

Dense Crowd Counting Network Based on Multi-scale Perception
-
摘要:
针对密集人群场景存在的目标尺度多样、人群大尺度变化等问题,提出一种基于多尺度感知的密集人群计数网络. 首先,考虑到小尺度目标在图像中占比较大,以VGG-16 (visual geometry group 2016)网络为基础,引入空洞卷积模块,以挖掘图像细节信息;其次,为充分利用目标多尺度信息,构建新的上下文感知模块,以提取不同尺度之间的对比特征;最后,考虑到目标尺度连续变化的特点,设计多尺度特征聚合模块,提高密集尺度采样范围与多尺度信息交互,从而提升网络性能. 实验结果显示:在ShangHai Tech (Part_A/Part_B)和UCF_CC_50数据集上,本文方法的平均绝对误差(mean absolute error,MAE)分别为62.5、6.9、156.5,均方根误差(root mean square error,RMSE)分别为95.7、11.0、223.3;相较于最优对比方法,在UCF_QNRF数据集上的MAE和RMSE分别降低1.1%和4.3%,在NWPU数据集上分别降低8.7%和13.9%.
Abstract:A dense crowd counting network based on multi-scale perception was proposed to solve the problems of diverse target scales and large-scale changes of crowds in dense crowd scenes. Firstly, since the small-scale targets account for a relatively large proportion of the images, a dilated convolution module was introduced based on the visual geometry group 2016 (VGG-16) network to mine the detailed information in the images. Then, by utilizing the multi-scale information of the target, a novel context-aware module was designed to extract the contrast features between different scales. Finally, In view of the continuous change of target scales, the multi-scale feature aggregation module was designed to improve the sampling range of dense scales, enhance the interaction of multi-scale information, and thus improve the model performance. The experimental results show that mean absolute errors (MAEs) of the proposed method are 62.5, 6.9, and 156.5, and the root mean square errors (RMSEs) are 95.7, 11.0, and 223.3 on ShangHai Tech (Part_A/Part_B) and UCF_CC_50 datasets, respectively. Compared with the optimal method of comparison model, the MAE and RMSE are reduced by 1.1% and 4.3% on the UCF_QNRF dataset and by 8.7% and 13.9% on the NWPU dataset.
-
Key words:
- crowd density estimation /
- multi-scale aggregation /
- dilated convolution /
- density map
-
人群计数主要任务是估计场景中的总人数,在公共安全管理、城市空间规划、交通调度等领域有着广泛应用[1] ,受到国内外研究者大量关注. 随着城市人口数量持续增长,各种人群聚集性活动频繁开展,例如旅游景点、大型体育馆、热门商圈等常出现人群大量聚集现象[2],对人群计数的需求日益增加. 然而,在实际场景中,由于目标尺度多样、同一图像尺度连续变化以及图像间存在显著的密度差异等问题,使得人群计数任务仍然面临着较大挑战.
传统的人群计数主要采用基于检测[3]和基于回归[4]的方法对稀疏场景中的人群目标进行计数,但这些方法均依赖手工特征,难以适用于密集人群场景. 同时,缺乏对人群空间分布信息的关注,使得计数结果缺乏可信度和解释性. 为解决上述问题,文献[5]提出了基于密度估计的方法,通过学习人群图像特征和密度图之间的线性映射并对密度图积分实现对人群的计数. 该方法不仅揭示了人群的空间分布特征,还在高密度场景提高了计数性能. 因此,本文仍关注基于密度估计的人群计数方法研究.
近年来,由于卷积神经网络 (convolutional neural networks,CNN)具有强大的特征提取能力,被广泛应用于人群计数领域并取得显著效果[1-2]. Wang等[6]首次结合CNN提出人群计数模型,但未考虑目标尺度变化对模型性能的影响,导致计数准确度低. 在此基础上,Zhang等[7]提出一个多列卷积神经网络(multi-column convolutional neural network,MCNN),其利用三列具有不同卷积核的分支构建网络模型,以捕获不同感受野下的多尺度特征.
MCNN的提出为多分支人群计数研究奠定基础[8-9],但其模型结构存在冗余,且计算成本高. 因此,Li等[10]结合VGG-16 (visual geometry group 2016)[11]前10层和空洞卷积[12]提出CSRNet (congested scene recognition network),可在简化结构同时更好聚合拥挤场景中的多尺度特征. 考虑到空洞卷积有扩大感受野而不增加计算量的优势[13],左静等[14]以空洞卷积为基础,构建多尺度特征提取模块,提升人群计数的准确性. Chen等[15]提出一种尺度金字塔网络(scale pyramid network,SPN),采用并行单列结构,通过空洞卷积构成尺度金字塔模块,提取深层多尺度信息. Sindagi等[16]从特征融合的角度出发,引入一种多级自下而上和自上而下的融合网络,通过将浅层信息和深层信息以双向方式在不同尺度之间进行交互,提高多尺度融合的有效性. Zhou等[17]在提出的多尺度生成对抗网络中,利用来自不同层级的融合特征检测大尺度变化的人群,并通过对抗训练模式进行人群密度估计. Jiang等[18]利用网格式编-解码网络 (trellis encoder-decoder network,TED-Net)分层聚合特征,提高对尺度变化目标的表达. Tian等[19]为缓解在不同人群密度下泛化性不足的问题,构建多个不同密度场景下的预训练子网络以挖掘泛密度信息. 此外,文献[8,20-21]等还利用上下文信息来优化计数任务,进而提高模型在复杂场景中的适应性与精确度.
上述方法虽然能获取人群特征信息,但仅通过简单的特征提取对输入图像进行处理,忽略目标尺度连续变化的特性. 因此,如何利用网络模型去提取尺度连续变化的人群特征,减少空间细节信息丢失、有效融合多层次尺度特征仍是亟待解决的问题. 为此,本文提出一种基于多尺度感知的密集人群计数网络(dense crowd counting network based on multi-scale perception,MSPNet),网络结构主要由空洞卷积模块(dilated convolution module,DCM)、上下文感知模块(context-aware module,CAM)以及多尺度特征聚合模块(multi-scale feature aggregation module,MSAM)组成. 具体而言,将VGG-16提取的初级特征分别经过DCM与CAM模块以获取丰富的细粒度和上下文信息,进而利用MSAM模块挖掘多尺度特征并实现有效聚合,最后通过标准卷积获得最终的预测密度图. 在ShangHai Tech[7]、UCF_CC_50[22]、UCF_QNRF[23]以及NWPU[24]数据集上进行实验验证,结果表明本文方法具有较好的计数性能.
1. 本文算法
1.1 MSPNet结构
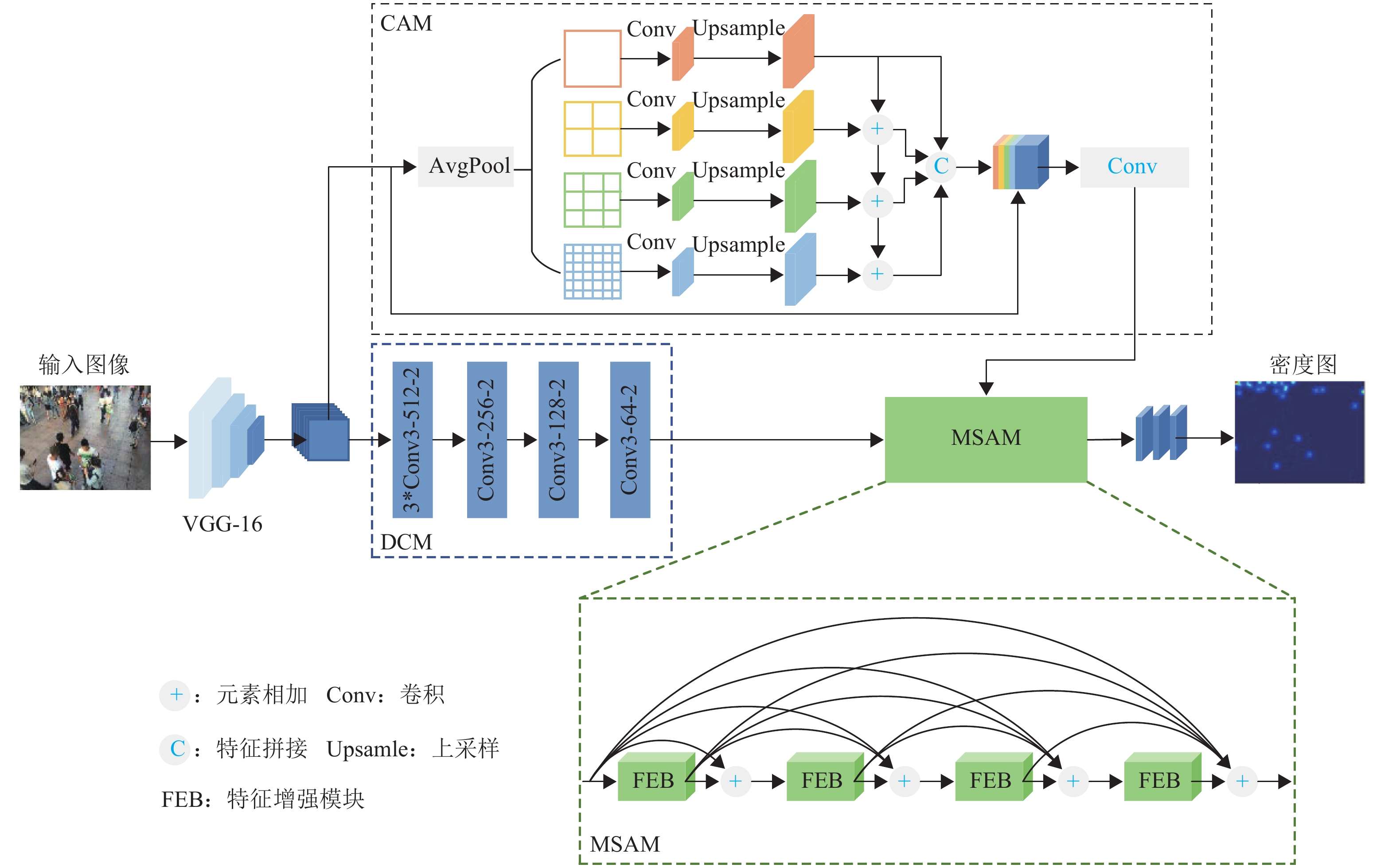
本文提出的基于多尺度感知的密集人群计数网络结构如图1所示. 图中:Conv3-256-2表示卷积运算中卷积核为3、通道数为256、空洞率为2,其余类推;3*Conv表示该层卷积执行3次.
 图 1 基于多尺度感知的密集人群计数网络结构Figure 1. Structure of dense crowd counting network based on multi-scale perception
图 1 基于多尺度感知的密集人群计数网络结构Figure 1. Structure of dense crowd counting network based on multi-scale perception根据人群计数经验可知,VGG-16网络[11]主要使用3 × 3大小的标准卷积,结构简单灵活,常被用作初级特征提取器[10,20]. 因此,本文使用VGG-16网络的前10层作为主干网. 对于输入图像I,经过主干网提取,得到特征fv,如式 (1)所示.
fv=Fvgg(I), (1) 式中:Fvgg(·)为特征提取函数.
考虑到密集人群图像中存在大量的小尺度目标,故在主干网络后设计小空洞率的空洞卷积模块,用于挖掘图像细节信息,具体结构如图1中DCM所示.
此外,为增强网络对大尺度范围的感知能力,本文设计上下文感知模块,主要将输入特征经过不同尺度的平均池化以学习上下文信息,并将其与空洞卷积模块的输出特征融合,以得到丰富的多尺度信息. 在此基础上,还提出多尺度特征聚合模块,进一步聚合多层次特征以应对尺度的连续变化. 最后,通过标准卷积,生成高质量密度图,进而实现人群图像计数.
1.2 上下文感知模块
Zhao等[25]在所提出PSPNet (pyramid scene parsing network)模型中,利用不同尺度的池化分支设计了金字塔池化模块(pyramid pooling module,PPM),可有效聚合上下文信息,但各尺度特征之间缺乏信息交互. 因此,本文在PPM的基础上提出上下文感知模块,其结构如图1中CAM所示.
首先,将输入特征按尺度划分为4个由粗到细的不同组别,并分别对每组进行池化和1 × 1卷积操作,每组池化核大小分别是1 × 1、2 × 2、3 × 3、6 × 6. 然后,使用双线性插值进行上采样,得到与输入大小相同的尺度感知特征fc,j,如式(2)所示.
fc,j=Ub(F0(Pave(fv,j),θj)), (2) 式中:j为尺度,Pave(·)为平均池化函数, F0(·)为1 × 1大小的卷积运算,Ub(·)为双线性插值函数,θj为网络参数.
其次,为充分利用人群图像中不同尺度的上下文信息,CAM采用自上而下、逐分支相加的方式聚合不同分支的对比特征. 然后,通过特征拼接操作拼接4个分支的输出特征并与原始特征进行跨通道融合. 最后,将融合后特征输入到后续卷积层中,输出最终结果.
在主干网络后引入CAM结构,可以由粗到细的层次化方式捕获不同尺度的特征信息,从而获得丰富的多尺度上下文特征.
1.3 多尺度特征聚合模块
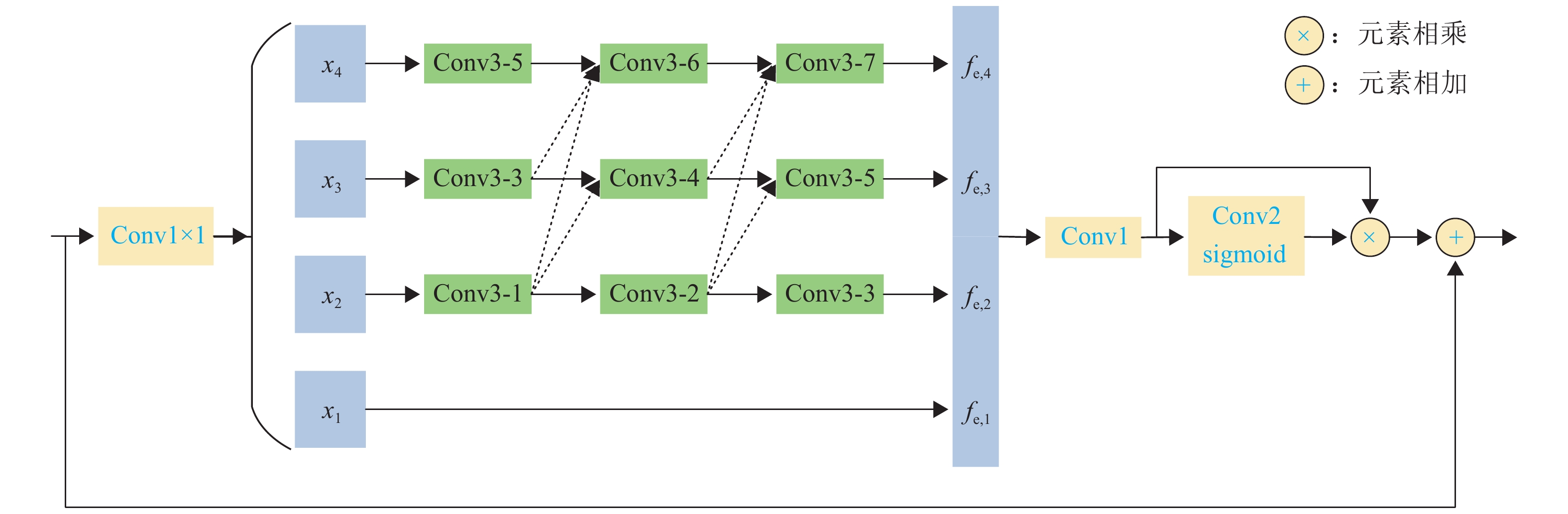
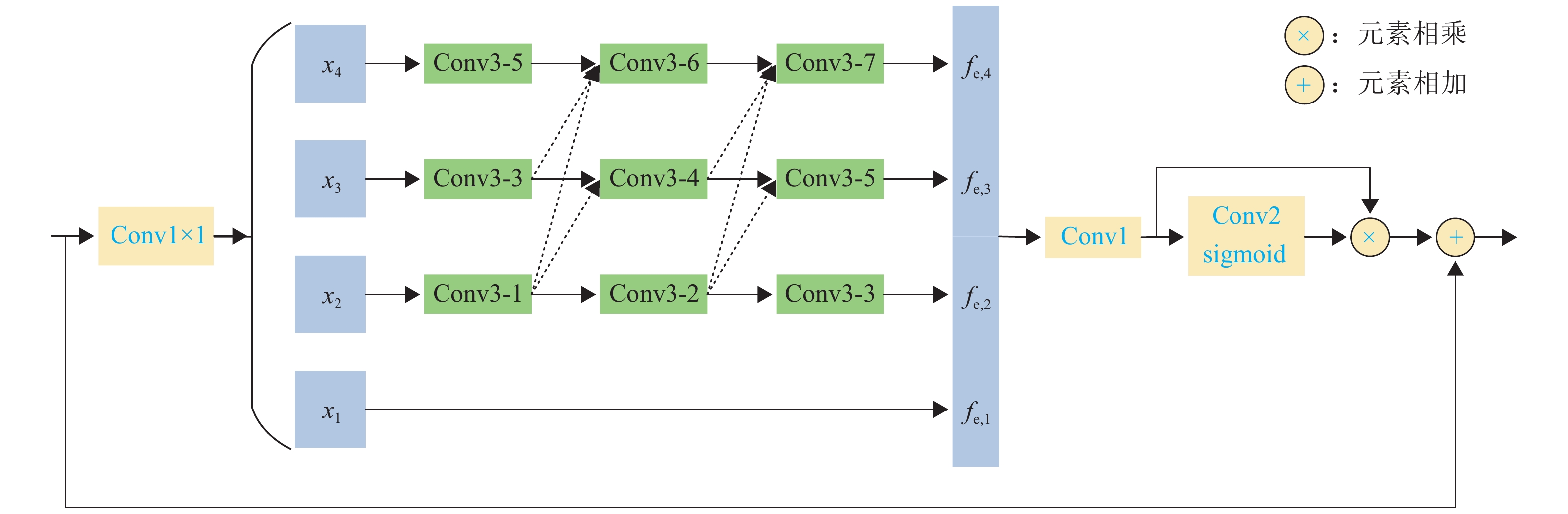
受文献[26]启发,将语义信息引入浅层特征,将空间信息嵌入深层特征,可以有效融合不同尺度的特征. 基于此,本文提出一个由FEB组成的多尺度特征聚合模块.
FEB为MSAM的核心部分,其结构如图2所示. 图中,Conv3-1表示卷积核为3、空洞率为1,其余类推. 首先,为降低计算复杂度,输入特征在经过1 × 1卷积后被平均划分为4个特征子集,依次分别为x1~x4. 其中,每个特征子集的通道数量降为输入特征的1/4. 除x1外,其他每个xk (k=2,3,4)都有一组对应的空洞卷积,其空洞率分别为(1,2,3), (3,4,5), (5,6,7),该设置方式可减少空洞卷积的网格效应,提高信息连续性. 同时,以残差的形式与其他子集连接. 对于第k个子集,其相应的输出为
fe,k={xk,k=1,Ck,3(k∑n=2Cn,2(n∑l=2Cl,1(xk))),k=2,3,4, (3) 式中:Ck,3(·)为第k行的第3个空洞卷积操作,其他类似结构以此类推.
融合fe,k并细化特征图,得到FEB结构的输出特征ffeb为
ffeb=fin⊕(F1(4∑k=1fe,k)⊗φ(F2(F1(4∑k=1fe,k)))), (4) 式中:fin为FEB结构的输入,F1(·)和F2(·)均为标准卷积,φ(·)为sigmoid激活函数,⊕为逐个元素相加,⨂为逐个元素相乘.
在FEB中,通过设置空洞卷积间空洞率互质以及将每个扩展层都与其他层紧密连接的方式有效减少像素信息的丢失. 同时,在网络中使用空洞率为3和5的空洞卷积各2次,避免感受野大小的跳跃变化. 总之,FEB通过提高感受野范围的连续性,丰富了尺度多样性,更有利于提取尺度连续变化的人群特征.
然而,由于FEB之间缺乏关联,本文结合密集残差连接策略[27]设计了MSAM结构. 通过融合不同网络层的多尺度特征,实现不同深度网络间的跨层连接. 其中,将较浅层的细节信息整合到深层中使得后续层的信息更加丰富. 同时,对特征的再次利用可减少由于网络加深引起的信息丢失,提高模型性能.
2. 实验与结果分析
2.1 训练细节
本文方法代码基于Pytorch框架实现,并且在Windows10操作系统和NVIDIA GeForce RTX 3080 GPU配置下进行实验. 此外,模型训练采用Adam优化器,学习率设为1×10−4,且动量设为0.9,每批次样本包含10张图像. 为使模型充分训练,在图像的不同位置执行随机翻转、剪切操作,以提升模型鲁棒性.
2.1.1 真实密度图生成
采用自适应高斯核[6]方法来生成真实密度图DGT,如式(5)所示.
{DGT=M∑m=1δ(p−pm)Gσm(x),σm=βdm, (5) 式中:M为图像中头部标记点总数;p为图像坐标;pm为第m个头部标记点坐标;δ(p−pm)为冲击函数;Gσm(·)为高斯核滤波器;σm为高斯核大小;β为超参数,取值为0.3;dm为pm与3个相邻目标的平均距离.
2.1.2 损失函数
为生成高质量预测密度图,使用如式(6)的联合损失函数L.
L=L1+λL2, (6) L1=1NtrNtr∑i=1|G(Ii;θ)−DGT|, (7) L2=1NtrNtr∑i=1S∑s=11z2s‖Pave(G(Ii;θ),zs)−Pave(DGT,zs)‖1, (8) 式中:L1为绝对值损失,L2为多尺度密度级一致性损失[28],λ为平衡损失函数L1、L2的权重参数,Ntr为训练图像批次量,Ii为第i张训练图像,G(Ii;θ)为第i张图像的预测密度图,θ为网络参数,S为尺度级别数,zs为第s级平均池化的输出大小.
2.1.3 评价指标
平均绝对误差(mean absolute error,MAE)和均方根误差(root mean square error,RMSE)是人群计数中常用的评估准则[1-2],其定义如式(9)、(10)所示.
eMAE=1NteNte∑i=1|yGT,i−yi|, (9) eRMSE=[1NteNte∑i=1(yGT,i−yi)2]12, (10) 式中:Nte为测试图像数量,yGT,i和yi分别为第i张测试图像的实际人数和预测人数.
2.2 结果分析
2.2.1 数据集
Shanghai Tech数据集包含Part_A和Part_B两部分[7], Part_A是从网上随机收集的482张密集图像,Part_B是拍摄于上海繁华街道的716张稀疏图像.
UCF_CC_50是第一个密集人群图像数据集[22]. 该数据集共有50张不同分辨率的灰度图像,密度大且包含多个不同复杂场景,非常具有挑战性. 根据文献[22],在实验时使用五折交叉验证法来验证模型性能.
UCF_QNRF数据集由Idrees等[23]提出,共有
1535 张高分辨率的密集图像. 该数据集的场景、角度和光线变化丰富多样,且分布杂乱,挑战难度很大.NWPU是西北工业大学于2020年公开的大型数据集[24],共有
5109 张高分辨率图像,其中包含351个负样本,涵盖多种复杂场景,是目前规模最大、最具挑战的人群计数数据集.2.2.2 实验结果分析
在4个数据集上进行训练,并与现有方法进行比较,结果如表1所示. 表中,数字加粗表示最优值,余表同.
表 1 不同方法在Shanghai Tech、UCF_CC_50、UCF_QNRF、NWPU数据集上的对比结果Table 1. Comparison results of different methods on Shanghai Tech, UCF_CC_50, UCF_QNRF, and NWPU datasets模型 Shanghai Tech Part_A Shanghai Tech Part_B UCF_ CC_50 UCF_ QNRF NWPU MAE RMSE MAE RMSE MAE RMSE MAE RMSE MAE RMSE MCNN[7] 110.2 173.2 26.4 41.3 377.6 509.1 277.0 426.0 218.5 700.6 CSRNet[10] 68.2 115.0 10.6 16.0 266.1 397.5 120.3 208.5 104.8 433.4 PDD-CNN[29] 64.7 99.1 8.8 14.3 205.4 311.7 115.3 190.2 TEDNet[18] 64.2 109.1 8.2 12.8 249.4 354.5 113.0 188.0 KDMG[30] 63.8 99.2 7.8 12.7 99.5 173.0 100.5 415.5 BL[31] 62.8 101.8 7.7 12.7 229.3 308.2 88.7 154.8 93.6 470.3 CAN[20] 62.3 100.0 7.8 12.2 212.2 243.7 107.0 183.0 93.5 489.9 MCANet[32] 60.1 100.2 6.8 11.0 181.3 258.6 100.8 185.9 SC2Net[33] 58.9 97.7 6.9 11.4 209.4 286.3 98.5 174.5 89.7 348.9 MSPNet 62.5 95.7 6.9 11.0 156.5 223.3 87.7 148.2 81.9 300.3 由表1可知,本文所提方法在4个数据集上都具有很强的竞争力. 在Shanghai Tech数据集的模型性能对比中,相较于SC2Net[33],MSPNet的MAE略有损失,这是由于该数据集中存在较多背景干扰,在一定程度上影响了模型计数的准确性,但RMSE在Part_A上降低2.0%,在Part_B上降低3.5%,表明MSPNet具有较好的稳定性. 在小样本数据集UCF_CC_50中,与MCANet[32]相比,MSPNet的MAE降低13.7%,RMSE降低13.6%. 同时,对于场景丰富的UCF_QNRF数据集,MSPNet与BL[31]相比,MAE降低1.1%,RMSE降低4.3%,相较于其他对比模型均表现出良好的计数性能,这是因为本文在聚合上下文和多尺度信息基础上,构建了密集连接的多尺度特征聚合模块,进而减少了尺度连续变化的影响. 在UCF_CC_50和UCF_QNRF数据集上的实验结果表明,MSPNet可在密集场景中取得较好的准确性. 此外,在人数变化范围大的NWPU数据集中,MSPNet在对比模型中取得最好的MAE和RMSE,虽然负样本的加入增大了训练难度,但有助于提升模型的泛化性,且通过实验充分证明了MSPNet具有更好的鲁棒性.
为进一步验证本文所提模型的预测效果,图3展示MSPNet在不同数据集上的部分可视化预测结果. 由图3可见,MSPNet生成的预测密度图与真实密度图更接近,在4个数据集上都取得较好的计数结果,表明MSPNet具有良好的多尺度特征提取能力.
2.3 消融实验
2.3.1 CAM结构的消融实验
为进一步验证CAM可有效提升模型性能,将原始PPM与CAM结构在Shanghai Tech数据集Part_A上做消融实验,结果如表2所示.
表 2 CAM结构的消融实验结果Table 2. Ablation experiments of CAM structure方法 MAE RMSE 本文+PPM 63.6 105.4 本文+CAM 62.5 95.7 由表2可知,本文使用CAM结构时性能有所改进,MAE降低1.1,RMSE降低9.7,因为CAM可有效促进各尺度特征信息之间的交互,增强上下文感知能力,提升模型的鲁棒性.
2.3.2 模块结构的消融实验
所提模型主要由CAM、DCM和MSAM 3个模块组成,为进一步验证各部分结构的合理性和有效性,在ShangHai Tech数据集Part_A上分别对CAM、DCM、CAM+MSAM、DCM+MSAM,DCM+CAM、DCM+CAM+MSAM进行消融实验研究,实验结果如表3所示.
表 3 模块结构的消融实验结果Table 3. Ablation experiments of different module structures方法 MAE RMSE CAM 68.2 118.8 DCM 66.2 113.0 DCM+CAM 64.9 109.8 CAM+MSAM 65.5 111.4 DCM+MSAM 64.0 111.5 DCM+CAM+MSAM 62.5 95.7 从表3中不难发现,单个CAM和DCM均可以在一定程度上获取人群信息,但其计数准确度较低. 将DCM和CAM融合后,计数性能有所提升,说明融合结构提取的多尺度信息更丰富. 而所提方法在融合结构基础上,密集连接了4层FEB结构,以增强各网络层的信息传递,提高尺度连续变化的建模能力,在MAE和RMSE上均取得最好的计数结果. 此外,CAM和DCM分别与MSAM进行结合后,MAE分别降为65.5和64.0,RMSE分别降为111.4和111.5,表明MSAM结构对特征聚合具有良好的增强作用.
2.3.3 FEB层数选择消融实验
MSAM是整个模型中的重要组成部分,其核心结构是FEB. 因此,为验证FEB级联层数的合理性,在ShangHai Tech数据集Part_A上进行消融实验,结果如表4所示.
表 4 FEB层选择消融实验结果Table 4. Ablation experiments of number selection for FEBFEB 层数/层 MAE RMSE 0 64.9 109.8 2 63.5 103.4 4 62.5 95.7 6 67.1 115.8 由表4可以看出,随着FEB层数由0增加到4层时,模型计数性能随之提升,而FEB层数为6层时,由于信息冗余度过高,造成输出尺度混乱,从而导致计数精度降低. 通过对比实验,选择4层FEB来构建MSAM可有效提高模型性能.
3. 结束语
1) 提出了基于多尺度感知的密集人群计数网络,并在4个基准数据集上进行性能验证,其评价指标优于其他对比方法,针对不同的密集人群图像均具有良好的计数精度和鲁棒性.
2) 多尺度特征聚合模块以密集残差的连接方式级联4个特征增强块,有效聚合跨层次特征,提高多尺度信息的连续性. 在消融实验中充分证明该模块能有效提高尺度连续变化的建模能力.
3) 基于金字塔池化结构设计的上下文感知模块,能促进各分支间多尺度信息的交互,增强多尺度上下文信息的表达.
在后续工作中,将从提高算法对背景信息的鲁棒性角度出发,引入注意力机制以更好地聚焦人群区域,进一步弱化背景干扰和人群分布杂乱等带来的影响,提高人群计数性能.
-
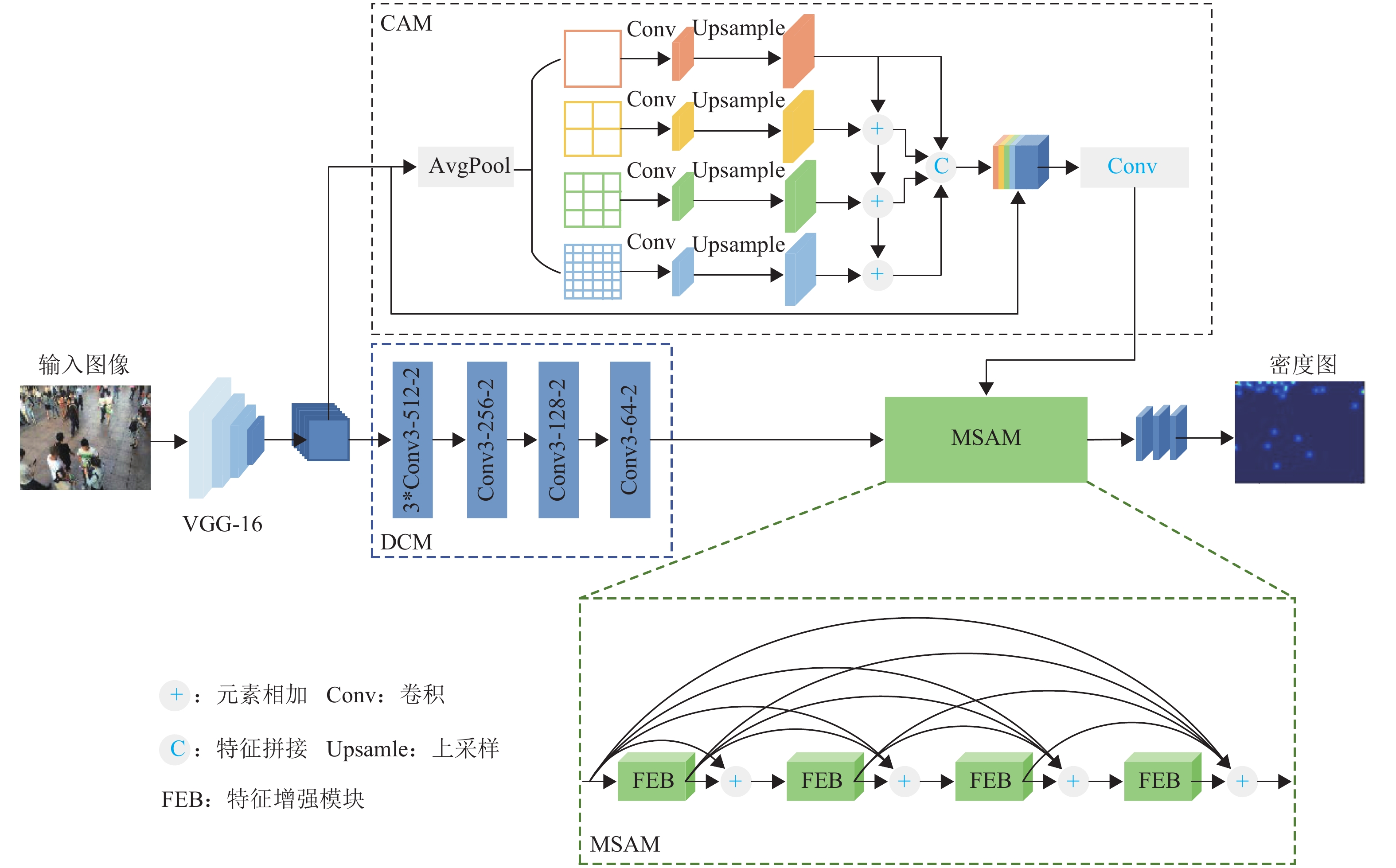
图 1 基于多尺度感知的密集人群计数网络结构
Figure 1. Structure of dense crowd counting network based on multi-scale perception
表 1 不同方法在Shanghai Tech、UCF_CC_50、UCF_QNRF、NWPU数据集上的对比结果
Table 1. Comparison results of different methods on Shanghai Tech, UCF_CC_50, UCF_QNRF, and NWPU datasets
模型 Shanghai Tech Part_A Shanghai Tech Part_B UCF_ CC_50 UCF_ QNRF NWPU MAE RMSE MAE RMSE MAE RMSE MAE RMSE MAE RMSE MCNN[7] 110.2 173.2 26.4 41.3 377.6 509.1 277.0 426.0 218.5 700.6 CSRNet[10] 68.2 115.0 10.6 16.0 266.1 397.5 120.3 208.5 104.8 433.4 PDD-CNN[29] 64.7 99.1 8.8 14.3 205.4 311.7 115.3 190.2 TEDNet[18] 64.2 109.1 8.2 12.8 249.4 354.5 113.0 188.0 KDMG[30] 63.8 99.2 7.8 12.7 99.5 173.0 100.5 415.5 BL[31] 62.8 101.8 7.7 12.7 229.3 308.2 88.7 154.8 93.6 470.3 CAN[20] 62.3 100.0 7.8 12.2 212.2 243.7 107.0 183.0 93.5 489.9 MCANet[32] 60.1 100.2 6.8 11.0 181.3 258.6 100.8 185.9 SC2Net[33] 58.9 97.7 6.9 11.4 209.4 286.3 98.5 174.5 89.7 348.9 MSPNet 62.5 95.7 6.9 11.0 156.5 223.3 87.7 148.2 81.9 300.3  下载: 导出CSV
下载: 导出CSV
表 2 CAM结构的消融实验结果
Table 2. Ablation experiments of CAM structure
方法 MAE RMSE 本文+PPM 63.6 105.4 本文+CAM 62.5 95.7
下载: 导出CSV
表 3 模块结构的消融实验结果
Table 3. Ablation experiments of different module structures
方法 MAE RMSE CAM 68.2 118.8 DCM 66.2 113.0 DCM+CAM 64.9 109.8 CAM+MSAM 65.5 111.4 DCM+MSAM 64.0 111.5 DCM+CAM+MSAM 62.5 95.7
下载: 导出CSV
表 4 FEB层选择消融实验结果
Table 4. Ablation experiments of number selection for FEB
FEB 层数/层 MAE RMSE 0 64.9 109.8 2 63.5 103.4 4 62.5 95.7 6 67.1 115.8
下载: 导出CSV
-
[1] FAN Z Z, ZHANG H, ZHANG Z, et al. A survey of crowd counting and density estimation based on convolutional neural network[J]. Neurocomputing, 2022, 472: 224-251. doi: 10.1016/j.neucom.2021.02.103 [2] 余鹰,朱慧琳,钱进,等. 基于深度学习的人群计数研究综述[J]. 计算机研究与发展,2021,58(12): 2724-2747. doi: 10.7544/issn1000-1239.2021.20200699YU Ying, ZHU Huilin, QIAN Jin, et al. Survey on deep learning based crowd counting[J]. Journal of Computer Research and Development, 2021, 58(12): 2724-2747. doi: 10.7544/issn1000-1239.2021.20200699 [3] TOPKAYA I S, ERDOGAN H, PORIKLI F. Counting people by clustering person detector outputs[C]//2014 11th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). Seoul: IEEE, 2014: 313-318. [4] RYAN D, DENMAN S, SRIDHARAN S, et al. An evaluation of crowd counting methods, features and regression models[J]. Computer Vision and Image Understanding, 2015, 130: 1-17. doi: 10.1016/j.cviu.2014.07.008 [5] LEMPITSKY V, ZISSERMAN A. Learning to count objects in images[C]//Proceedings of the 23rd International Conference on Neural Information Processing Systems. New York: ACM, 2010: 1324-1332. [6] WANG C, ZHANG H, YANG L, et al. Deep people counting in extremely dense crowds[C]//Proceedings of the 23rd ACM international conference on Multimedia. Brisbane: ACM, 2015: 1299-1302. [7] ZHANG Y Y, ZHOU D S, CHEN S Q, et al. Single-image crowd counting via multi-column convolutional neural network[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas: IEEE, 2016: 589-597. [8] SINDAGI V A, PATEL V M. Generating high-quality crowd density maps using contextual pyramid CNNs[C]//2017 IEEE International Conference on Computer Vision (ICCV). Venice: IEEE, 2017: 1879-1888. [9] CAO X K, WANG Z P, ZHAO Y Y, et al. Scale aggregation network for accurate and efficient crowd counting[C]//European Conference on Computer Vision. Cham: Springer, 2018: 757-773. [10] LI Y H, ZHANG X F, CHEN D M. CSRNet: dilated convolutional neural networks for understanding the highly congested scenes[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 1091-1100. [11] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]//3rd International Conference on Learning Representations. San Diego: [s.n.], 2015: 1-14. [12] YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[C]//Proceedings of the 4th International Conference on Learning Representations. Puerto Rico: ICLR, 2016: 1-13. [13] 田晟,张剑锋,张裕天,等. 基于扩张卷积金字塔网络的车道线检测算法[J]. 西南交通大学学报,2020,55(2): 386-392,416. doi: 10.3969/j.issn.0258-2724.20181026TIAN Sheng, ZHANG Jianfeng, ZHANG Yutian, et al. Lane detection algorithm based on dilated convolution pyramid network[J]. Journal of Southwest Jiaotong University, 2020, 55(2): 386-392,416. doi: 10.3969/j.issn.0258-2724.20181026 [14] 左静,巴玉林. 基于多尺度融合的深度人群计数算法[J]. 激光与光电子学进展,2020,57(24): 315-323.ZUO Jing, BA Yulin. Population-depth counting algorithm based on multiscale fusion[J]. Laser & Optoelectronics Progress, 2020, 57(24): 315-323. [15] CHEN X Y, BIN Y R, SANG N, et al. Scale pyramid network for crowd counting[C]//2019 IEEE Winter Conference on Applications of Computer Vision (WACV). Waikoloa: IEEE, 2019: 1941-1950. [16] SINDAGI V, PATEL V. Multi-level bottom-top and top-bottom feature fusion for crowd counting[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul: IEEE, 2019: 1002-1012. [17] ZHOU Y, YANG J X, LI H R, et al. Adversarial learning for multiscale crowd counting under complex scenes[J]. IEEE Transactions on Cybernetics, 2021, 51(11): 5423-5432. doi: 10.1109/TCYB.2019.2956091 [18] JIANG X L, XIAO Z H, ZHANG B C, et al. Crowd counting and density estimation by trellis encoder-decoder networks[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach: IEEE, 2019: 6126-6135. [19] TIAN Y K, LEI Y M, ZHANG J P, et al. PaDNet: pan-density crowd counting[J]. IEEE Transactions on Image Processing, 2020, 29: 2714-2727. doi: 10.1109/TIP.2019.2952083 [20] LIU W Z, SALZMANN M, FUA P. Context-aware crowd counting[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach: IEEE, 2019: 5094-5103. [21] LI H, KONG W H, ZHANG S H. Effective crowd counting using multi-resolution context and image quality assessment-guided training[J]. Computer Vision and Image Understanding,2020,201:103065.1-103065.10. [22] IDREES H, SALEEMI I, SEIBERT C, et al. Multi-source multi-scale counting in extremely dense crowd images[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland: IEEE, 2013: 2547-2554. [23] IDREES H, TAYYAB M, ATHREY K, et al. Composition loss for counting, density map estimation and localization in dense crowds[C]//European Conference on Computer Vision. Cham: Springer, 2018: 544-559. [24] WANG Q, GAO J Y, LIN W, et al. NWPU-crowd: a large-scale benchmark for crowd counting and localization[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(6): 2141-2149. doi: 10.1109/TPAMI.2020.3013269 [25] ZHAO H S, SHI J P, QI X J, et al. Pyramid scene parsing network[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu: IEEE, 2017: 6230-6239. [26] ZHANG Z L, ZHANG X Y, PENG C, et al. ExFuse: enhancing feature fusion for semantic segmentation[C]//European Conference on Computer Vision. Cham: Springer, 2018: 273-288. [27] 王银,王立德,邱霁. 基于DenseNet结构的轨道暗光环境实时增强算法[J]. 西南交通大学学报,2022,57(6): 1349-1357. doi: 10.3969/j.issn.0258-2724.20210199WANG Yin, WANG Lide, QIU Ji. Real-time enhancement algorithm based on DenseNet structure for railroad low-light environment[J]. Journal of Southwest Jiaotong University, 2022, 57(6): 1349-1357. doi: 10.3969/j.issn.0258-2724.20210199 [28] DAI F, LIU H, MA Y K, et al. Dense scale network for crowd counting[C]//Proceedings of the 2021 International Conference on Multimedia Retrieval. Taipei: ACM, 2021: 64-72. [29] WANG W X, LIU Q L, WANG W. Pyramid-dilated deep convolutional neural network for crowd counting[J]. Applied Intelligence, 2022, 52(2): 1825-1837. doi: 10.1007/s10489-021-02537-6 [30] WAN J, WANG Q Z, CHAN A B. Kernel-based density map generation for dense object counting[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(3): 1357-1370. doi: 10.1109/TPAMI.2020.3022878 [31] MA Z H, WEI X, HONG X P, et al. Bayesian loss for crowd count estimation with point supervision[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul: IEEE, 2019: 6141-6150. [32] WANG X, LV R R, ZHAO Y, et al. Multi-scale context aggregation network with attention-guided for crowd counting[C]//2020 15th IEEE International Conference on Signal Processing (ICSP). Beijing: IEEE, 2020: 240-245. [33] LIANG L J, ZHAO H L, ZHOU F B, et al. SC2Net: scale-aware crowd counting network with pyramid dilated convolution[J]. Applied Intelligence, 2023, 53(5): 5146-5159. 期刊类型引用(1)
1. 陈永,王镇,张娇娇. 频谱池化与混洗注意力增强的铁路异物轻量检测. 西南交通大学学报. 2024(06): 1294-1304 .  本站查看
本站查看其他类型引用(0)
-

 下载:
下载:

 下载:
下载:


 点击查看大图
点击查看大图
计量
- 文章访问数: 330
- HTML全文浏览量: 106
- PDF下载量: 71
- 被引次数: 1