

Spherical Layer Sampling Method for Probability Evaluation on Structural Failure
-
摘要:
传统Monte Carlo抽样方法应用于小失效概率等复杂可靠度问题时,存在效率低下、精度有限等不足,针对这一问题提出一种球层抽样分析方法. 首先,通过分离距离与方向参量,对标准正态随机向量进行重构,并验证其标准正态性与相互独立性;然后,采用分层抽样策略,将半径大于一阶可靠度指标外的正态空间划分为多个球层,进而利用所重构的向量逐层进行抽样,并结合全概率公式,形成估计结构失效概率的球层抽样算法;最后,通过对3个典型算例进行对比分析,验证算法性能. 分析表明:所提出算法具有较高的抽样效率与收敛性能,算例计算结果误差在3%以内;与其他算法相比,其估计方差更小,且可有效解决多设计验算点等复杂可靠度问题;算法在抽样效率、适用范围以及稳定性等方面具有优势,更适用于实际复杂结构可靠度的求解分析.
Abstract:When the traditional Monte Carlo sampling method is applied to complex reliability problems such as small failure probability, there are some shortcomings such as low efficiency and limited accuracy. To solve this problem, a spherical layer sampling analysis method is developed. Firstly, by dividing the distance and direction parameters, the standard normal random vector is reconstructed, and its standard normality and mutual independence are verified. Thereafter, based on a layered sampling strategy, the standard normal space with the radius beyond first order reliability index is divided into multiple spherical layers, which are then sampled by the reconstructed vector layer by layer. Combined with the full probability formula, a spherical layer sampling algorithm is developed to estimate the structural failure probability. Finally, three typical examples are taken as objects of interest, and the performance of the algorithm is verified through comparative analysis. The results show that, the proposed algorithm has high sampling efficiency and convergence performance, and the error of calculation results is within 3%. Compared with other algorithms, its estimation variance is smaller, and it can effectively solve complex reliability problems such as multiple design check points. The algorithm has advantages in sampling efficiency, scope of application, and stability, and is more suitable for solving and analyzing the reliability of actual complex structures.
-
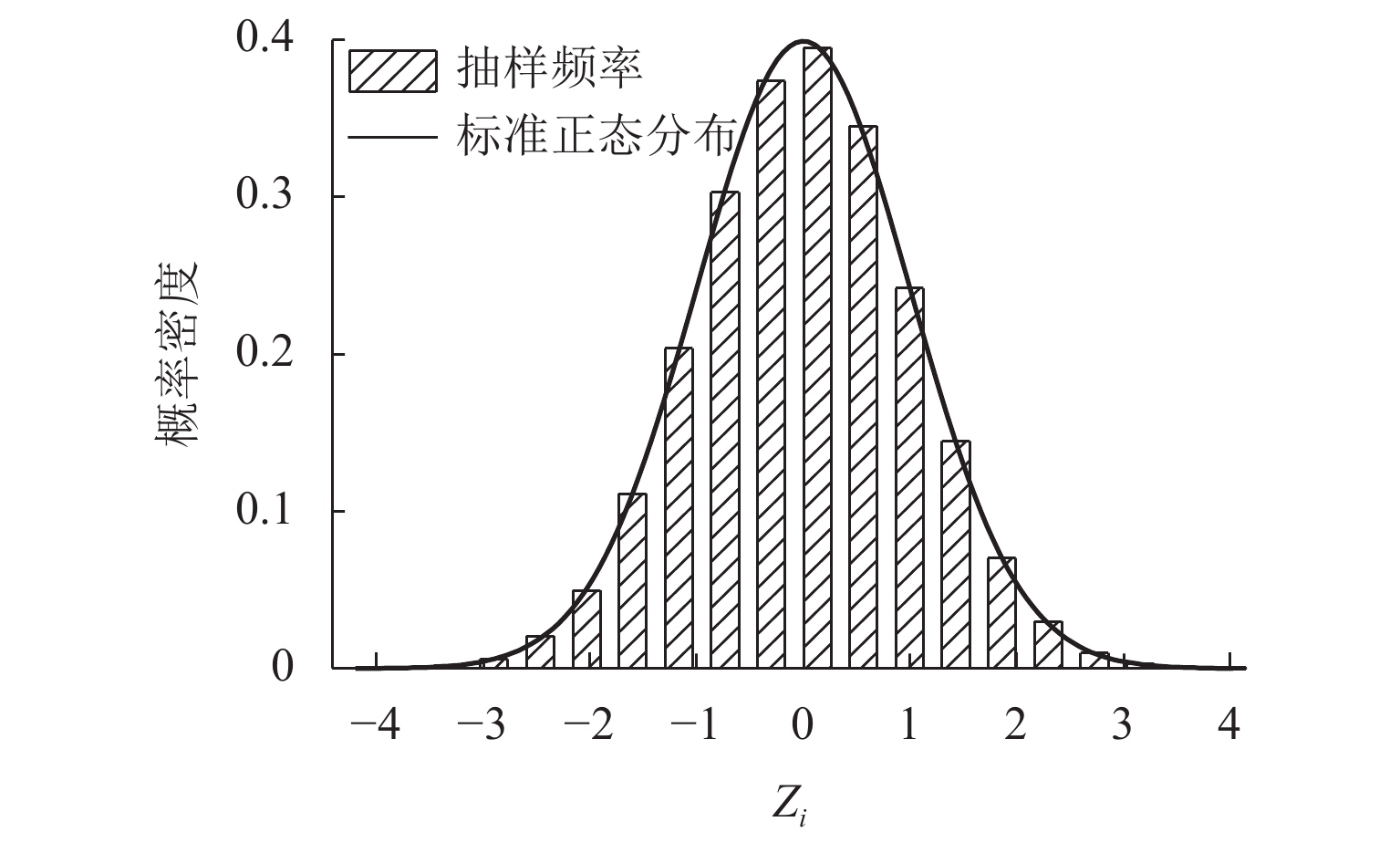
图 2 Zi抽样频率密度与标准正态分布概率密度对比
Figure 2. Fig. 2 Comparison of probability density between Zi sampling and standard normal distribution

图 3 n维标准正态空间中n−1维球面均匀分布
Figure 3. Spherical uniform distribution of n−1 dimensions in standard normal space
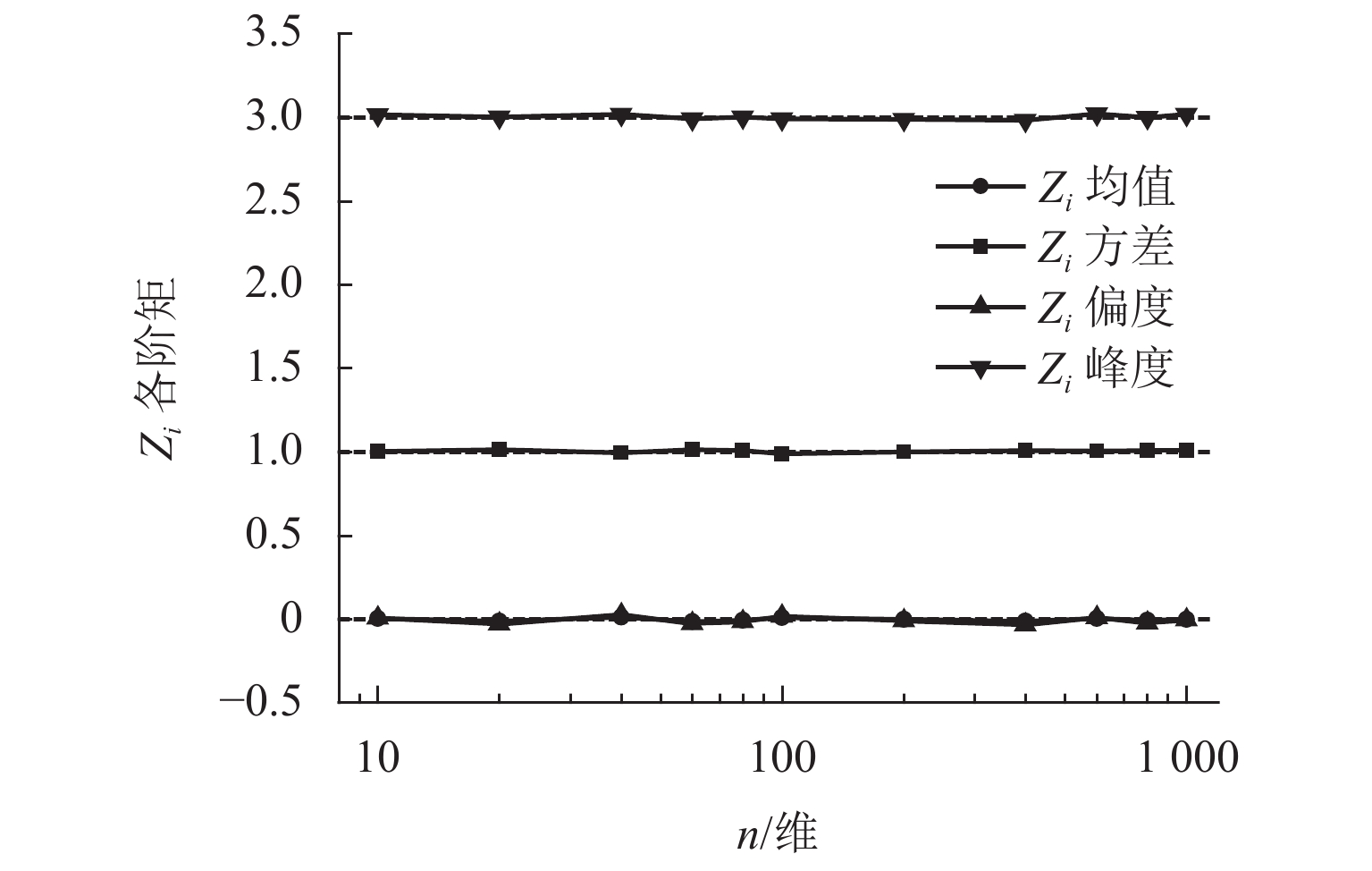
图 4 不同维度下Zi前四阶矩抽样结果
Figure 4. Sampling results of first four-order moments of Zi in different dimensions

图 8 算例1极限状态曲面及球层划分
Figure 8. Limit state surface and spherical layer division in standard normal space for case 1

图 9 算例1球层抽样失效概率变异系数随抽样次数变化
Figure 9. Coefficient of variation in failure probability of spherical layer sampling with sampling times for case 1

图 11 算例3钢斜拉桥最大单悬臂施工工况示意(单位:m)
Figure 11. Illustration of case 3 steel cable-stayed bridge in longest single cantilever construction phase (unit: m)
表 1 算例1不同方法计算结果对比
Table 1. Comparison of calculation results with different sampling methods for case 1
计算方法 抽样
数/次Pf/×10−3 βform 相对误差/% 变异
系数HL-RF 1.832 2.9057 38.3 重要抽样 1000 2.090 2.8642 29.6 0.360 线抽样 1000 1.957 2.8850 34.1 0.004 球层抽样 1000 2.998 2.7480 0.9 0.062 MCS 1×106 2.970 2.7511 注:各算法变异系数结果为重复100次计算得到,后续算例同.  下载: 导出CSV
下载: 导出CSV
表 2 算例2随机变量的分布参数
Table 2. Distribution parameters of random variables for case 2
项目 q/
(kN•m−1)ls/m As/m2 Ac/m2 Es/
GPaEc/
GPa均值 20 12 9.82 × 10-4 0.04 100 20 变异系数 0.07 0.01 0.06 0.12 0.06 0.06
下载: 导出CSV
表 3 算例2不同方法计算结果对比
Table 3. Comparison of calculation results with different sampling methods for case 2
下载: 导出CSV
表 4 算例3抗力不确定性变量分布参数
Table 4. Distribution parameters of resistance random variables for case 3
项目 km kf kp t≤16 mm 16 mm<t≤25 mm 25 mm<t≤38 mm 38 mm<t≤50 mm 偏差系数 1.1511 1.1228 1.0991 1.2074 1.0000 1.0890 变异系数 0.0656 0.0670 0.0843 0.0917 0.0200 0.1080
下载: 导出CSV
表 5 算例3荷载变量分布参数
Table 5. Distribution parameters of temporary load random variables during construction for case 3
项目 桥面吊机和焊接设备 焊接平台 张拉平台 均值/kN 2402 150 399 变异系数 0.0500 0.0500 0.0500
下载: 导出CSV
-
[1] 吕震宙,宋述芳,李洪双,等. 结构机构可靠性及可靠性灵敏度分析[M]. 北京: 科学出版社,2009: 13-85,194-242. [2] MELCHERS R E. Importance sampling in structural systems[J]. Structural Safety, 1989, 6(1): 3-10. doi: 10.1016/0167-4730(89)90003-9 [3] GEYER S, PAPAIOANNOU I, STRAUB D. Cross entropy-based importance sampling using Gaussian densities revisited[J]. Structural Safety, 2019, 76: 15-27. doi: 10.1016/j.strusafe.2018.07.001 [4] KOUTSOURELAKIS P S, PRADLWARTER H J, SCHUËLLER G I. Reliability of structures in high dimensions, part Ⅰ: algorithms and applications[J]. Probabilistic Engineering Mechanics, 2004, 19(4): 409-417. doi: 10.1016/j.probengmech.2004.05.001 [5] SCHUËLLER G I, PRADLWARTER H J, KOUTSOURELAKIS P S. A critical appraisal of reliability estimation procedures for high dimensions[J]. Probabilistic Engineering Mechanics, 2004, 19(4): 463-474. doi: 10.1016/j.probengmech.2004.05.004 [6] 吕召燕,吕震宙,张磊刚,等. 基于条件期望的改进线抽样方法及其应用[J]. 工程力学,2014,31(4): 34-39.LÜ Zhaoyan, LÜ Zhenzhou, ZHANG Leigang, et al. An improved line sampling method and its application based on conditional expectation[J]. Engineering Mechanics, 2014, 31(4): 34-39. [7] AU S K, BECK J L. Estimation of small failure probabilities in high dimensions by subset simulation[J]. Probabilistic Engineering Mechanics, 2001, 16(4): 263-277. doi: 10.1016/S0266-8920(01)00019-4 [8] AU S K, WANG Y. Engineering risk assessment with subset simulation[M]. Singapore: Wiley, 2014: 157-204. [9] KATAFYGIOTIS L S, CHEUNG S H. Application of spherical subset simulation method and auxiliary domain method on a benchmark reliability study[J]. Structural Safety, 2007, 29(3): 194-207. doi: 10.1016/j.strusafe.2006.07.003 [10] KATAFYGIOTIS L, CHEUNG S H, YUEN K V. Spherical subset simulation (S³) for solving non-linear dynamical reliability problems[J]. International Journal of Reliability and Safety, 2010, 4(2/3): 122-138. doi: 10.1504/IJRS.2010.032442 [11] NOWAK A S, COLLINS K R. Reliability of structures [M]. 2nd edition. New York: CRC Press, 2013: 97-100,126-161. [12] 何平. 数理统计与多元统计[M]. 成都: 西南交通大学出版社,2004: 18-27. [13] 盛骤,谢式千,潘承毅. 概率论与数理统计[M]. 4版. 北京: 高等教育出版社,2008: 106-110,135-208. [14] 巩祥瑞,吕震宙,孙天宇,等. 一种新的矩独立重要性测度分析方法及高效算法[J]. 北京航空航天大学学报,2019,45(2): 283-290.GONG Xiangrui, LÜ Zhenzhou, SUN Tianyu, et al. A new moment-independent importance measure analysis method and its efficient algorithm[J]. Journal of Beijing University of Aeronautics and Astronautics, 2019, 45(2): 283-290. [15] GONG W P, JUANG C H, MARTIN J R II, et al. New sampling method and procedures for estimating failure probability[J]. Journal of Engineering Mechanics, 2016, 142(4): 04015107.1-04015107.10. [16] DER KIUREGHIAN A, DAKESSIAN T. Multiple design points in first and second-order reliability[J]. Structural Safety, 1998, 20(1): 37-49. doi: 10.1016/S0167-4730(97)00026-X [17] 白冰. 大跨度钢斜拉桥施工及运营过程系统可靠度研究[D]. 成都: 西南交通大学,2015. [18] CREMONA C. Structural performance: probability-based assessement[M]. London: ISTE,2011. [19] 薛国峰. 结构可靠性和概率失效分析数值模拟方法[D]. 哈尔滨: 哈尔滨工业大学,2010. -

 下载:
下载:





 点击查看大图
点击查看大图

计量
- 文章访问数: 332
- HTML全文浏览量: 382
- PDF下载量: 20
- 被引次数: 0