

Fault Diagnosis of Rolling Bearing Based on EEMD-Hilbert and FWA-SVM
-
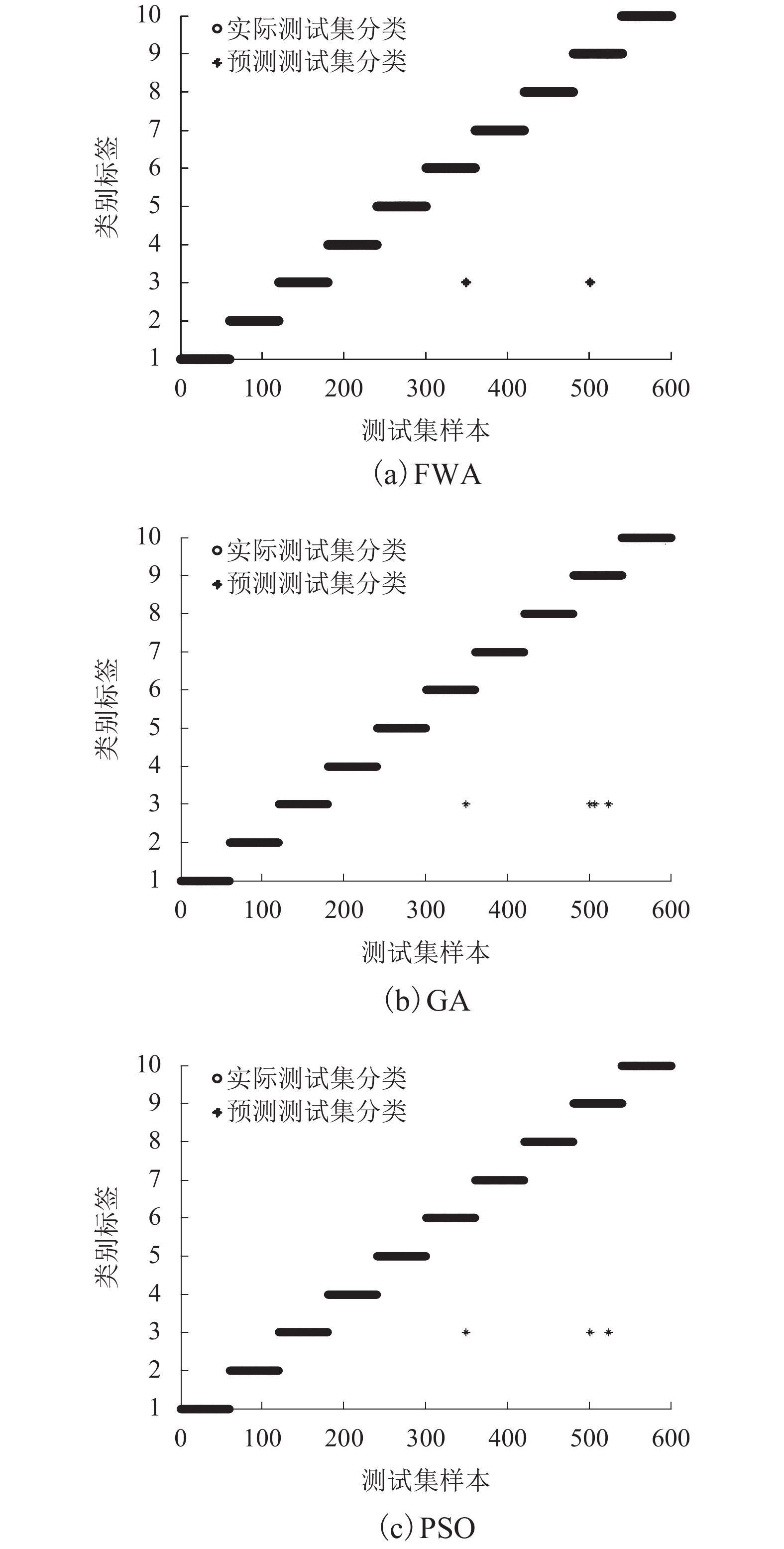
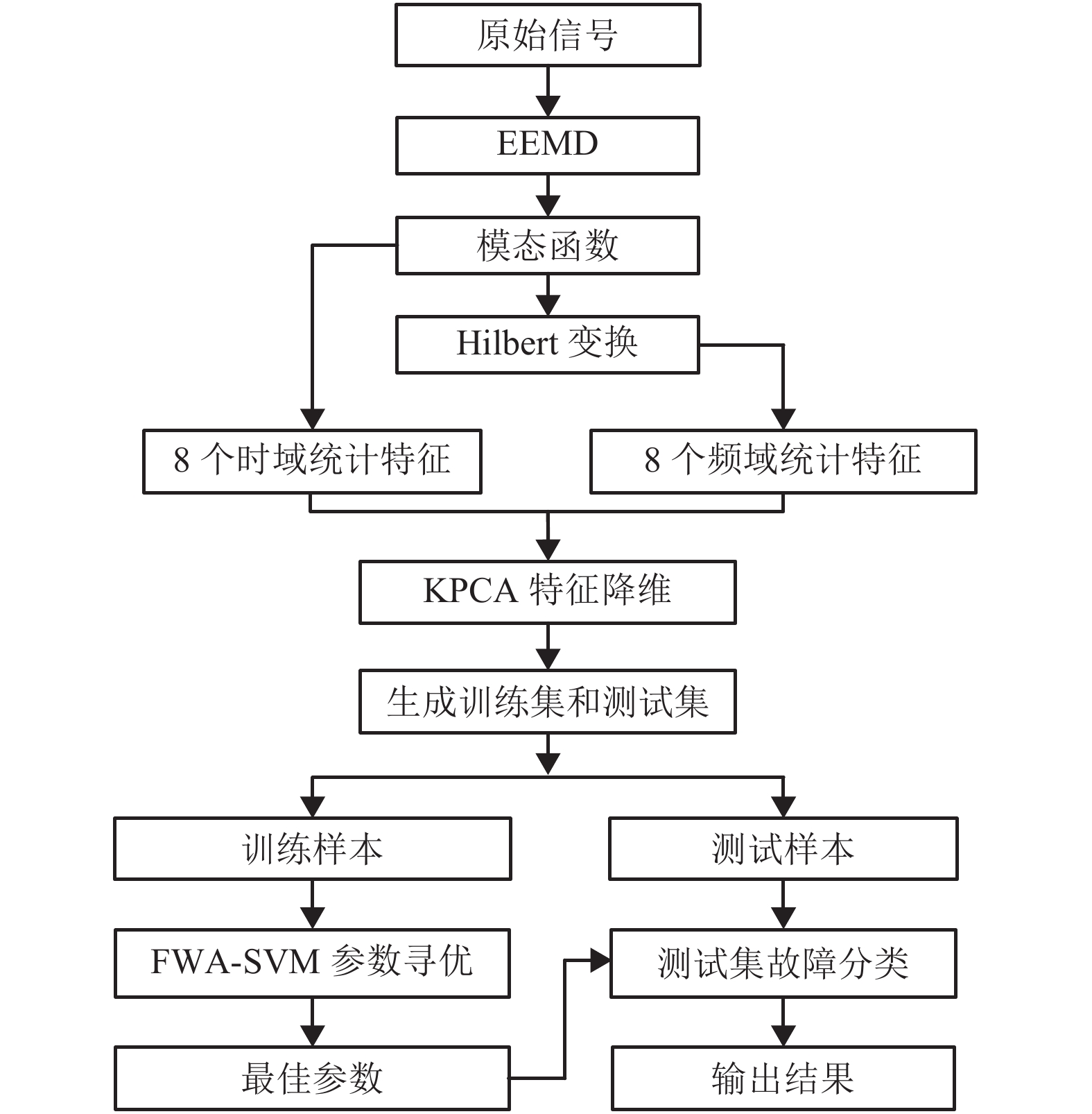
摘要: 为有效提取非平稳特性的滚动轴承振动信号特征,提高故障诊断效率,提出一种采用集合经验模态分解(empiricalmode decomposition,EEMD)、Hilbert变换的特征提取方法,并利用烟花算法优化支持向量机(support vector machine,SVM)分类参数的滚动轴承故障诊断方法. 通过EEMD方法将目标信号分解成若干个模态函数,采取Hilbert变换获取模态函数的瞬时频率,并对模态函数及其瞬时频率进行统计特征提取,从而实现特征的有效降维. 结果表明:信号经过EEMD-Hilbert处理后特征能有效提取,将训练集和测试集各600组数据代入烟花算法优化SVM模型得到测试集正确率为99.63%;比传统的遗传算法和粒子群算法优化模型分别提高0.4%和0.2%左右;同时收敛时间更短,验证了该算法模型的可行性与有效性.Abstract: To effectively extract the non-stationary characteristics of the rolling bearing vibration signal and improve the fault diagnosis efficiency, a feature extraction method based on the ensemble empirical mode decomposition (EEMD) and Hilbert transform was proposed. The support vector machine (SVM) classification parameters were optimised using the fireworks algorithm (FWA) for the rolling bearing fault diagnosis method. The EEMD method was used to decompose the target signal into several modal functions. The instantaneous frequencies of the modal functions were obtained through Hilbert transforms. Statistical feature extraction and dimensionality reduction were respectively performed for the modal function and instantaneous frequency. The fireworks algorithm model was used to optimise the SVM parameters as well as the multi-classification fault diagnosis with training and test sets drawn from 600 datasets. The accuracy of the signal is estimated to be 99.633%, which is 0.4% and 0.2% higher than that of the traditional genetic algorithm and particle swarm optimisation algorithm, respectively. Further, the ability of iterative convergence is also seen to have obvious advantages. The feasibility and validity of the algorithm models are thus verified.
-
表 1 轴承故障样本
Table 1. Bearing failure samples
轴承状态 故障点直径/mm 训练集 测试集 正常 — 60 60 内圈故障 0.178 60 60 滚动体故障 0.178 60 60 外圈故障 0.178 60 60 内圈故障 0.356 60 60 滚动体故障 0.356 60 60 外圈故障 0.356 60 60 内圈故障 0.533 60 60 滚动体故障 0.533 60 60 外圈故障 0.533 60 60  下载: 导出CSV
下载: 导出CSV
表 2 3种分类结果
Table 2. Classification results for the three methods
模型 迭代时间/s 正确率/% EEMD_H模型 282.9 99.43 EEMD模型 149.8 94.17 EMD_H模型 304.3 95.10
下载: 导出CSV
表 3 FWA、PSO、GA对SVM参数寻优
Table 3. FWA,PSO,and GA for SVM parameter optimisation
算法 C $\sigma $ 正确率/% PSO 38.12 9.35 98.67 FWA 35.39 6.88 99.00 GA 57.86 23.97 98.67
下载: 导出CSV
表 4 3种分类结果
Table 4. Classification results for the three algorithms
模型 迭代时间/s 正确率/% FWA 14.4 99.63 GA 114.3 99.20 PSO 282.9 99.43
下载: 导出CSV
-
TANDON N, CHOUDHURY A. A review of vibration and acoustic measurement methods for the detection of defects in rolling element bearings[J]. Tribology International, 1999, 32(8): 469-480. 于德介, 程军圣, 杨宇. 机械故障诊断的Hilbert-Huang变换方法[M]. 北京: 科学出版社, 2006: 4-12 HUANG N E, SHEN Z, LONG S R, et al. The empirical mode decomposition and the hilbert spectrum for nonlinear and non-stationary time series analysis[J]. Proceedings of the Royal Society A:Mathematical,Physical and Engineering Sciences, 1998, 454: 903-995. 黄建,胡晓光,巩玉楠. 基于经验模态分解的高压短路机械故障诊断方法[J]. 中国电机工程学报,2011,31(12): 108-113.HUANG Jian, HU Xiaoguang, GONG Yumin. Model fault diagnosis method of high voltage short circuit based on empirical mode decomposition[J]. Proceeding of the CSEE, 2011, 31(12): 108-113. 时培明,李庚,韩冬颖. 基于改进 EMD的旋转机械耦合故障诊断方法研究[J]. 中国机械工程,2013,24(17): 2367-2372.SHI Peiming, LI Geng, HAN Dongying. Study on coupling fault diagnosis method of rotating machinery based on improved EMD[J]. China Mechanical Engineering, 2013, 24(17): 2367-2372. WU Z, HUANG N. Ensemble empirical mode decomposition:a noise assisted data analysis method[J]. Advances in Adaptive Data Analysis, 2009, 1(1): 1-41. 秦娜,金炜东,黄进,等. 基于EEMD样本熵的高速列车转向架故障特征提取[J]. 西南交通大学学报,2014,49(1): 27-32.QIN Na, JIN Weidong, HUANG Jin, et al. Fault feature extraction of high-speed train bogies based on eemd sample entropy[J]. Journal of Southwest Jiaotong University, 2014, 49(1): 27-32. AlVAR M, SANCHEZ A, ARRANZ A. Fast background subtraction using static and dynamic gates[J]. Artificial Intelligence Review, 2014, 41(1): 113-128. 何青,褚东亮,毛新华,等. 基于EEMD和 MFFOA-SVM滚动轴承故障诊断[J]. 中国机械工程,2016,27(9): 1191-1197.HE Qing, ZHU Dongliang, MAO Xinhua, et al. Fault diagnosis of rolling bearing based on EEMD and MFFOA-SVM[J]. China Mechanical Engineering, 2016, 27(9): 1191-1197. TAN Y, ZHU Y. Fireworks algorithm for optimization [C]//International Conference in Swarm Intelligence. Berlin: Springer, 2010: 355-364 顾军华,赵燕,董瑶. 基于FWA-SVM的室内无线定位研究[J]. 河北工业大学学报,2016,45(6): 35-40.GU Junhua, ZHAO Yan, DONG Yao. Study on indoor wireless location based on FWA-SVM[J]. Journal of Hebei University of Technology, 2016, 45(6): 35-40. 高宏宾,侯杰,李瑞光. 基于核主成分分析的数据流降维研究[J]. 计算机工程与应用,2013,49(11): 105-109.GAO Hongbin, HOU Jie, LI Ruiguang. Research on dimension reduction of data flow based on kernel principal component analysis[J]. Computer Engineering and Applications, 2013, 49(11): 105-109. 陈维荣,关佩,邹月娴. 基于SVM的交通事件检测技术[J]. 西南交通大学学报,2011,46(1): 63-67.CHEN Weirong, GUAN Pei, ZOU Yuexian. A traffic event detection technology based on SVM[J]. Journal of Southwest Jiaotong University, 2011, 46(1): 63-67. 于世飞,齐丙娟,谭红艳. 支持向量机理论与算法研究综述[J]. 电子科技大学学报,2011,40(1): 2-10.YU Shifei, QI Bingjuan, TAN Hongyan. Study on support vector machine theory and algorithm[J]. Journal of University of Electronic Science and Technology of China, 2011, 40(1): 2-10. 叶林,刘鹏. 基于经验模态分解和支持向量机的短期风电功率组合预测模型[J]. 中国电机工程学报,2011,31(31): 102-108.YE Lin, LIU Peng. Study on short-term wind power combination forecasting model based on empirical mode decomposition and support vector machine[J]. Proceeding of the CSEE, 2011, 31(31): 102-108. 谭营,郑少秋. 烟花算法研究进展[J]. 智能系统学报,2014(5): 515-528.TAN Ying, ZHENG Shaoqiu. Research progress of fireworks algorithm[J]. Journal of Intelligent Systems, 2014(5): 515-528. 张乾, 基于振动信号的轴承状态监测和故障诊断方法研究[D]. 长沙: 中南大学, 2012 张敏,程文明,刘娟. 复杂生产过程小故障诊断与分类方法研究[J]. 西南交通大学学报,2014,49(5): 842-847.ZHANG Min, CHENG Wenming, LIU Juan. Study on fault diagnosis and classification of complex production processes[J]. Journal of Southwest Jiaotong University, 2014, 49(5): 842-847. -

 下载:
下载:




 点击查看大图
点击查看大图
图(5) / 表(4)
计量
- 文章访问数: 801
- HTML全文浏览量: 288
- PDF下载量: 29
- 被引次数: 0