

Masked Face Detection Model Based on Multi-scale Attention-Driven Faster R-CNN
-
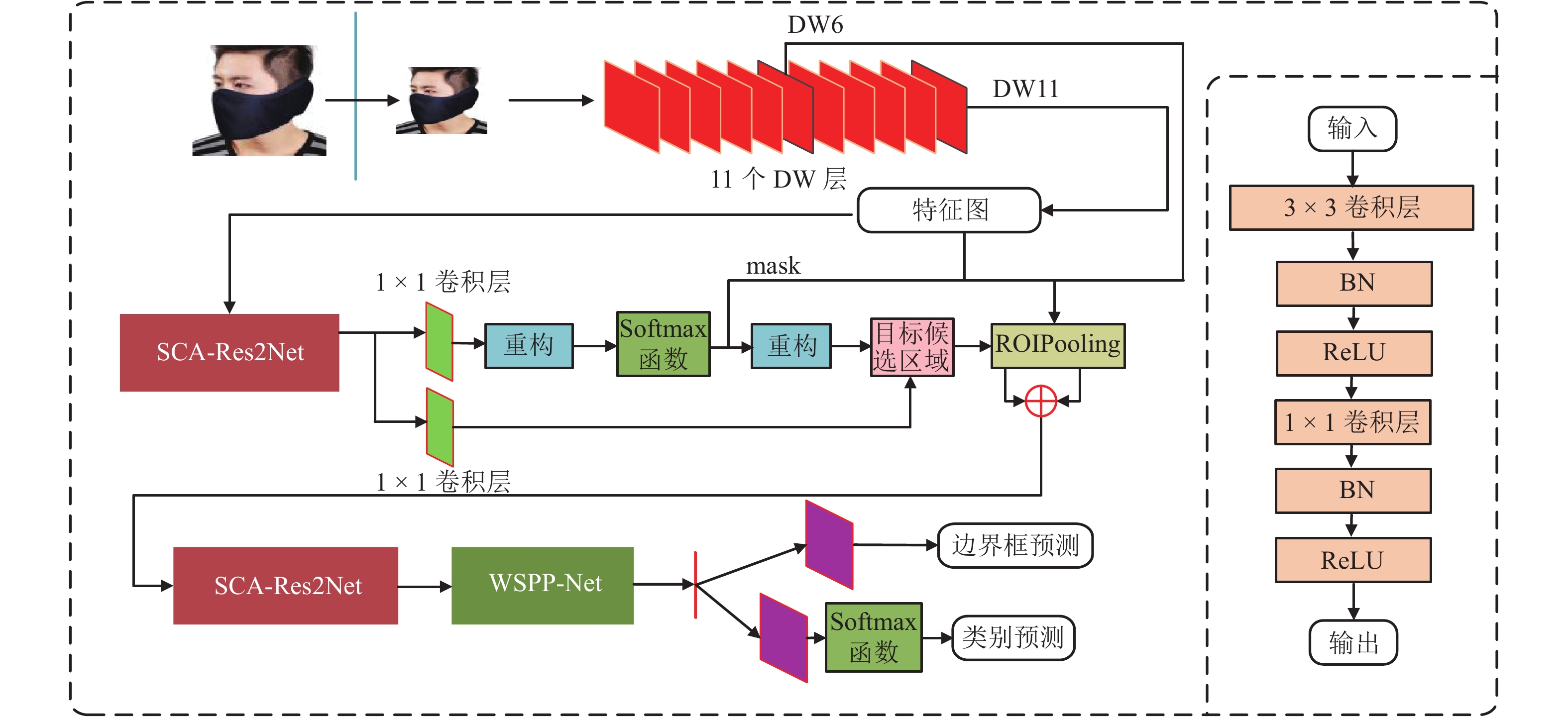
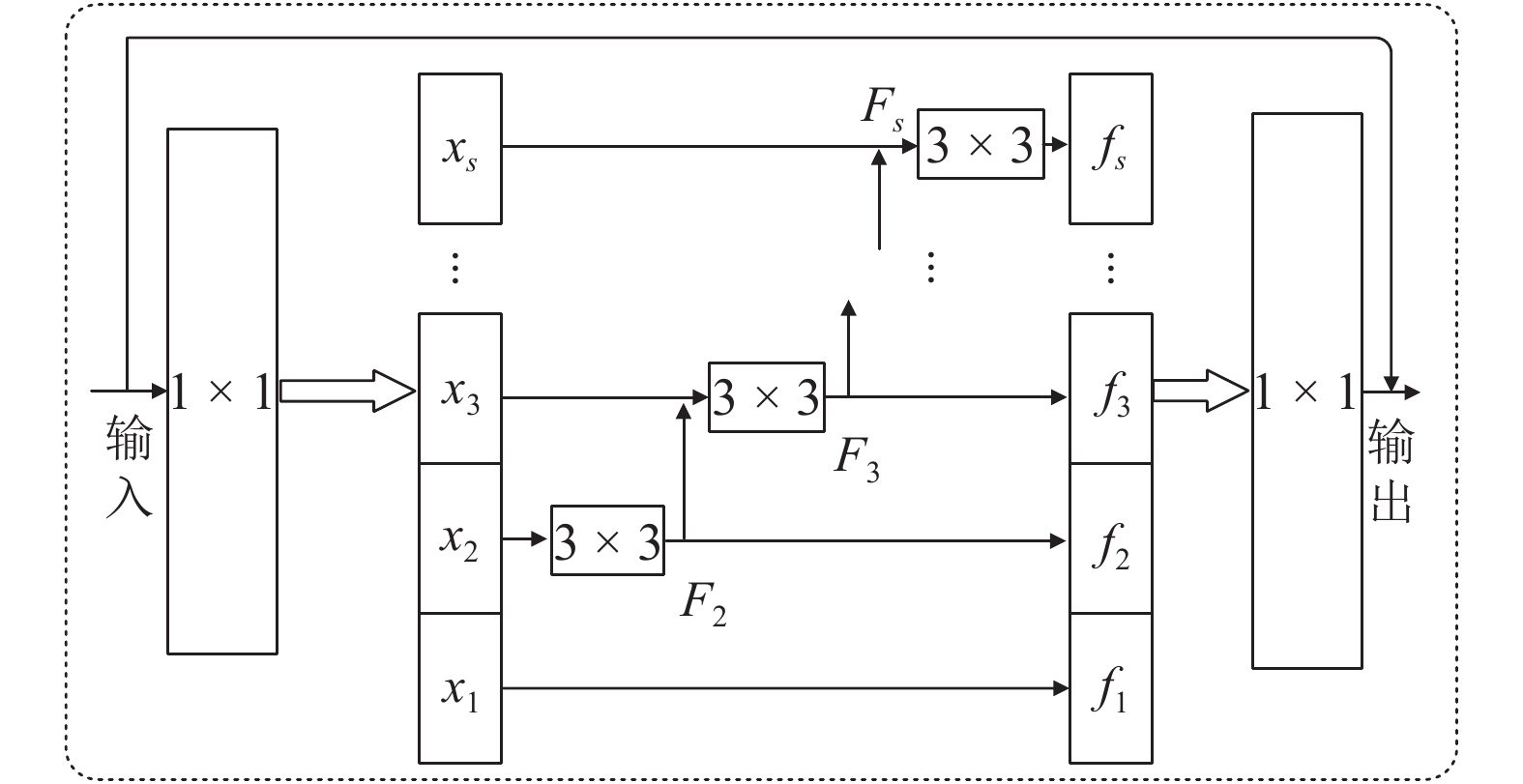
摘要: 针对在佩戴口罩等有遮挡条件下的人脸检测问题,提出了多尺度注意力学习的Faster R-CNN (MSAF R-CNN)人脸检测模型. 首先,为充分考虑人脸目标多尺度信息,相较于原始Faster R-CNN框架,引入Res2Net分组残差结构,获取更细粒度的特征表征;其次,基于空间-通道注意力结构改进的Res2Net模块,结合注意力机制自适应学习目标不同尺度特征;最后,为学习目标的全局信息并减轻过拟合现象,在模型顶端嵌入加权空间金字塔池化网络,采用由粗到细的方式进行特征尺度划分. 在AIZOO和FMDD两个人脸数据集上的实验结果表明:所提出MSAF R-CNN模型对佩戴口罩的人脸检测准确率分别达到90.37%和90.11%,验证了模型的可行性和有效性.Abstract: For the purpose of masked face detection, a multi-scale attention-driven faster region-based convolutional neural network (MSAF R-CNN) model is proposed. First, given the Faster R-CNN model architecture and the multi-scale information of the face, Res2Net, a grouped-residual structure, is introduced to model more fine-grained features. Then, inspired by the attention mechanism, a novel spatial-channel attention Res2Net (SCA-Res2Net) module is developed to learn the multi-scale features adaptively. Finally, to further learn the global feature representation and ease the overfitting problem, the weighted spatial pyramid pooling network is embedded on the top of the model, which can segment the feature maps into different groups from finer to coarser scales. Experimental results on the AIZOO and FMDD datasets show that the accuracy of masked face detection with the proposed MSAF R-CNN model can reach 90.37% and 90.11%, respectively, thus verifying the feasibility and effectiveness of the proposed model.
-
Key words:
- masked face /
- deep learning /
- attention mechanism /
- multi-scale learning /
- feature fusion /
- object detection
-
表 1 不同分组数实验结果
Table 1. Experimental results under different numbers of groups
% 数据集 类别 分组数 2 4 6 8 10 AIZOO Face 90.43 90.32 90.11 89.92 90.10 Mask 89.95 90.37 89.86 90.27 89.50 mAP 90.19 90.35 89.99 90.10 89.80 FMDD Face 86.21 87.27 86.17 86.50 86.17 Mask 89.99 90.11 90.04 90.21 89.99 mAP 88.10 88.69 88.10 88.35 88.08  下载: 导出CSV
下载: 导出CSV
表 2 不同压缩比实验结果
Table 2. Experimental results under different compression ratios
% 数据集 类别 压缩比 10 12 14 16 18 AIZOO Face 90.31 90.39 90.12 90.32 90.41 Mask 89.79 90.08 90.20 90.37 89.87 mAP 90.05 90.23 90.16 90.35 90.14 FMDD Face 86.98 84.89 86.26 87.27 86.30 Mask 89.90 89.68 90.25 90.11 89.86 mAP 88.44 87.29 88.26 88.69 88.08
下载: 导出CSV
表 3 WSPP-Net不同多尺度窗口大小实验结果
Table 3. Experimental results under different window sizes in WSPP-Net
% 数据集 类别 窗口大小 S1 S2 S3 S4 AIZOO Face 90.08 90.32 90.32 90.38 Mask 90.31 90.37 90.13 90.01 mAP 90.20 90.35 90.22 90.19 FMDD Face 86.51 87.27 86.56 86.45 Mask 89.76 90.11 89.60 89.99 mAP 88.14 88.69 88.08 88.22
下载: 导出CSV
表 4 不同检测方法的性能
Table 4. Performance of different methods
% 数据集 类别 模型 1 模型 2 模型 3 模型 4 MSAF R-CNN AIZOO Face 87.32 90.42 89.94 90.19 90.32 Mask 78.15 89.84 89.71 89.99 90.37 mAP 82.73 90.13 89.82 90.09 90.35 FMDD Face 86.01 86.41 84.44 85.05 87.27 Mask 77.95 90.01 89.94 90.10 90.11 mAP 81.98 88.21 87.19 87.58 88.69
下载: 导出CSV
表 5 消融实验结果
Table 5. Ablation experimental results of feature removal and fusion
% 数据集 类别 模型 5 模型 6 模型 7 MSAF R-CNN AIZOO Face 90.43 89.92 90.40 90.32 Mask 90.05 90.03 90.00 90.37 mAP 90.24 89.97 90.20 90.35 FMDD Face 85.13 86.01 86.23 87.27 Mask 89.93 90.00 89.98 90.11 mAP 87.53 88.01 88.10 88.69
下载: 导出CSV
-
VIOLA P, JONES M. Rapid object detection using a boosted cascade of simple features[C]//Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001. Kauai: IEEE, 2001: I.511-I.518. LIENHART R, MAYDT J. An extended set of Haar-like features for rapid object detection[C]//Proceedings of International Conference on Image Processing. New York: IEEE, 2002: I.900-I.903. 胡丽乔,仇润鹤. 一种自适应加权HOG特征的人脸识别算法[J]. 计算机工程与应用,2017,53(3): 164-168. doi: 10.3778/j.issn.1002-8331.1506-0183HU Liqiao, QIU Runhe. Face recognition based on adaptively weighted HOG[J]. Computer Engineering and Applications, 2017, 53(3): 164-168. doi: 10.3778/j.issn.1002-8331.1506-0183 张路达,邓超. 多尺度融合的YOLOv3人群口罩佩戴检测方法[J]. 计算机工程与应用,2021,57(16): 283-290.ZHANG Luda, DENG Chao. Multi-scale fusion of YOLOv3 crowd mask wearing detection method[J]. Computer Engineering and Applications, 2021, 57(16): 283-290. 魏丽,王洁,姜昕言,等. 遮挡条件下的人脸检测与遮挡物属性判识[J]. 计算机仿真,2020,37(9): 441-445,450. doi: 10.3969/j.issn.1006-9348.2020.09.093WEI Li, WANG Jie, JIANG Xinyan, et al. Face detection and obstacle attribute identification under occlusion[J]. Computer Simulation, 2020, 37(9): 441-445,450. doi: 10.3969/j.issn.1006-9348.2020.09.093 薛均晓,程君进,张其斌,等. 改进轻量级卷积神经网络的复杂场景口罩佩戴检测方法[J]. 计算机辅助设计与图形学学报,2021,33(7): 1045-1054.XUE Junxiao, CHENG Junjin, ZHANG Qibin, et al. Improved efficient convolutional neural network for complex scene mask-wearing detection[J]. Journal of Computer-Aided Design & Computer Graphics, 2021, 33(7): 1045-1054. LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[M]//Computer Vision – ECCV 2016. Cham: Springer International Publishing, 2016: 21-37. 迟万达,王士奇,张潇,等. 基于轻量化SSD的人脸检测模型设计[J]. 计算机与网络,2021,47(5): 69-73. doi: 10.3969/j.issn.1008-1739.2021.05.055CHI Wanda, WANG Shiqi, ZHANG Xiao, et al. Design on face detection model based on lightweight SSD[J]. Computer & Network, 2021, 47(5): 69-73. doi: 10.3969/j.issn.1008-1739.2021.05.055 GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 580-587. GIRSHICK R. Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision (ICCV). Santiago: IEEE, 2015: 1440-1448. REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN:towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. doi: 10.1109/TPAMI.2016.2577031 GAO S H, CHENG M M, ZHAO K, et al. Res2Net:a new multi-scale backbone architecture[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(2): 652-662. doi: 10.1109/TPAMI.2019.2938758 BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate[EB/OL]. (2014-09-01)[2020-12-20]. https://www.researchgate.net/publication/265252627_Neural_Machine_Translation_by_Jointly_Learning_to_Align_and_Translate. ZHU Y S, ZHAO C Y, GUO H Y, et al. Attention coupleNet:fully convolutional attention coupling network for object detection[J]. IEEE Transactions on Image Processing, 2019, 28(1): 113-126. doi: 10.1109/TIP.2018.2865280 ZHANG J F, NIU L, ZHANG L Q. Person re-identification with reinforced attribute attention selection[J]. IEEE Transactions on Image Processing, 2021, 30: 603-616. doi: 10.1109/TIP.2020.3036762 HE L, CHAN J C W, WANG Z M. Automatic depression recognition using CNN with attention mechanism from videos[J]. Neurocomputing, 2021, 422: 165-175. doi: 10.1016/j.neucom.2020.10.015 HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas: IEEE, 2016: 770-778. MUDUMBI T, BIAN N Z, ZHANG Y Y, et al. An approach combined the faster RCNN and mobilenet for logo detection[J]. Journal of Physics:Conference Series, 2019, 1284: 012072.1-012072.8. SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]//3rd International Conference on Learning Representations. San Diego: [s.n.], 2015: 1-14. SZEGEDY C, LIU W, JIA Y Q, et al. Going deeper with convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Boston: IEEE, 2015: 1-9. HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132-7141. WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[M]//Computer Vision-ECCV 2018. Cham: Springer International Publishing, 2018: 3-19. XI O Y, KANG G, PAN Z. Spatial pyramid pooling mechanism in 3D convolutional network for sentence-level classification[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2018, 26(11): 2167-2179. doi: 10.1109/TASLP.2018.2852502 YANG R, ZHANG Y, ZHAO P F, et al. MSPPF-nets: a deep learning architecture for remote sensing image classification[C]//IGARSS 2019 - 2019 IEEE International Geoscience and Remote Sensing Symposium. Yokohama: IEEE, 2019: 3045-3048. WANG H J, SHI Y Y, YUE Y J, et al. Study on freshwater fish image recognition integrating SPP and DenseNet network[C]//2020 IEEE International Conference on Mechatronics and Automation (ICMA). Beijing: IEEE, 2020: 564-569. WANG T, YUAN L, ZHANG X, et al. Distilling object detectors with fine-grained feature imitation[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 4928-4937. YANG S, LUO P, LOY C C, et al. WIDER FACE: a face detection benchmark[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas: IEEE, 2016: 5525-5533. GE S M, LI J, YE Q T, et al. Detecting masked faces in the wild with LLE-CNNs[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu: IEEE, 2017: 426-434. LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//2017 IEEE International Conference on Computer Vision (ICCV). Venice: IEEE, 2017: 2999-3007. -

 下载:
下载:




 点击查看大图
点击查看大图
计量
- 文章访问数: 856
- HTML全文浏览量: 474
- PDF下载量: 75
- 被引次数: 0