuracy EDM of micro holes by using a 5-DOF controlled maglev local actuator[J]. Materials Science Forum, 2009, 2(4): 255-260. -

 下载:
下载:





 点击查看大图
点击查看大图
计量
- 文章访问数: 450
- HTML全文浏览量: 225
- PDF下载量: 18
- 被引次数: 0