

Evaluation Difference of Dynamic and Static Track Irregularity and Characteristics of Dynamic Chord Measurement Method
-
摘要:
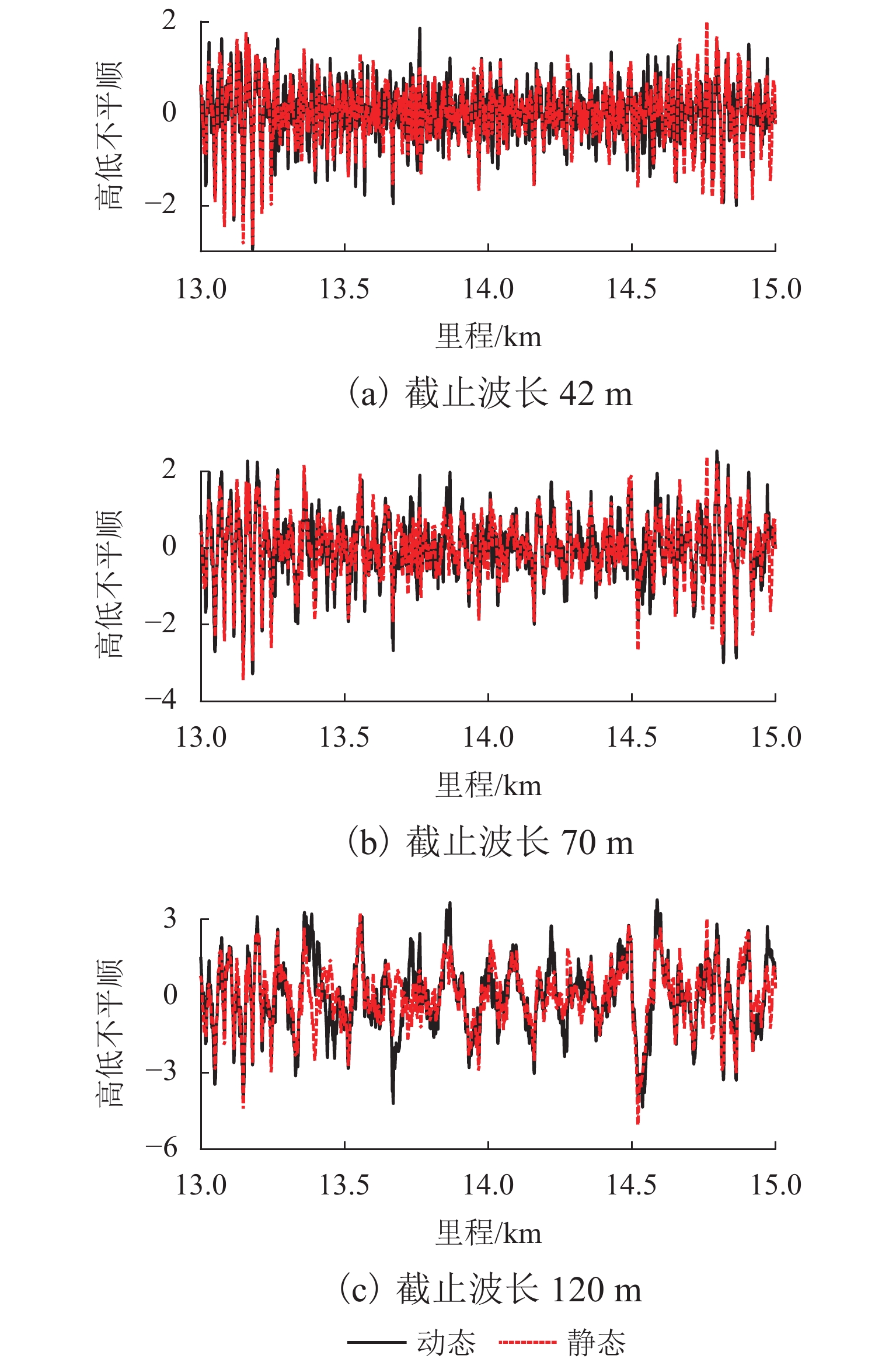
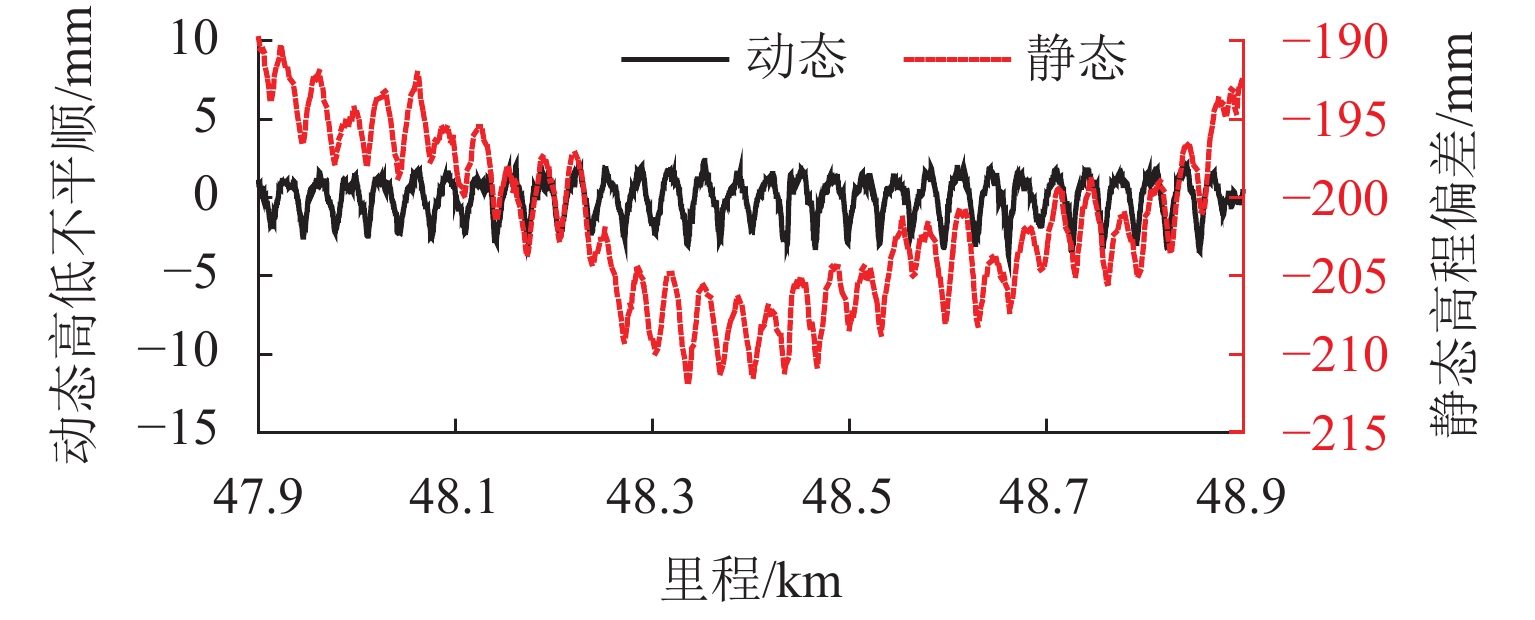
中点弦测法能够有效控制影响行车安全性和舒适性的指定波段轨道不平顺,主要用于测量轨道静态不平顺,但其较低的测量效率制约着轨道“状态修”的发展. 针对上述问题,将轨道动态不平顺按中点弦测输出,分析动静态弦测值差异与弦长和不平顺波长的关联关系,提出能够评价轨道动态平顺性的动态弦测法,研究动态不平顺与静态不平顺间的映射关系. 研究结果表明:42 m和70 m动态高通滤波幅值分别与10 m弦和20 m弦测值变化规律相当;当不平顺波长大于70 m时,120 m动态高通滤波幅值与40 m弦测值变化规律基本对应;截止波长为42、70、120 m的轨道动态不平顺,分别与弦长为20、30 ~ 40、30 ~ 60 m的动态弦测波形相关性最优,对应的动态弦测法最大合理弦长分别为20、30、40 m,通过路基和简支梁区段实测数据验证了动态弦测法的适应性;在路基沉降区段,弦长为60 m时,静态弦测值明显朝负方向偏离动态弦测值的处所为沉降点,相邻两侧朝正方向偏离动态弦测值的处所为沉降区段起终点.
Abstract:The midpoint chord method can effectively control the track irregularity of the designated band that affects the driving safety and comfort. It is mainly used to measure the track static irregularity. However, its low measurement efficiency restricts the development of track ‘state-maintenance’. To solve the above problems, the track dynamic irregularity is output according to the midpoint chord. The correlation between the dynamic and static chord measured values with the chord length and the irregularity wavelength is analyzed. The dynamic track irregularity is outputed according to the midpoint chord measurement. A dynamic chord measurement method is proposed, that can evaluate the dynamic smoothness of the track, and studies the mapping relationship between dynamic irregularity and static irregularity. The results show that, the dynamic high-pass filter amplitudes of 42 m and 70 m are equivalent to the measured values of 10 m chord and 20 m chord respectively. When the irregularity wavelength is greater than 70 m, the 120 m dynamic high-pass filter amplitude basically corresponds to the variation law of 40 m chord measured value. The track dynamic irregularities with cut-off wavelengths of 42, 70 m and 120 m have the best correlation with the dynamic chord measurement waveforms with chord lengths of 20, 30–40 m and 30–60 m respectively. The maximum reasonable chord lengths of the dynamic chord measurement method are 20, 30 m and 40 m respectively. The adaptability of the dynamic chord measurement method has been verified by the measured data of subgrade and simply supported beam sections. In the subgrade settlement section, when the chord length is 60 m, the place where the static chord measurement value deviates significantly from the dynamic chord measurement value in the negative direction is the settlement point, and the places where the adjacent two sides deviate from the dynamic chord measurement value in the positive direction are the beginning and end of the settlement section.
-
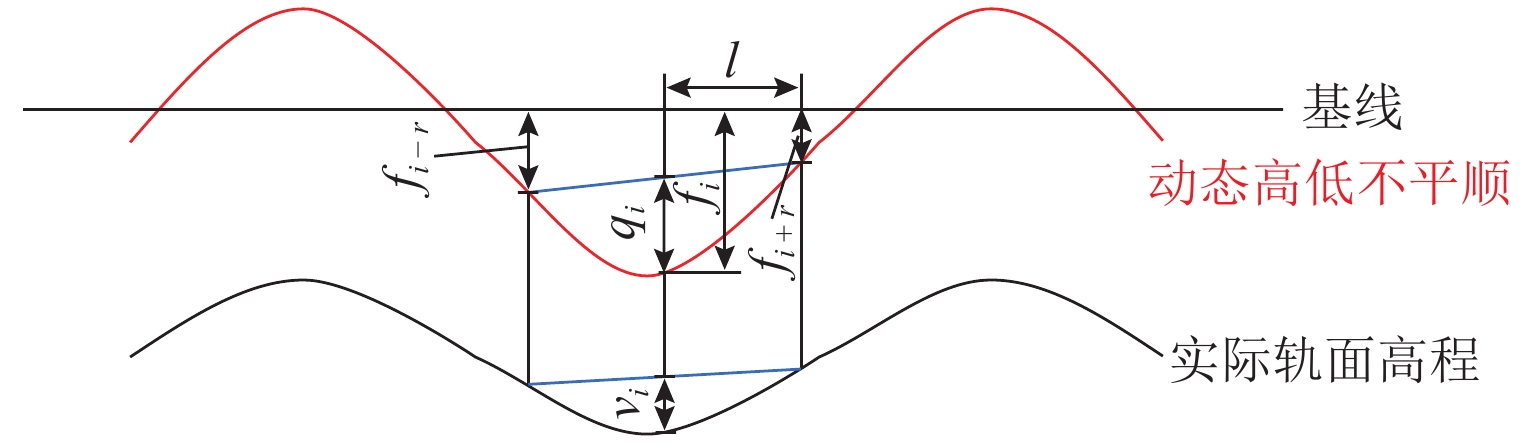
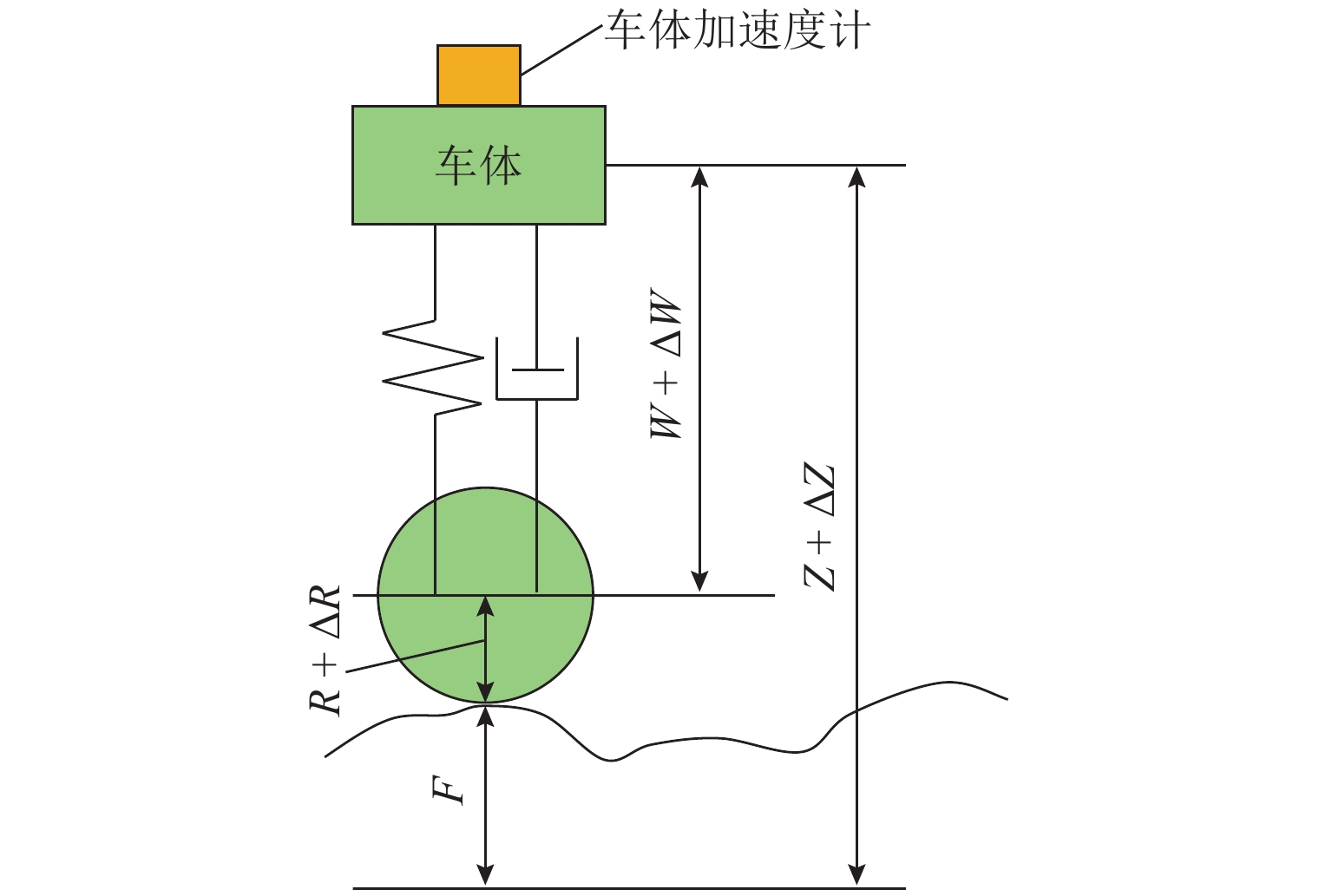
图 2 基于动态弦测法的轨道高低不平顺测量
Figure 2. Track longitudinal level measurements with the dynamic chord method
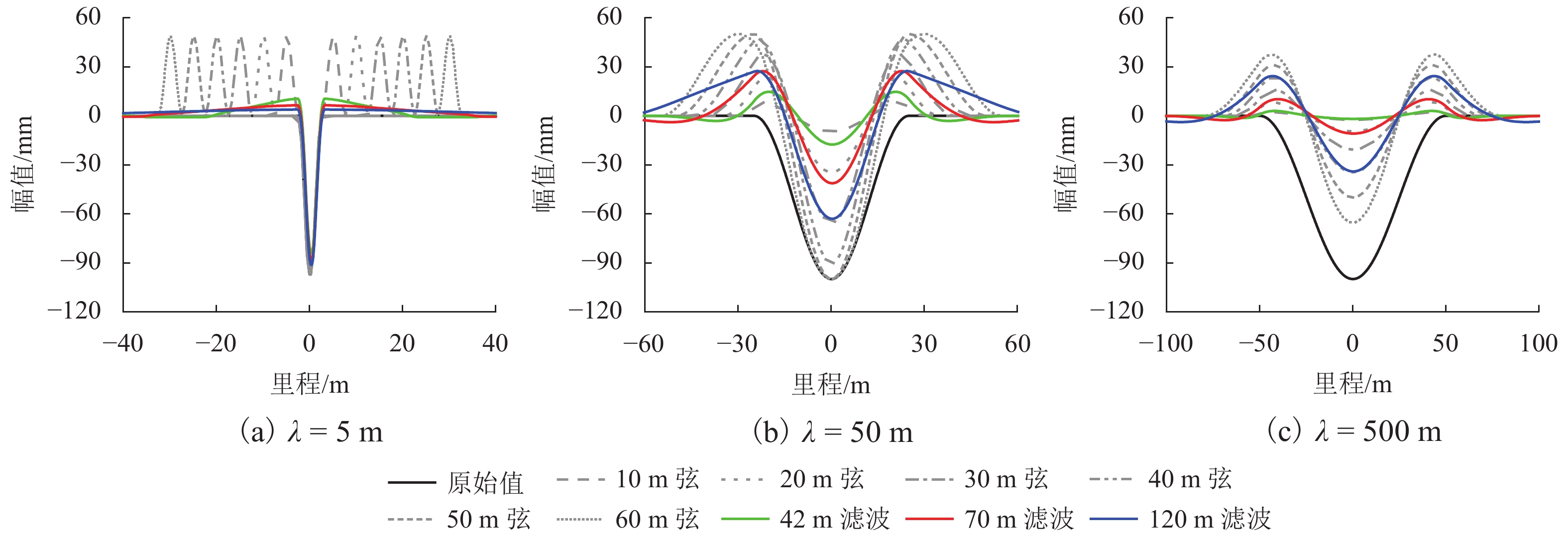
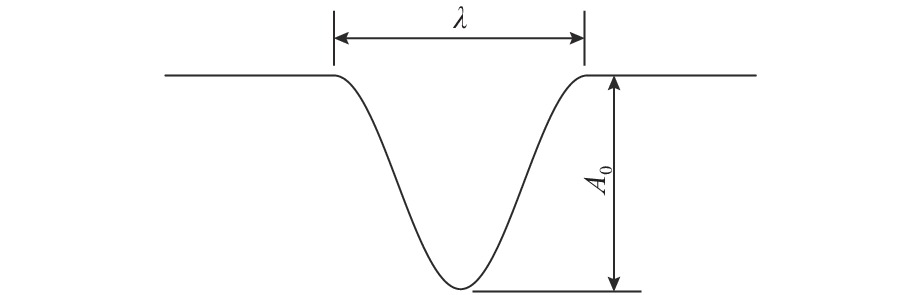
图 5 部分典型余弦型不平顺动、静态波形
Figure 5. Dynamic and static waveforms of some typical cosine irregularities
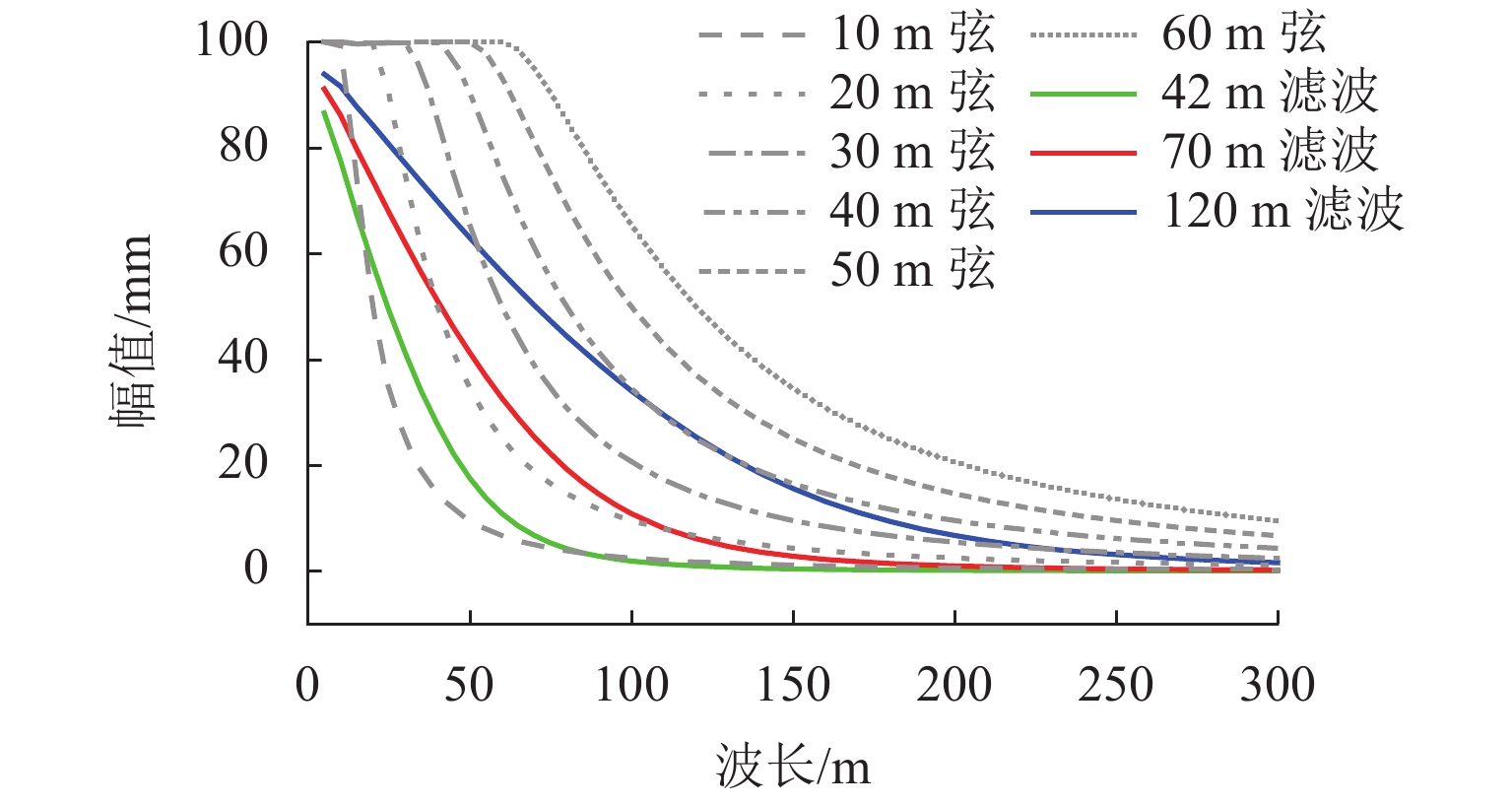
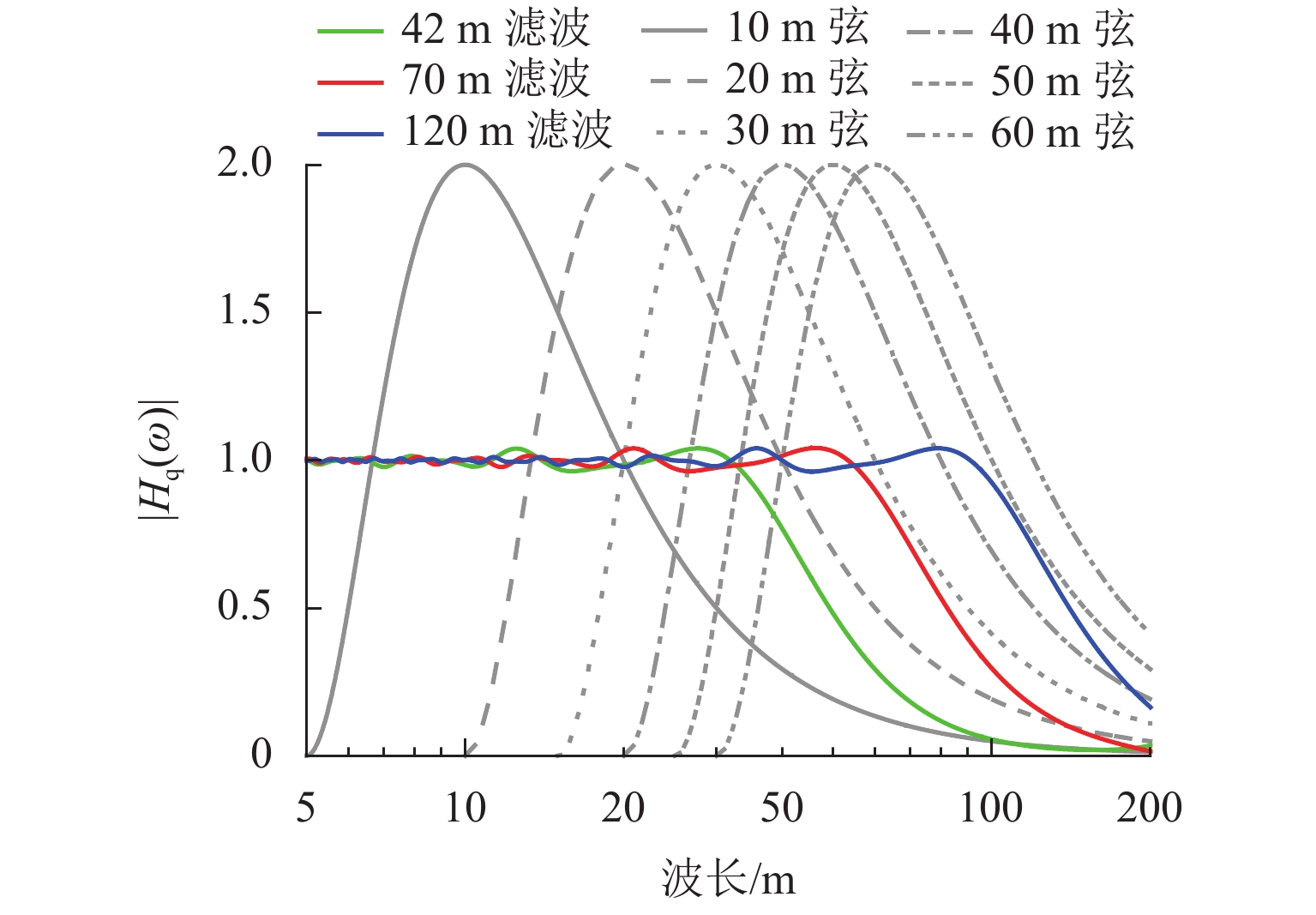
图 6 动、静态不平顺峰值随波长的变化规律
Figure 6. Variation of peak values of dynamic and static irregularity with wavelength
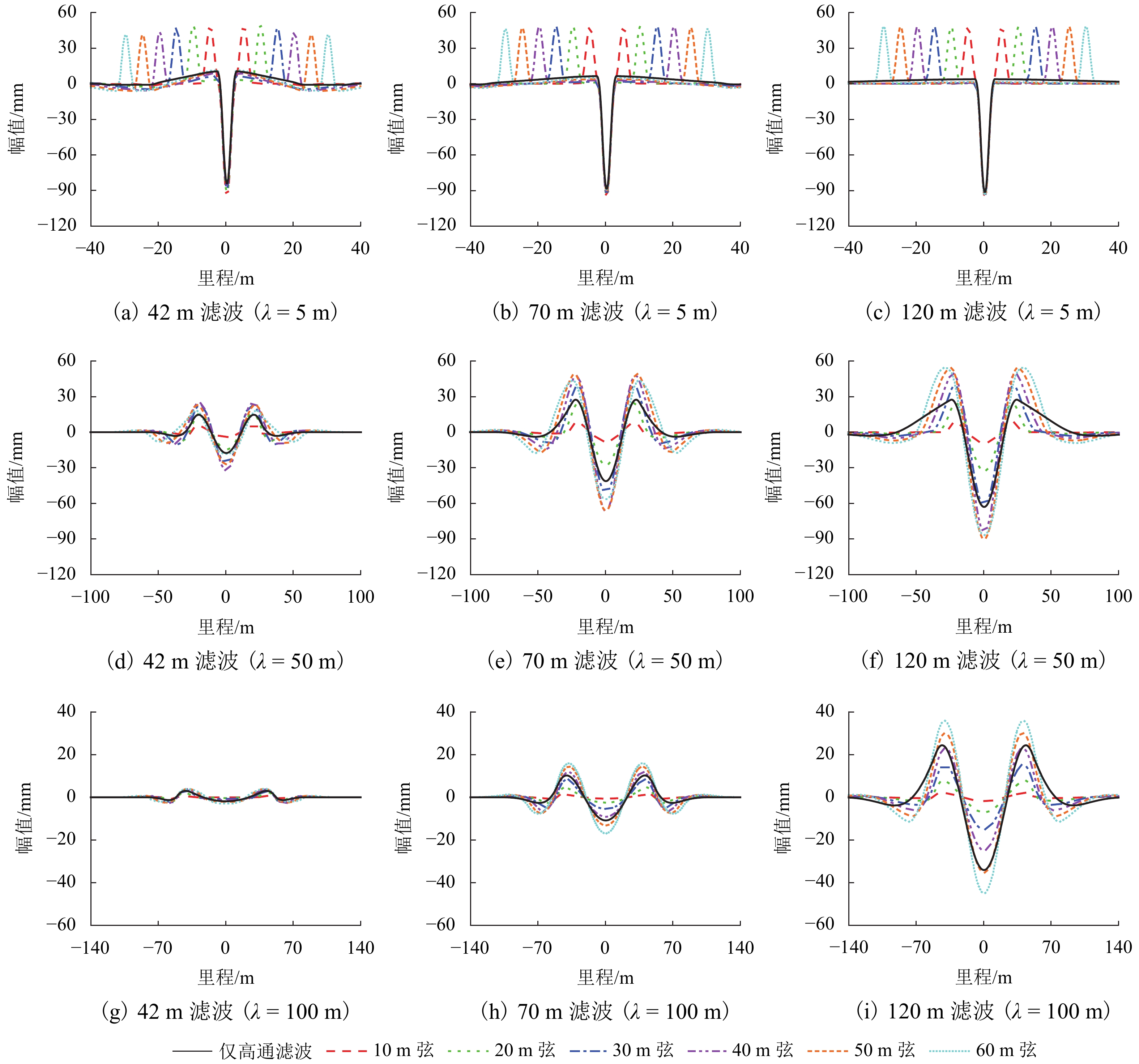
图 7 部分典型余弦型不平顺动态弦对比
Figure 7. Comparison of dynamic chords with some typical cosine irregularities
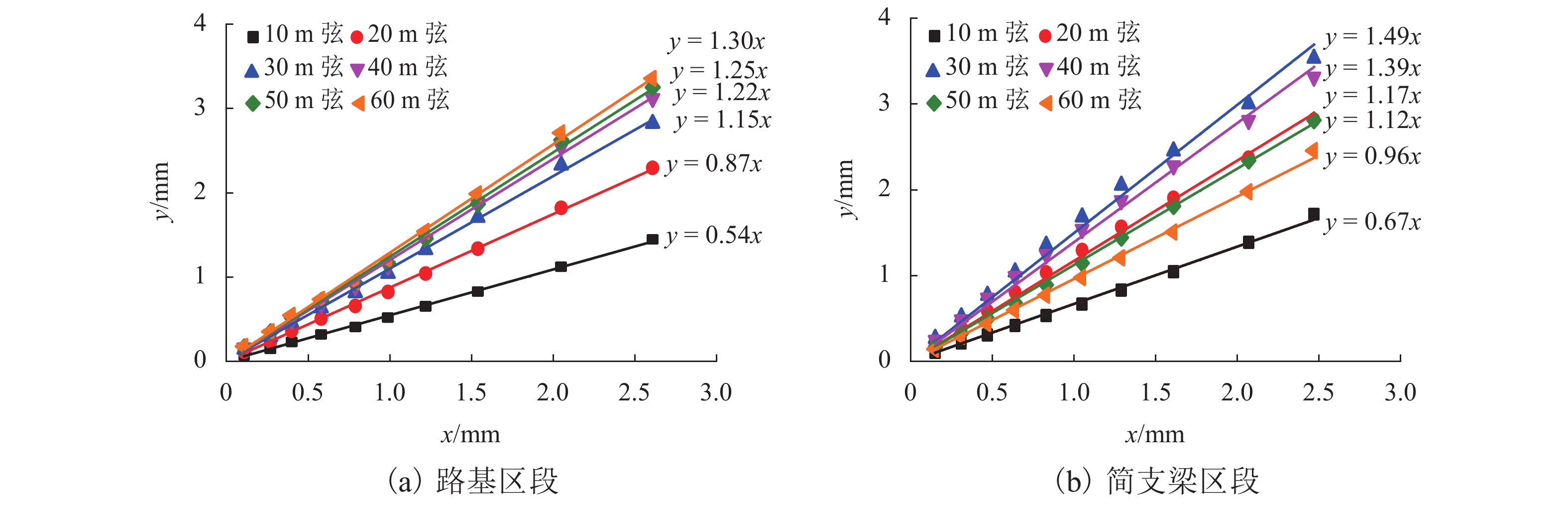
图 9 动态弦与原始动态高低不平顺峰值的关系
Figure 9. Relationship between dynamic chord and original dynamic longitudinal level peak
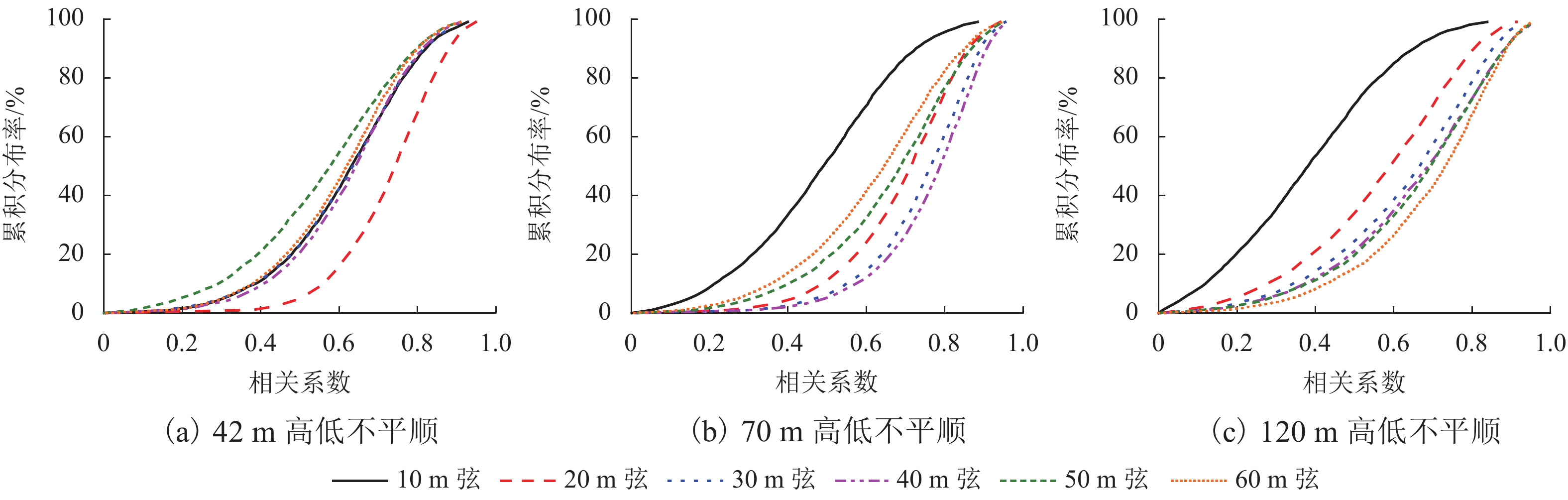
图 10 动态弦与实测动态高低不平顺相关性
Figure 10. Correlation between dynamic chord and measured dynamic longitudinal level
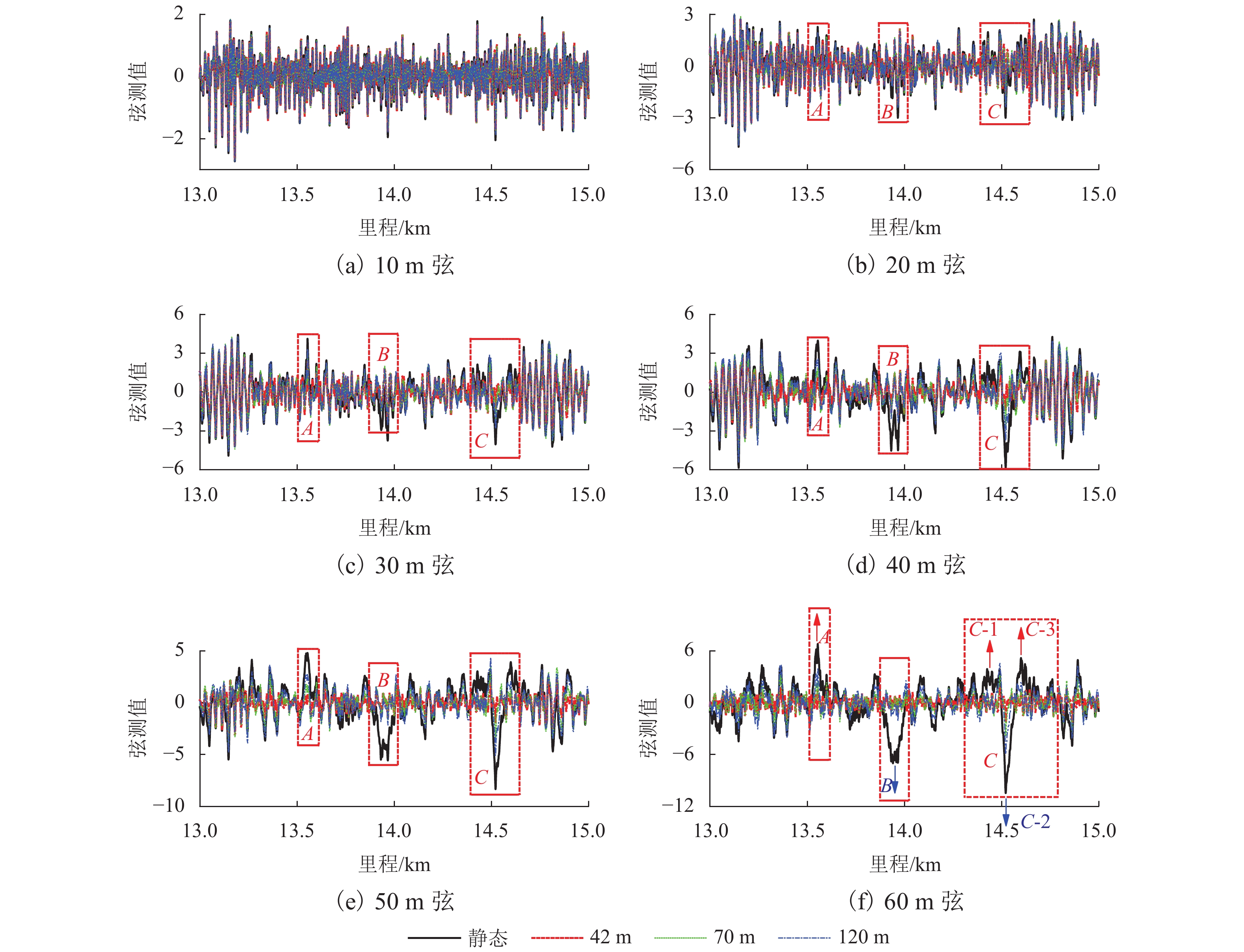
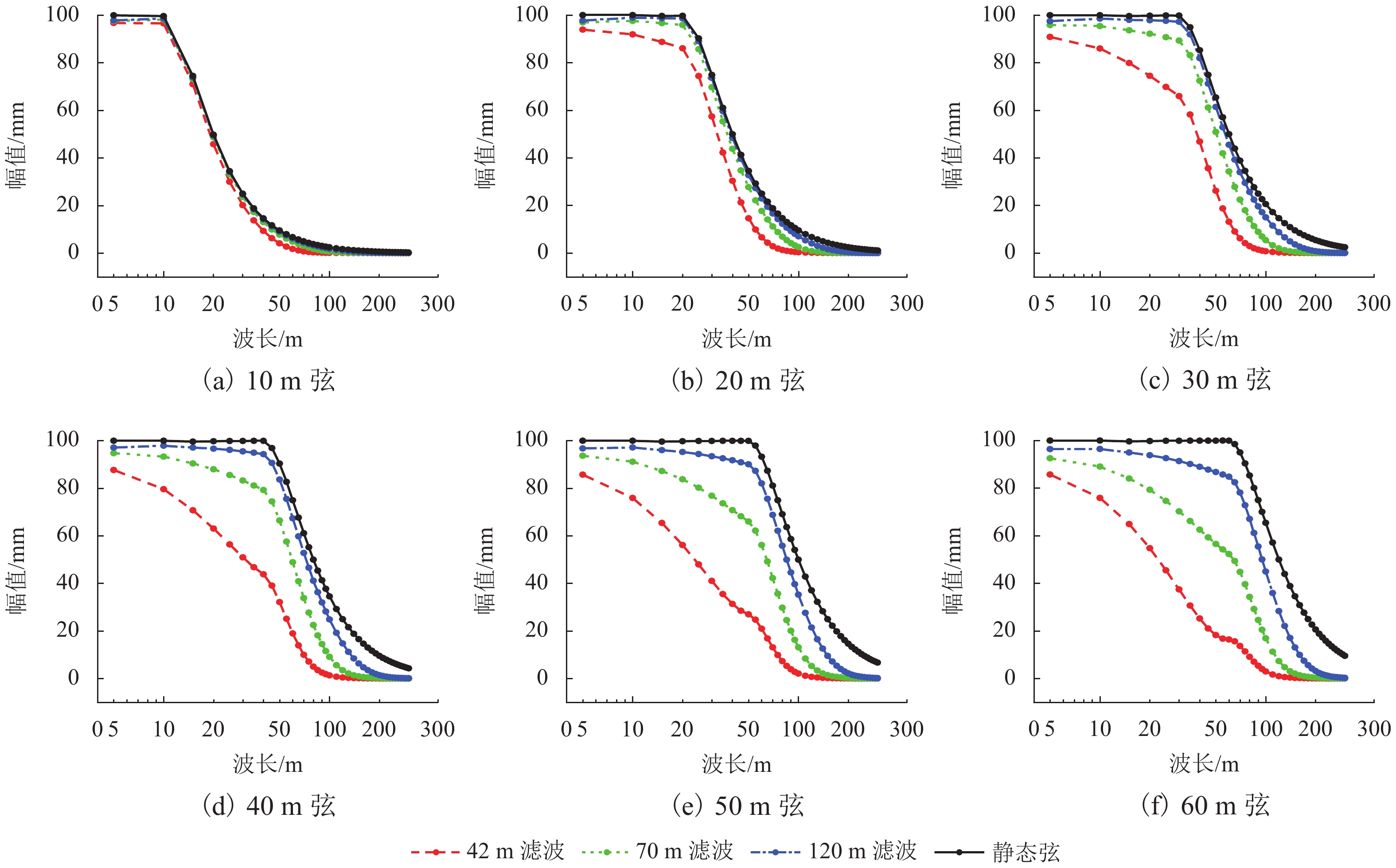
图 13 路基区段动态弦测与静态弦测对比
Figure 13. Comparison between dynamic and static chord measurements in subgrade section
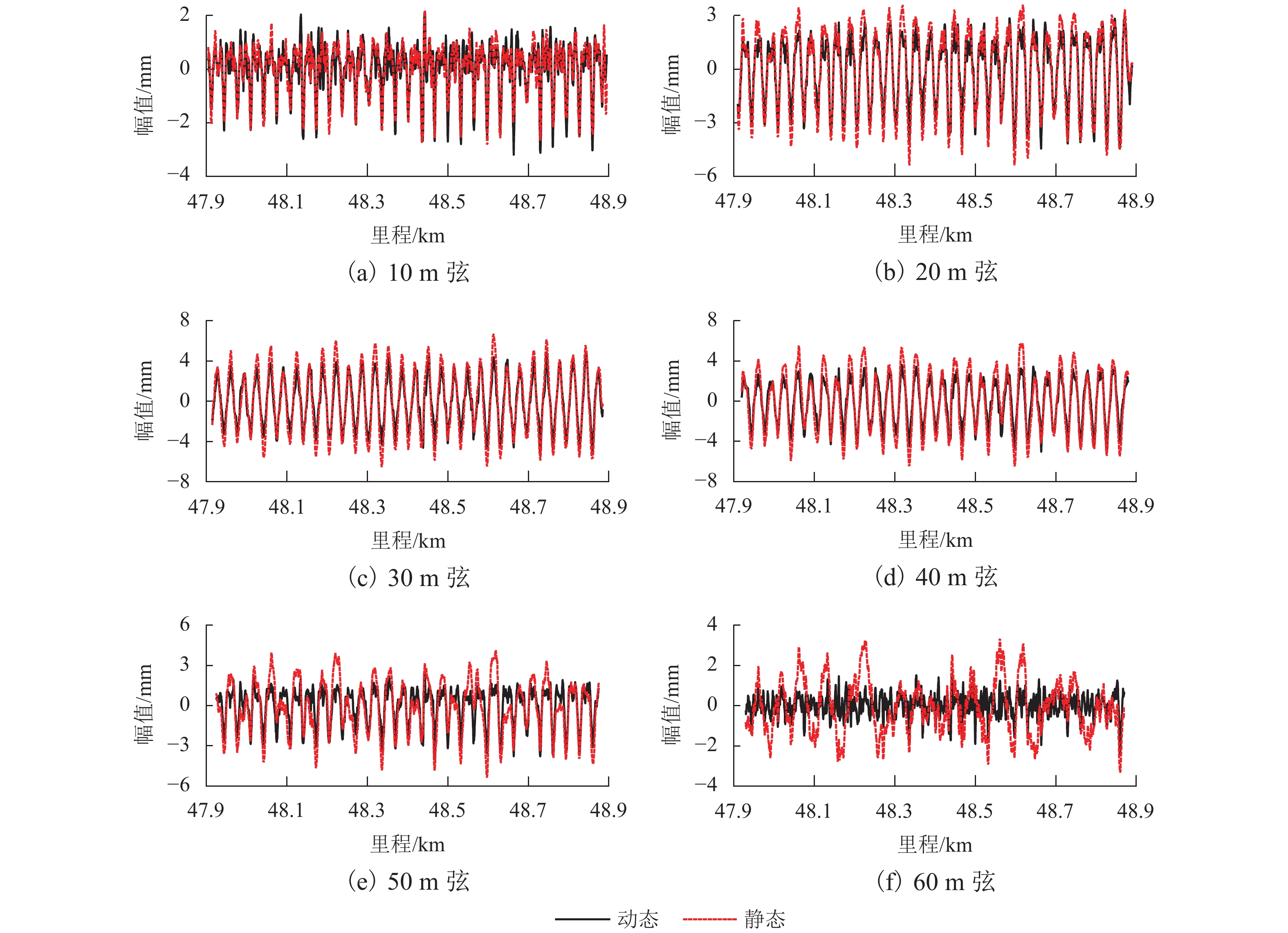
图 15 简支梁区段动态弦测与静态弦测对比
Figure 15. Comparison between dynamic and static chord measurements in simply supported beam section
表 1 动态弦测误差
Table 1. Dynamic chord measurement error
% 截止波长/m 弦长/m 10 20 30 40 50 60 42 5.4 20.0 39.3 58.2 73.2 83.6 70 2.4 7.7 16.6 27.5 39.3 51.0 120 2.2 2.7 6.0 10.4 15.7 21.8  下载: 导出CSV
下载: 导出CSV
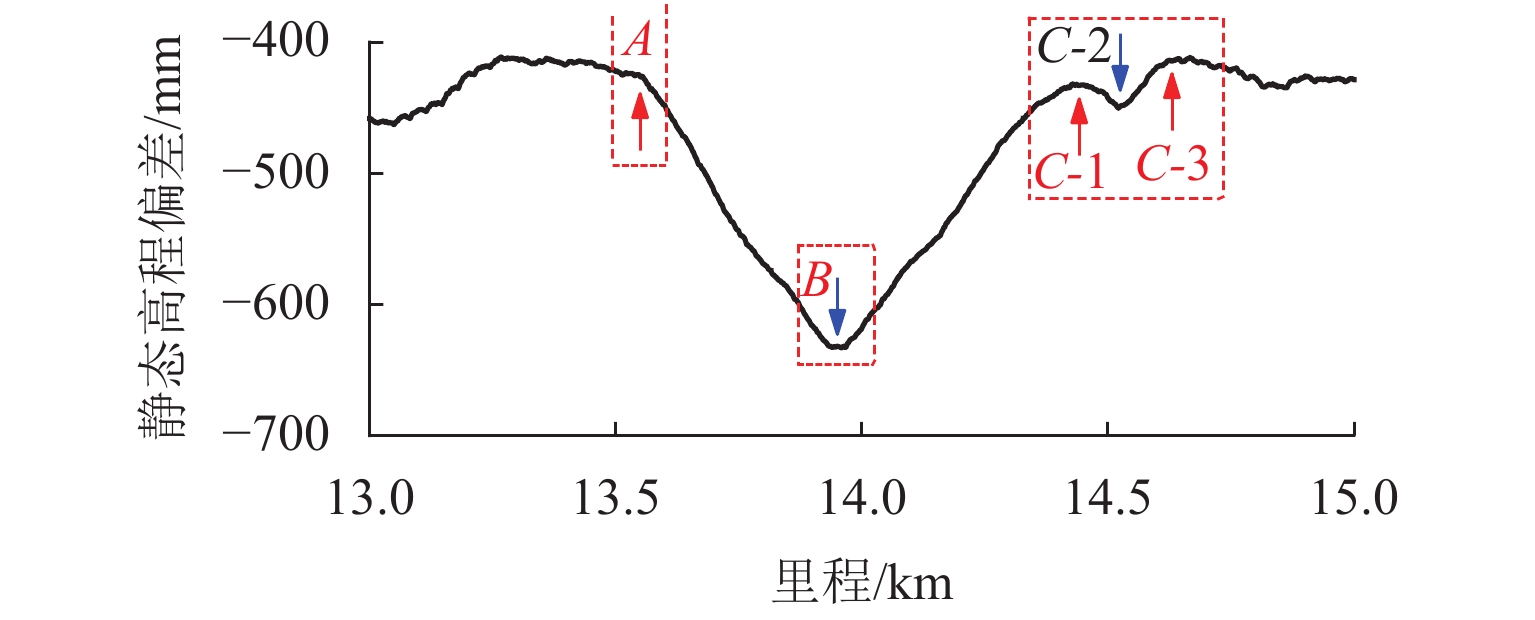
表 2 动态弦测值与静态弦测值峰值差
Table 2. Peak value difference between dynamic chord measurement and static chord measurement mm
弦长/m 截止波长/m 动、静态弦测值峰值差 A B C-1 C-2 C-3 10 42 0.2 0.3 0.1 0.4 0.1 70 0.2 0.2 0.1 0.3 0.1 120 0.1 0.2 0.1 0.2 0.1 20 42 0.8 0.8 0.4 1.3 0.6 70 0.6 0.7 0.4 0.9 0.5 120 0.4 0.6 0.3 0.6 0.3 30 42 1.7 1.5 0.5 2.7 1.3 70 1.2 1.4 0.4 1.9 0.9 120 0.8 1.2 0.3 1.2 0.6 40 42 2.8 2.7 1.4 4.5 0.9 70 2.1 2.6 1.4 3.3 0.7 120 1.4 2.2 1.2 2.2 0.5 50 42 4.0 4.1 2.0 6.4 3.0 70 3.1 4 1.9 4.8 2.6 120 2.0 3.4 1.7 3.2 1.8 60 42 5.2 5.6 2.9 7.7 4.0 70 4.3 5.6 2.7 6.1 3.6 120 2.9 4.8 2.4 4.0 2.5
下载: 导出CSV
-
[1] 罗林, 张格明, 吴旺青, 等. 轮轨系统轨道平顺状态的控制[M]. 北京: 中国铁道出版社, 2006: 62-65 [2] 刘学文,杨怀志,杨飞,等. 基于动静态检测数据的轨道精测精调评价技术[J]. 铁道建筑,2019,59(9): 111-115. doi: 10.3969/j.issn.1003-1995.2019.09.27LIU Xuewen, YANG Huaizhi, YANG Fei, et al. Evaluation technology of track precision measurement and fine adjustment based on dynamic and static detection data[J]. Railway Engineering, 2019, 59(9): 111-115. doi: 10.3969/j.issn.1003-1995.2019.09.27 [3] 杨飞,刘丙强,谭社会,等. 高速铁路轨道静态几何不平顺弦测评价标准体系研究[J]. 铁道建筑,2021,61(6): 107-111,120. doi: 10.3969/j.issn.1003-1995.2021.06.24YANG Fei, LIU Bingqiang, TAN Shehui, et al. Research on evaluation standard system of chord measurement for track static geometric irregularity of high speed railway[J]. Railway Engineering, 2021, 61(6): 107-111,120. doi: 10.3969/j.issn.1003-1995.2021.06.24 [4] 田新宇,高亮,杨飞,等. 基于动态短弦的无砟轨道板周期性不平顺管理标准[J]. 中国铁道科学,2020,41(6): 30-38. doi: 10.3969/j.issn.1001-4632.2020.06.04TIAN Xinyu, GAO Liang, YANG Fei, et al. Management standard for cyclic irregularity of ballastless track slab based on dynamic short chord[J]. China Railway Science, 2020, 41(6): 30-38. doi: 10.3969/j.issn.1001-4632.2020.06.04 [5] 张国锋,高晓蓉,王黎,等. 数字逆滤波技术在轨道不平顺检测中的应用[J]. 信号处理,2004,20(6): 667-670. doi: 10.3969/j.issn.1003-0530.2004.06.030ZHANG Guofeng, GAO Xiaorong, WANG Li, et al. The applying of digital- inverse filtering technology in track irregularity inspection[J]. Signal Processing, 2004, 20(6): 667-670. doi: 10.3969/j.issn.1003-0530.2004.06.030 [6] 程樱,许玉德,周宇,等. 三点偏弦法复原轨面不平顺波形的理论及研究[J]. 华东交通大学学报,2011,28(1): 42-46. doi: 10.3969/j.issn.1005-0523.2011.01.009CHENG Ying, XU Yude, ZHOU Yu, et al. Theory and research of asymmetrical chord offset method of restoring a waveform of track irregularity[J]. Journal of East China Jiaotong University, 2011, 28(1): 42-46. doi: 10.3969/j.issn.1005-0523.2011.01.009 [7] 王源,徐金辉,陈嵘,等. 基于中点弦测法的轨道不平顺精确值数学模型研究[J]. 铁道建筑,2015,55(5): 139-143. doi: 10.3969/j.issn.1003-1995.2015.05.35WANG Yuan, XU Jinhui, CHEN Rong, et al. Research on mathematical model of accurate value of track irregularity based on midpoint chord measurement method[J]. Railway Engineering, 2015, 55(5): 139-143. doi: 10.3969/j.issn.1003-1995.2015.05.35 [8] 魏晖,朱洪涛,殷华,等. 高铁轨道平顺性的150 m/300 m校验及其快速测量[J]. 铁道工程学报,2015,32(1): 44-48,54. doi: 10.3969/j.issn.1006-2106.2015.01.009WEI Hui, ZHU Hongtao, YIN Hua, et al. 150 m/300 m check for the irregularities of HSR and its rapid survey[J]. Journal of Railway Engineering Society, 2015, 32(1): 44-48,54. doi: 10.3969/j.issn.1006-2106.2015.01.009 [9] 杨飞,赵文博,高芒芒,等. 运营期高速铁路轨道长波不平顺静态测量方法及控制标准[J]. 中国铁道科学,2020,41(3): 41-49. doi: 10.3969/j.issn.1001-4632.2020.03.05YANG Fei, ZHAO Wenbo, GAO Mangmang, et al. Static measurement method and control standard for long-wave irregularity of high-speed railway track during operation period[J]. China Railway Science, 2020, 41(3): 41-49. doi: 10.3969/j.issn.1001-4632.2020.03.05 [10] 赵文博,杨飞,李国龙,等. 高速铁路轨道平顺性静态长弦测量矢距差法数学模型推导及特性分析[J]. 铁道建筑,2020,60(2): 105-109.ZHAO Wenbo, YANG Fei, LI Guolong, et al. Mathematical model derivation and characteristics analysis of vector distance difference method for static long chord measurement of high speed railway[J]. Railway Engineering, 2020, 60(2): 105-109. [11] 魏世斌,李颖,赵延峰,等. GJ-6型轨道检测系统的设计与研制[J]. 铁道建筑,2012,52(2): 97-100. doi: 10.3969/j.issn.1003-1995.2012.02.030 [12] 魏晖,朱洪涛,吴维军,等. 高速铁路长波不平顺的相对测量整道[J]. 铁道建筑,2014,54(8): 95-98. doi: 10.3969/j.issn.1003-1995.2014.08.29 [13] 魏晖,朱洪涛,赵国堂,等. 基于中点弦测模型的无砟轨道精调量迭代求解[J]. 西南交通大学学报,2015,50(1): 131-136. doi: 10.3969/j.issn.0258-2724.2015.01.019WEI Hui, ZHU Hongtao, ZHAO Guotang, et al. Iterative algorithm of HSR ballastless track realignment calculation based on MCO model[J]. Journal of Southwest Jiaotong University, 2015, 50(1): 131-136. doi: 10.3969/j.issn.0258-2724.2015.01.019 [14] 中华人民共和国铁道部. 高速铁路无砟轨道线路维修规则(试行): TG/GW 115—2012 [S]. 北京: 中国铁道出版社, 2012. [15] 杨飞,吴细水,孙宪夫,等. 钢轨轧制不平顺激扰下的动车组动力响应特性[J]. 西南交通大学学报,2022,57(2): 267-276,294.YANG Fei, WU Xishui, SUN Xianfu, et al. Dynamic response characteristics of EMU under excitation of rail straightening irregularity[J]. Journal of Southwest Jiaotong University, 2022, 57(2): 267-276,294. [16] NAGANUMA Y, KOBAYASHI M, OKUMURA T. Inertial measurement processing techniques for track condition monitoring on Shinkansen commercial trains[J]. Journal of Mechanical Systems for Transportation and Logistics, 2010, 3(1): 315-325. doi: 10.1299/jmtl.3.315 [17] 魏世斌,刘伶萍,刘维桢,等. 提速线路轨道长波不平顺检测技术[J]. 中国铁道科学,2010,31(2): 141-144.WEI Shibin, LIU Lingping, LIU Weizhen, et al. Technology for the measurement of long-wavelength track irregularity of speed-up railway[J]. China Railway Science, 2010, 31(2): 141-144. [18] HAIGERMOSER A, LUBER B, RAUH J, et al. Road and track irregularities: measurement, assessment and simulation[J]. Vehicle System Dynamics, 2015, 53(7): 878-957. doi: 10.1080/00423114.2015.1037312 [19] 中国国家铁路集团有限公司. 铁路基础设施动态检测——轨道几何检测系统: Q/CR 751—2020[S]. 北京: 中国铁道出版社, 2020 -

 下载:
下载:

 点击查看大图
点击查看大图
计量
- 文章访问数: 1208
- HTML全文浏览量: 755
- PDF下载量: 138
- 被引次数: 0