

A Survey of Human-Object Interaction Detection
-
摘要:
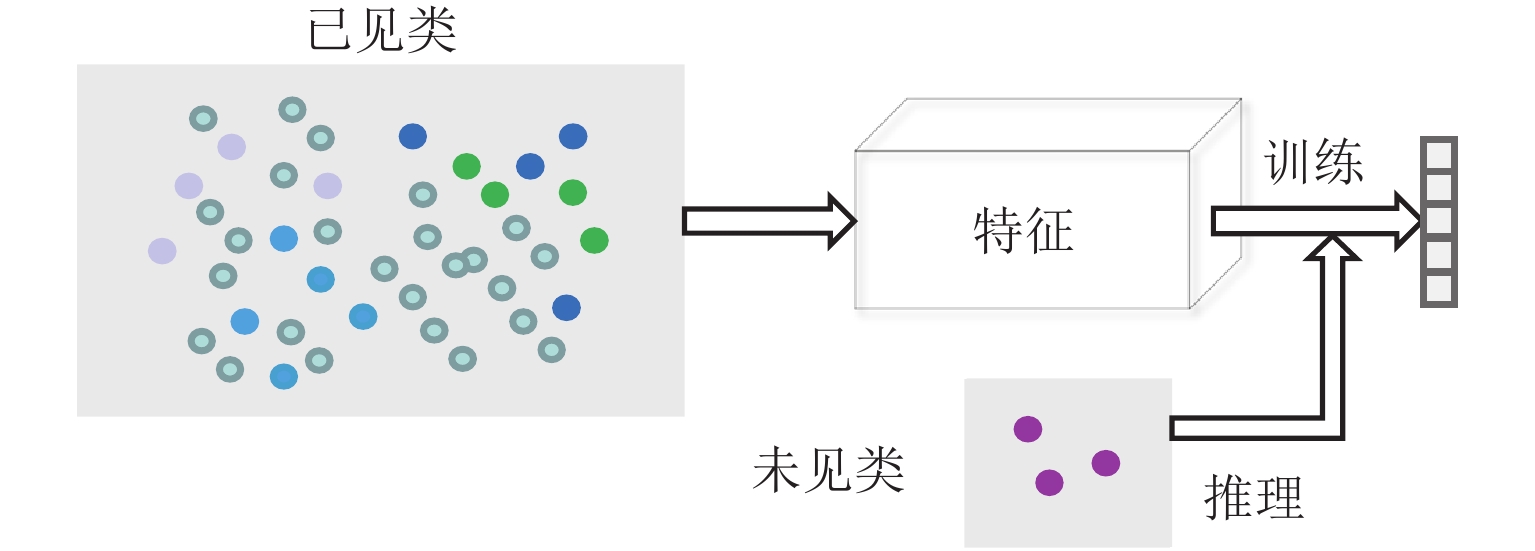
作为目标检测、行为识别、视觉关系检测的交叉学科,人物交互(human-object interaction,HOI)检测旨在识别特定应用场景下人与物体的相互关系. 本文对基于图像的人物交互检测研究成果进行了系统总结及论述. 首先,从交互关系建模的原理出发,把人物交互检测方法分为基于全局实例和基于局部实例两类,并对代表性方法进行了详细阐述和分析;进而,根据所采用视觉特征的差异将基于全局实例的方法进行细分,包括融合空间位置信息、融合外观信息与融合人体姿态信息;然后,讨论了零样本学习、弱监督学习以及Transformer模型在人物交互检测中的应用;最后,从交互类别、视觉干扰以及运动视角三方面出发,总结了人物交互检测面临的挑战,并指出领域泛化、实时检测和端到端网络是未来发展的趋势.
Abstract:As an interdisciplinary subject of object detection, action recognition and visual relationship detection, human-object interaction (HOI) detection aims to identify the interaction between humans and objects in specific application scenarios. Here, recent work in the field of image-based HOI detection is systematically summarized. Firstly, based on the theory of interaction modeling, HOI detection methods can be divided into two categories: global instance based and local instance based, and the representative methods are elaborated and analyzed in detail. Further, according to the differences in visual features, the methods based on the global instance are further subdivided into fusion of spatial information, fusion of appearance information and fusion of body posture information. Finally, the applications of zero-shot learning, weakly supervised learning and Transformer model in HOI detection are discussed. From three aspects of HOI, visual distraction and motion perspective, the challenges faced by HOI detection are listed, and it is pointed out that domain generalization, real-time detection and end-to-end network are the future development trends.
-
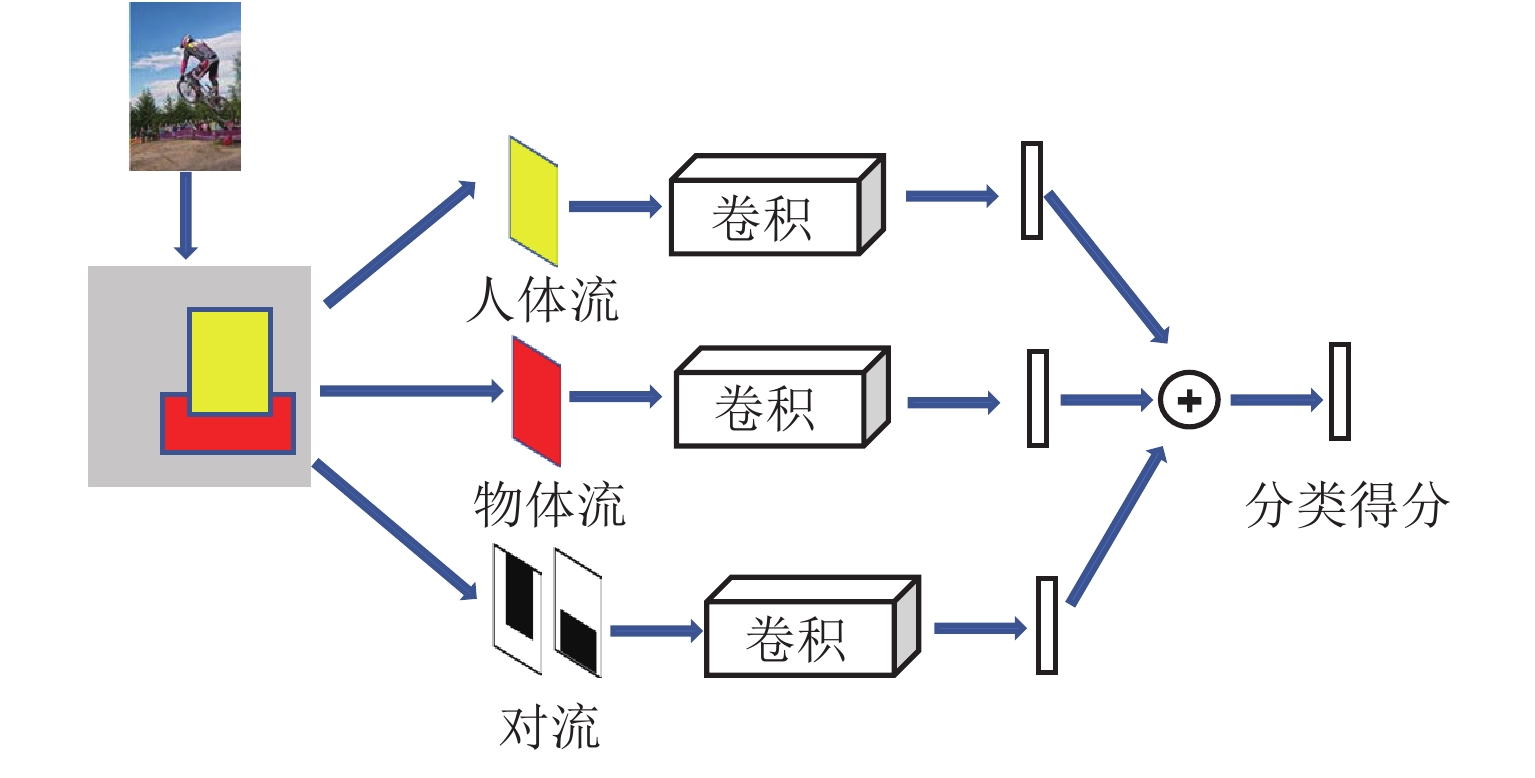
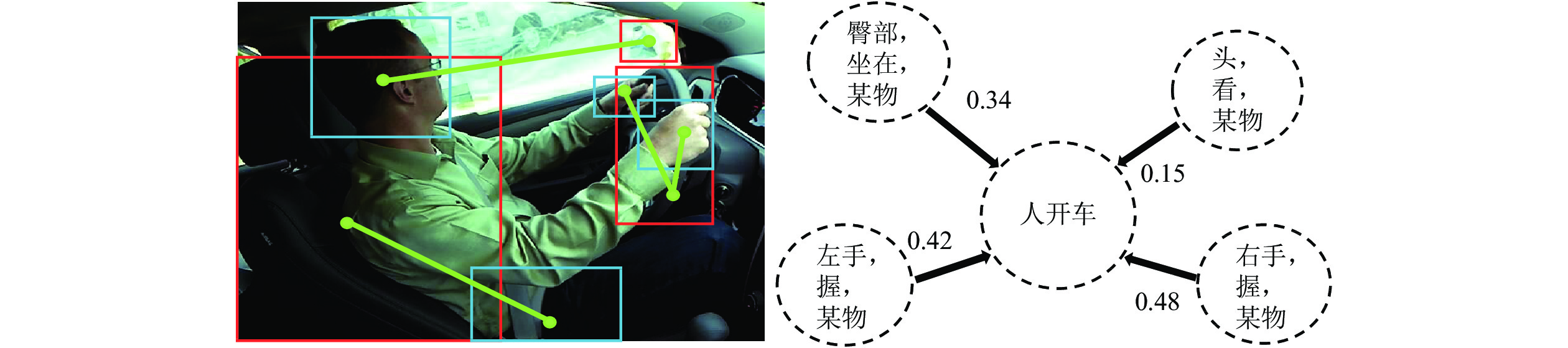
图 3 基于人-物区域位置信息的HO-RCNN网络
Figure 3. HO-RCNN networks based on human-object regional information
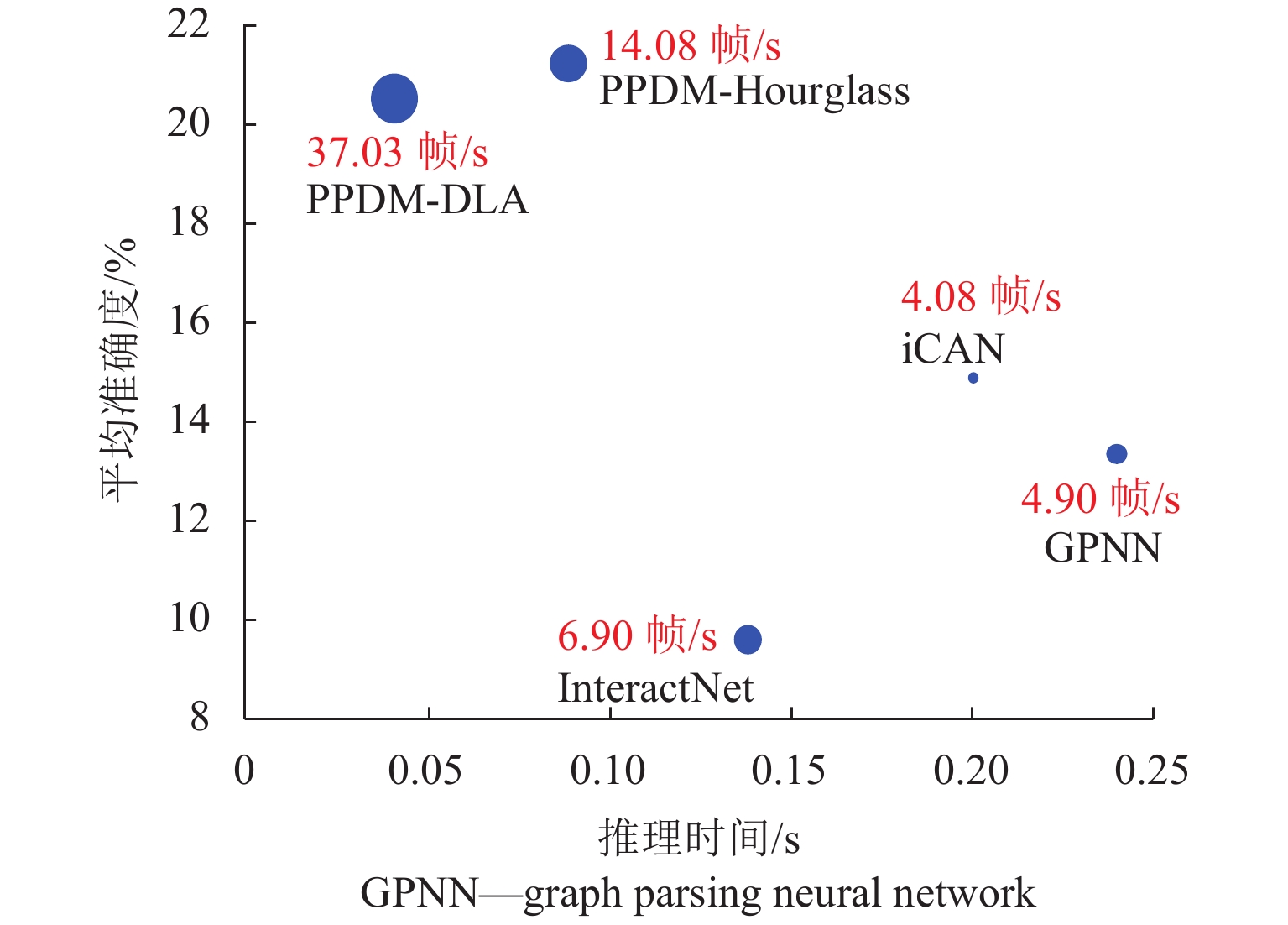
图 5 PPDM与同类方法在HICO-DET上的推理时间、平均准确度以及速度
Figure 5. Inference time, mAP, speed between PPDM and similar methods on HICO-DET dataset
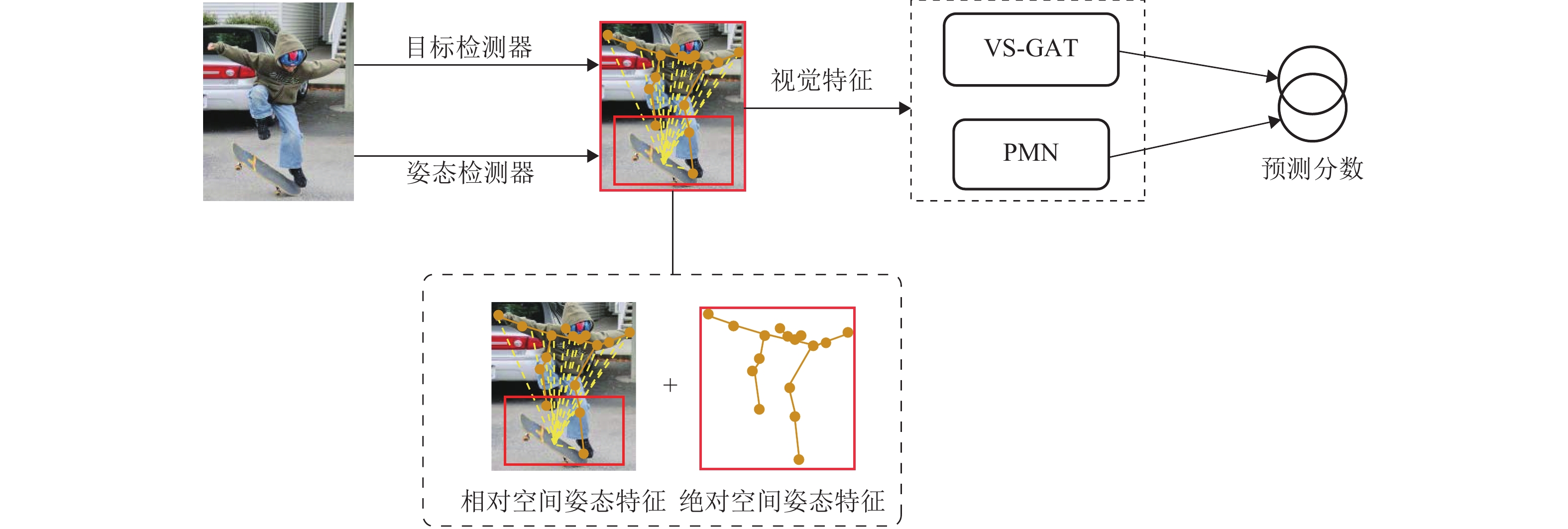
图 6 融合视觉语义姿态特征的VSP-GMN网络
Figure 6. VSP-GMN network integrating visual, semantic and pose features
表 1 人物交互图像数据集
Table 1. HOI image datasets
数据集 发布机构/发布者 图片/张 动作/类 注释类型 示例 HAKE (2020)[13] 上海交通大学 118 000 156 检测框结合
语义描述
HOI-A (2020)[14] 北京航空航天大学 17 606 10 检测框结合
语义描述
HICO-DET (2018)[12] 密西根大学安娜堡分校 48 000 117 检测框结合
语义描述
HCVRD (2018)[15] 澳大利亚阿德莱德大学 788 160 9 852 检测框结合
语义描述
V-COCO (2015)[11] 加州大学伯克利分校 10 346 80 检测框 
HICO (2015)[9] 密西根大学安娜堡分校 47 774 600 语义描述 
MPII (2014)[10] 普朗克信息学研究所 40 522 410 2D 姿态 
TUHOI (2014)[8] 意大利特伦托波沃大学 10 805 2 974 语义描述 
 下载: 导出CSV
下载: 导出CSV
表 2 基于视觉特征方法在HICO-DET数据集的mAP结果对比
Table 2. Result comparison of mAP with visual feature based methods on HICO-DET data set
来源 年份 方法 特征 mAP(Default)/% mAP(Know Object)/% Full Rare None-Rare Full Rare None-Rare 文献[46] 2021 年 GGNet A 29.17 22.13 30.84 33.50 26.67 34.89 文献[14] 2020 年 PPDM A 21.73 13.78 24.10 24.58 16.65 26.84 文献[17] 2020 年 VS-GATs
+ PMNA + S + P 21.21 17.60 22.29 文献[45] 2021 年 多级成对特征网络 A + S + P 20.05 16.66 21.07 24.01 21.09 24.89 文献[34] 2019 年 PMFNet A + S + P 17.46 15.65 18.00 20.34 17.47 21.20 文献[31] 2019 年 TIN A + S + P 17.22 13.51 18.32 19.38 15.38 20.57 文献[20] 2019 年 多分支网络 A + S 16.24 11.16 17.75 17.73 12.78 19.21 文献[19] 2018 年 iCAN A + S 14.84 10.45 16.15 16.26 11.33 17.73 文献[12] 2018 年 HO-RCNN A + S 7.81 5.37 8.54 10.41 8.94 10.85 注:A、S、P 分别表示外观、空间和骨架;Full、Rare、None-Rare 分别表示完整类、罕见类、非罕见类.
下载: 导出CSV
表 3 基于视觉特征方法在V-COCO数据集结果对比
Table 3. Results comparison of visual feature based methods on V-COCO data set
下载: 导出CSV
表 4 其他新技术总结
Table 4. Summary of other new technologies
来源 年份 数据集 方法 主要工作概述 mAP/% 文献[57] 2021 年 V-COCO QPIC 利用注意力机制有效地聚合特征以检测各种 HOI 类 58.80 文献[56] 2021 年 HICO-DET HOTR 首次提出基于Transformer编码器-解码器结构的预测框架 25.10 文献[54] 2020 年 HICO GCNCL 以弱监督的方式训练未见类 16.02 文献[51] 2019 年 COCO-a
UnRel
HICO-DET三联体模型 提出了一个类比迁移模型,可计算从未见过的视觉短语嵌入信息 7.30
17.50
20.90文献[50] 2019 年 VT60 ZSL + S2S 语义到空间体系结构融合了零样本学习共同捕获信息并查询 50.47 文献[49] 2018 年 ILSVRC-2017
Unseen (all)
Seen端到端的深度架构 将零样本任务扩展到目标检测领域,联合建模了视觉和语义领域信息融合的端到端深度网络 16.40
26.10文献[48] 2018 年 HICO-DET 多任务训练网络 通过零样本学习方法将 HOI 识别扩展到长类别,实现对未见的动词-对象对的零样本目标检测 6.46
下载: 导出CSV
-
[1] JOHNSON J, KRISHNA R, STARK M, et al. Image retrieval using scene graphs[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE Computer Society, 2015: 3668-3678. [2] LI Y K, OUYANG W L, ZHOU B L, et al. Scene graph generation from objects, phrases and region captions[DB/OL]. (2017-06-31)[2021-02-02]. https://arxiv.org/abs/1707.09700. [3] XU D F, ZHU Y K, CHOY C B, et al. Scene graph generation by iterative message passing[EB/OL]. (2017-01-10)[2021-02-02]. https://arxiv.org/abs/1701.02426. [4] BERGSTROM T, SHI H. Human-object interaction detection: a quick survey and examination of methods[DB/OL]. (2020-09-27)[2021-02-02]. https://arxiv.org/abs/2009.12950. [5] GUPTA A, KEMBHAVI A, DAVIS L S. Observing human-object interactions: using spatial and functional compatibility for recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(10): 1775-1789. doi: 10.1109/TPAMI.2009.83 [6] ALESSANDRO P, CORDELIA S, VITTORIO F. Weakly supervised learning of interactions between humans and objects[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(3): 601-614. doi: 10.1109/TPAMI.2011.158 [7] LI L J, LI F F. What, where and who? Classifying events by scene and object recognition[C]//Proceedings of IEEE International Conference on Computer Vision. [S.l.]: IEEE, 2007: 1-8. [8] LE D T, UIJLINGS J, BERNARDI R. TUHOI: trento universal human object interaction dataset[C]// Proceedings of the Third Workshop on Vision and Language. Brighton: Brighton University, 2014: 17-24. [9] CHAO Y W, WANG Z, HE Y, et al. HICO: a benchmark for recognizing human-object interactions in images[C]//IEEE International Conference on Computer Vision. [S.l.]: IEEE, 2015: 1-9. [10] ANDRILUKA M, PISHCHULIN L, GEHLER P, et al. 2d human pose estimation: New benchmark and state of the art analysis[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2014: 3686-3693. [11] GUPTA S, MALIK J. Visual semantic role labeling[DB/OL]. (2015-03-17)[2021-02-02]. https://arxiv.org/abs/1505.04474.pdf. [12] CHAO Y W, LIU Y, LIU X, et al. Learning to detect human-object interactions[C]//2018 IEEE Winter Conference on Applications of Computer Vision. [S.l.]: IEEE, 2018: 381-389. [13] LI Y L, XU L, LIU X, et al. Pastanet: Toward human activity knowledge engine[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2020: 379-388. [14] LIAO Y, LIU S, WANG F, et al. PPDM: Parallel point detection and matching for real-time human-object interaction detection[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2020: 479-487. [15] ZHUANG B, WU Q, SHEN C, et al. Hcvrd: a benchmark for large-scale human-centered visual relationship detection[C/OL]//Proceedings of the AAAI Conference on Artificial Intelligence, 2018. [2021-02-22]. https://ojs.aaai.org/index.php/AAAI/article/view/12260. [16] XU B J, LI J N, YONGKANG W, et al. Interact as You intend:intention-driven human-object interaction detection[J]. IEEE Transactions on Multimedia, 2019, 22(6): 1423-1432. [17] ULUTAN O, IFTEKHAR A S M, MANJUNATH B S. Vsgnet: spatial attention network for detecting human object interactions using graph convolutions[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2020: 13617-13626. [18] GIRSHICK R. Fast R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision. [S.l.]: IEEE, 2015: 1440-1448. [19] GAO C, ZOU Y, HUANG J B. iCAN: instance-centric attention network for human-object interaction detection[DB/OL]. (2018-08-30)[2021-02-22]. https://arxiv.org/abs/1808.10437. [20] WANG T, ANWER R M, KHAN M H, et al. Deep contextual attention for human-object interaction detection[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. [S.l.]: IEEE, 2019: 5694-5702. [21] PENG C, ZHANG X, YU G, et al. Large kernel matters-improve semantic segmentation by global con- volutional network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2017: 4353-4361. [22] GIRDHAR R, RAMANAN D. Attentional pooling for action recognition[DB/OL]. (2017-11-04)[2021-02-15]. https://doi.org/10.48550/arXiv.1711.01467. [23] BANSAL A, RAMBHATLA S S, SHRIVASTAVA A, et al. Spatial priming for detecting human-object interactions[DB/OL]. (2020-04-09)[2021-02-15]. https://arxiv.org/abs/2004.04851. [24] GKIOXARI G, GIRSHICK R, DOLLÁR P, et al. Detecting and recognizing human-object interactions[DB/OL]. (2017-04-24)[2021-02-22]. https://arxiv.org/abs/1704.07333 [25] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. [26] GUPTA T, SCHWING A, HOIEM D. No-frills human-object interaction detection: factorization, layout encodings, and training techniques[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. [S.l.]: IEEE, 2019: 9677-9685. [27] YU F, WANG D, SHELHAMER E, et al. Deep layer aggregation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2018: 2403-2412. [28] ZHOU X Y, WANG D Q, KRÄHENBÜHL P. Objects as points[DB/OL]. (2019-04-16)[2021-02-15]. http://arxiv.org/abs/1904.07850. [29] LAW H, DENG J. Cornernet: detecting objects as paired keypoints[C]//Proceedings of the European Conference on Computer Vision. [S.l.]: Springer, 2018: 734-750. [30] NEWELL A, YANG K, DENG J. Stacked hourglass networks for human pose estimation[C]//European Conference on Computer Vision. [S.l.]: Springer, 2016: 483-499. [31] LI Y L, ZHOU S, HUANG X, et al. Transferable interactiveness knowledge for human-object interaction detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2019: 3585-3594. [32] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]//European Conference on Computer Vision. Cham: Springer, 2014: 740-755 [33] LI J, WANG C, ZHU H, et al. Crowdpose: efficient crowded scenes pose estimation and a new benchmark[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2019: 10863-10872. [34] WAN B, ZHOU D, LIU Y, et al. Pose-aware multi-level feature network for human object interaction detection[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. [S.l.]: IEEE, 2019: 9469-9478. [35] CHEN Y, WANG Z, PENG Y, et al. Cascaded pyramid network for multi-person pose estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2018: 7103-7112. [36] LIANG Z J, LIU J F, GUAN Y S, et al. Pose-based modular network for human-object interaction detection[DB/OL]. (2020-08-05)[2021-02-22]. https://arxiv.org/abs/2008.02042 [37] LIANG Z J, LIU J F, GUAN Y S, et al. Visual-semantic graph attention networks for human-object interaction detection[DB/OL]. (2020-01-07)[2021-02-22]. https://arxiv.org/abs/2001.02302 [38] FANG H S, CAO J, TAI Y W, et al. Pairwise body-part attention for recognizing human-object interactions[C]//Proceedings of the European Conference on Computer Vision. [S.l.]: Springer, 2018: 51-67. [39] FANG H S, XIE S, TAI Y W, et al. Rmpe: regional multi-person pose estimation[C]//Proceedings of the IEEE International Conference on Computer Vision. [S.l.]: IEEE, 2017: 2334-2343. [40] MALLYA A, LAZEBNIK. Learning models for actions and person-object interactions with transfer to question answering[C]//Proceedings of the European Conference on Computer Vision. [S.l.]: Springer, 2016: 414-428. [41] ZHOU P, CHI M. Relation parsing neural network for human-object interaction detection[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. [S.l.]: IEEE, 2019: 843-851. [42] GIRSHICK R, RADOSAVOVIC I, GKIOXARI G, et al.Detectron[CP/OL]. (2020-09-22)[2021-02-11]. https://github.com/facebookresearch/detectron. [43] HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision. [S.l.]: IEEE, 2017: 2961-2969. [44] QI S, WANG W, JIA B, et al. Learning human-object interactions by graph parsing neural networks[C]//Proceedings of the European Conference on Computer Vision. [S.l.]: Springer, 2018: 401-417. [45] LIU H C, MU T J, HUANG X L. Detecting human-object interaction with multi-level pairwise feature network[J]. Computational Visual Media, 2021, 7(2): 229-239. doi: 10.1007/s41095-020-0188-2 [46] ZHONG X, QU X, DING C, et al. Glance and gaze: inferring action-aware points for one-stage human-object interaction detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2021: 13234-13243. [47] LAMPERT C H, NICKISCH H, HARMELING S. Learning to detect unseen object classes by between-class attribute transfer[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). [S.l.]: IEEE, 2009: 951-958. [48] SHEN L, YEUNG S, HOFFMAN J, et al. Scaling human-object interaction recognition through zero-shot learning[C]//2018 IEEE Winter Conference on Applications of Computer Vision. [S.l.]: IEEE, 2018: 1568-1576. [49] EUM S, KWON H. Semantics to space (S2S): embedding semantics into spatial space for zero-shot verb-object query inferencing[DB/OL]. (2019-06-13)[2022-02-22]. https://arxiv.org/abs/1906.05894 [50] RAHMAN S, KHAN S, PORIKLI F. Zero-shot object detection: learning to simultaneously recognize and localize novel concepts[DB/OL]. (2018-03-16)[2021-02-22]. https://arxiv.org/abs/1803.06049 [51] PEYRE J, LAPTEV I, SCHMID C, et al. Detecting unseen visual relations using analogies[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. [S.l.]: IEEE, 2019: 1981-1990. [52] ALESSANDRO P, SCHMID C, FERRARI V. Weakly supervised learning of interactions between humans and objects[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 34(3): 601-614. [53] PEYRE J, LAPTEV I, SCHMID C, et al. Weakly-supervised learning of visual relations[DB/OL]. (2017-07-29)[2021-02-22]. https://arxiv.org/abs/1707.09472. [54] SARULLO A, MU T T. Zero-shot human-object interaction recognition via affordance graphs[DB/OL]. (2020-09-02)[2021-02-22]. https://arxiv.org/abs/2009. 01039. [55] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[DB/OL]. (2017-06-12)[2022-02-26]. https://doi.org/10.48550/arXiv.1706.03762 [56] KIM B, LEE J, KANG J, et al. HOTR: end-to-end human-object interaction detection with transfor- mers[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2021: 74-83. [57] TAMURA M, OHASHI H, YOSHINAGA T. QPIC: query-based pairwise human-object interaction detection with image-wide contextual information[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2021: 10410-10419. -

 下载:
下载:



 点击查看大图
点击查看大图

计量
- 文章访问数: 1707
- HTML全文浏览量: 1152
- PDF下载量: 275
- 被引次数: 0