

Parallel Algorithms for Text Sentiment Analysis Based on Deep Learning
-
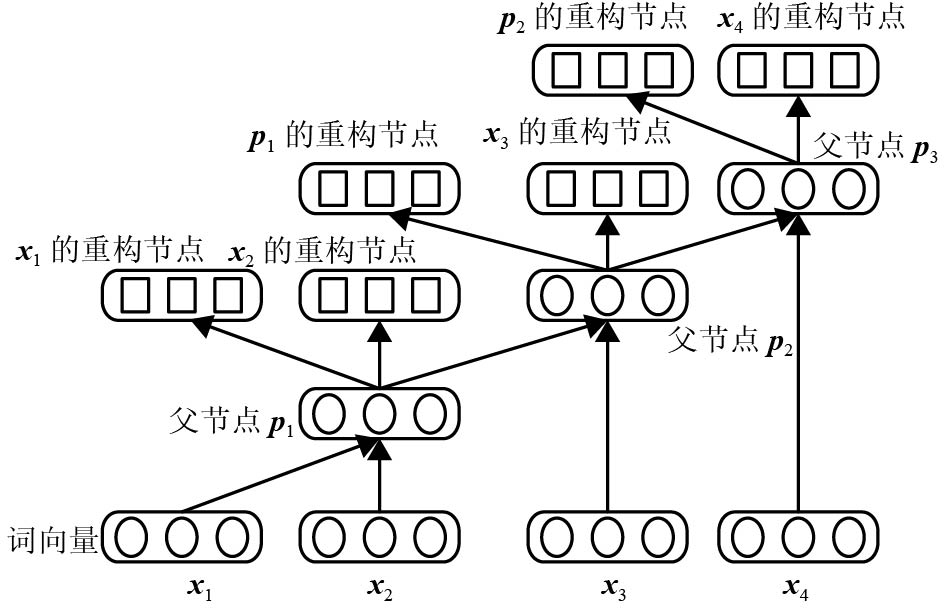
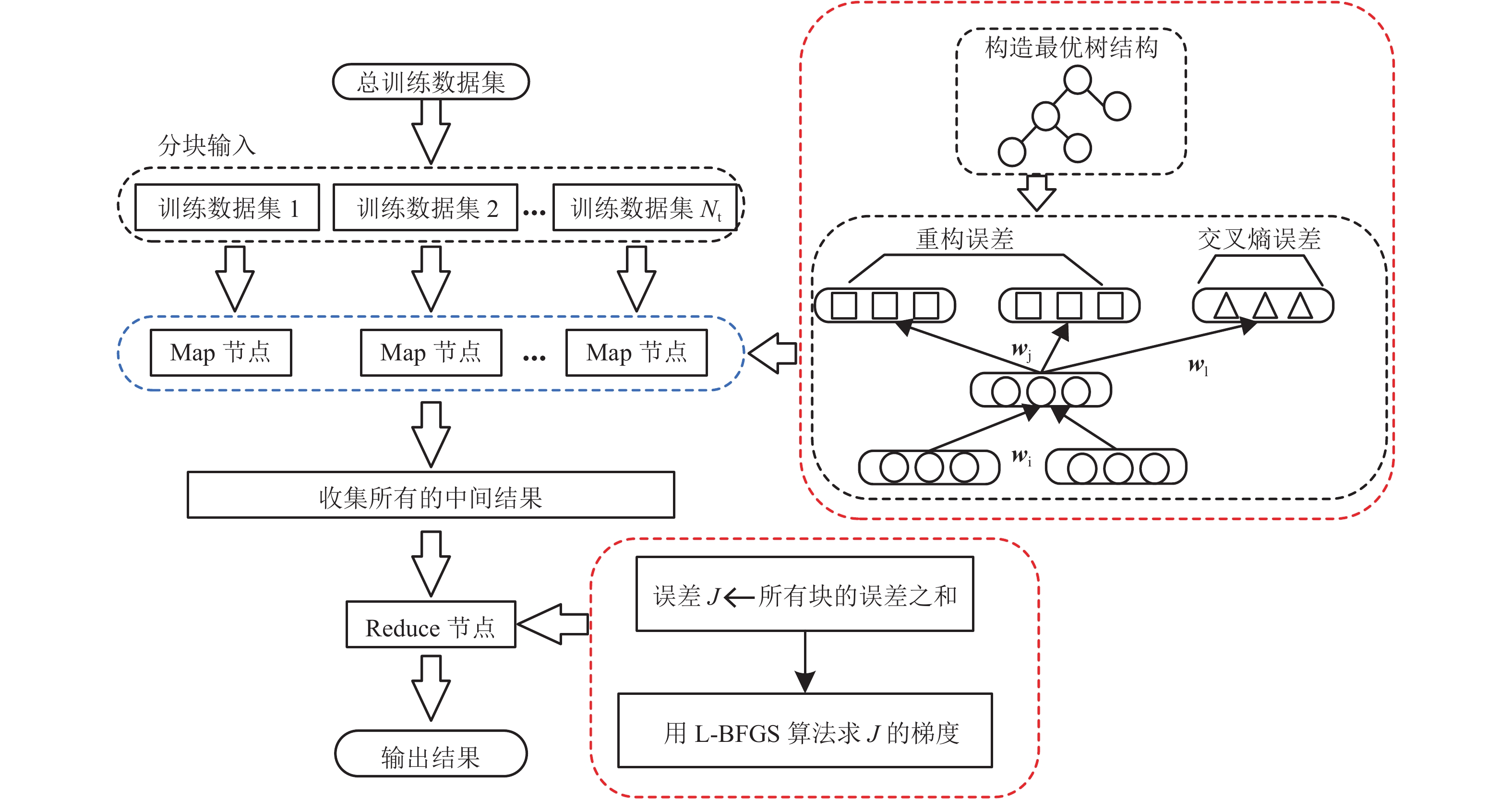
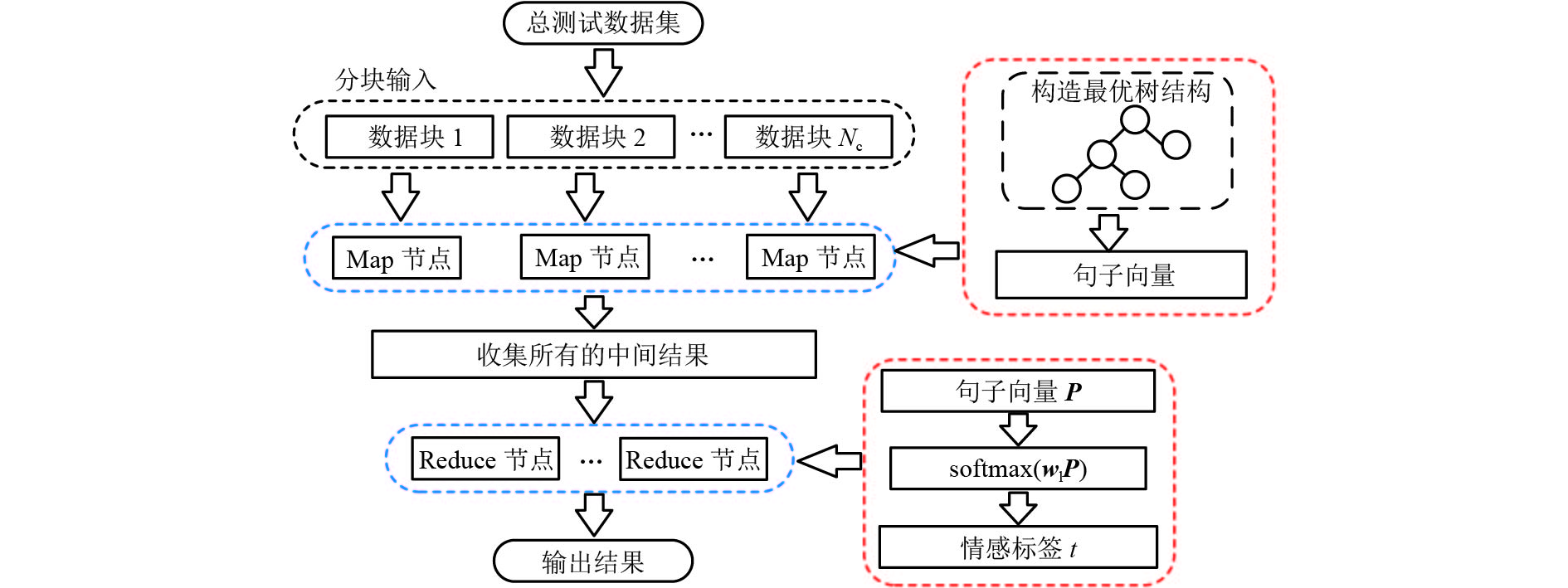
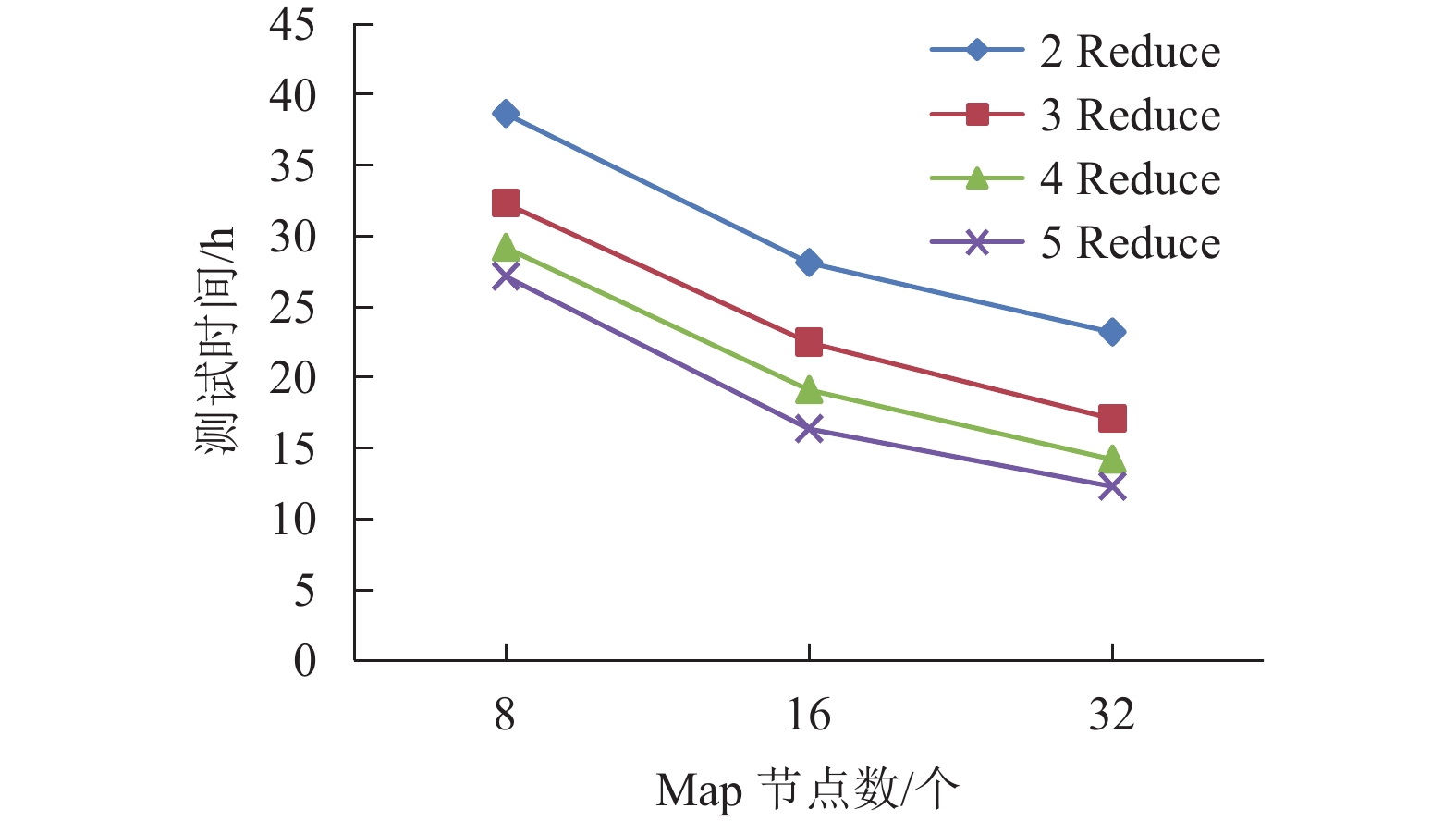
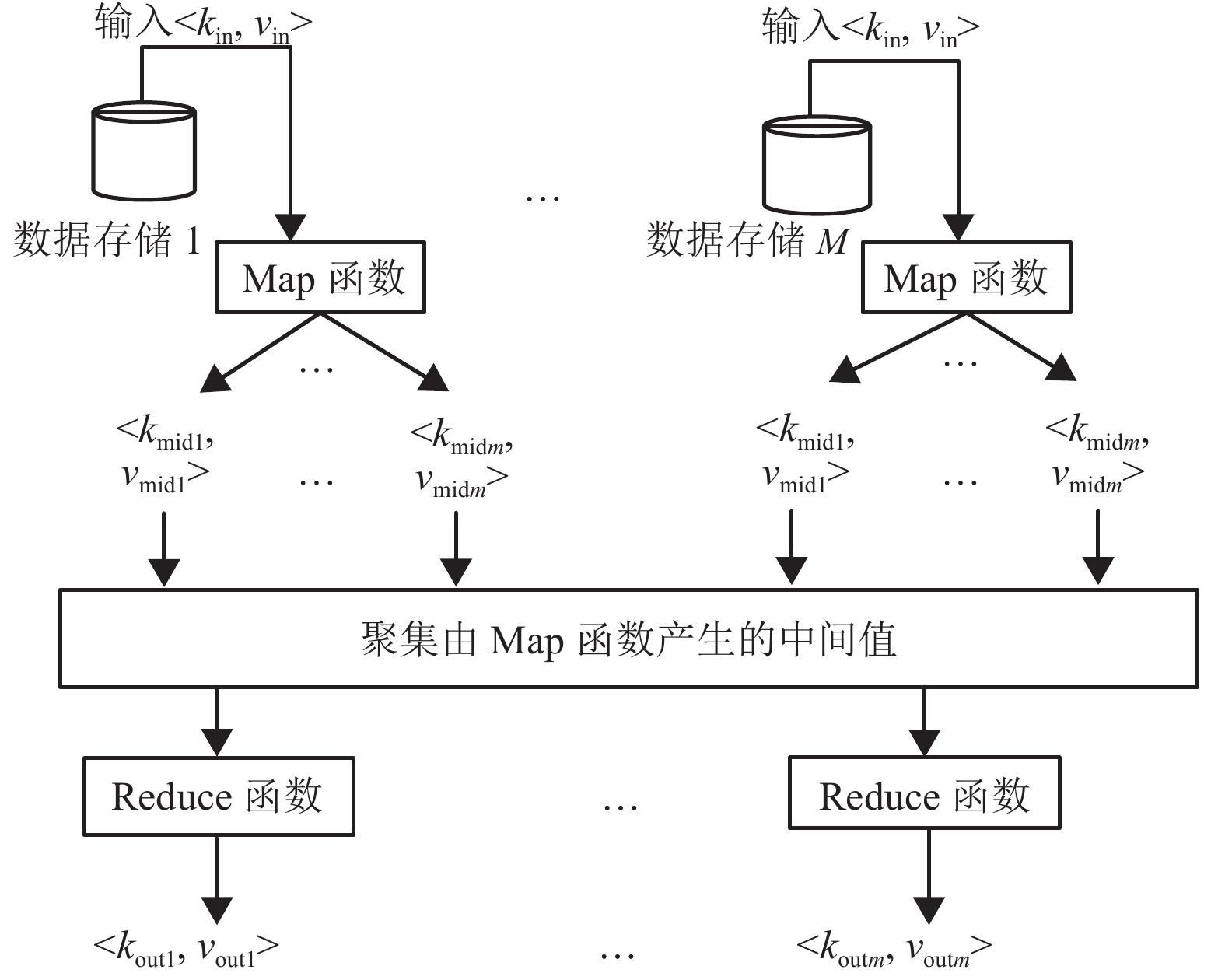
摘要: 在训练集和测试集数据量大的情况下,半监督递归自编码(semi-supervised recursive auto encoder,Semi-Supervised RAE)文本情感分析模型会出现网络训练速度缓慢和模型的测试结果输出速率缓慢等问题. 因此,提出采用并行化处理框架,在大训练集情况下,基于“分而治之”的方法,先将数据集进行分块划分并将各个数据块输入Map节点计算每个数据块的误差,利用缓冲区汇总所有的块误差,Reduce节点从缓冲区读取这些块误差以计算优化目标函数;然后,调用L-BFGS (limited-memory Broyden-Fletcher-Goldfarb-Shanno)算法调整参数,更新后的参数集再次加载到模型中,重复以上训练步骤逐步优化目标函数直至收敛,从而得到最优参数集;在测试集大的情况下,模型的初始化参数为上述步骤得到的参数集,Map节点对各句子进行编码得到其向量表示,然后暂存在缓冲区中;最后,在Reduce节点中分类器利用各语句的向量表示计算各自语句的情感标签. 实例验证表明:在标准语料库MR (movie review)下本文算法精确度为77.0%,与原始算法的精确度(77.3%)几乎相同;在大数据量训练集下,训练时间在一定程度上随着计算节点的增加而大量减少.Abstract: In the case of big training set and test set, based on semi-supervised auto encoder (Semi-Supervised RAE), the text sentiment analysis algorithm is accompanied by slow training rate and output rate of test results. To solve these problems, the corresponding parallel algorithms are proposed in this paper. For the big training data set, the method of " separate operation” is adopted to divide the data set into blocks. Each data block is inputted into Map nodes to calculate its error, and the errors of all data blocks are stored in the buffer. The block errors are read by Reduce nodes from the buffer to calculate the optimization objective function. Then, the limited-memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS) algorithm is called to update the parameter set, and the updated parameter set is reloaded into the cluster. The above process is iterated until the optimization objective function converges; therefore, an optimal parameter set is obtained. For the big test data set, the parameter set obtained by the above steps is used to initialize the cluster. The vector representation of each sentence is calculated in Map nodes and temporarily stored in the buffer. Then, the sentiment label of each sentence is calculated by the classifier in the Reduce node using the vector representation. The experimental results demonstrate that in the standard MR (movie review) corpus, the accuracy of the algorithm is 77.0%, which is almost the same as the accuracy of the original algorithm (77.3%), at the same time the training time is decreased greatly along with the increase of compute nodes in the massive training data sets.
-
表 1 语料库信息
Table 1. Corpus information
语料库 分类数 正面,负面,
中性评论/条总评论数/条 AmazonCorpus2 3 7 103,6 312,6 585 20 000 AmazonCorpus10 3 33 250,37 235,
29 515100 000 MR 2 5 331,5 331,0 10 000  下载: 导出CSV
下载: 导出CSV
表 2 AmazonCorpus语料库样例
Table 2. Samples of the AmazonCorpus
评论语句 情感标记 这个手机看起来比预期的好. 1 这个手机很好,但是它的耳机卡住了,我尝试了各种方法都没有将它拔出. 0 这个手机的耳机根本无法正常工作. –1
下载: 导出CSV
表 3 MR语料库样例
Table 3. Samples of the MR corpus
评论语句 情感标记 如果你有时候想要去看一场电影,电影wasabi会是一个好的开始. 1 简单、愚蠢和乏味. –1
下载: 导出CSV
-
LIU Bing. Sentiment analysis and opinion mining[M]. San Rafael: Morgan & Claypool, 2012: 1-6 唐慧丰,谭松波,程学旗. 基于监督学习的中文情感分类技术比较研究[J]. 中文信息学报,2007,6(2): 88-94.TANG Huifeng, TAN Songbo, CHENG Xueqi. Research on sentiment classification of chinese reviews based on supervised machine learning techniques[J]. Journal of Chinese Information Processing, 2007, 6(2): 88-94. 梁军,柴玉梅,原慧斌,等. 基于深度学习的微博情感分析[J]. 中文信息学报,2014,28(5): 155-161. doi: 10.3969/j.issn.1003-0077.2014.05.019LIANG Jun, CHAI Yumei, YUAN Huibin, et al. Deep learning for Chinese micro-blog sentiment analysis[J]. Journal of Chinese Information Processing, 2014, 28(5): 155-161. doi: 10.3969/j.issn.1003-0077.2014.05.019 杨经,林世平. 基于SVM的文本词句情感分析[J]. 计算机应用与软件,2011,28(9): 225-228. doi: 10.3969/j.issn.1000-386X.2011.09.068YANG Jing, LIN Shiping. Emotion analysis on text words and sentences based on SVM[J]. Computer Applications and Software, 2011, 28(9): 225-228. doi: 10.3969/j.issn.1000-386X.2011.09.068 HINTON G E, SALAKHUTDINOV R R. Reducing the dimensio-nality of data with neural networks[J]. Science, 2006, 28(7): 504-507. HINTON G E, OSINDERO S A. Fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7): 1527-1554. doi: 10.1162/neco.2006.18.7.1527 KIM Y. Convolutional neural networks for sentence classification[J]. Eprint Arxiv, 2014: 1746-1751. 黄磊,杜昌顺. 基于递归神经网络的文本分类研究[J]. 北京化工大学学报(自然科学版),2017,44(1): 99-104.HUANG Lei, DU Changshun. Application of recurrent neural networks in text classification[J]. Journal of Beijing University of Chemical Technology (Natural Science), 2017, 44(1): 99-104. SOCHER R, PENNINGTON J, HUANG E H, et al. Semi-supervised recursive autoencoders for predicting sentiment distributions[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Edinburgh: John McIntyre Conference Centre, 2011: 151-161 SOCHER R, HUVAL B, MANNING C D, et al. Semantic compositionality through recursive matrix-vector spaces[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Jeju Island: Stanford Press Release, 2012: 1201-1211 SOCHER R, PERELYGIN A, WU J Y, et al. Recursive deep models for semantic compos-itionality over a sentiment treebank[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Seattle: Stanford Press Release, 2013: 1631-1642 DEAN J, CORRADO G S, MONGA R, et al. Large scale distributed deep networks[C]//Advances in Neural Information Processing. Vancouver: Curran Associates Inc., 2012: 1232-1240 RAINA R, MADHAVAN A, NG A. Large-scale deep unsupervised learning using graphics processors[C]//Proceeding 26th Annual International Conference on Machine Learning, ICML. Montreal: ACM. 2009: 873-880 温馨,罗侃,陈荣国. 基于Shark/Spark的分布式空间数据分析框架[J]. 地球信息科学学报,2015,17(4): 401-407.WEN Xin, LUO Kai, CHEN Rongguo. Distributed spatial data analysis framework based on Shark/Spark[J]. Journal of Geo-information Science, 2015, 17(4): 401-407. ABADI M, BARHAM P, CHEN J, et al. TensorFlow: a system for large-scale machine learning[C]// Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation. Savannah: Google Press. 2016: 265-283 ISARD M, BUDIU M, YU Y, et al, Dryad: distributed data-parallel programs from sequential building blocks[C]//Proceedings of the 2nd ACM SIGOPS/EuroSys European Conference on Computer Systems. New York: ACM, 2007: 59-72 DEAN J, GHEMAWAT S. Mapreduce:simp-lified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113. doi: 10.1145/1327452 侯佳林,王佳君,聂洪玉. 基于异常检测模型的异构环境下MapReduce性能优化[J]. 计算机应用,2015,35(9): 2476-2481.HOU Jialin, WANG Jiajun, NIE Hongyu. MapReduce performance optimization based on anomaly detection model in heterogeneous cloud environment[J]. Journal of Computer Applications, 2015, 35(9): 2476-2481. LIU Yang, YANG Jie, HUANG Yuang, et al. MapReduce based parallel neural networks in enabling large scale machine learning[J]. Computational Intelligence and Neuroscience, 2015, 2015(2): 1-13. SUN Kairan, WEI Xu, JIA Gengtao, et al. Large-scale artificial neural network: mapreduce-based deep learning[DB/OL]. [2015-10-09]. https://arxiv.org/pdf/1-510.02709.pdf ZHANG Kunlei, CHEN Xuewen. Large-scale deep belief nets with MapReduce[J]. IEEE Access, 2014, 2(2): 395-403. PANG Bo, LEE L, VAITHYANATHAN S. Thumbs up? sentiment classification using machine learning techniques[C]//Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing. Philadelphia: Association for Computational Linguistics. 2002: 79-86 李然. 基于深度学习的短文本情感倾向性研究[D]. 北京: 北京理工大学, 2015 朱少杰. 基于深度学习的文本情感分类研究[D]. 哈尔滨: 哈尔滨工业大学, 2014 PANG Bo, LEE L. Seeing stars: exploiting class relationships for sentiment categorization with respect to rating scales[C]//Proceeding ACL’05 Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics. Michigan: Association for Computational Linguistics, 2005: 115-124 -

 下载:
下载:





 点击查看大图
点击查看大图
图(9) / 表(4)
计量
- 文章访问数: 591
- HTML全文浏览量: 294
- PDF下载量: 21
- 被引次数: 0